KubernetesとTerraformで実現する地球規模の科学計算クラウドの第2部へようこそ。本記事では、KubernetesとTerraformによる地球規模の科学計算クラウドの実装デモを一通りご紹介します。モダンなDevOpsの考え方や原則をおさらいしたい、もう少し詳しく知りたいという方は、本シリーズ第1部をご覧ください。
本ガイドでは、DevOps、コンテナ、Kubernetes、Terraformを実際の計算ワークロードのデプロイにどう活かせるかを解説します。
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
概要
サンプルコードの全体像は次のとおりです。
- 代表的なバイオインフォマティクスツール(FastQCとBWA)をコンテナイメージ化し、各クラウドのイメージリポジトリへアップロードする方法を示します
- Infrastructure as CodeツールであるTerraformを使い、ワークロード実行に必要なクラウドインフラを起動・素早く破棄します
- これらのイメージと構築済みインフラをもとに、共通のワークフローパイプラインを各クラウドのフルマネージドKubernetesサービス(コンテナ実行管理・オーケストレーション基盤)へデプロイします。Kubernetesクラスター上のタスクのワークフローやパイプラインのオーケストレーションにはArgoを使います
Docker、Terraform、Kubernetes、Argoを組み合わせることで、次のことができるようになります。
- シンプルなコマンドで、ワークロード実行に必要なインフラを起動・更新・破棄する
- 個々のステップが想定外のエラーやインフラ障害に見舞われても自動で再試行される、エンドツーエンドのDAG型ワークロードを実行する
- ワークロードのログとメトリクス監視を、クラウドネイティブのログ・メトリクス分析ツールに集約する
- 必要に応じて自動的にスケールアップ(地球規模の処理能力まで)・スケールダウン(計算リソースを最小限またはゼロに)するインフラ上でワークロードを動かし、タスクの完遂に必要なCPU・RAM・ストレージ分だけを支払う。サーバーをアイドル状態で放置して請求額を無駄に膨らませる時代はもう終わりです
- 新バージョンのソフトウェアをシームレスにデプロイし、旧バージョンの利用を段階的に廃止する
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
コードのウォークスルー
DevOpsの基礎を押さえたところで、本記事に対応するコードベースがDevOpsの中核原則をどう体現しているかを見ていきましょう。本ウォークスルーでは、地球規模に対応した科学計算パイプラインを支えるインフラの構築方法をご紹介します。具体的には、代表的なバイオインフォマティクスパイプラインの構成要素を実行します。
ゴールは次の2点です。
- 生のゲノムシーケンスデータファイルのペアについて、品質を確認するためのレポートを生成する。生のシーケンスデータはFASTQ形式で保存されており、QCチェックはFastQCというツールで行います。
- レポート生成後、アラインメントと呼ばれる処理を行う。これは(下流ツールでの追加処理を経て)最終的に変異検出を可能にする工程で、bwa-mem2というツールを使います。
つまり、Kubernetesベースのパイプラインで、FASTQシーケンスデータファイルのペアに対して2つのFastQCコンテナを同時実行し、両方のタスクが成功した場合のみ、生のシーケンスデータセットのペアをhg38と呼ばれる最新のヒトゲノムに対してbwa-mem2でアラインメントします。FastQCレポートとBWAが生成するアラインメントファイル(BAMファイル)は、長期保管のためバケットへアップロードします。
コストに関するご注意
本コードベースは単純なサンプルではなく実運用に近い分析ユースケースを扱うため、構築する計算環境にはそれなりのコストがかかります。Terraformで構築したインフラを稼働させ続ける時間にもよりますが、クラウド請求として数十ドル程度を見込んでおくとよいでしょう。
Step 0: ローカルクライアントのインストール — Cloud CLI、Terraform、kubectl
使用するアカウントに対して、ローカルのクラウドCLIツールがインストールされ、認証済みであることを確認してください。CLIのリンクはこちら:GCP、AWS。Infrastructure as Codeでクラウドインフラを立ち上げるには、YAML形式のTerraformファイルが置かれたフォルダに移動して次を実行するだけです。
terraform apply -auto-approve
これを動かすには、Terraformクライアントをローカルにインストールしておく必要があります。Terraformはお使いのクラウド CLIの認証情報を自動的に利用します。
