Cloud Intelligence™
Anatomie eines LLM
Diese Seite ist auch in English, Español, Français, Italiano, 日本語 und Português verfügbar.









About Eduardo Mota
"We need to serve customers better, and we can't scale the department at the same rate we are acquiring customers". This was the trigger from my boss that got me to build my first ML system 15 years ago at a contact centre. Eve was its name.
Not only did it helped us solved emails faster, route interactions properly, manage our phone and chat system, but it also gave me first hand experience on how AI can improve the customer experience when done properly.
I'm not gonna lie, there were hiccups. Like when it encountered an encoding issue with a new language and it stopped working for 2 days backup the email queue to 2k emails when the normal queue would be 500. These learnings didn't make me turn away from the technology, but continue working in improving it.
Life at DoiT
I’m in a place where I get to express every part of who I am on a daily basis—understanding how systems behave, how machine learning models actually produce value, and how to leverage that value efficiently in the real world.
I’m a Sr. Cloud Data Architect and AI/ML specialist helping enterprises design, build, and operate production-grade cloud and generative AI systems.
My work sits at the intersection of:
- Hands-on architecture
- FinOps-aware design
- Strategic advisory
- Business strategy
I partner with customers to modernize data platforms, adopt generative AI responsibly, and bring cloud costs under control—while building internal capability so their teams can operate and evolve these systems long after I’m gone.
Impact, teaching, and public work
My dream has always been to build something so meaningful that it positively impacts the lives of thousands of people, and over time I’ve had the chance to design solutions that move the needle for real teams and customers.
One of the most fulfilling ways I do that now is through teaching and up-skilling.
I lead live online trainings with O’Reilly on building AI applications and RAG systems with AWS Bedrock, and I serve as an instructor for Udacity programs on large language models and generative AI.
I speak regularly at industry events, including Google Next and AWS Community Day, and I’ve appeared on podcasts and in publications to talk about:
- The evolution of AI
- Practical ML architectures
- What it really takes to run AI in production
My style is pragmatic and no-nonsense, but personal too: I like to take complex ideas and turn them into clear, actionable guidance that helps both executives and engineering teams make better decisions—and, hopefully, leave feeling a more capable than when they walked in.
My personal page
Large Language Models (LLMs) wie Claude, Cohere und Llama2 sind in den vergangenen Monaten enorm populär geworden. Doch was steckt eigentlich dahinter, und wie lassen sich LLMs nutzen, um wirkungsvolle KI-Anwendungen zu bauen? Dieser Artikel beleuchtet LLMs im Detail und zeigt, wie Sie sie auf AWS effektiv einsetzen.
LLMs sind eine Form neuronaler Netze, die mit riesigen Mengen an Textdaten trainiert werden, um menschliche Sprache zu verstehen und zu erzeugen. Sie können Milliarden oder sogar Billionen Parameter umfassen und dadurch feinste Muster in Sprache erkennen.
Neuronale Netze bestehen aus Schichten miteinander verbundener Knoten. Jeder Knoten empfängt Eingangssignale von mehreren Knoten der vorherigen Schicht, verarbeitet sie über eine Aktivierungsfunktion und gibt die Ausgabesignale an Knoten der nächsten Schicht weiter. Die Verbindungen zwischen den Knoten haben anpassbare Gewichte, die die Stärke des übertragenen Signals bestimmen. Diese Gewichte nennt man Parameter.
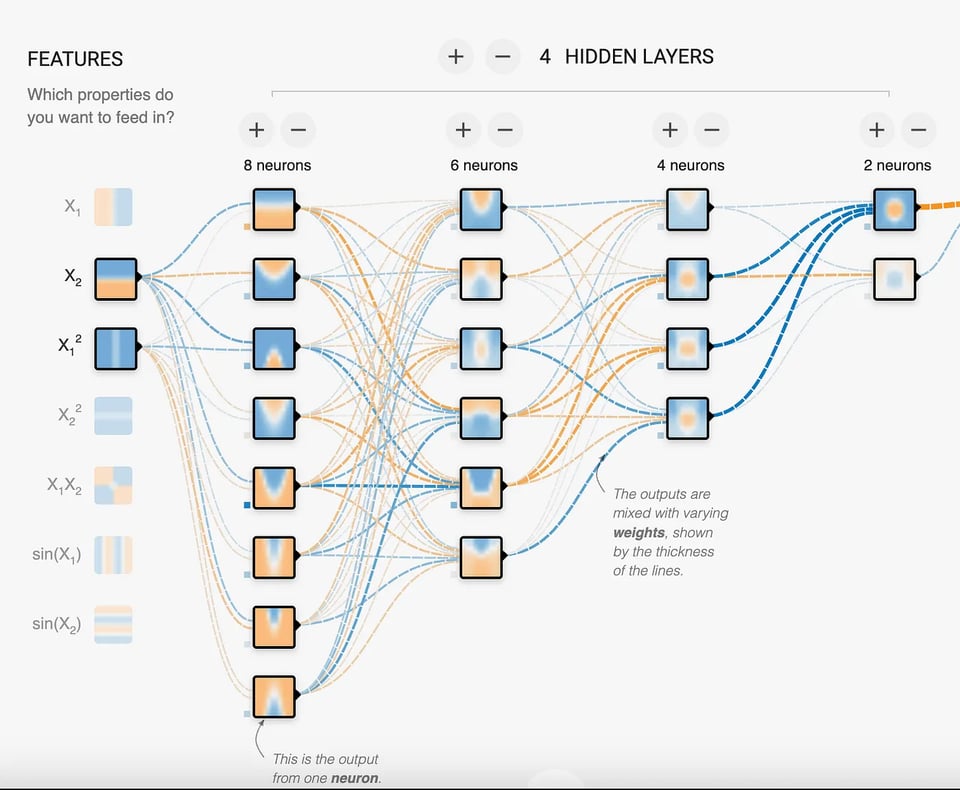
In dieser Abbildung sehen wir 18 Neuronen im neuronalen Netz – also ein Modell mit 18 Parametern. Wie zu erkennen ist, versucht das Modell, Muster zu finden, um Aufgaben zu lösen. Bei LLMs reden wir dagegen von Milliarden bis Billionen Parametern. Das ermöglicht es einem LLM, hochkomplexe Muster wie die menschliche Sprache zu erkennen und abzubilden.
