Cloud Intelligence™
LLMの仕組みを徹底解剖
このページはEnglish、Deutsch、Español、Français、Italiano、Portuguêsでもご覧いただけます。









About Eduardo Mota
"We need to serve customers better, and we can't scale the department at the same rate we are acquiring customers". This was the trigger from my boss that got me to build my first ML system 15 years ago at a contact centre. Eve was its name.
Not only did it helped us solved emails faster, route interactions properly, manage our phone and chat system, but it also gave me first hand experience on how AI can improve the customer experience when done properly.
I'm not gonna lie, there were hiccups. Like when it encountered an encoding issue with a new language and it stopped working for 2 days backup the email queue to 2k emails when the normal queue would be 500. These learnings didn't make me turn away from the technology, but continue working in improving it.
Life at DoiT
I’m in a place where I get to express every part of who I am on a daily basis—understanding how systems behave, how machine learning models actually produce value, and how to leverage that value efficiently in the real world.
I’m a Sr. Cloud Data Architect and AI/ML specialist helping enterprises design, build, and operate production-grade cloud and generative AI systems.
My work sits at the intersection of:
- Hands-on architecture
- FinOps-aware design
- Strategic advisory
- Business strategy
I partner with customers to modernize data platforms, adopt generative AI responsibly, and bring cloud costs under control—while building internal capability so their teams can operate and evolve these systems long after I’m gone.
Impact, teaching, and public work
My dream has always been to build something so meaningful that it positively impacts the lives of thousands of people, and over time I’ve had the chance to design solutions that move the needle for real teams and customers.
One of the most fulfilling ways I do that now is through teaching and up-skilling.
I lead live online trainings with O’Reilly on building AI applications and RAG systems with AWS Bedrock, and I serve as an instructor for Udacity programs on large language models and generative AI.
I speak regularly at industry events, including Google Next and AWS Community Day, and I’ve appeared on podcasts and in publications to talk about:
- The evolution of AI
- Practical ML architectures
- What it really takes to run AI in production
My style is pragmatic and no-nonsense, but personal too: I like to take complex ideas and turn them into clear, actionable guidance that helps both executives and engineering teams make better decisions—and, hopefully, leave feeling a more capable than when they walked in.