Kubernetes上でジョブやワークフローを実行するのも、ジョブ/ワークフローのYAMLテンプレートを作成して次を実行するだけです。
kubectl create -f job.yaml
そのためには、kubectlクライアントをローカルにインストールしておく必要があります。kubectlの認証は、クラウドごとのCLIコマンドで行います。
Step 1: FASTQとヒト参照ゲノム(hg38)データの取得
このワークフローのデモを始める前に、サンプルとなるFASTQファイルのペアと、作業に使うhg38ヒト参照ゲノムを用意する必要があります。
処理コストを抑えつつ実運用に近い規模のデータを扱うため、1000 GenomesプロジェクトのS3バケットから、いわゆる「ゴールドスタンダード」サンプルNA12878の約0.5GBのFASTQファイル2つを取得しました。これらのファイルは、ご自身のクラウドアカウントにGCSまたはS3のバケットを作成してコピーしておくことを強くおすすめします。ワークフローを繰り返しテストするうちに、毎回1000GのS3バケットから取得するのは避けたくなるはずです。
常にクロスリージョンのデータ転送料金に注意してください。
FASTQファイルはAmazonのus-east-1リージョンに置かれているため、別リージョンのS3バケット(例:本テストで使ったus-west-2)へ移動したり、AWSからGCPのCloud Storageバケットへ移したりすると、バケットのリージョン外へ出るデータ1GBごとに料金が発生します。希望するクラウドリージョンにバケットを作成し、FASTQをコピーしてください。
# us-east-1のS3バケットにあるR1 FASTQ
s3://1000genomes/phase3/data/NA12878/sequence_read/ERR001268_1.filt.fastq.gz
# us-east-1のS3バケットにあるR2 FASTQ
s3://1000genomes/phase3/data/NA12878/sequence_read/ERR001268_2.filt.fastq.gz# オブジェクトをコピーするコマンド例:
YOUR_FASTQ_BUCKET=<BUCKET_NAME_HERE># AWSの場合:
aws s3 cp s3://1000genomes/phase3/data/NA12878/sequence_read/ERR001268_1.filt.fastq.gz s3://{YOUR_FASTQ_BUCKET}/FASTQ/
# GCPの場合は、まず 'aws s3 cp' でVMのローカルストレージへコピー
# その後、gsutilでローカルからGCSバケットへコピー:
gsutil -o GSUtil:parallel_composite_upload_threshold=150M cp /tmp/FASTQ/ERR001268_1.filt.fastq.gz gs://{YOUR_FASTQ_BUCKET}/FASTQ/
さらに、最新のヒト参照ゲノムを取得し、bwa-mem2のインデックスを構築する必要があります。おすすめの手順は次のとおりです。
- Broad Instituteのus-east-1 S3バケットにあるhg38 FASTAを、お好きなクラウドの大容量メモリVMへコピーする(AWSならr5.16xlarge、GCPならn2-highmem-64などが候補です)
- bwa-mem2をインストールする(または後述のコンテナイメージを利用する)
- bwa-mem2の参照インデックスを構築する(1〜2時間かかります)
- 出力ファイルをクラウドアカウント内の新しいバケットへアップロードする
# us-east-1のS3バケットにあるBroad Instituteのhg38参照ゲノム
s3://broad-references/hg38/v0/Homo_sapiens_assembly38.fasta# bwa-mem2インデックスを構築してバケットへ保存するコマンド例
YOUR_REF_BUCKET=<BUCKET_NAME_HERE># AWS・GCP共通:
aws s3 cp s3://broad-references/hg38/v0/Homo_sapiens_assembly38.fasta /tmp/reference/hg38.fastabwa-mem2 index -p hg38 /tmp/reference/hg38.fasta# AWSの場合:
aws s3 sync /tmp/reference/ s3://${YOUR_REF_BUCKET}/hg38/
# GCPの場合:
gsutil -m -o GSUtil:parallel_composite_upload_threshold=150M cp "/tmp/reference/hg38*" gs://${YOUR_REF_BUCKET}/hg38/
ここまで正しく進めば、バイオインフォマティクスワークフローのテストに使うFASTQ 2ファイル(生のゲノムシーケンスデータ)とhg38ヒト参照ゲノムが揃った状態になります。
