Willkommen zu Teil 2 von Scientific Cloud Computing mit Kubernetes und Terraform. In diesem Beitrag zeige ich Ihnen anhand einer ausführlichen Demo, wie sich global skalierbares wissenschaftliches Cloud Computing mit Kubernetes und Terraform umsetzen lässt. Wenn Sie Ihr Wissen auffrischen oder mehr über moderne DevOps-Prinzipien und -Konzepte erfahren möchten, werfen Sie einen Blick in Teil 1 dieser Reihe.
Dieser Leitfaden zeigt Ihnen, wie sich DevOps, Container, Kubernetes und Terraform praxisnah einsetzen lassen, um Compute-workloads auszurollen.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Überblick
Auf einen Blick demonstriert der Beispielcode Folgendes:
- Wie Sie gängige Bioinformatik-Tools (FastQC und BWA) in Container-Images verpacken und in das Image-Repository der jeweiligen Cloud hochladen
- Wie Sie über Terraform – ein Infrastructure-as-Code-Tool – die gesamte Cloud-Infrastruktur für Ihre workloads aufsetzen (und ebenso schnell wieder abbauen)
- Wie Sie eine Workflow-Pipeline auf Basis dieser Images und der bereitgestellten Cloud-Infrastruktur in den vollständig verwalteten Kubernetes-Service der jeweiligen Cloud ausrollen – ein System zur Verwaltung und Orchestrierung von Container-Ausführungen. Für die Orchestrierung eines Workflows bzw. einer Task-Pipeline auf einem Kubernetes-Cluster kommt Argo zum Einsatz
Im Zusammenspiel von Docker, Terraform, Kubernetes und Argo lernen Sie:
- Wie Sie die für Ihre workloads erforderliche Infrastruktur mit wenigen Befehlen aufsetzen, aktualisieren und wieder abbauen
- Wie Sie End-to-End-Analyse-workloads als DAG-gesteuerte Workflows ausführen – mit automatischen Wiederholungen einzelner Schritte bei unerwarteten Fehlern oder Infrastrukturausfällen
- Wie Sie Logging und Metriken Ihrer workloads zentral in cloud-native Log- und Metrik-Tools zusammenführen
- Wie Sie workloads auf einer Infrastruktur betreiben, die je nach Bedarf automatisch hoch- (bis zur globalen Skalierung) und herunterskaliert (bis hin zu wenigen oder gar keinen Compute-Ressourcen). So zahlen Sie ausschließlich für die CPU-, RAM- und Storage-Ressourcen, die für Ihre Tasks tatsächlich nötig sind. Vorbei sind die Zeiten, in denen Server unnötig im Leerlauf liefen und die Rechnung in die Höhe trieben
- Wie Sie neue Softwareversionen reibungslos ausrollen und alte Versionen schrittweise ablösen
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Code-Walkthrough
Mit einem grundlegenden DevOps-Verständnis im Gepäck schauen wir uns nun an, wie die zu diesem Beitrag gehörige Codebasis zentrale DevOps-Prinzipien veranschaulicht. Der Walkthrough zeigt, wie Sie eine Infrastruktur aufbauen, die global skalierbare wissenschaftliche Pipelines ausführen kann. Konkret lassen wir Bestandteile einer typischen Bioinformatik-Pipeline laufen.
Wir möchten:
- Reports über ein Paar roher Genomsequenzierungsdateien erzeugen, um deren hohe Qualität zu validieren. Rohe Sequenzierungsdaten liegen im FASTQ-Format vor, QC-Prüfungen erfolgen mit dem Tool FastQC.
- Sind diese Reports erstellt, folgt der als Alignment bekannte Prozess, der – durch zusätzliche nachgelagerte Verarbeitungsschritte – schließlich die Mutationssuche ermöglicht. Hierfür nutzen wir bwa-mem2.
Unsere Kubernetes-basierte Pipeline soll also zwei FastQC-Container parallel auf einem Paar FASTQ-Sequenzierungsdaten ausführen. Sind beide Tasks erfolgreich, folgt das bwa-mem2-Alignment desselben Datenpaars gegen die aktuelle Version des menschlichen Genoms (hg38). Sowohl die FastQC-Reports als auch die von BWA erzeugte Alignment-Datei – ein BAM-File – werden zur Langzeitspeicherung in einen Bucket hochgeladen.
Hinweis zu den Kosten
Da diese Codebasis Sie durch einen realen analytischen Anwendungsfall führt und kein triviales Beispiel ist, fallen für die eingerichtete Compute-Umgebung nicht unerhebliche Kosten an. Je nachdem, wie lange Sie die Terraform-Infrastruktur laufen lassen, sollten Sie mit einem zweistelligen Dollarbetrag auf Ihrer Cloud-Rechnung rechnen.