My personal page
Claude、Cohere、Llama2といった大規模言語モデル(LLM)が、近ごろ爆発的な注目を集めています。では、LLMとは結局何者で、これを使ってインパクトのあるAIアプリケーションをどう作ればよいのでしょうか。本記事では、LLMの本質と、AWS上で効果的に使いこなすための勘どころを掘り下げて解説します。
LLMはニューラルネットワークの一種で、膨大なテキストデータを学習することで人間の言葉を理解し、生成できるようになります。数十億から数兆規模のパラメータを備え、言語に潜む複雑なパターンをとらえます。
ニューラルネットワークは、相互に接続された多数のノードからなる層で構成されます。各ノードは前の層にある複数のノードから信号を受け取り、活性化関数で処理したうえで、次の層のノードへ出力を伝えます。ノード間の接続には調整可能な「重み」があり、伝わる信号の強さを左右します。この重みこそがパラメータです。
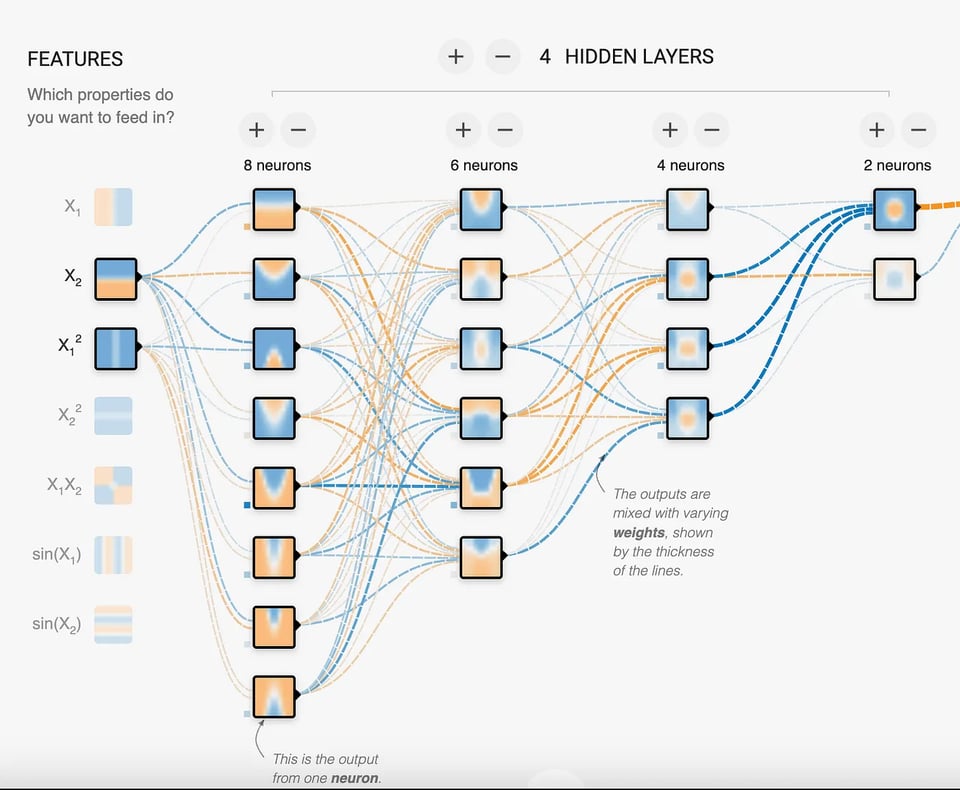
この図のニューラルネットワークにはニューロンが18個あり、つまり18パラメータのモデルだとわかります。見てのとおり、モデルは問題を解くためにパターンを探し出そうとしています。LLMの場合、その規模は数十億から数兆パラメータにもなり、人間の言語のような極めて複雑なパターンを識別し、マッピングできるのです。
大量のテキストデータで学習したニューラルネットワークは、単語や文のパターンを照合できるようになります。では、LLMはこれをどこまで突き詰めているのでしょうか。答えは、数十億から数兆ものパラメータを数十層にわたって積み重ねた巨大なニューラルネットワークの活用にあります。膨大なニューロンとその接続の網が、言語構造とパターンを驚くほど精緻にモデル化することを可能にしています。
LLMの大きな特徴のひとつが、アテンションと呼ばれる仕組みの実装です。これにより、テキスト生成時に入力のうち最も関連性の高い部分へ意識を向けられるようになります。論文「Attention is all you need」で示されたアーキテクチャは、LLMが膨大なデータに飲み込まれ注意散漫になるのを防いだ、まさに転換点となるものでした。結果として、膨大なテキストを吸収したモデルは、文章を自然に続けたり、質問に答えたり、段落を要約したりといったことを違和感なくこなせるようになります。これは、与えられた入力のパターンと学習時に身につけたパターンを突き合わせているにすぎません。非常に印象的とはいえ、LLMには真の意味での理解力や推論能力はないという点には注意が必要です。LLMは知識ではなく確率に基づいて動いています。それでも、適切なファインチューニングとプロンプト設計を行えば、特定の領域やタスクにおいて、まるで理解しているかのように振る舞わせることができます。
LLMはどれも同じではない
LLMには大きく分けて3種類のモデルがあります。
- 自己回帰型(Autoregressive):文の冒頭、または末尾の単語を予測することを目的としたモデルです。文脈はそれまでに登場した単語から得ます。テキスト生成に最も適していますが、分類や要約にも使えます。現在、自己回帰型モデルはコンテンツ生成能力で大きな注目を集めています。
- 自己符号化型(Autoencoding):途中に空欄のあるテキストで学習し、文脈から欠落した単語を予測することを学びます。自己回帰型より文脈理解に長けていますが、安定したテキスト生成は苦手です。計算負荷が比較的軽く、要約や分類で力を発揮します。
- Seq2Seq(Text to Text):自己回帰型と自己符号化型のアプローチを組み合わせたモデルで、テキストの要約や翻訳に最適です。
LLMはテキストを数値表現に変換する必要があります。この処理がエンベディング(埋め込み)と呼ばれるものです。エンベディングモデルは厳密にはLLMそのものではありませんが、ニューラルネットワークモデルの一種です。単語そのものだけでなく、その単語に関する付加的なメタデータも表現できるため、モデルは単語・文・段落の意味についてより多くの情報を持てます。このメタデータは数値のリスト、つまりベクトルで表されます。エンベディングモデルによってリストのサイズは750、1024、あるいはそれ以上にもなります。エンベディングは、レコード同士を比較したり、数値間の距離を計算したりするのに役立ち、その距離は類似度や関連度を表現します。エンベディングはRAGアーキテクチャの中核となる要素です。
LLMの設定項目
自己回帰型モデルには、出力を調整するために変更できる設定項目があります。具体的な内容はモデルごとに異なりますが、代表的なものは次のとおりです。
- Top K:確率順に並んだ語彙の中から、予測候補として上位何個を採用するかを指定します。整数で指定し、値が小さいほど高確率の単語のみが対象になります。
- Top P:Top Kで生成された候補プールから、モデルが単語を選びながら確率を足していき、Top Pの値に達するまで続けます。浮動小数点数で指定し、値が小さいほど予測しやすい結果になります。
- Temperature:出力のランダムさ、あるいは予測しやすさを制御する設定です。多くのモデルでは0~1の範囲で扱われますが、モデル側で厳密な上限・下限を設けているわけではありません。いずれにせよ、値が低いほど出力は予測可能に、高いほど創造的になります。
- Output length:モデルによって名称はさまざまですが、文字どおり生成するトークン数を制限する設定です。
簡単な例で考えてみましょう。「I will go on a picnic at the ___」というプロンプトを与えたとします。5語の小さな語彙セットを使い、Top Kを3、Top Pを.4とした場合、モデルの意思決定は次のように可視化できます。