Step 2: クラウドインフラの構築
Terraformを使って、フルマネージドなKubernetesクラスターの実行に必要なクラウドインフラを一式起動します。さらに、クラスター上で(kubectl経由で)いくつかのコマンドを実行し、ワークフロー実行用のKubernetesツールであるargo(バイオインフォマティクスパイプラインなどに利用)をクラスターへインストールします。
Terraformはデフォルトでは把握済みのクラウドインフラ状態をローカルに保持しますが、実運用ではバケットをTerraformのバックエンドとして利用します。こうすれば、社内の誰かがインフラを変更しても、全員が同じ最新の「正」のインフラ状態を参照しながら作業できます。
バケットをバックエンドにすると、ある変更セットを適用している間は他のインフラ変更がロックされるため、競合し得る複数のterraform apply操作が同時に走るのを防げます。バケット利用のTerraformバックエンドを有効にするには、クラウド環境にバケットを作成し、コードベース内のdoit-matt-tf-state-testをご自身のバケット名にすべて置換してください。
Terraformバックエンド用バケットの準備が整えば、いよいよインフラを起動できます。
Google Cloudでワークロードを動かしたい場合は、GCP/terraformに移動します。このフォルダ内にはstandardとautopilotというサブフォルダがあり、それぞれGKE StandardモードとAutopilotモードでGKEクラスターを起動するTFコードが入っています。Autopilotは、ノード(計算リソース)をサーバーレスモデルに近づけるだけでなく、各種のセキュリティのベストプラクティスを強制するため、一般的にはこちらが推奨されます。
残念ながら、本デモではAutopilotは利用できません。エフェメラルディスクが10 GiBに制限されており、実データに対するFastQCやbwa-mem2の実行には足りないためです。ただし、将来この制約が緩和されればStandardよりAutopilotを選ぶのが望ましいので、公開後に制限が緩和されるケースに備えてAutopilot用のTFコードも用意しています。AWS ECS Fargateにも200 GiBのディスク制限があり、ほとんどの実運用の科学計算用途には不十分です。FargateのTFコードはコードリポジトリでは扱っていません。
AWSでワークロードを実行したい場合は、AWS/terraformに移動してください。
クラウドごとのterraformフォルダに入ったら、次を実行します。
terraform apply -auto-approve# 何も作成せずに計画されたインフラ変更の一覧を確認したい場合は、まず 'terraform plan' を実行
これにより、フォルダ内の「.tf」ファイル群に基づく計画が作成され、即座に実行されてK8sクラスターと前提リソースが起動します。Terraformが尋ねてくるのはGCPプロジェクトIDかAWSアカウントIDだけです。
クラスターを起動するリージョンの変更、クラスター名の変更、GCPプロジェクトIDやAWSアカウントIDの変数のハードコーディングなどを行いたい場合は、apply実行前にvariables.tfを編集できます。
Terraformを学ぶためにも、ぜひコードを丁寧に読み込むことをおすすめします
理解を早めるために、GCPでは以下が作成されます。
- Compute、Container、IAMの各APIの有効化
- デフォルトVPC内に、最新のデフォルトKubernetesバージョン(公開時点でv1.20)を用いた自動スケーリング対応のGKE Standardクラスター。Workload Identity、Shielded Nodes、Secure Bootなど任意のセキュリティ機能を有効化。複数ゾーン(データセンター)にノードを分散したリージョナルクラスターです
- GCPサービスアカウント(SA)と、それに紐づくKubernetesサービスアカウント(KSA)。Workload Identityにより、特定のKubernetes namespace内で実行される全ジョブのGCP権限スコープを制限します。SA/KSAにはバケットの読み書き、およびCloud LoggingとCloud Metricsへの各種ログ・メトリクス書き込みが許可されます
- クラスターはプリエンプティブル/Spotインスタンスを利用。オンデマンド料金より大幅に安く済む代わりに、ノードが突然落ちて最終的に置き換えられる可能性があります。K8sはノードの突然の停止によるジョブ失敗を自動検知して再スケジュールします
AWSでは、ネットワークおよびセキュリティ関連で以下が作成されます。
- K8sクラスター専用の新しいVPC
- クラスターノード用のパブリック(未使用)・プライベートサブネットおよびルートテーブル
