
The microservices honeymoon period is over. Uber is refactoring thousands of microservices into a more manageable solution [1]; Kelsey Hightower is predicting monoliths are the future [2]; and even Sam Newman is declaring that microservices should never be the default choice, but rather a last resort [3].
What’s going on here? Why have so many projects become unmaintainable, despite microservices’ promise of simplicity and flexibility? Or are monoliths better, after all?
In this post, I want to address these questions. You will learn about common design issues that turn microservices into distributed big balls of mud — and, of course, how you can avoid them.
But first, let’s set the record straight on what a monolith is.
Monolith
Microservices have always been positioned as a solution for monolithic codebases. But are monoliths necessarily a problem? According to Wikipedia’s definition [4], a monolithic application is self-contained and independent from other computing applications. Independence from other applications? Isn’t that what we are chasing, often to no avail, when we design microservices? David Heinemeier Hansson [5] called out the smearing of monoliths right away. He warned about the liabilities and challenges inherent to distributed systems and used Basecamp to prove that a large system serving millions of customers can be implemented and maintained in a monolithic codebase.
Hence, microservices do not “fix” monoliths. The real problem that microservices are supposed to solve is an inability to deliver business goals. Often, teams fail to achieve business goals because of the exponentially growing — or even worse unpredictable — costs of making a change. In other words, the system is unable to keep up with the needs of the business. The uncontrollable cost of change is not a property of a monolith but rather of a big ball of mud [6]:
A Big Ball of Mud is a haphazardly structured, sprawling, sloppy, duct-tape-and-baling-wire, spaghetti-code jungle. These systems show unmistakable signs of unregulated growth, and repeated, expedient repair. Information is shared promiscuously among distant elements of the system, often to the point where nearly all the important information becomes global or duplicated.
The complexity of changing and evolving a big ball of mud can be caused by multiple factors: coordinating the work of multiple teams, conflicting non-functional requirements, or an intricate business domain. Either way, we often seek to tackle this complexity by decomposing such clumsy solutions into microservices.
Micro- what?
The term “microservice” implies that some parts of a service can be measured and its value should be minimized. But what does microservice mean, exactly? Let’s examine a few common ways the term is used.
Micro-teams
The first one is the size of the team that works on a service. And this metric should be measured in pizzas. Seriously. They say that if a team working on a service can be fed with two pizzas, then it’s a microservice. I find this heuristic anecdotal, as I’ve built projects with teams that could be fed with one pizza …and I dare anyone to call those balls of mud microservices!
Micro-codebases
Another widespread approach is to design a microservice-based on the size of its codebase. Some take this notion to the extreme and try to limit service sizes to a certain number of lines of code. That said, the exact number of lines needed to constitute a microservice is yet to be found. Once this holy grail of software architecture is discovered, we will move on to the next question — what is the recommended editor width for building microservices?
On a more serious note, a less extreme version of this approach is the prevalent one. The size of a codebase is often used as a heuristic for deciding whether it is a microservice or not.
In some way, this approach makes sense. The smaller the codebase, the lower the scope of the business domain. Thus, it’s simpler to understand, to implement, and to evolve. Moreover, a smaller codebase has fewer chances of turning into a big ball of mud — and if it does happen, it is simpler to refactor.
Unfortunately, the aforementioned simplicity is just an illusion. When we evaluate a service’s design based on the service itself, we miss a crucial part of system design. We forget the system itself, the system that the service is a component of.
“There are many useful and revealing heuristics for defining the boundaries of a service. Size is one of the least useful.” ~ Nick Tune
We Build Systems!
We build systems, not sets of services. We use microservices-based architecture to optimize a system’s design, not the design of individual services. No matter what others may say, microservices cannot, and will never be neither completely decoupled, nor fully independent. You cannot build a system out of separate components! That would go against the very definition of the term “system” [7]:
1. A set of connected things or devices that operate together
2. A set of computer equipment and programs used together for a particular purpose
Services will always have to interact with each other to form a system. If you design a system by optimizing its services, but ignore the interactions between them, this is what you may end up with this:

Those “microservices” may be simple individually, but the system itself is a complexity hell!