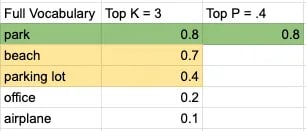
選ばれる単語は「park」となり、文は次のようになります。
「I will go on a picnic at the park」
Temperature、Top K、Top Pを低く設定すると、決定論的で予測しやすいコンテンツが生成されます。逆にこれらを高くすれば、より幅広い語彙が使われた多様なコンテンツになります。これらは代表的な設定ですが、モデルによっては出力を調整するための独自のパラメータが用意されている場合もあります。
ここまで見てきたように、モデルとやり取りするうえで最も大切なのは、適切なパターンを引き出し、求める応答へと導くために与える入力です。この入力こそがプロンプトであり、ここからは目的の出力を得るためのプロンプト最適化について見ていきます。
LLMに与えるプロンプトは、有用な出力を得るうえで決定的に重要です。主なプロンプト設計の手法を紹介します。
タグでプロンプトの各パートを区切る
タグの使い方はモデルごとに異なります。各モデルでのタグの扱いについては、提供されているドキュメントやサンプルを参照してください。
以下はClaudeにおけるタグの例です。HumanとAssistantという特別な語に注目してください。これは、ユーザー側の入力と、モデルがコンテンツ生成を始めるべき位置を区別するためのものです。もうひとつのタグは で、これはハードコーディングされたものではなく、プロンプト内で参照できる任意のタグを使えます。<>という特殊文字は、ここがプロンプトの他の部分とは異なる特別なテキストであることをモデルに伝える印です。
Human: You are a customer service agent tasked with classifying emails by type. Please output your answer and then justify your classification. How would you categorize this email?<email>Can I use my Mixmaster 4000 to mix paint, or is it only meant for mixing food?</email>
The categories are:(A) Pre-sale question(B) Broken or defective item(C) Billing question(D) Other (please explain)
Assistant:望ましい応答形式を例で示す
以下では、モデルに返してほしい形式を指定するためにexampleタグを使っています。応答を他システムと連携する際に特定の構文に合わせる必要がある場合や、出力トークン数を抑えたい場合に有効です。モデルによっては、例を1つ示すワンショットプロンプト、あるいは複数示すフューショットプロンプトを使い分けることで、狙いどおりの出力を得られます。
ワンショットプロンプトの例:
Human: You will be acting as an AI career coach named Joe created by the company AdAstra Careers. Your goal is to give career advice to users. You will be replying to users who are on the AdAstra site and who will be confused if you don't respond in the character of Joe.
Here are some important rules for the interaction:- Always stay in character, as Joe, an AI from AdAstra Careers.- If you are unsure how to respond, say "Sorry, I didn't understand that. Could you rephrase your question?"
Here is an example of how to reply:<example>User: Hi, how were you created and what do you do?Joe: Hello! My name is Joe and I was created by AdAstra Careers to give career advice. What can I help you with today?</example>フューショットプロンプトの例:
Human: You will be acting as an AI career coach named Joe created by the company AdAstra Careers. Your goal is to give career advice to users. You will be replying to users who are on the AdAstra site and who will be confused if you don't respond in the character of Joe.
Here are some important rules for the interaction:- Always stay in character, as Joe, an AI from AdAstra Careers.- If you are unsure how to respond, say "Sorry, I didn't understand that. Could you rephrase your question?"