- NATゲートウェイ、S3およびECRのVPCエンドポイントとそれに紐づくTLS対応のセキュリティグループ、プライベートノードクラスターをサポートするためのDNSホスト名の有効化
- クラスターのコントロールプレーンへのパブリックアクセスを可能にするインターネットゲートウェイ
AWSではさらに、AWS/terraform/ecrに移動して再度terraform applyを実行する必要があります。このフォルダの.tfファイルでは以下が作成されます。
- 作成するコンテナイメージを格納するリポジトリ
(GCPではリポジトリの作成は不要です)
続いてAWS/terraform/eksに移動し、再度terraform applyを実行します。このフォルダの.tfファイルでは以下が作成されます。
- S3バケットへの読み書きアクセス、およびSSM Manager経由でのブラウザベース・キーレスSSHでのノード接続を可能にする、クラスター用IAMロール
- 最新のデフォルトKubernetesバージョン(公開時点でv1.21)を用いた自動スケーリング対応のEKSクラスター。Workload Identity、Shielded Nodes、Secure BootはEKSではすぐに使える機能ではありません。複数ゾーン(データセンター)にノードを分散したリージョナルクラスターです
- クラスターはプリエンプティブル/Spotインスタンスを利用。オンデマンド料金より大幅に安く済む代わりに、ノードが突然落ちて最終的に置き換えられる可能性があります。K8sはノードの突然の停止によるジョブ失敗を自動検知して再スケジュールします
terraform applyの一連の操作が完了すると、クラスターが稼働し、kubectlでKubernetes APIコマンドを発行できる状態になります。クラウドごとのコマンドでkubectlを認証するだけでOKです。
# GCPの場合:
gcloud container clusters get-credentials --region=us-central1 bioinformatics-tasks
# AWSの場合:
aws eks update-kubeconfig --name=bioinformatics-tasks
これで、kubectl get pods -Aで全namespaceにデプロイされたPod一覧を表示するなど、クラスターに対してさまざまなコマンドを実行できるようになります。
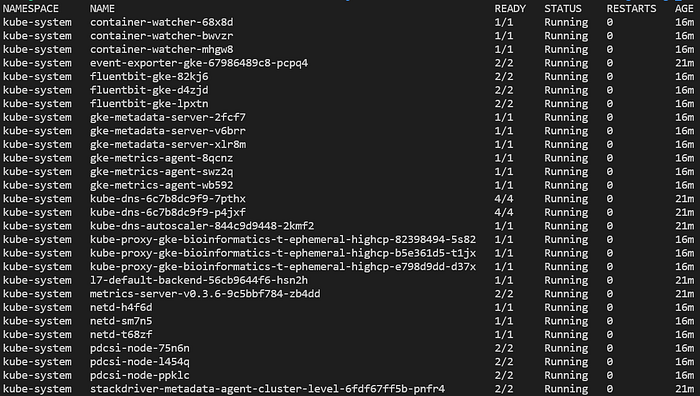
新規作成したフルマネージドGKE Standardクラスターでよく見られるPod群
クラスターが立ち上がったら、次はargoをクラスターへインストールします。argoがあれば、単発のタスクだけでなく、DAG型のワークフロー/タスクパイプラインを投入できるようになります。
GCPの場合はGCP/terraform/standard/kubectl_commandsに移動します。
AWSの場合はAWS/terraform/kubectl_commandsに移動します。
これらのフォルダでterraform apply -auto-approveを実行すると、Terraform管理下のkubectlコマンドが走り、次の処理が行われます。
- 「biojobs」namespaceを作成。ジョブはここに投入され、(GCPでは)バケット内オブジェクトの読み書きのみに権限スコープを制限します。
- argoをインストール。GCPではWorkload Identityを通じて、「biojobs」namespace内のPod進捗を監視するための適切にスコープされた権限を付与します。
namespaceが作成されargoがインストールされたかどうかは、全namespaceの一覧表示と、argo namespaceで稼働中のPodの確認で検証できます。
kubectl get ns
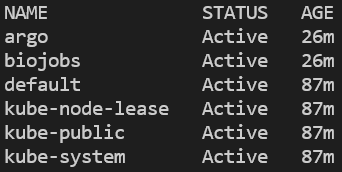
クラスター上の全namespace。EKSの場合は「amazon-cloudwatch」も含まれます。
kubectl get pods -n argo

「argo」namespaceで稼働中のArgoサーバーおよびワークフローコントローラーのPod
最後に、Kubernetes v1.19以降でコンテナランタイムがdockerからcontainerdへ切り替わった点にargoが対応するよう、次のコマンドを実行してください。argo側がいずれ修正してくれるので、この詳細を深追いする必要はありません。
kubectl patch configmap workflow-controller-configmap -n argo --patch ‘{"data":{"containerRuntimeExecutor":"k8sapi"}}’
argoがインストールされ、計算ノードも準備万端です。さあ、本番に取りかかりましょう!