Schritt 0: Lokale Clients installieren – Cloud-CLI, Terraform und kubectl
Stellen Sie sicher, dass das Cloud-CLI-Tool lokal installiert und gegen das Konto authentifiziert ist, das Sie verwenden möchten. CLI-Links: GCP und AWS. Cloud-Infrastruktur als Code aufzusetzen ist denkbar einfach: In den Ordner mit den YAML-Terraform-Dateien wechseln und ausführen:
terraform apply -auto-approve
Damit das funktioniert, müssen Sie den Terraform-Client lokal installieren. Terraform greift dann automatisch auf die Auth-Credentials Ihrer Cloud-CLI zurück.
Auch das Ausführen eines Jobs oder Workflows auf Kubernetes ist unkompliziert: YAML-Template für den Job/Workflow erstellen und ausführen:
kubectl create -f job.yaml
Voraussetzung dafür ist, dass Sie den kubectl-Client lokal installieren. Kubectl wird über einen cloud-spezifischen CLI-Befehl authentifiziert.
Schritt 1: FASTQ- und Human-Reference-Daten (hg38) beschaffen
Bevor wir den Workflow demonstrieren können, brauchen Sie ein FASTQ-Beispieldateipaar sowie das humane Referenzgenom hg38.
Um die Verarbeitungskosten gering zu halten und gleichzeitig mit praxisnahen Datenmengen zu arbeiten, habe ich aus dem S3-Bucket des 1000-Genomes-Projekts zwei FASTQ-Dateien (jeweils ca. 0,5 GB) für die "Goldstandard"-Probe NA12878 gezogen. Mein dringender Rat: Legen Sie in Ihrem Cloud-Konto einen GCS- oder S3-Bucket an und kopieren Sie die Dateien dorthin. Wenn Sie den Workflow wiederholt testen, möchten Sie die Daten vermutlich nicht jedes Mal aus dem 1000G-S3-Bucket nachladen.
Behalten Sie die Kosten für Cross-Region-Datentransfers stets im Blick.
Die FASTQ-Dateien liegen in der Region us-east-1 von Amazon. Wer sie in einen S3-Bucket einer anderen Region (z. B. us-west-2 in meinen Tests) oder aus AWS heraus in einen GCP-Cloud-Storage-Bucket verschiebt, zahlt für jedes GB, das aus der Bucket-Region heraus transferiert wird. Erstellen Sie also einen Bucket in der gewünschten Cloud-Region und kopieren Sie die FASTQs dorthin:
# R1 FASTQ in einem us-east-1 S3 Bucket
s3://1000genomes/phase3/data/NA12878/sequence_read/ERR001268_1.filt.fastq.gz
# R2 FASTQ in einem us-east-1 S3 Bucket
s3://1000genomes/phase3/data/NA12878/sequence_read/ERR001268_2.filt.fastq.gz# Beispielbefehl zum Kopieren eines Objekts:
YOUR_FASTQ_BUCKET=<BUCKET_NAME_HERE># Für AWS:
aws s3 cp s3://1000genomes/phase3/data/NA12878/sequence_read/ERR001268_1.filt.fastq.gz s3://{YOUR_FASTQ_BUCKET}/FASTQ/
# Für GCP: Datei zunächst mit 'aws s3 cp' in den lokalen Speicher einer VM kopieren
# Anschließend mit gsutil von dort in einen GCS-Bucket übertragen:
gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp /tmp/FASTQ/ERR001268_1.filt.fastq.gz gs://{YOUR_FASTQ_BUCKET}/FASTQ/
Außerdem müssen Sie das aktuelle humane Referenzgenom abrufen und einen bwa-mem2-Index dafür erstellen. Mein Vorgehen:
- Kopieren Sie die hg38-FASTA aus dem us-east-1-S3-Bucket des Broad Institute auf eine VM mit sehr viel Arbeitsspeicher in der Cloud Ihrer Wahl. Das kann eine r5.16xlarge auf AWS oder eine n2-highmem-64 auf GCP sein.
- Installieren Sie bwa-mem2 (oder verwenden Sie das später beschriebene Container-Image).
- Bauen Sie den bwa-mem2-Referenzindex (das dauert 1–2 Stunden).
- Laden Sie die Ausgabedateien in einen neuen Bucket in Ihrem Cloud-Konto hoch.
# hg38-Referenzgenom des Broad Institute in einem us-east-1 S3 Bucket
s3://broad-references/hg38/v0/Homo_sapiens_assembly38.fasta# Beispielbefehle zum Erstellen des bwa-mem2-Index und Speichern in Ihrem Bucket
YOUR_REF_BUCKET=<BUCKET_NAME_HERE># Für AWS und GCP:
aws s3 cp s3://broad-references/hg38/v0/Homo_sapiens_assembly38.fasta /tmp/reference/hg38.fastabwa-mem2 index -p hg38 /tmp/reference/hg38.fasta# Für AWS:
aws s3 sync /tmp/reference/ s3://${YOUR_REF_BUCKET}/hg38/
# Für GCP:
gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp "/tmp/reference/hg38*" gs://${YOUR_REF_BUCKET}/hg38/
Wenn Sie die obigen Schritte korrekt ausgeführt haben, verfügen Sie nun über zwei FASTQs (rohe Genomsequenzierungsdaten) und das humane Referenzgenom hg38, einsatzbereit für Tests Ihrer Bioinformatik-Workflows.