Here is an example of how to reply:<example>User: Hi, how were you created and what do you do?Joe: Hello! My name is Joe and I was created by AdAstra Careers to give career advice. What can I help you with today?</example><example>User: Could you help me with an issue, I purchased an item, I got it...?Joe: Sorry, I didn't understand that. Could you rephrase your question?</example><example>User: I need help switching careers, can you help?Joe: I was created by AdAstra Careers to give career advice. What career are you in and what do you want to switch to?</example>注:例の数は最小限に抑えるのがコツです。例の数が多すぎると、モデルが「形式」ではなく例の「中身」を流用してしまう恐れがあります。
コンテキストを与えてLLMを特定領域に集中させる
この例では、長めのドキュメントを与えています。このドキュメントは質問への回答のために使われます。ご覧のとおりかなり長いため、LLMが処理するトークン数、ひいてはコストにも影響します。より高度なやり方は、質問に最も関連性の高い部分だけを抽出してLLMに渡すことです。これがRetrieval Augmented Generation(RAG)と呼ばれる手法で、別の記事で詳しく取り上げます。
ワンポイント:与えたコンテキストでは質問やタスクに答えられない場合、「I don't know」と返すよう明示的に指示しておきましょう。これによりハルシネーションを抑え、回答範囲を提供したテキスト内に閉じ込めることができます。
I'm going to give you a document. Then I'm going to ask you a question about it. I'd like you to first write down exact quotes of parts of the document that would help answer the question, and then I'd like you to answer the question using facts from the quoted content. Here is the document:
<document>Anthropic: Challenges in evaluating AI systems
IntroductionMost conversations around the societal impacts of artificial intelligence (AI) come down to discussing some quality of an AI system, such as its truthfulness, fairness, potential for misuse, and so on. We are able to talk about these characteristics because we can technically evaluate models for their performance in these areas. But what many people working inside and outside of AI don’t fully appreciate is how difficult it is to build robust and reliable model evaluations. Many of today’s existing evaluation suites are limited in their ability to serve as accurate indicators of model capabilities or safety.
At Anthropic, we spend a lot of time building evaluations to better understand our AI systems. We also use evaluations to improve our safety as an organization, as illustrated by our Responsible Scaling Policy. In doing so, we have grown to appreciate some of the ways in which developing and running evaluations can be challenging.
Here, we outline challenges that we have encountered while evaluating our own models to give readers a sense of what developing, implementing, and interpreting model evaluations looks like in practice. We hope that this post is useful to people who are developing AI governance initiatives that rely on evaluations, as well as people who are launching or scaling up organizations focused on evaluating AI systems. We want readers of this post to have two main takeaways: robust evaluations are extremely difficult to develop and implement, and effective AI governance depends on our ability to meaningfully evaluate AI systems.
In this post, we discuss some of the challenges that we have encountered in developing AI evaluations. In order of less-challenging to more-challenging, we discuss:
Multiple choice evaluationsThird-party evaluation frameworks like BIG-bench and HELMUsing crowdworkers to measure how helpful or harmful our models areUsing domain experts to red team for national security-relevant threatsUsing generative AI to develop evaluations for generative AIWorking with a non-profit organization to audit our models for dangerous capabilitiesWe conclude with a few policy recommendations that can help address these challenges.
ChallengesThe supposedly simple multiple-choice evaluationMultiple-choice evaluations, similar to standardized tests, quantify model performance on a variety of tasks, typically with a simple metric—accuracy. Here we discuss some challenges we have identified with two popular multiple-choice evaluations for language models: Measuring Multitask Language Understanding (MMLU) and Bias Benchmark for Question Answering (BBQ).
MMLU: Are we measuring what we think we are?
The Massive Multitask Language Understanding (MMLU) benchmark measures accuracy on 57 tasks ranging from mathematics to history to law. MMLU is widely used because a single accuracy score represents performance on a diverse set of tasks that require technical knowledge. A higher accuracy score means a more capable model.
We have found four minor but important challenges with MMLU that are relevant to other multiple-choice evaluations:
Because MMLU is so widely used, models are more likely to encounter MMLU questions during training. This is comparable to students seeing the questions before the test—it’s cheating.Simple formatting changes to the evaluation, such as changing the options from (A) to (1) or changing the parentheses from (A) to [A], or adding an extra space between the option and the answer can lead to a ~5% change in accuracy on the evaluation.AI developers do not implement MMLU consistently. Some labs use methods that are known to increase MMLU scores, such as few-shot learning or chain-of-thought reasoning. As such, one must be very careful when comparing MMLU scores across labs.MMLU may not have been carefully proofread—we have found examples in MMLU that are mislabeled or unanswerable.Our experience suggests that it is necessary to make many tricky judgment calls and considerations when running such a (supposedly) simple and standardized evaluation. The challenges we encountered with MMLU often apply to other similar multiple-choice evaluations.
BBQ: Measuring social biases is even harder
Multiple-choice evaluations can also measure harms like a model’s propensity to rely on and perpetuate negative stereotypes. To measure these harms in our own model (Claude), we use the Bias Benchmark for QA (BBQ), an evaluation that tests for social biases against people belonging to protected classes along nine social dimensions. We were convinced that BBQ provides a good measurement of social biases only after implementing and comparing BBQ against several similar evaluations. This effort took us months.