Step 3: FastQCとbwa-mem2のコンテナイメージを構築する
AWSやGCPでFastQCとbwa-mem2のワークロードを動かすには、これらのツールのコンテナイメージを構築し、対応するクラウドのコンテナイメージリポジトリ(GCPはGCR、AWSはECR)へ保存する必要があります。
images/fastqc/に移動します。
このフォルダには、FastQCを、s5cmd(AWS S3⇔ローカル間の高速コピーツール)とgsutil(GCS⇔ローカル間のコピー用)とともにコンテナへパッケージングする方法を定義したDockerfileがあります。中身に目を通し、Dockerfileの構成についても学んでみましょう。少し脱線しますが、私が執筆したバケットへのデータ転送速度を最大化する方法に関する記事もご興味があれば。記事内で紹介している原則はDockerfileにも取り入れられています。
build_fastqc_image_gcp.shまたはbuild_fastqc_image_aws.shを実行すると、Dockerfileからコンテナイメージが作成され、それぞれGCRまたはECRへプッシュされます。
bwa-memのコンテナイメージを作成してGCRまたはECRへ保存する場合は、images/bwa-mem2/に移動して同じ手順でビルドスクリプトを実行してください。
このステップが完了すると、クラウド環境のイメージリポジトリに保存したコンテナイメージを介して、Kubernetesクラスター上でFastQCとbwa-mem2を実行できる状態になります。
Step 4: Kubernetesジョブの投入と監視
続いて、Kubernetesジョブ用のクラウド別フォルダへ移動し、いくつかジョブを起動してみます。最終的にはargoでパイプラインとしてFastQCとbwa-mem2をつなげて実行しますが、まずはこれらを単発で動かしてみます。
GCPの場合はGCP/gke/FastQC/に移動します。
AWSの場合はAWS/eks/FastQC/に移動します。
これらのフォルダ内に、fastqc.yamlというKubernetes Jobがあります。
このYAMLは、kubectl create -f fastqc.yamlで実行できるジョブを定義しています。ただしファイルにはいくつかの変数が含まれており、run_fastqc_job.sh内で定義・置換されることが前提です。Kubernetesのオブジェクト全般、特にJobについて理解を深めたうえでfastqc.yamlを読み解き、シェルスクリプトの動作も確認してみてください。
Kubernetesは、Deploymentと呼ばれる長時間稼働のPod(例:長期稼働のWebサーバー)を動かす用途で使われることが多いですが、Job(FastQCのような科学計算プログラムなど、一度きりの実行タスク)の実行にも使えます。本コードベースを通じて、Kubernetes Jobオブジェクトをクラスターへ投入していきます。