Schritt 2: Cloud-Infrastruktur aufbauen
Mit Terraform setzen wir die gesamte Cloud-Infrastruktur auf, die für den Betrieb eines vollständig verwalteten Kubernetes-Clusters nötig ist. Anschließend führen wir auf dem Cluster (über kubectl) einige Befehle aus, die argo installieren – ein Kubernetes-Tool zur Ausführung von Workflows wie z. B. Bioinformatik-Pipelines.
Standardmäßig speichert Terraform den bekannten Zustand der Cloud-Infrastruktur lokal. In der Praxis nutzt man jedoch einen Bucket als Terraform-Backend, sodass alle Beteiligten in einem Unternehmen bei Infrastrukturänderungen mit derselben aktuellen "Single Source of Truth" arbeiten.
Ein Bucket-Backend sperrt zudem weitere Infrastrukturänderungen, solange ein Änderungssatz noch angewendet wird. So lassen sich konkurrierende, potenziell konfliktbehaftete terraform-apply-Operationen verhindern. Um die Unterstützung für ein Bucket-basiertes Terraform-Backend zu aktivieren, erstellen Sie einen Bucket in Ihrer Cloud-Umgebung und ersetzen Sie per Suchen-und-Ersetzen alle Verweise auf doit-matt-tf-state-test in der Codebasis durch den Namen Ihres Buckets.
Mit einem fertigen Terraform-Backend-Bucket können Sie nun die Infrastruktur hochfahren.
Möchten Sie Ihren workload in Google Cloud ausführen, wechseln Sie nach GCP/terraform. In diesem Ordner finden Sie die Unterordner standard und autopilot mit jeweils eigenem TF-Code, der einen GKE-Cluster im Standard- bzw. Autopilot-Modus startet. Autopilot ist in der Regel die bevorzugte Option: Es bewegt Nodes (Compute-Ressourcen) in Richtung eines Serverless-Modells und erzwingt zahlreiche Security-Best-Practices.
Leider funktioniert Autopilot in dieser Demo aufgrund einer Einschränkung nicht: Der ephemere Festplattenspeicher ist auf 10 GiB begrenzt – zu wenig, um FastQC oder bwa-mem2 mit realen Daten auszuführen. Sollte diese Beschränkung künftig fallen, ist Autopilot dennoch dem Standard-Modus vorzuziehen. Für diesen Fall liegt der TF-Code für Autopilot bereits bei. Auch AWS ECS Fargate hat ein Limit von 200 GiB Festplattenspeicher, das für die meisten realen wissenschaftlichen Compute-Anwendungsfälle nicht ausreicht. Fargate-TF-Code ist im Repository deshalb nicht enthalten.
Möchten Sie Ihren workload auf AWS ausführen, wechseln Sie nach AWS/terraform.
Im jeweiligen cloud-spezifischen Terraform-Ordner führen Sie aus:
terraform apply -auto-approve# Mit 'terraform plan' können Sie die geplanten Infrastrukturänderungen zunächst einsehen, ohne etwas zu erstellen
Damit werden die im Ordner liegenden .tf-Dateien geplant und unmittelbar angewendet, um einen K8s-Cluster samt Voraussetzungen aufzusetzen. Terraform fragt lediglich nach einer GCP-Projekt-ID oder einer AWS-Account-ID – das war's.
Optional können Sie vor dem Apply die Datei variables.tf bearbeiten, um etwa die Region des Clusters, den Cluster-Namen oder die GCP-Projekt-/AWS-Account-ID-Variable fest einzutragen.
Ich empfehle Ihnen ausdrücklich, den Code zu studieren, um Terraform zu lernen.