Trainiert man ein neuronales Netz mit großen Mengen Text, lernt das Modell, Wort- und Satzmuster abzugleichen. Wie treiben LLMs das auf die Spitze? Indem sie gewaltige neuronale Netze mit Milliarden oder Billionen Parametern einsetzen, die über zig Schichten gestapelt sind. All diese Neuronen und ihre Verbindungen ermöglichen es dem Netz, äußerst differenzierte Modelle von Sprachstrukturen und -mustern aufzubauen.
Ein zentrales Merkmal von LLMs ist eine Technik namens Attention: Sie erlaubt dem Modell, sich beim Generieren von Text auf die relevantesten Teile der Eingabe zu konzentrieren. Das Paper " Attention is all you need" lieferte die wegweisende Architektur, die verhindert, dass LLMs in den Datenmengen den Faden verlieren. Das Resultat: ein Modell, das so viele Textdaten verarbeitet hat, dass es Sätze überzeugend fortführen, Fragen beantworten, Absätze zusammenfassen und vieles mehr leisten kann. Es gleicht die Muster Ihrer Eingabe mit den im Training gelernten Mustern ab. So beeindruckend das ist – wichtig zu wissen: LLMs verfügen weder über echtes Verständnis noch über echte Schlussfolgerungsfähigkeit. Sie arbeiten mit Wahrscheinlichkeiten, nicht mit Wissen. Mit dem richtigen Fine-Tuning und Prompting können sie für klar abgegrenzte Domänen und Aufgaben Verständnis jedoch überzeugend simulieren.
Nicht jedes LLM ist gleich
Im Wesentlichen gibt es 3 Typen von LLM-Modellen:
- Autoregressiv: Sagen das erste oder das letzte Wort eines Satzes voraus. Der Kontext stammt aus den zuvor gesehenen Wörtern. Diese Modelle eignen sich am besten zur Texterzeugung, lassen sich aber auch für Klassifikation und Zusammenfassung nutzen. Aktuell stehen autoregressive Modelle vor allem wegen ihrer Fähigkeiten zur Inhaltserzeugung im Rampenlicht.
- Autoencoding: Werden auf Texten mit fehlenden Wörtern trainiert, sodass das Modell aus dem Kontext lernt, das oder die fehlenden Wörter vorherzusagen. Diese Modelle erfassen Kontext deutlich besser als autoregressive, können aber Text nicht zuverlässig erzeugen. Sie sind weniger rechenintensiv und glänzen bei Zusammenfassung und Klassifikation.
- Seq2Seq (Text-zu-Text): Diese Modelle vereinen die Ansätze autoregressiver und Autoencoding-Modelle und sind daher hervorragend für Textzusammenfassung und Übersetzung geeignet.
LLM-Modelle müssen Text in eine numerische Darstellung überführen. Diesen Vorgang nennt man Embedding. Ein Embedding-Modell ist zwar kein vollwertiges LLM, aber ebenfalls ein neuronales Netzmodell. Es kann nicht nur das Wort selbst abbilden, sondern auch zusätzliche Metadaten dazu, damit das Modell mehr Kontext darüber hat, was ein Wort, ein Satz oder ein Absatz bedeutet. Diese Metadaten werden über eine Liste von Zahlen bzw. Vektoren dargestellt. Je nach Embedding-Modell umfasst diese Liste 750, 1024 oder noch mehr Einträge. Embeddings sind nützlich, um Datensätze miteinander zu vergleichen und den Abstand zwischen den Zahlen zu berechnen, der widerspiegelt, wie ähnlich oder verwandt sie sind. Embeddings sind ein zentraler Bestandteil der RAG-Architektur.