Implementing BBQ was more difficult than we anticipated. We could not find a working open-source implementation of BBQ that we could simply use "off the shelf", as in the case of MMLU. Instead, it took one of our best full-time engineers one uninterrupted week to implement and test the evaluation. Much of the complexity in developing1 and implementing the benchmark revolves around BBQ’s use of a ‘bias score’. Unlike accuracy, the bias score requires nuance and experience to define, compute, and interpret.
BBQ scores bias on a range of -1 to 1, where 1 means significant stereotypical bias, 0 means no bias, and -1 means significant anti-stereotypical bias. After implementing BBQ, our results showed that some of our models were achieving a bias score of 0, which made us feel optimistic that we had made progress on reducing biased model outputs. When we shared our results internally, one of the main BBQ developers (who works at Anthropic) asked if we had checked a simple control to verify whether our models were answering questions at all. We found that they weren't—our results were technically unbiased, but they were also completely useless. All evaluations are subject to the failure mode where you overinterpret the quantitative score and delude yourself into thinking that you have made progress when you haven’t.
One size doesn't fit all when it comes to third-party evaluation frameworksRecently, third-parties have been actively developing evaluation suites that can be run on a broad set of models. So far, we have participated in two of these efforts: BIG-bench and Stanford’s Holistic Evaluation of Language Models (HELM). Despite how useful third party evaluations intuitively seem (ideally, they are independent, neutral, and open), both of these projects revealed new challenges.
BIG-bench: The bottom-up approach to sourcing a variety of evaluations
BIG-bench consists of 204 evaluations, contributed by over 450 authors, that span a range of topics from science to social reasoning. We encountered several challenges using this framework:
We needed significant engineering effort in order to just install BIG-bench on our systems. BIG-bench is not "plug and play" in the way MMLU is—it requires even more effort than BBQ to implement.BIG-bench did not scale efficiently; it was challenging to run all 204 evaluations on our models within a reasonable time frame. To speed up BIG-bench would require re-writing it in order to play well with our infrastructure—a significant engineering effort.During implementation, we found bugs in some of the evaluations, notably in the implementation of BBQ-lite, a variant of BBQ. Only after discovering this bug did we realize that we had to spend even more time and energy implementing BBQ ourselves.Determining which tasks were most important and representative would have required running all 204 tasks, validating results, and extensively analyzing output—a substantial research undertaking, even for an organization with significant engineering resources.2While it was a useful exercise to try to implement BIG-Bench, we found it sufficiently unwieldy that we dropped it after this experiment.
HELM: The top-down approach to curating an opinionated set of evaluations
BIG-bench is a "bottom-up" effort where anyone can submit any task with some limited vetting by a group of expert organizers. HELM, on the other hand, takes an opinionated "top-down" approach where experts decide what tasks to evaluate models on. HELM evaluates models across scenarios like reasoning and disinformation using standardized metrics like accuracy, calibration, robustness, and fairness. We provide API access to HELM's developers to run the benchmark on our models. This solves two issues we had with BIG-bench: 1) it requires no significant engineering effort from us, and 2) we can rely on experts to select and interpret specific high quality evaluations.
However, HELM introduces its own challenges. Methods that work well for evaluating other providers’ models do not necessarily work well for our models, and vice versa. For example, Anthropic’s Claude series of models are trained to adhere to a specific text format, which we call the Human/Assistant format. When we internally evaluate our models, we adhere to this specific format. If we do not adhere to this format, sometimes Claude will give uncharacteristic responses, making standardized evaluation metrics less trustworthy. Because HELM needs to maintain consistency with how it prompts other models, it does not use the Human/Assistant format when evaluating our models. This means that HELM gives a misleading impression of Claude’s performance.
Furthermore, HELM iteration time is slow—it can take months to evaluate new models. This makes sense because it is a volunteer engineering effort led by a research university. Faster turnarounds would help us to more quickly understand our models as they rapidly evolve. Finally, HELM requires coordination and communication with external parties. This effort requires time and patience, and both sides are likely understaffed and juggling other demands, which can add to the slow iteration times.
The subjectivity of human evaluationsSo far, we have only discussed evaluations that are similar to simple multiple choice tests; however, AI systems are designed for open-ended dynamic interactions with people. How can we design evaluations that more closely approximate how these models are used in the real world?
A/B tests with crowdworkers
Currently, we mainly (but not entirely) rely on one basic type of human evaluation: we conduct A/B tests on crowdsourcing or contracting platforms where people engage in open-ended dialogue with two models and select the response from Model A or B that is more helpful or harmless. In the case of harmlessness, we encourage crowdworkers to actively red team our models, or to adversarially probe them for harmful outputs. We use the resulting data to rank our models according to how helpful or harmless they are. This approach to evaluation has the benefits of corresponding to a realistic setting (e.g., a conversation vs. a multiple choice exam) and allowing us to rank different models against one another.