Zur schnelleren Orientierung – für GCP werden folgende Ressourcen erstellt:
- Aktivierung der Compute-, Container- und IAM-APIs
- Ein autoskalierender GKE-Standard-Cluster im Standard-VPC mit der jeweils aktuellen Kubernetes-Version (zum Veröffentlichungszeitpunkt v1.20) und einigen optionalen Security-Best-Practices wie Workload Identity, Shielded Nodes und Secure Boot. Es handelt sich um einen regionalen Cluster mit Nodes in mehreren Zonen (Rechenzentren)
- Ein GCP Service Account (SA) sowie der zugehörige Kubernetes Service Account (KSA), die mittels Workload Identity die GCP-Berechtigungen aller Jobs in einem bestimmten Kubernetes-Namespace einschränken. Der SA/KSA darf in Buckets lesen und schreiben sowie diverse Logs und Metriken in Cloud Logging und Cloud Metrics schreiben
- Der Cluster nutzt Preemptible-/Spot-Instances. Sie zahlen deutlich weniger als den On-Demand-Preis – müssen aber damit rechnen, dass Nodes unerwartet wegfallen und schließlich ersetzt werden. K8s erkennt Jobs, die durch eine plötzliche Node-Termination fehlschlagen, automatisch und plant sie neu ein
Für AWS werden folgende Networking- und Security-Komponenten erstellt:
- Eine neue VPC, die ausschließlich den K8s-Cluster beherbergt
- Öffentliche (ungenutzte) und private Subnetze sowie Routing-Tabellen für Cluster-Nodes
- Ein NAT-Gateway, S3- und ECR-VPC-Endpunkte mit zugehörigen TLS-fähigen Security Groups sowie Aktivierung der DNS-Hostname-Unterstützung für einen privaten Node-Cluster
- Ein Internet Gateway für den öffentlichen Zugriff auf die Cluster-Control-Plane
Bei AWS müssen Sie zusätzlich nach AWS/terraform/ecr wechseln und erneut terraform apply ausführen, da die .tf-Dateien in diesem Ordner Folgendes erstellen:
- Die Repositories, in denen die von Ihnen erstellten Container-Images abgelegt werden
(Auf GCP müssen die Repositories nicht erstellt werden.)
Bei AWS müssen Sie außerdem nach AWS/terraform/eks wechseln und erneut terraform apply ausführen, da die .tf-Dateien in diesem Ordner Folgendes anlegen:
- Eine IAM-Rolle für den Cluster mit Lese- und Schreibzugriff auf S3-Buckets sowie browserbasiertem, schlüssellosem SSH-Zugriff auf Nodes via SSM Manager
- Einen autoskalierenden EKS-Cluster mit der jeweils aktuellen Kubernetes-Version (zum Veröffentlichungszeitpunkt v1.21). Workload Identity, Shielded Nodes und Secure Boot stehen auf EKS nicht ohne Weiteres zur Verfügung. Es handelt sich um einen regionalen Cluster mit Nodes in mehreren Zonen (Rechenzentren)
- Der Cluster nutzt Preemptible-/Spot-Instances. Sie zahlen deutlich weniger als den On-Demand-Preis – müssen aber damit rechnen, dass Nodes unerwartet wegfallen und schließlich ersetzt werden. K8s erkennt Jobs, die durch eine plötzliche Node-Termination fehlschlagen, automatisch und plant sie neu ein
Sind die Terraform-Apply-Operationen abgeschlossen, ist Ihr Cluster betriebsbereit und kann über kubectl mit Kubernetes-API-Befehlen angesteuert werden. Authentifizieren Sie kubectl einfach mit einem cloud-spezifischen Befehl:
# Für GCP:
gcloud container clusters get-credentials --region=us-central1 bioinformatics-tasks
# Für AWS:
aws eks update-kubeconfig --name=bioinformatics-tasks
Nun können Sie verschiedene Befehle gegen den Cluster ausführen, etwa Pods aus allen Namespaces auflisten mit kubectl get pods -A:
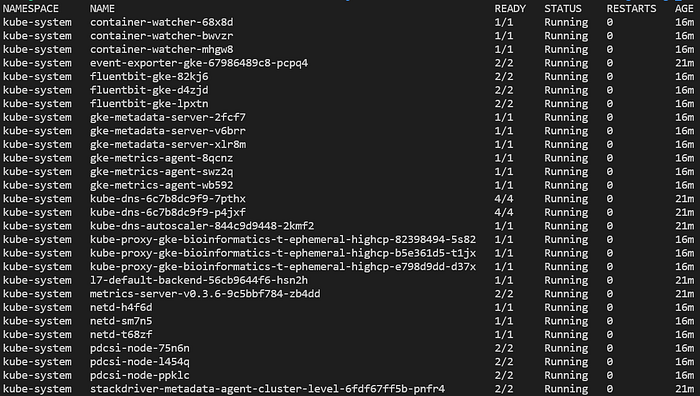
Typische Pods in einem neuen, vollständig verwalteten GKE-Standard-Cluster
Mit dem laufenden Cluster müssen wir nun argo installieren – damit lassen sich nicht nur einzelne Tasks einreichen, sondern auch DAG-gesteuerte Workflows bzw. Task-Pipelines.
Auf GCP wechseln Sie dafür nach GCP/terraform/standard/kubectl_commands
Auf AWS wechseln Sie nach AWS/terraform/kubectl_commands
Mit terraform apply -auto-approve in diesen Ordnern werden Terraform-verwaltete kubectl-Befehle ausgeführt, die:
- einen Namespace "biojobs" anlegen, an den Jobs eingereicht werden und der (auf GCP) auf Lese-/Schreibzugriff auf einen Bucket beschränkt ist.