シェルスクリプトに変数INPUT_FILEPATHとOUTPUT_FILEPATHを渡すと、先ほど取得したFASTQファイルのいずれかを使ってFastQCジョブが起動され、最終的にzip圧縮されたレポートがバケットへ保存されます。あるいは、fastqc.yaml内の変数を手動で置き換えて、kubectl create -f fastqc.yamlでジョブを実行する方法でも構いません。
FastQCの進捗は次のコマンドで追えます: kubectl get pods -n biojobs
すると、Podが1つ起動し、まずコンテナイメージのプルを行い、その直後に指定したジョブが実行される様子がわかります。

FastQC Pod — ContainerCreatingステータス

FastQC Pod — Runningステータス
稼働中のアプリケーションログはkubectl logs -n biojobs <pod_name>で確認できます。
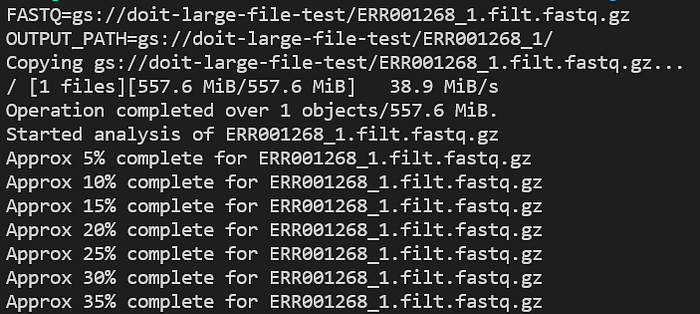
FastQC Podの進捗
コンテナ、そしてGKE/EKSは監視を前提に設計されているため、これらのログエントリはクラウドのネイティブなロギングソリューション内で簡単に見つけられ、長期保管や調査にも活用できます。
GCPのCloud LoggingやAWSのCloudWatchでcomplete forというフレーズを検索すれば、FastQC Podのログエントリを見つけられます。
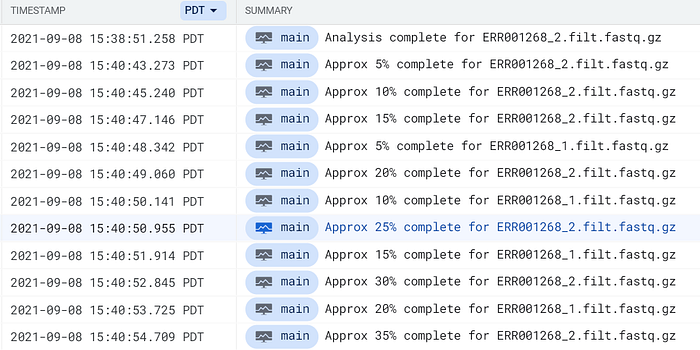
GCPのCloud Loggingに送られたFastQC Podのログ
しばらくすると、出力バケットのパスにFastQCレポートが届くはずです。両方のFASTQファイルに対してFastQC Podを実行し、それぞれのレポートを確認してみましょう。
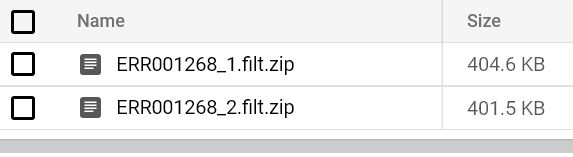
バケットに保存されたFastQCレポート
Kubernetes上でFastQCをスケールさせて動かす方法は、これだけです!
FastQCジョブを1つだけ走らせることも、一度に1万個走らせることも可能です。Kubernetesのコントロールプレーンと、それに連携するクラウド環境の計算ノード自動スケーリング機能が、FastQCのKubernetesオブジェクトYAMLで定義したCPU/メモリ/ディスク要件に基づいて、ワークロードの需要に合わせて計算容量を増減させてくれます。
クラスター作成時には、クラスターオートスケーラーで許可される最大ノード数/CPU/メモリの値が十分に大きい(あるいはコスト管理の観点から望ましい水準にある)ことを必ず確認しておきましょう。(GCP: gke.tf、AWS: cluster.tf)
同じくらい手軽に、bwa-mem2もコスト効率よく大規模に動かせます!