So how do we design microservices that tackle the complexity not only of the services but of the system as a whole?
That’s a tough question, but luckily for us, it was answered a long time ago.
A System-Wide Perspective on Complexity
Forty years ago, there was no cloud computing, no global-scale requirements, and no need to deploy a system every 11.7 seconds. But engineers still had to tame systems’ complexity. Even though the tools in those days were different, the challenges — and more importantly, the solution — are all relevant nowadays, and can be applied to the design of microservices-based systems.
In his book, “Composite/Structured Design” [8], Glenford J. Myers discusses how to structure procedural code to reduce its complexity. On the very first page of the book, he writes:
There is much more to the subject of complexity than simply attempting to minimize the local complexity of each part of a program. A much more important type of complexity is global complexity: the complexity of the overall structure of a program or system (i.e., the degree of association or interdependence among the major pieces of a program).
In our context, local complexity is the complexity of each individual microservice, whereas global complexity is the complexity of the whole system. Local complexity depends on the implementation of a service; global complexity is defined by the interactions and dependencies between the services.
So which complexity is more important — local or global? Let’s see what happens when only one of the complexities is taken care of.
It’s surprisingly easy to reduce global complexity to a minimum. All we have to do is to eliminate any interactions between the system’s components — i.e., implement all functionality in one monolithic service. As we’ve seen earlier, this strategy may work in specific scenarios. In others, it may lead to the dreaded big ball of mud — probably the highest possible level of local complexity.
On the other hand, we know what happens when you optimize only the local complexity, but neglect the system’s global complexity — the even more dreaded distributed big ball of mud.
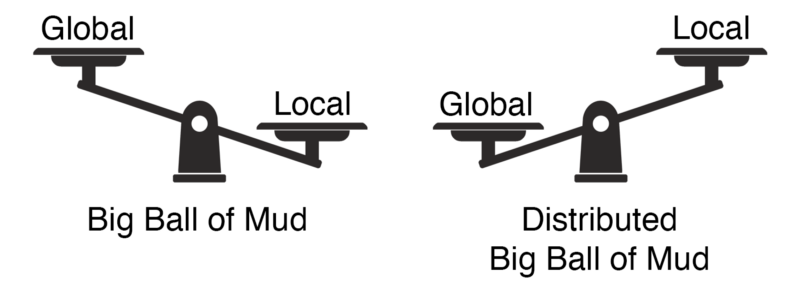
Hence, if we concentrate on only one type of complexity, it doesn’t matter which one is chosen. In a fairly complex distributed system, the opposite complexity will skyrocket. Therefore, we can’t optimize only one. Instead, we have to balance both the local and global complexities.
Interestingly, the means for balancing complexity described in the “Composite/Structured Design” book are not only relevant to distributed systems. They also offer insight into how to design microservices.
Microservices
Let’s start by defining what exactly are those services and microservices, that we are talking about.
What is a Service?
According to OASIS Standard [9], a service is:
A mechanism to enable access to one or more capabilities, where the access is provided using a prescribed interface.
The prescribed interface part is crucial. A service’s interface defines the functionality it exposes to the world. According to Randy Shoup [10], a service’s public interface is simply any mechanism that gets data in or out of service. It can be synchronous, such as a plain request/response model, or asynchronous. one that produces and consumes events. Either way, synchronous or asynchronous, the public interface is just the means for getting data in or out of service. Randy also describes the service’s public interfaces as its front door.
A service is defined by its public interface, and this definition is enough to define what makes a service a microservice.
What is a Microservice?
If a service is defined by its public interface, then —
A microservice is a service with a micro public interface — micro front door.
This simple heuristic was followed in the days of procedural programming, and it is more than relevant in the realm of distributed systems. The smaller the service you expose, the simpler its implementation, and the lower its local complexity. From the global complexity standpoint, smaller public interfaces produce fewer dependencies and connections between services.
The notion of micro-interfaces also explains the widespread practice of microservices not exposing their databases. No microservice can access another microservice’s database, but only through its public interface. Why is that? — Well, a database would be a huge public interface! Just consider how many different operations you can execute on a relational database.