- argo installieren und ihm – auf GCP via Workload Identity – passend zugeschnittene Berechtigungen geben, um den Pod-Fortschritt im Namespace "biojobs" zu überwachen.
Ob der Namespace erstellt und argo installiert wurde, prüfen Sie, indem Sie alle Namespaces auflisten und anschließend nach Pods im argo-Namespace suchen:
kubectl get ns
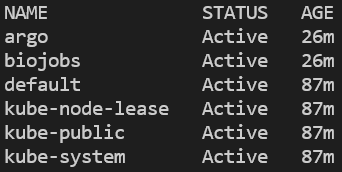
Alle Namespaces im Cluster. Bei EKS kommt zusätzlich "amazon-cloudwatch" hinzu.
kubectl get pods -n argo

Argo-Server- und Workflow-Controller-Pods im Namespace "argo"
Führen Sie zum Schluss diesen Befehl aus, damit argo mit dem Wechsel von docker zu containerd als Container-Runtime ab Kubernetes ≥ v1.19 reibungslos zusammenarbeitet. Diese Detailfrage müssen Sie nicht weiter beachten – argo wird das Problem ohnehin in absehbarer Zeit selbst lösen:
kubectl patch configmap workflow-controller-configmap -n argo --patch ‘{"data":{"containerRuntimeExecutor":"k8sapi"}}’
Mit installiertem argo und einsatzbereiten Compute-Nodes können wir kreativ werden!
Schritt 3: Container-Images für FastQC und bwa-mem2 erstellen
Um FastQC- und bwa-mem2-workloads in AWS oder GCP auszuführen, müssen wir Container-Images für diese Tools bauen und im Container-Image-Repository der jeweiligen Cloud (GCR für GCP, ECR für AWS) ablegen.
Wechseln Sie nach images/fastqc/
In diesem Ordner liegt das Dockerfile, das definiert, wie FastQC zusammen mit s5cmd (einem Tool für schnelle AWS-S3-↔-Lokal-Kopien) und gsutil (für GCS-↔-Lokal-Kopien) in einen Container gepackt wird. Nehmen Sie sich Zeit, den Inhalt der Datei zu studieren und sich anzuschauen, wie Dockerfiles aufgebaut sind. Ergänzend könnte Sie dieser Artikel von mir zur Maximierung der Bucket-Datentransfergeschwindigkeit interessieren – die dort beschriebenen Prinzipien fließen in das Dockerfile ein.
Führen Sie build_fastqc_image_gcp.sh oder build_fastqc_image_aws.sh aus, um aus dem Dockerfile ein Container-Image zu erstellen und anschließend in GCR bzw. ECR zu pushen.
Um ein Container-Image für bwa-mem zu erstellen und in GCR oder ECR abzulegen, wechseln Sie nach images/bwa-mem2/ und wiederholen denselben Build-Skript-Vorgang.
Nach diesem Schritt stehen FastQC und bwa-mem2 über die im Image-Repository Ihrer Cloud-Umgebung gespeicherten Container-Images zur Ausführung auf einem Kubernetes-Cluster bereit.
Schritt 4: Kubernetes-Jobs einreichen und überwachen
Als Nächstes wechseln wir in den cloud-spezifischen Ordner für Kubernetes-Jobs und starten ein paar davon. Letztlich werden wir FastQC und bwa-mem2 in einer Pipeline mit argo ausführen – zunächst aber starten wir die Tasks einzeln.
Für GCP wechseln Sie nach GCP/gke/FastQC/
Für AWS wechseln Sie nach AWS/eks/FastQC/
In diesen Ordnern liegt ein Kubernetes-Job mit dem Namen fastqc.yaml.
Dieses YAML definiert einen Job, der mit kubectl create -f fastqc.yaml ausgeführt werden kann. Die Datei enthält allerdings einige Variablen, die run_fastqc_job.sh direkt darin setzt und ersetzt. Nehmen Sie sich Zeit, Kubernetes-Objekte generell und Jobs im Speziellen zu verstehen, um fastqc.yaml nachvollziehen zu können – und werfen Sie einen Blick auf das Shell-Skript.
Im Wesentlichen wird Kubernetes häufiger genutzt, um langlaufende Pods – sogenannte Deployments (z. B. langlebige Webserver) – zu betreiben. Es kann aber auch Jobs bzw. einmalige Ausführungs-Tasks bewältigen, etwa wissenschaftliche Programme wie FastQC. In der gesamten Codebasis reichen wir Kubernetes-Job-Objekte beim Cluster ein.