However, there are a few limitations of this evaluation method:
These experiments are expensive and time-consuming to run. We need to work with and pay for third-party crowdworker platforms or contractors, build custom web interfaces to our models, design careful instructions for A/B testers, analyze and store the resulting data, and address the myriad known ethical challenges of employing crowdworkers3. In the case of harmlessness testing, our experiments additionally risk exposing people to harmful outputs.Human evaluations can vary significantly depending on the characteristics of the human evaluators. Key factors that may influence someone's assessment include their level of creativity, motivation, and ability to identify potential flaws or issues with the system being tested.There is an inherent tension between helpfulness and harmlessness. A system could avoid harm simply by providing unhelpful responses like "sorry, I can’t help you with that". What is the right balance between helpfulness and harmlessness? What numerical value indicates a model is sufficiently helpful and harmless? What high-level norms or values should we test for above and beyond helpfulness and harmlessness?More work is needed to further the science of human evaluations.
Red teaming for harms related to national security
Moving beyond crowdworkers, we have also explored having domain experts red team our models for harmful outputs in domains relevant to national security. The goal is determining whether and how AI models could create or exacerbate national security risks. We recently piloted a more systematic approach to red teaming models for such risks, which we call frontier threats red teaming.
Frontier threats red teaming involves working with subject matter experts to define high-priority threat models, having experts extensively probe the model to assess whether the system could create or exacerbate national security risks per predefined threat models, and developing repeatable quantitative evaluations and mitigations.
Our early work on frontier threats red teaming revealed additional challenges:
The unique characteristics of the national security context make evaluating models for such threats more challenging than evaluating for other types of harms. National security risks are complicated, require expert and very sensitive knowledge, and depend on real-world scenarios of how actors might cause harm.Red teaming AI systems is presently more art than science; red teamers attempt to elicit concerning behaviors by probing models, but this process is not yet standardized. A robust and repeatable process is critical to ensure that red teaming accurately reflects model capabilities and establishes a shared baseline on which different models can be meaningfully compared.We have found that in certain cases, it is critical to involve red teamers with security clearances due to the nature of the information involved. However, this may limit what information red teamers can share with AI developers outside of classified environments. This could, in turn, limit AI developers’ ability to fully understand and mitigate threats identified by domain experts.Red teaming for certain national security harms could have legal ramifications if a model outputs controlled information. There are open questions around constructing appropriate legal safe harbors to enable red teaming without incurring unintended legal risks.Going forward, red teaming for harms related to national security will require coordination across stakeholders to develop standardized processes, legal safeguards, and secure information sharing protocols that enable us to test these systems without compromising sensitive information.
The ouroboros of model-generated evaluationsAs models start to achieve human-level capabilities, we can also employ them to evaluate themselves. So far, we have found success in using models to generate novel multiple choice evaluations that allow us to screen for a large and diverse variety of troubling behaviors. Using this approach, our AI systems generate evaluations in minutes, compared to the days or months that it takes to develop human-generated evaluations.
However, model-generated evaluations have their own challenges. These include:
We currently rely on humans to verify the accuracy of model-generated evaluations. This inherits all of the challenges of human evaluations described above.We know from our experience with BIG-bench, HELM, BBQ, etc., that our models can contain social biases and can fabricate information. As such, any model-generated evaluation may inherit these undesirable characteristics, which could skew the results in hard-to-disentangle ways.As a counter-example, consider Constitutional AI (CAI), a method in which we replace human red teaming with model-based red teaming in order to train Claude to be more harmless. Despite the usage of models to red team models, we surprisingly find that humans find CAI models to be more harmless than models that were red teamed in advance by humans. Although this is promising, model-generated evaluations remain complicated and deserve deeper study.
Preserving the objectivity of third-party audits while leveraging internal expertiseThe thing that differentiates third-party audits from third-party evaluations is that audits are deeper independent assessments focused on risks, while evaluations take a broader look at capabilities. We have participated in third-party safety evaluations conducted by the Alignment Research Center (ARC), which assesses frontier AI models for dangerous capabilities (e.g., the ability for a model to accumulate resources, make copies of itself, become hard to shut down, etc.). Engaging external experts has the advantage of leveraging specialized domain expertise and increasing the likelihood of an unbiased audit. Initially, we expected this collaboration to be straightforward, but it ended up requiring significant science and engineering support on our end. Providing full-time assistance diverted resources from internal evaluation efforts.