GCPの場合はGCP/gke/bwa-mem2/に移動します。
AWSの場合はAWS/eks/bwa-mem2/に移動します。
run_bwa-mem2_job.shの冒頭にある変数に入出力パスを指定すると、それらがbwa-mem2.yaml内の変数名に置換され、Jobがクラスターへ投入されます。
引き続きPodのステータスとログを監視し、出力バケットのパスにBAMファイルが書き出されるのを確認しましょう。
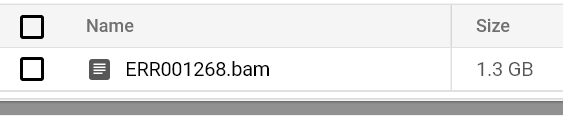
バケットに保存されたBAMファイル
クラスターを支えるGCE/EC2ノードのCPU使用率メトリクスを見ると、負荷の軽いシングルコアのFastQCジョブは小型のCPUマシンへ、全コアを使い切るBWAジョブは高CPUマシンへ投入されていることがわかります。これは、特性が大きく異なるそれぞれのワークロードを適切なサイズのマシンで支え、コスト効率よく自動スケールさせるために用意した、低CPUと高CPUのKubernetesノードグループに対応しています。
たとえばAWSでは、シングルコアのFastQCジョブを1つ走らせるためだけに96 vCPUのm5.24xlargeをスケールアップでプロビジョニングするのは合理的ではないため、FastQCは4 vCPUのm5.xlargeで構成されたノードグループへ投入します。一方、bwaは投入できるだけのコアを使い切るため、これらのジョブは96 vCPUのノードグループへ投入し、4 vCPU(FastQC)用ノードグループとは独立してスケールさせます。
生のシーケンスデータを処理してバリアントを検出するセカンダリ解析ワークフローを構築した経験のある方なら、Kubernetesの威力が見え始めているのではないでしょうか。次のような苦労はもう過去のものです。
- 大規模実行で動作が不安定になりがちなオンプレのジョブスケジューラ
- 一度に大量のジョブを投入したらジョブスケジューラ、あるいは自分(と他者)のワークロードを支えるクラスター自体が落ちないかと心配する状況
- 同僚が動かしたいワークロード用のオンプレ計算リソースを奪ってしまい、不興を買うこと
- 予期せぬとはいえ復旧可能な理由で失敗するワークロードを監視し、再起動する作業
- クラッシュしたジョブのログファイルを掘り起こすのに頭を抱える時間 — しかも、ろくにログ機能が整っていないアプリケーション相手に
あとは、ステップをつなぐスパゲッティコードのパイプラインさえ書かずに済めば言うことなしですよね…
Step 5: Argoワークフローの投入(Kubernetesジョブのパイプライン化)
Argoを使うと、ジョブを大規模でも安定して動作するパイプラインに組み立てつつ、想定外の失敗時にはジョブやパイプラインの再試行も行えます。
ここでは、argoを使って2つのFastQC Podを同時に走らせる方法をデモします。さらに、その2つのPodがどちらも成功した場合に限り、同じFASTQペアを使ってbwa-mem2によるアラインメントを起動します。
(個人的な演習として、FastQCイメージにpass/no-passのステップを追加し、FASTQの品質が低すぎてアラインメントを実行する価値がないと判断した場合に、このargoワークフロー内のBWAステップをスキップするようにしてみるのも面白いでしょう。)
GCPの場合はGCP/gke/argo_workflow/に移動します。
AWSの場合はAWS/eks/argo_workflow/に移動します。
run_fastqc_to_bwa.shの冒頭にある変数に入出力パスを指定すると、それらがfastqc_to_bwa.yaml内の変数名に置換され、Jobがクラスターへ投入されます。
kubectl get pods -n biojobsを繰り返し実行すると、FastQC Podが起動して完了し、その後にBWAジョブが起動される様子が確認できます。

NA12878のR1とR2 FASTQファイルに対して稼働中のFastQC Pod
…

2つのFastQC Podが完了した後に起動したbwa-mem2のアラインメントPod
bwa-mem2のPodを次のコマンドで覗いてみましょう:
kubectl logs -n biojobs <pod_name> main
(Pod名のあとに「main」が付いている点にご注意を。argoではワークフロー内のジョブごとに「main」と「wait」のPodログが存在します。)
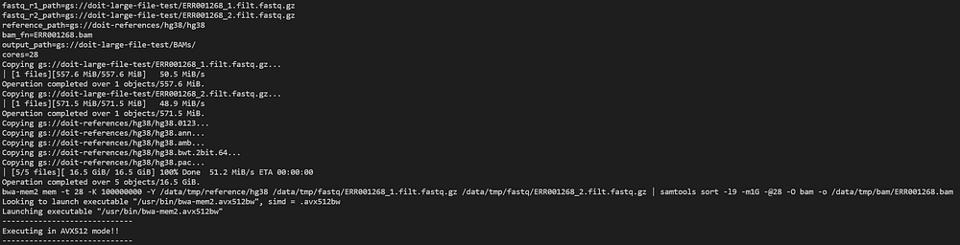