Übergeben Sie dem Shell-Skript die Variablen INPUT_FILEPATH und OUTPUT_FILEPATH; es startet daraufhin einen FastQC-Job mit einer der zuvor heruntergeladenen FASTQ-Dateien und legt den gepackten Report in einem Bucket ab. Alternativ können Sie die Variablen in fastqc.yaml manuell ersetzen und den Job ausführen mit: kubectl create -f fastqc.yaml
Den FastQC-Fortschritt verfolgen Sie mit: kubectl get pods -n biojobs
Sie sehen, dass ein einzelner Pod gestartet wird, der zunächst das Container-Image herunterlädt und kurz darauf den angegebenen Job ausführt:

FastQC-Pod – Status ContainerCreating

FastQC-Pod – Status Running
Anwendungslogs während der Ausführung prüfen Sie mit kubectl logs -n biojobs <pod_name>:
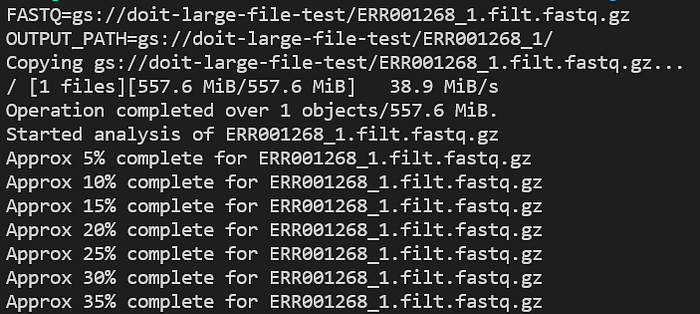
Fortschritt des FastQC-Pods
Da Container – und GKE/EKS – von Anfang an mit Blick auf Monitoring konzipiert wurden, finden Sie diese Log-Einträge mühelos in der nativen Logging-Lösung Ihrer Cloud. Das ermöglicht eine langfristige Log-Aufbewahrung samt Analysefunktionen.
Verwenden Sie den Suchbegriff complete for in Cloud Logging (GCP) oder CloudWatch (AWS), um Log-Einträge des FastQC-Pods zu finden:
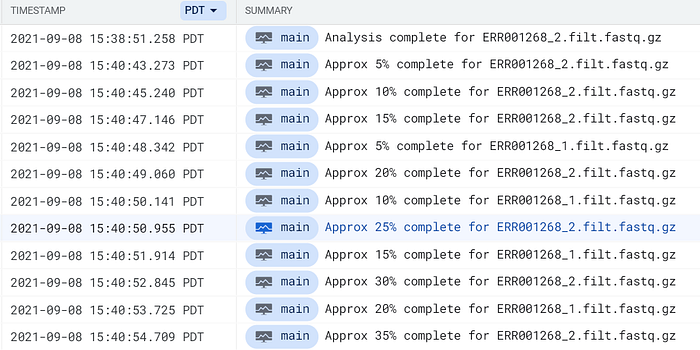
FastQC-Pod-Logs in Cloud Logging von GCP
Nach kurzer Zeit sollte ein FastQC-Report in Ihrem Output-Bucket-Pfad auftauchen. Starten Sie FastQC-Pods für beide FASTQ-Dateien, bis die Reports erscheinen:
Im Bucket gespeicherte FastQC-Reports
Mehr braucht es nicht, um FastQC im großen Maßstab auf Kubernetes laufen zu lassen!
Sie können einen FastQC-Job starten – oder zehntausend gleichzeitig. Die Kubernetes-Control-Plane skaliert zusammen mit dem Auto-Scaling-Service der Compute-Nodes Ihrer Cloud-Umgebung die Compute-Kapazität nach Bedarf hoch und herunter, abgestimmt auf die in der Kubernetes-Object-YAML von FastQC definierten Anforderungen an CPU, Speicher und Disk.
Achten Sie nur darauf, dass die Maximalwerte des Cluster-Autoscalers für Node-Anzahl, CPU und Speicher beim Anlegen des Clusters hoch genug sind – oder zumindest auf dem Niveau, das Sie aus Kostengründen anstreben. (GCP: gke.tf, AWS: cluster.tf)
Bwa-mem2 lässt sich mit ähnlicher Leichtigkeit kosteneffizient skalieren!
Für GCP wechseln Sie nach GCP/gke/bwa-mem2/
Für AWS wechseln Sie nach AWS/eks/bwa-mem2/
Geben Sie Input- und Output-Pfade für die Variablen am Anfang von run_bwa-mem2_job.sh an. Die Werte ersetzen die Variablennamen in bwa-mem2.yaml, und der Job wird beim Cluster eingereicht.