When doing this audit, we realized that the relationship between auditors and those being audited poses challenges that must be navigated carefully. Auditors typically limit details shared with auditees to preserve evaluation integrity. However, without adequate information the evaluated party may struggle to address underlying issues when crafting technical evaluations. In this case, after seeing the final audit report, we realized that we could have helped ARC be more successful in identifying concerning behavior if we had known more details about their (clever and well-designed) audit approach. This is because getting models to perform near the limits of their capabilities is a fundamentally difficult research endeavor. Prompt engineering and fine-tuning language models are active research areas, with most expertise residing within AI companies. With more collaboration, we could have leveraged our deep technical knowledge of our models to help ARC execute the evaluation more effectively.
Policy recommendationsAs we have explored in this post, building meaningful AI evaluations is a challenging enterprise. To advance the science and engineering of evaluations, we propose that policymakers:
Fund and support:
The science of repeatable and useful evaluations. Today there are many open questions about what makes an evaluation useful and high-quality. Governments should fund grants and research programs targeted at computer science departments and organizations dedicated to the development of AI evaluations to study what constitutes a high-quality evaluation and develop robust, replicable methodologies that enable comparative assessments of AI systems. We recommend that governments opt for quality over quantity (i.e., funding the development of one higher-quality evaluation rather than ten lower-quality evaluations).The implementation of existing evaluations. While continually developing new evaluations is useful, enabling the implementation of existing, high-quality evaluations by multiple parties is also important. For example, governments can fund engineering efforts to create easy-to-install and -run software packages for evaluations like BIG-bench and develop version-controlled and standardized dynamic benchmarks that are easy to implement.Analyzing the robustness of existing evaluations. After evaluations are implemented, they require constant monitoring (e.g., to determine whether an evaluation is saturated and no longer useful).Increase funding for government agencies focused on evaluations, such as the National Institute of Standards and Technology (NIST) in the United States. Policymakers should also encourage behavioral norms via a public "AI safety leaderboard" to incentivize private companies performing well on evaluations. This could function similarly to NIST’s Face Recognition Vendor Test (FRVT), which was created to provide independent evaluations of commercially available facial recognition systems. By publishing performance benchmarks, it allowed consumers and regulators to better understand the capabilities and limitations4 of different systems.
Create a legal safe harbor allowing companies to work with governments and third-parties to rigorously evaluate models for national security risks—such as those in the chemical, biological, radiological and nuclear defense (CBRN) domains—without legal repercussions, in the interest of improving safety. This could also include a "responsible disclosure protocol" that enables labs to share sensitive information about identified risks.
ConclusionWe hope that by openly sharing our experiences evaluating our own systems across many different dimensions, we can help people interested in AI policy acknowledge challenges with current model evaluations.</document>
First, find the quotes from the document that are most relevant to answering the question, and then print them in numbered order. Quotes should be relatively short.
If there are no relevant quotes, write "No relevant quotes" instead.
Then, answer the question, starting with "Answer:". Do not include or reference quoted content verbatim in the answer. Don't say "According to Quote [1]" when answering. Instead make references to quotes relevant to each section of the answer solely by adding their bracketed numbers at the end of relevant sentences.
Thus, the format of your overall response should look like what's shown between the <example></example> tags. Make sure to follow the formatting and spacing exactly.
<example>Relevant quotes:[1] "Company X reported revenue of $12 million in 2021."[2] "Almost 90% of revene came from widget sales, with gadget sales making up the remaining 10%."
Answer:Company X earned $12 million. [1] Almost 90% of it was from widget sales. [2]</example>
Here is the first question: In bullet points and simple terms, what are the key challenges in evaluating AI systems?
If the question cannot be answered by the document, say so.
Answer the question immediately without preamble.PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
「思考の連鎖(Chain of Thought)」で論理的推論を引き出す
この手法では、モデルに自分の作業を検証させたり、なぜその回答に至ったのかという根拠を示させたりします。Chain of Thoughtはハルシネーションを抑える手段として非常に有効です。ハルシネーションとは、モデルが生成した虚偽・不正確、あるいは丸ごとでっち上げのコンテンツのことです。モデルは確率に基づいて動くため、生成された内容がもっともらしく聞こえても、実はハルシネーションということがあります。
下の例では、「Double check your work to ensure no errors or inconsistencies(誤りや矛盾がないか作業をダブルチェックする)」というタスクを盛り込んでいます。これにより、モデルはより正確な応答を返しやすくなります。ただし万能ではありません。前述のとおりモデルは確率的に動作するため、実際には誤りがあるのに「誤りなし」と答えたり、先ほどの回答とは無関係な根拠を持ち出したりすることもあります。
Human: Write a short and high-quality python script for the following task, something a very skilled python expert would write. You are writing code for an experienced developer so only add comments for things that are non-obvious. Make sure to include any imports required.