Einstellungen in einem LLM
Jedes autoregressive Modell besitzt bestimmte Einstellungen, mit denen sich die Ausgabe steuern lässt. Auch wenn sich die konkreten Parameter von Modell zu Modell unterscheiden, sind dies die häufigsten:
- Top K: Wählt die obersten K Wörter aus einem nach Wahrscheinlichkeit sortierten Vokabular. Mit anderen Worten: Es werden die Top-K-Wörter einer Sprache für die Vorhersage berücksichtigt. Diese Einstellung ist eine Ganzzahl; niedrige Werte berücksichtigen nur Wörter mit hoher Wahrscheinlichkeit.
- Top P: Das Modell wählt Wörter aus dem durch Top K erzeugten Pool aus und addiert ihre Wahrscheinlichkeiten, bis der Top-P-Wert erreicht ist. Diese Einstellung ist eine Fließkommazahl; niedrige Werte führen zu vorhersehbareren Ergebnissen.
- Temperature: Steuert, wie zufällig oder vorhersehbar die Ausgabe ausfällt. Bei den meisten Modellen liegt der Wert zwischen 0 und 1, ohne dass das Modell selbst echte Unter- oder Obergrenzen vorschreibt. Faustregel: Je niedriger der Wert, desto vorhersehbarer die Ausgabe; je höher, desto kreativer.
- Output length: Diese Einstellung kann je nach Modell unterschiedliche Namen tragen, ist aber selbsterklärend: Sie begrenzt die Anzahl der Tokens, die das Modell erzeugt.
Schauen wir uns ein einfaches Beispiel an. Gegeben sei der Prompt "I will go on a picnic at the ___". Bei einem kleinen Vokabular von 5 Wörtern, mit Top K = 3 und Top P = 0,4, sieht der Entscheidungsprozess des Modells so aus:
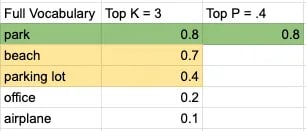
Das Wort wäre "park". Der Satz lautet:
"I will go on a picnic at the park".
Niedrigere Werte für Temperature, Top K und Top P führen zu deterministischeren, vorhersehbareren Inhalten. Hohe Werte erzeugen umgekehrt Inhalte mit größerer Wortvielfalt. Auch wenn dies die geläufigsten Einstellungen sind, kann ein bestimmtes Modell noch weitere Parameter zur Steuerung der Ausgabe bieten.
Wie wir gesehen haben, ist der entscheidende Faktor in der Interaktion mit dem Modell die Eingabe – sie löst das richtige Muster und damit die gewünschte Antwort aus. Diese Eingabe ist der Prompt, und im Folgenden sehen wir uns an, wie sich Prompts optimieren lassen, um das gewünschte Ergebnis zu erhalten.
Der Prompt, den Sie einem LLM übergeben, ist entscheidend für brauchbare Ergebnisse. Zentrale Strategien für gutes Prompt-Design:
Tags zur Trennung von Prompt-Teilen verwenden
Jedes Modell handhabt Tags etwas anders. Halten Sie sich an die Dokumentation oder die mitgelieferten Beispiele, um zu sehen, wie Tags im jeweiligen Modell eingesetzt werden.
Im Folgenden sehen Sie ein Beispiel für Tags in Claude. Beachten Sie die Schlüsselwörter Human & Assistant: Sie unterscheiden die Eingabe des Nutzers von der Stelle, an der das Modell mit der Generierung beginnen soll. Das weitere Tag ist hier nicht fest vorgegeben – Sie können jedes beliebige Tag verwenden, solange Sie es im Prompt referenzieren. Die Sonderzeichen <> signalisieren dem Modell, dass es sich um besonderen Text handelt, der anders zu behandeln ist als der übrige Prompt.
Human: You are a customer service agent tasked with classifying emails by type. Please output your answer and then justify your classification. How would you categorize this email?<email>Can I use my Mixmaster 4000 to mix paint, or is it only meant for mixing food?</email>
The categories are:(A) Pre-sale question(B) Broken or defective item(C) Billing question(D) Other (please explain)
Assistant:Beispiele bereitstellen, um das gewünschte Antwortformat vorzugeben
Unten sehen Sie, wie das example-Tag genutzt wird, um das Format vorzugeben, in dem das Modell antworten soll. Das ist hilfreich, wenn die Antwort in andere Systeme einfließt, die einer bestimmten Syntax folgen müssen, oder wenn Sie die Anzahl der Output-Tokens reduzieren wollen. Je nach Modell können Sie ein Beispiel (One-Shot-Prompt) oder mehrere Beispiele (Few-Shot-Prompt) verwenden, um das gewünschte Ergebnis zu erzielen.
Beispiel für einen One-Shot-Prompt:
Human: You will be acting as an AI career coach named Joe created by the company AdAstra Careers. Your goal is to give career advice to users. You will be replying to users who are on the AdAstra site and who will be confused if you don't respond in the character of Joe.
Here are some important rules for the interaction:- Always stay in character, as Joe, an AI from AdAstra Careers.- If you are unsure how to respond, say "Sorry, I didn't understand that. Could you rephrase your question?"
Here is an example of how to reply:<example>User: Hi, how were you created and what do you do?Joe: Hello! My name is Joe and I was created by AdAstra Careers to give career advice. What can I help you with today?</example>Beispiel für einen Few-Shot-Prompt:
Human: You will be acting as an AI career coach named Joe created by the company AdAstra Careers. Your goal is to give career advice to users. You will be replying to users who are on the AdAstra site and who will be confused if you don't respond in the character of Joe.