Beobachten Sie weiterhin Pod-Status und Logs, bis ein BAM-File in Ihrem Output-Bucket-Pfad erscheint:
Im Bucket gespeicherte BAM-Datei
Schauen Sie sich die CPU-Auslastungsmetriken der GCE-/EC2-Nodes an, die Ihren Cluster betreiben: Sie werden feststellen, dass die schwach ausgelasteten, einkernigen FastQC-Jobs an kleinere CPU-Maschinen gehen, während BWA-Jobs, die alle Kerne nutzen, an leistungsstarke CPU-Maschinen geleitet werden. Diese entsprechen den Low-/High-CPU-Kubernetes-Node-Groups, die so angelegt wurden, dass für jeden grundverschiedenen workload passend dimensionierte Maschinen kosteneffizient hoch- und wieder herunterskalieren.
Beispielsweise wäre es auf AWS wenig sinnvoll, beim Hochskalieren eine 96-vCPU-m5.24xlarge-Maschine bereitzustellen, nur um einen einzelnen Single-Core-FastQC-Job zu fahren. Stattdessen senden wir FastQC an eine Node-Group mit 4-vCPU-m5.xlarge-Maschinen. BWA hingegen braucht so viele Kerne wie möglich – diese Jobs gehen an die 96-vCPU-Node-Group, die unabhängig von der 4-vCPU-(FastQC)-Node-Group skaliert.
Wer schon einmal Secondary-Analysis-Workflows entwickelt hat, die rohe Sequenzierungsdaten zur Variantenentdeckung verarbeiten, beginnt jetzt vermutlich, die Stärke von Kubernetes zu erkennen. Vorbei sind die Zeiten von:
- On-Prem-Job-Schedulern, die im großen Maßstab zickig werden
- Sorgen, ob das gleichzeitige Starten zu vieler Jobs den Job-Scheduler oder gar den Cluster lahmlegt, der Ihre (und alle anderen) workloads betreibt
- Verärgerten Kolleg:innen, weil Sie ihnen On-Prem-Compute-Kapazität wegnehmen, die sie für ihre eigenen workloads brauchen
- Manuellem Überwachen und Neustarten von workloads, die aus unerwarteten, aber behebbaren Gründen fehlschlagen
- Verzweifeltem Suchen nach Logdateien abgestürzter Jobs – häufig für Anwendungen ohne saubere Log-Funktionalität
Wenn man jetzt nur noch keinen Spaghetti-Code mehr schreiben müsste, um die Pipeline-Schritte zu verketten …
Schritt 5: Argo-Workflows einreichen (Pipelines aus Kubernetes-Jobs)
Argo erlaubt es, Jobs zu Pipelines zu verketten, die auch im großen Maßstab stabil laufen und sowohl Job- als auch Pipeline-Wiederholungen bei unerwarteten Ausfällen unterstützen.
Schauen wir uns an, wie sich mit argo zwei FastQC-Pods parallel ausführen lassen. Nur wenn beide Pods erfolgreich abgeschlossen sind, startet anschließend das Alignment mit bwa-mem2 – und zwar mit demselben FASTQ-Paar.
(Als persönliche Übung: Sie könnten dem FastQC-Image einen Pass/No-Pass-Schritt hinzufügen. Ist die FASTQ-Qualität so niedrig, dass sich das Alignment nicht lohnt, wird der BWA-Schritt im argo-Workflow übersprungen.)
Für GCP wechseln Sie nach GCP/gke/argo_workflow/
Für AWS wechseln Sie nach AWS/eks/argo_workflow/
Geben Sie Input- und Output-Pfade für die Variablen am Anfang von run_fastqc_to_bwa.sh an. Die Werte ersetzen die Variablennamen in fastqc_to_bwa.yaml, und der Job wird beim Cluster eingereicht.
Führen Sie fortlaufend kubectl get pods -n biojobs aus, und Sie sehen, wie zunächst die FastQC-Pods laufen, dann abgeschlossen werden und anschließend ein BWA-Job startet:

FastQC-Pods, die auf den R1- und R2-FASTQ-Dateien für NA12878 laufen
…

bwa-mem2-Alignment-Pod, gestartet nach Abschluss der beiden FastQC-Pods
Werfen wir einen Blick auf den bwa-mem2-Pod mit:
kubectl logs -n biojobs <pod_name> main
(Beachten Sie, dass nach dem Pod-Namen "main" angefügt wurde. Bei argo gibt es für jeden Job in einem Workflow "main"- und "wait"-Pod-Logs.)