argoワークフローの一部として黙々と処理を進めるbwa-mem2
argoワークフローの進捗はkubectl get wf -n biojobsで監視できます。

BWAが完了するとワークフロー全体も完了し、出力バケットにはFastQCレポートのペアとBAMが揃っているはずです。
Step 6: 後片付け
BWAを動かすために、それなりに高価な計算インフラを立ち上げてきました。使わないのにこのGKE/EKSクラスターを残しておきたくはありません。
Terraformフォルダを逆順にたどって、次を実行するだけです。
terraform destroy -auto-approve
これは、Terraformのバックエンド用やFASTQ・参照ファイル保存用に手動で作成したバケットは削除しない点にご注意ください。Terraformは自身が起動したリソースの変更しか把握・監視できません。GCPでは、加えてGCR内のコンテナイメージも手動で削除する必要があります。
GCPの場合、destroyコマンドは次の順で実行します。
GCP/terraform/standard/kubectl_commands/
GCP/terraform/standard/
AWSの場合、destroyコマンドは次の順で実行します。
AWS/terraform/eks/kubectl_commands/
AWS/terraform/eks/
AWS/terraform/ecr/ (イメージリポジトリを削除したい場合)
AWS/terraform/
Step 7: 次のステップ
ここまで身につけたスキルがあれば、任意のアプリケーションを組み合わせた、どんな複雑さのパイプラインでも構築できます。あらゆるプログラムをコンテナ化できるからです。
バージョン管理されたコンテナイメージのコード、バージョンタグ付きのコンテナ、バージョン管理されたインフラとargoパイプラインを組み合わせれば、新しいソフトウェアやパイプラインのバージョンをデプロイし、旧バージョンを廃止し、不具合のあるデプロイ時には比較的容易にロールバックすることができます — 少なくとも代替手段と比べれば、ですが。この学習を続けていけば、その差はさらに広がるはずです。
次に何をするかはあなた次第ですが、現代的でスケーラブルな科学計算に必要な核心的スキルを、ここでお伝えできていれば幸いです。
クラウドにおいて、ベストプラクティスだけで到達できる地点には限界があります。高可用性、障害耐性、コスト最適化されたスケーラビリティを備えた構築は、今や非常に難しい仕事です。こうした追加のエンジニアリング作業は、ただでさえ膨らみ続けるワークロードの山に積み重なり、生産性に直接響いてきます。
21世紀の科学者にとって、スケーラビリティとデプロイのしやすさを意識したアプリケーション構築は不可欠です。これを怠れば、組織に頭痛の種を生むだけ。長期的には、これらの問題は雪だるま式に膨らみ、深刻で終わりの見えない本番運用の問題へと発展してしまいます。
このプロジェクトに刺激を受けつつも、少し圧倒されている方は、ぜひDoiT Internationalまでお気軽にご連絡ください。LinkedInで私に直接メッセージをいただいても構いません。
DoiTは、コスト最適化され、スケーラブルで、可用性が高く、障害に強く、ビッグデータ規模にも対応できるクラウドアーキテクチャへとお客様を導くことに誇りを持っています。このサービスは文字どおり無償で提供しています。当社がGoogle Cloudの2020 Global Reseller Partner of the Yearを受賞したのには、それだけの理由があります。
当社はトップクラスのエンジニアリング人材と手厚いカスタマーサポートにより、AWS Advanced Consulting Partnerであり続けながら、AmazonのPartner Network(APN)認定も獲得しています。クラウドに関するご質問への回答や継続的な課題解決に必要な情報は、すべてオンデマンドでお届けします。
お時間をいただきありがとうございました。本シリーズの2本の記事が、皆さまのスキルアップの一助になれば幸いです。スケールアップをお考えですか? ぜひお声がけください。目標達成をお手伝いします。
お読みいただきありがとうございました! 引き続き情報を受け取るには、DoiT Engineering Blog、DoiT LinkedInチャンネル、DoiT Twitterチャンネルをフォローしてください。キャリア機会についてはhttps://careers.doit-intl.comをご覧ください。