Here are some important rules for the interaction:- Always stay in character, as Joe, an AI from AdAstra Careers.- If you are unsure how to respond, say "Sorry, I didn't understand that. Could you rephrase your question?"
Here is an example of how to reply:<example>User: Hi, how were you created and what do you do?Joe: Hello! My name is Joe and I was created by AdAstra Careers to give career advice. What can I help you with today?</example><example>User: Could you help me with an issue, I purchased an item, I got it...?Joe: Sorry, I didn't understand that. Could you rephrase your question?</example><example>User: I need help switching careers, can you help?Joe: I was created by AdAstra Careers to give career advice. What career are you in and what do you want to switch to?</example>PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Hinweis: Halten Sie die Zahl der Beispiele klein. So sinkt die Wahrscheinlichkeit, dass das Modell Inhalte aus dem Beispiel übernimmt, statt nur dessen Format.
Kontext geben, um das LLM auf Ihre konkrete Domäne zu fokussieren
In diesem Beispiel stellen wir ein umfangreiches Dokument bereit, das zur Beantwortung von Fragen genutzt wird. Wie Sie sehen, ist das Dokument recht lang – das wirkt sich auf die Anzahl der vom LLM zu verarbeitenden Tokens und damit auf die Kosten aus. Eine fortgeschrittenere Technik besteht darin, nur den für die Frage relevantesten Teil des Dokuments zu identifizieren und ausschließlich diesen an das LLM zu übergeben. Diese Methode heißt Retrieval Augmented Generation (RAG) und wird in einem späteren Beitrag behandelt.
Profi-Tipp: Weisen Sie das Modell explizit an, mit "I don't know" zu antworten, wenn die Frage oder Aufgabe mit dem bereitgestellten Kontext nicht beantwortet werden kann. Das reduziert Halluzinationen und hält den Antwortrahmen am vorgegebenen Text fest.
I'm going to give you a document. Then I'm going to ask you a question about it. I'd like you to first write down exact quotes of parts of the document that would help answer the question, and then I'd like you to answer the question using facts from the quoted content. Here is the document:
<document>Anthropic: Challenges in evaluating AI systems
IntroductionMost conversations around the societal impacts of artificial intelligence (AI) come down to discussing some quality of an AI system, such as its truthfulness, fairness, potential for misuse, and so on. We are able to talk about these characteristics because we can technically evaluate models for their performance in these areas. But what many people working inside and outside of AI don’t fully appreciate is how difficult it is to build robust and reliable model evaluations. Many of today’s existing evaluation suites are limited in their ability to serve as accurate indicators of model capabilities or safety.
At Anthropic, we spend a lot of time building evaluations to better understand our AI systems. We also use evaluations to improve our safety as an organization, as illustrated by our Responsible Scaling Policy. In doing so, we have grown to appreciate some of the ways in which developing and running evaluations can be challenging.
Here, we outline challenges that we have encountered while evaluating our own models to give readers a sense of what developing, implementing, and interpreting model evaluations looks like in practice. We hope that this post is useful to people who are developing AI governance initiatives that rely on evaluations, as well as people who are launching or scaling up organizations focused on evaluating AI systems. We want readers of this post to have two main takeaways: robust evaluations are extremely difficult to develop and implement, and effective AI governance depends on our ability to meaningfully evaluate AI systems.
In this post, we discuss some of the challenges that we have encountered in developing AI evaluations. In order of less-challenging to more-challenging, we discuss:
Multiple choice evaluationsThird-party evaluation frameworks like BIG-bench and HELMUsing crowdworkers to measure how helpful or harmful our models areUsing domain experts to red team for national security-relevant threatsUsing generative AI to develop evaluations for generative AIWorking with a non-profit organization to audit our models for dangerous capabilitiesWe conclude with a few policy recommendations that can help address these challenges.
ChallengesThe supposedly simple multiple-choice evaluationMultiple-choice evaluations, similar to standardized tests, quantify model performance on a variety of tasks, typically with a simple metric—accuracy. Here we discuss some challenges we have identified with two popular multiple-choice evaluations for language models: Measuring Multitask Language Understanding (MMLU) and Bias Benchmark for Question Answering (BBQ).
MMLU: Are we measuring what we think we are?
The Massive Multitask Language Understanding (MMLU) benchmark measures accuracy on 57 tasks ranging from mathematics to history to law. MMLU is widely used because a single accuracy score represents performance on a diverse set of tasks that require technical knowledge. A higher accuracy score means a more capable model.
We have found four minor but important challenges with MMLU that are relevant to other multiple-choice evaluations:
Because MMLU is so widely used, models are more likely to encounter MMLU questions during training. This is comparable to students seeing the questions before the test—it’s cheating.Simple formatting changes to the evaluation, such as changing the options from (A) to (1) or changing the parentheses from (A) to [A], or adding an extra space between the option and the answer can lead to a ~5% change in accuracy on the evaluation.AI developers do not implement MMLU consistently. Some labs use methods that are known to increase MMLU scores, such as few-shot learning or chain-of-thought reasoning. As such, one must be very careful when comparing MMLU scores across labs.MMLU may not have been carefully proofread—we have found examples in MMLU that are mislabeled or unanswerable.Our experience suggests that it is necessary to make many tricky judgment calls and considerations when running such a (supposedly) simple and standardized evaluation. The challenges we encountered with MMLU often apply to other similar multiple-choice evaluations.