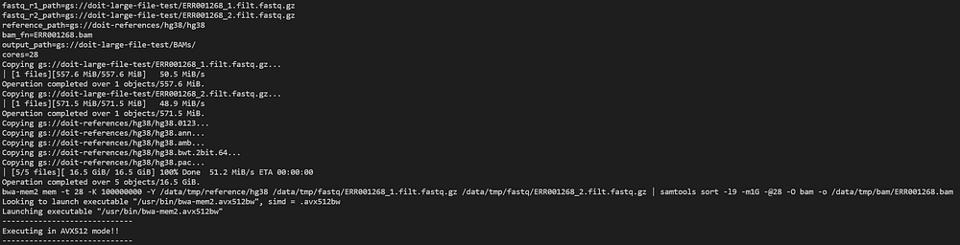
bwa-mem2 arbeitet als Teil eines argo-Workflows munter vor sich hin
Mit kubectl get wf -n biojobs überwachen Sie den Fortschritt des argo-Workflows:

Sobald BWA fertig ist, ist der Workflow abgeschlossen, und Sie finden ein Paar FastQC-Reports sowie eine BAM-Datei in Ihrem Output-Bucket.
Schritt 6: Aufräumen
Wir haben für BWA einiges an teurer Compute-Infrastruktur hochgefahren – und möchten diesen GKE-/EKS-Cluster nicht ungenutzt herumstehen lassen.
Gehen Sie einfach in umgekehrter Reihenfolge durch die Terraform-Ordner und führen Sie aus:
terraform destroy -auto-approve
Beachten Sie: Die Buckets, die Sie manuell als Terraform-Backend bzw. zur Speicherung der FASTQ- und Referenzdateien angelegt haben, werden dadurch nicht entfernt. Terraform kennt und überwacht ausschließlich Ressourcen, die es selbst angelegt hat. Auf GCP müssen Sie zudem die Container-Images in GCR manuell löschen.
Für GCP führen Sie den Destroy-Befehl in dieser Reihenfolge aus:
GCP/terraform/standard/kubectl_commands/
GCP/terraform/standard/
Für AWS führen Sie den Destroy-Befehl in dieser Reihenfolge aus:
AWS/terraform/eks/kubectl_commands/
AWS/terraform/eks/
AWS/terraform/ecr/ (falls Sie die Image-Repositories löschen möchten)
AWS/terraform/
Schritt 7: Nächste Schritte
Mit den bisher erlernten Fähigkeiten können Sie Pipelines beliebiger Komplexität bauen, die auf jeder beliebigen Anwendung basieren – denn jedes Programm lässt sich containerisieren.
Mit versioniertem Container-Image-Code, versionsgetaggten Containern, versionierter Infrastruktur und argo-Pipelines können Sie neue Software- und Pipeline-Versionen ausrollen, alte Versionen ablösen und bei fehlerhaften Deployments zurückrollen – relativ unkompliziert, zumindest verglichen mit den Alternativen, sofern Sie diesen Lernpfad weitergehen.
Welche nächsten Schritte Sie gehen, liegt bei Ihnen. Ich hoffe jedoch, Ihnen die Kernfähigkeiten für modernes, skalierbares Scientific Computing mit auf den Weg gegeben zu haben.
Mit Best Practices allein kommen Sie in der Cloud nur bedingt weit. Hochverfügbar, ausfallsicher und kostenoptimiert zu skalieren, ist heute eine echte Herausforderung. Diese zusätzlichen Engineering-Aufgaben kommen oben auf den ohnehin wachsenden workload-Berg – und das geht direkt zulasten der Produktivität.
Als Wissenschaftler:in im 21. Jahrhundert ist es essenziell, Anwendungen von Anfang an mit Blick auf Skalierbarkeit und einfaches Deployment zu entwickeln. Andernfalls bereiten Sie Ihrer Organisation nur Kopfschmerzen. Auf Dauer wachsen diese Probleme zu ernsten und endlosen Production-Issues heran.
Wenn Sie dieses Projekt inspiriert, Sie sich aber gleichzeitig etwas erschlagen fühlen, sprechen Sie DoiT International an. Sie können mir auch direkt auf LinkedIn schreiben.
DoiT begleitet Kunden hin zu kostenoptimierten, skalierbaren, hochverfügbaren, resilienten und Big-Data-tauglichen Cloud-Architekturen – und das buchstäblich kostenlos. Nicht ohne Grund wurden wir als Google Cloud Global Reseller Partner of the Year 2020 ausgezeichnet.
Außerdem haben wir die Partner Network (APN) Certification Distinction von Amazon erlangt und sind weiterhin AWS Advanced Consulting Partner – dank erstklassiger Engineering-Talente und starker Kundenbetreuung. Alle Informationen erhalten Sie bedarfsgerecht, um cloud-bezogene Fragen zu beantworten oder laufende Probleme zu lösen.
Vielen Dank für Ihre Zeit. Ich hoffe, diese beiden Artikel haben Ihre Skills erweitert. Sie skalieren? Melden Sie sich – wir helfen Ihnen, Ihre Ziele zu erreichen.
Danke fürs Lesen! Bleiben Sie in Verbindung – folgen Sie uns auf dem DoiT Engineering Blog , dem DoiT LinkedIn-Kanal und dem DoiT Twitter-Kanal . Karrieremöglichkeiten finden Sie unter https://careers.doit-intl.com .