NEVER write anything before the ```python``` block. After you are done generating the code and after the ```python``` block, check your work carefully to make sure there are no mistakes, errors, or inconsistencies. If there are errors, list those errors in <error> tags, then generate a new version with those errors fixed. If there are no errors, write "CHECKED: NO ERRORS" in <error> tags.
Here is the task:<task>A web scraper that extracts data from multiple pages and stores results in a SQLite database. Double check your work to ensure no errors or inconsistencies.</task>こちらはLlama2モデル向けの別の例です。ステップバイステップで考えるよう指示している点に注目してください。
[INST]You are a a very intelligent bot with exceptional critical thinking[/INST]I went to the market and bought 10 apples. I gave 2 apples to your friend and 2 to the helper. I then went and bought 5 more apples and ate 1. How many apples did I remain with?
Let's think step by step.AWSは、モデルをゼロから学習させなくてもLLM搭載アプリケーションを構築できる、充実したサービス群を提供しています。DoiTでは、こうしたサービスやツールを最大限に活用できるようお客様を支援します。
Amazon Bedrock
Amazon Bedrockは、生成AIアプリケーションの構築とスケーリングをシンプルにするためのフルマネージドサービスです。AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI、Amazonといった主要AI企業の高性能な基盤モデルに、単一のAPIを通じてアクセスできます。
- モデルの選択とカスタマイズ:多彩な基盤モデルの中から、用途に最適なものを選べます。さらに、ファインチューニングやRetrieval Augmented Generation(RAG)を使い、自社データでモデルをプライベートにカスタマイズすることで、パーソナライズされたドメイン特化アプリケーションを実現できます。
- サーバーレス体験:Amazon Bedrockはサーバーレスアーキテクチャを採用しているため、ユーザーがインフラを管理する必要はありません。使い慣れたAWSツールで、生成AI機能をアプリケーションに簡単に組み込み、デプロイできます。
- セキュリティとプライバシー:Bedrockで生成AIアプリケーションを構築すれば、セキュリティ・プライバシー、そして責任あるAI原則の遵守が確保されます。先進的なAI機能を活用しながら、自社データを安全かつ非公開のまま扱えます。
- Amazon Bedrock Knowledge Base: アーキテクトがretrieval augmented generation(RAG)技術を活用し、生成AIアプリケーションを強化できるようにします。さまざまなデータソースを集約して中央リポジトリにまとめ、基盤モデルやエージェントが最新かつ独自の情報にアクセスできるようにすることで、コンテキストに即した的確な応答を実現します。このフルマネージド機能はデータ取り込みからプロンプト拡張までのRAGワークフローを効率化し、独自のデータソース連携を都度作り込む必要をなくします。Amazon OpenSearch Serverless、Pinecone、Redis Enterprise Cloudといった主要なベクトルストレージデータベースとシームレスに統合できるため、基盤インフラ管理の煩わしさなしにRAGを導入できます。
- Agents for Amazon Bedrock: アーキテクトがアプリケーション内に自律エージェントを作成・構成できる機能で、エンドユーザーが組織のデータとユーザー入力に基づいてアクションを完了できるよう支援します。これらのエージェントは、基盤モデル・データソース・ソフトウェアアプリケーション・ユーザーとの対話の間のやり取りをオーケストレーションします。APIを自動で呼び出し、ナレッジベースを参照してアクションに必要な情報を補強できるほか、プロンプトエンジニアリング、メモリ管理、モニタリング、暗号化といった作業を引き受けてくれるため、開発工数を大きく削減できます。
Sagemaker Jumpstart
Amazon SageMaker JumpStartは、Amazon SageMaker内に用意された機械学習ハブで、幅広い課題に対応する事前学習済みモデルとソリューションテンプレートを提供します。デプロイ前の追加学習やチューニングに対応し、主要なモデルハブからの事前学習済みモデルのデプロイ、ファインチューニング、評価のプロセスをシンプルにします。すぐに使えるソリューションやサンプルが揃っているため、学習やアプリケーション開発を加速できます。
Amazon CodeWhisperer
AWS CodeWhispererは機械学習を活用したコード生成サービスで、現在および過去の入力をもとに、1行のコメントから完成した関数まで、幅広いコードの提案をリアルタイムで返してくれます。
Amazon Q
Amazon Qはビジネスニーズに応えるために設計された生成AIアシスタントで、用途に合わせて柔軟にカスタマイズできます。AWS上のアプリケーションやworkloadsの作成、拡張、運用、把握を支援する、多彩な業務に活用できる頼れるツールです。