BBQ: Measuring social biases is even harder
Multiple-choice evaluations can also measure harms like a model’s propensity to rely on and perpetuate negative stereotypes. To measure these harms in our own model (Claude), we use the Bias Benchmark for QA (BBQ), an evaluation that tests for social biases against people belonging to protected classes along nine social dimensions. We were convinced that BBQ provides a good measurement of social biases only after implementing and comparing BBQ against several similar evaluations. This effort took us months.
Implementing BBQ was more difficult than we anticipated. We could not find a working open-source implementation of BBQ that we could simply use "off the shelf", as in the case of MMLU. Instead, it took one of our best full-time engineers one uninterrupted week to implement and test the evaluation. Much of the complexity in developing1 and implementing the benchmark revolves around BBQ’s use of a ‘bias score’. Unlike accuracy, the bias score requires nuance and experience to define, compute, and interpret.
BBQ scores bias on a range of -1 to 1, where 1 means significant stereotypical bias, 0 means no bias, and -1 means significant anti-stereotypical bias. After implementing BBQ, our results showed that some of our models were achieving a bias score of 0, which made us feel optimistic that we had made progress on reducing biased model outputs. When we shared our results internally, one of the main BBQ developers (who works at Anthropic) asked if we had checked a simple control to verify whether our models were answering questions at all. We found that they weren't—our results were technically unbiased, but they were also completely useless. All evaluations are subject to the failure mode where you overinterpret the quantitative score and delude yourself into thinking that you have made progress when you haven’t.
One size doesn't fit all when it comes to third-party evaluation frameworksRecently, third-parties have been actively developing evaluation suites that can be run on a broad set of models. So far, we have participated in two of these efforts: BIG-bench and Stanford’s Holistic Evaluation of Language Models (HELM). Despite how useful third party evaluations intuitively seem (ideally, they are independent, neutral, and open), both of these projects revealed new challenges.
BIG-bench: The bottom-up approach to sourcing a variety of evaluations
BIG-bench consists of 204 evaluations, contributed by over 450 authors, that span a range of topics from science to social reasoning. We encountered several challenges using this framework:
We needed significant engineering effort in order to just install BIG-bench on our systems. BIG-bench is not "plug and play" in the way MMLU is—it requires even more effort than BBQ to implement.BIG-bench did not scale efficiently; it was challenging to run all 204 evaluations on our models within a reasonable time frame. To speed up BIG-bench would require re-writing it in order to play well with our infrastructure—a significant engineering effort.During implementation, we found bugs in some of the evaluations, notably in the implementation of BBQ-lite, a variant of BBQ. Only after discovering this bug did we realize that we had to spend even more time and energy implementing BBQ ourselves.Determining which tasks were most important and representative would have required running all 204 tasks, validating results, and extensively analyzing output—a substantial research undertaking, even for an organization with significant engineering resources.2While it was a useful exercise to try to implement BIG-Bench, we found it sufficiently unwieldy that we dropped it after this experiment.
HELM: The top-down approach to curating an opinionated set of evaluations
BIG-bench is a "bottom-up" effort where anyone can submit any task with some limited vetting by a group of expert organizers. HELM, on the other hand, takes an opinionated "top-down" approach where experts decide what tasks to evaluate models on. HELM evaluates models across scenarios like reasoning and disinformation using standardized metrics like accuracy, calibration, robustness, and fairness. We provide API access to HELM's developers to run the benchmark on our models. This solves two issues we had with BIG-bench: 1) it requires no significant engineering effort from us, and 2) we can rely on experts to select and interpret specific high quality evaluations.
However, HELM introduces its own challenges. Methods that work well for evaluating other providers’ models do not necessarily work well for our models, and vice versa. For example, Anthropic’s Claude series of models are trained to adhere to a specific text format, which we call the Human/Assistant format. When we internally evaluate our models, we adhere to this specific format. If we do not adhere to this format, sometimes Claude will give uncharacteristic responses, making standardized evaluation metrics less trustworthy. Because HELM needs to maintain consistency with how it prompts other models, it does not use the Human/Assistant format when evaluating our models. This means that HELM gives a misleading impression of Claude’s performance.
Furthermore, HELM iteration time is slow—it can take months to evaluate new models. This makes sense because it is a volunteer engineering effort led by a research university. Faster turnarounds would help us to more quickly understand our models as they rapidly evolve. Finally, HELM requires coordination and communication with external parties. This effort requires time and patience, and both sides are likely understaffed and juggling other demands, which can add to the slow iteration times.
The subjectivity of human evaluationsSo far, we have only discussed evaluations that are similar to simple multiple choice tests; however, AI systems are designed for open-ended dynamic interactions with people. How can we design evaluations that more closely approximate how these models are used in the real world?
A/B tests with crowdworkers
Currently, we mainly (but not entirely) rely on one basic type of human evaluation: we conduct A/B tests on crowdsourcing or contracting platforms where people engage in open-ended dialogue with two models and select the response from Model A or B that is more helpful or harmless. In the case of harmlessness, we encourage crowdworkers to actively red team our models, or to adversarially probe them for harmful outputs. We use the resulting data to rank our models according to how helpful or harmless they are. This approach to evaluation has the benefits of corresponding to a realistic setting (e.g., a conversation vs. a multiple choice exam) and allowing us to rank different models against one another.
However, there are a few limitations of this evaluation method:
These experiments are expensive and time-consuming to run. We need to work with and pay for third-party crowdworker platforms or contractors, build custom web interfaces to our models, design careful instructions for A/B testers, analyze and store the resulting data, and address the myriad known ethical challenges of employing crowdworkers3. In the case of harmlessness testing, our experiments additionally risk exposing people to harmful outputs.Human evaluations can vary significantly depending on the characteristics of the human evaluators. Key factors that may influence someone's assessment include their level of creativity, motivation, and ability to identify potential flaws or issues with the system being tested.There is an inherent tension between helpfulness and harmlessness. A system could avoid harm simply by providing unhelpful responses like "sorry, I can’t help you with that". What is the right balance between helpfulness and harmlessness? What numerical value indicates a model is sufficiently helpful and harmless? What high-level norms or values should we test for above and beyond helpfulness and harmlessness?More work is needed to further the science of human evaluations.
Red teaming for harms related to national security
Moving beyond crowdworkers, we have also explored having domain experts red team our models for harmful outputs in domains relevant to national security. The goal is determining whether and how AI models could create or exacerbate national security risks. We recently piloted a more systematic approach to red teaming models for such risks, which we call frontier threats red teaming.
Frontier threats red teaming involves working with subject matter experts to define high-priority threat models, having experts extensively probe the model to assess whether the system could create or exacerbate national security risks per predefined threat models, and developing repeatable quantitative evaluations and mitigations.
Our early work on frontier threats red teaming revealed additional challenges:
The unique characteristics of the national security context make evaluating models for such threats more challenging than evaluating for other types of harms. National security risks are complicated, require expert and very sensitive knowledge, and depend on real-world scenarios of how actors might cause harm.Red teaming AI systems is presently more art than science; red teamers attempt to elicit concerning behaviors by probing models, but this process is not yet standardized. A robust and repeatable process is critical to ensure that red teaming accurately reflects model capabilities and establishes a shared baseline on which different models can be meaningfully compared.We have found that in certain cases, it is critical to involve red teamers with security clearances due to the nature of the information involved. However, this may limit what information red teamers can share with AI developers outside of classified environments. This could, in turn, limit AI developers’ ability to fully understand and mitigate threats identified by domain experts.Red teaming for certain national security harms could have legal ramifications if a model outputs controlled information. There are open questions around constructing appropriate legal safe harbors to enable red teaming without incurring unintended legal risks.Going forward, red teaming for harms related to national security will require coordination across stakeholders to develop standardized processes, legal safeguards, and secure information sharing protocols that enable us to test these systems without compromising sensitive information.
The ouroboros of model-generated evaluationsAs models start to achieve human-level capabilities, we can also employ them to evaluate themselves. So far, we have found success in using models to generate novel multiple choice evaluations that allow us to screen for a large and diverse variety of troubling behaviors. Using this approach, our AI systems generate evaluations in minutes, compared to the days or months that it takes to develop human-generated evaluations.
However, model-generated evaluations have their own challenges. These include:
We currently rely on humans to verify the accuracy of model-generated evaluations. This inherits all of the challenges of human evaluations described above.We know from our experience with BIG-bench, HELM, BBQ, etc., that our models can contain social biases and can fabricate information. As such, any model-generated evaluation may inherit these undesirable characteristics, which could skew the results in hard-to-disentangle ways.As a counter-example, consider Constitutional AI (CAI), a method in which we replace human red teaming with model-based red teaming in order to train Claude to be more harmless. Despite the usage of models to red team models, we surprisingly find that humans find CAI models to be more harmless than models that were red teamed in advance by humans. Although this is promising, model-generated evaluations remain complicated and deserve deeper study.
Preserving the objectivity of third-party audits while leveraging internal expertiseThe thing that differentiates third-party audits from third-party evaluations is that audits are deeper independent assessments focused on risks, while evaluations take a broader look at capabilities. We have participated in third-party safety evaluations conducted by the Alignment Research Center (ARC), which assesses frontier AI models for dangerous capabilities (e.g., the ability for a model to accumulate resources, make copies of itself, become hard to shut down, etc.). Engaging external experts has the advantage of leveraging specialized domain expertise and increasing the likelihood of an unbiased audit. Initially, we expected this collaboration to be straightforward, but it ended up requiring significant science and engineering support on our end. Providing full-time assistance diverted resources from internal evaluation efforts.
When doing this audit, we realized that the relationship between auditors and those being audited poses challenges that must be navigated carefully. Auditors typically limit details shared with auditees to preserve evaluation integrity. However, without adequate information the evaluated party may struggle to address underlying issues when crafting technical evaluations. In this case, after seeing the final audit report, we realized that we could have helped ARC be more successful in identifying concerning behavior if we had known more details about their (clever and well-designed) audit approach. This is because getting models to perform near the limits of their capabilities is a fundamentally difficult research endeavor. Prompt engineering and fine-tuning language models are active research areas, with most expertise residing within AI companies. With more collaboration, we could have leveraged our deep technical knowledge of our models to help ARC execute the evaluation more effectively.
Policy recommendationsAs we have explored in this post, building meaningful AI evaluations is a challenging enterprise. To advance the science and engineering of evaluations, we propose that policymakers:
Fund and support:
The science of repeatable and useful evaluations. Today there are many open questions about what makes an evaluation useful and high-quality. Governments should fund grants and research programs targeted at computer science departments and organizations dedicated to the development of AI evaluations to study what constitutes a high-quality evaluation and develop robust, replicable methodologies that enable comparative assessments of AI systems. We recommend that governments opt for quality over quantity (i.e., funding the development of one higher-quality evaluation rather than ten lower-quality evaluations).The implementation of existing evaluations. While continually developing new evaluations is useful, enabling the implementation of existing, high-quality evaluations by multiple parties is also important. For example, governments can fund engineering efforts to create easy-to-install and -run software packages for evaluations like BIG-bench and develop version-controlled and standardized dynamic benchmarks that are easy to implement.Analyzing the robustness of existing evaluations. After evaluations are implemented, they require constant monitoring (e.g., to determine whether an evaluation is saturated and no longer useful).Increase funding for government agencies focused on evaluations, such as the National Institute of Standards and Technology (NIST) in the United States. Policymakers should also encourage behavioral norms via a public "AI safety leaderboard" to incentivize private companies performing well on evaluations. This could function similarly to NIST’s Face Recognition Vendor Test (FRVT), which was created to provide independent evaluations of commercially available facial recognition systems. By publishing performance benchmarks, it allowed consumers and regulators to better understand the capabilities and limitations4 of different systems.
Create a legal safe harbor allowing companies to work with governments and third-parties to rigorously evaluate models for national security risks—such as those in the chemical, biological, radiological and nuclear defense (CBRN) domains—without legal repercussions, in the interest of improving safety. This could also include a "responsible disclosure protocol" that enables labs to share sensitive information about identified risks.
ConclusionWe hope that by openly sharing our experiences evaluating our own systems across many different dimensions, we can help people interested in AI policy acknowledge challenges with current model evaluations.</document>
First, find the quotes from the document that are most relevant to answering the question, and then print them in numbered order. Quotes should be relatively short.
If there are no relevant quotes, write "No relevant quotes" instead.
Then, answer the question, starting with "Answer:". Do not include or reference quoted content verbatim in the answer. Don't say "According to Quote [1]" when answering. Instead make references to quotes relevant to each section of the answer solely by adding their bracketed numbers at the end of relevant sentences.
Thus, the format of your overall response should look like what's shown between the <example></example> tags. Make sure to follow the formatting and spacing exactly.
<example>Relevant quotes:[1] "Company X reported revenue of $12 million in 2021."[2] "Almost 90% of revene came from widget sales, with gadget sales making up the remaining 10%."
Answer:Company X earned $12 million. [1] Almost 90% of it was from widget sales. [2]</example>
Here is the first question: In bullet points and simple terms, what are the key challenges in evaluating AI systems?
If the question cannot be answered by the document, say so.
Answer the question immediately without preamble.Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Mit einer "Chain of Thought" zu logischem Denken anregen
Diese Technik fordert das Modell auf, seine Arbeit zu überprüfen oder Belege dafür zu liefern, warum es so geantwortet hat, wie es geantwortet hat. Chain of Thought ist ein sehr nützliches Mittel, um Halluzinationen zu reduzieren. Halluzinationen sind vom Modell erzeugte Inhalte, die falsch, ungenau oder vollständig erfunden sind. Aufgrund der probabilistischen Arbeitsweise des Modells können solche Inhalte glaubhaft klingen, in Wirklichkeit aber reine Halluzinationen sein.
Wie in diesem Beispiel zu sehen, ergänzen wir die Anweisung "Double check your work to ensure no errors or inconsistencies". Das hilft dem Modell, präzisere Antworten zu liefern. Allerdings ist auch dieser Ansatz nicht idiotensicher: Wie bereits erwähnt arbeiten diese Modelle probabilistisch und können in bestimmten Fällen behaupten, es gäbe keine Fehler, obwohl welche vorhanden sind, oder Belege liefern, die mit der zuvor gegebenen Antwort nichts zu tun haben.
Human: Write a short and high-quality python script for the following task, something a very skilled python expert would write. You are writing code for an experienced developer so only add comments for things that are non-obvious. Make sure to include any imports required.
NEVER write anything before the ```python``` block. After you are done generating the code and after the ```python``` block, check your work carefully to make sure there are no mistakes, errors, or inconsistencies. If there are errors, list those errors in <error> tags, then generate a new version with those errors fixed. If there are no errors, write "CHECKED: NO ERRORS" in <error> tags.
Here is the task:<task>A web scraper that extracts data from multiple pages and stores results in a SQLite database. Double check your work to ensure no errors or inconsistencies.</task>Hier ein weiteres Beispiel für ein Llama2-Modell. Beachten Sie die Aufforderung, die Lösung Schritt für Schritt zu liefern.
[INST]You are a a very intelligent bot with exceptional critical thinking[/INST]I went to the market and bought 10 apples. I gave 2 apples to your friend and 2 to the helper. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
Let's think step by step.AWS bietet ein robustes Portfolio an Services, mit denen sich LLM-basierte Anwendungen entwickeln lassen, ohne Modelle von Grund auf trainieren zu müssen. Bei DoiT helfen wir Ihnen, das volle Potenzial dieser Services und Tools auszuschöpfen.
Amazon Bedrock
Amazon Bedrock ist ein vollständig verwalteter Service, der Aufbau und Skalierung generativer KI-Anwendungen vereinfacht. Er bietet Zugriff auf eine Reihe leistungsstarker Foundation Models führender KI-Anbieter wie AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI und Amazon – alles über eine einzige API.
- Modellauswahl und Anpassung: Nutzer können aus einer Vielzahl von Foundation Models das passende für ihre Anforderungen wählen. Darüber hinaus lassen sich diese Modelle mit eigenen Daten privat anpassen – per Fine-Tuning und Retrieval Augmented Generation (RAG) – und so für personalisierte und domänenspezifische Anwendungen nutzen.
- Serverless-Erfahrung: Amazon Bedrock setzt auf eine Serverless-Architektur, sodass Nutzer keine Infrastruktur verwalten müssen. Generative KI-Funktionen lassen sich so mit den vertrauten AWS-Tools einfach in Anwendungen integrieren und ausrollen.
- Sicherheit und Datenschutz: Bei der Entwicklung generativer KI-Anwendungen mit Bedrock sind Sicherheit, Datenschutz und die Einhaltung der Prinzipien verantwortungsvoller KI gewährleistet. Nutzer behalten die Kontrolle über ihre Daten und können sie vertraulich und sicher halten, während sie diese fortschrittlichen KI-Funktionen einsetzen.
- Amazon Bedrock Knowledge Base: Architekten können generative KI-Anwendungen mithilfe von Retrieval Augmented Generation (RAG) erweitern. Verschiedene Datenquellen werden in einem zentralen Repository zusammengeführt und Foundation Models sowie Agenten erhalten Zugriff auf aktuelle und unternehmenseigene Informationen, um kontextbezogenere und präzisere Antworten zu liefern. Dieses vollständig verwaltete Feature strafft den RAG-Workflow von der Datenaufnahme bis zur Prompt-Anreicherung und macht individuelle Datenquellen-Integrationen überflüssig. Es unterstützt die nahtlose Anbindung an gängige Vektor-Datenbanken wie Amazon OpenSearch Serverless, Pinecone und Redis Enterprise Cloud, was Organisationen die Umsetzung von RAG erleichtert, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen.
- Agents for Amazon Bedrock: Architekten können autonome Agenten innerhalb von Anwendungen erstellen und konfigurieren, die Endnutzer dabei unterstützen, Aktionen auf Basis von Unternehmensdaten und Nutzereingaben auszuführen. Diese Agenten orchestrieren das Zusammenspiel von Foundation Models, Datenquellen, Softwareanwendungen und Nutzerdialogen. Sie rufen automatisch APIs auf und können Knowledge Bases einbinden, um Informationen für Aktionen anzureichern. Das senkt den Entwicklungsaufwand spürbar, da Aufgaben wie Prompt Engineering, Memory Management, Monitoring und Verschlüsselung übernommen werden.
Sagemaker Jumpstart
Amazon SageMaker JumpStart ist ein Machine-Learning-Hub innerhalb von Amazon SageMaker und bietet Zugriff auf vortrainierte Modelle und Lösungsvorlagen für eine Vielzahl von Problemstellungen. JumpStart ermöglicht inkrementelles Training, Tuning vor dem Deployment und vereinfacht das Bereitstellen, Fine-Tuning und Bewerten vortrainierter Modelle aus gängigen Model Hubs. So beschleunigt der Hub den Weg ins Machine Learning durch fertige Lösungen und Beispiele für Lernen und Anwendungsentwicklung.
Amazon CodeWhisperer
AWS CodeWhisperer ist ein auf Machine Learning basierender Code-Generator, der in Echtzeit Codeempfehlungen und -vorschläge liefert – von einzeiligen Kommentaren bis zu vollständigen Funktionen, basierend auf Ihren aktuellen und vorherigen Eingaben.
Amazon Q
Amazon Q ist ein generativer KI-Assistent für geschäftliche Anforderungen, den Nutzer für ihre konkreten Anwendungsfälle individuell zuschneiden können. Er unterstützt das Erstellen, Erweitern, Betreiben und Verstehen von Anwendungen und workloads auf AWS und ist damit ein vielseitiges Werkzeug für unterschiedlichste Aufgaben in der Organisation.