Hence, to reiterate, in distributed systems, we balance local and global complexities by minimizing the services’ public interfaces and thus making them micro services.
WARNING
This heuristic may sound deceptively simple. If a microservice is just a service with a micro public interface, then we can just limit public interfaces to only one method. Since the front door can’t be any smaller than that, those should be the perfect microservices, right? Not really. To demonstrate why not, I’ll use the example from my other post [11] on this subject:
Let’s say we have the following backlog management service:
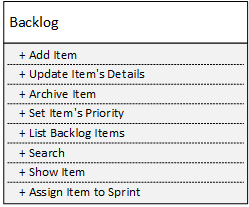
Once we decompose it into eight services, each having a single public method, we get services with perfect local complexities:
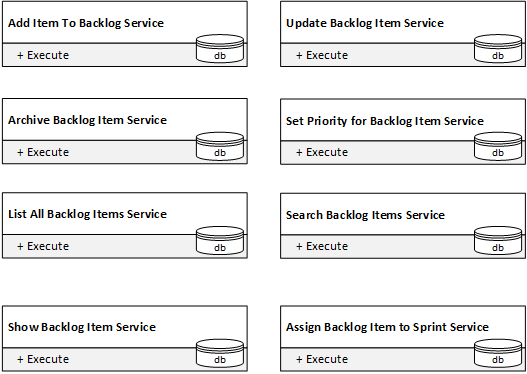
But can we connect them into the system that actually manages the backlog? Not really. To form the system, the services have to interact with each other and share changes to each service’s state. But they can’t. The services’ public interfaces do not support that.
Hence, we have to extend the front doors with public methods that enable integration between the services:
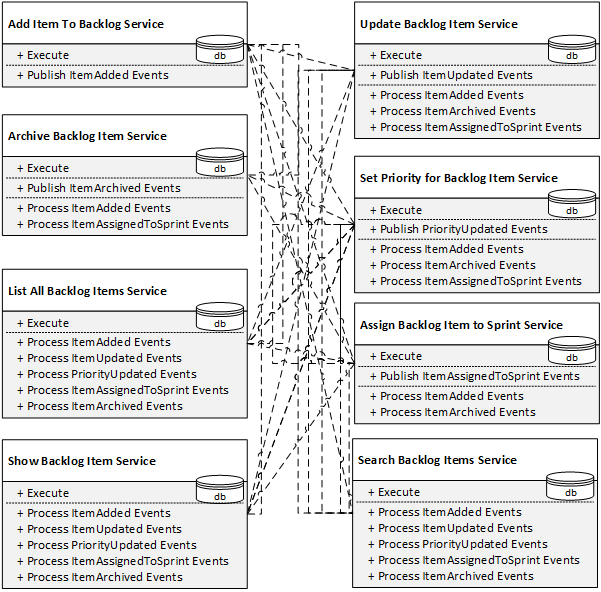
Boom. If we optimize the complexity of each service individually, the naïve decomposition works great. However, when we try to connect the services into a system, global complexity kicks in. Not only does the resulting system become an entangled mess; we also have to extend the public interfaces beyond our original intent — for the integration’s sake. Paraphrasing Randy Shoup, in addition to the tiny front door, we created a huge “staff only” entrance! Which brings us to an important point:
A service having more integration-related than business-related methods is a strong heuristic for a growing distributed big ball of mud!
Hence, the threshold upon which a service’s public interface can be minimized depends not only on the service itself but (mainly) on the system that the service is a part of. A proper decomposition to microservices should balance the system’s global complexity and the local complexities of its services.
Designing Service Boundaries
“Finding service boundaries is really damn hard… There is no flowchart!” — Udi Dahan
The above statement by Udi Dahan is especially true for microservices-based systems. Designing microservices’ boundaries is hard, and probably impossible to get right the first time. That makes designing a fairly complex microservices-based system an iterative process.
Hence, it is safer to start with wider boundaries — probably the boundaries of proper bounded contexts[12] — and decompose them into microservices later, as more knowledge is gained about the system and its business domain. This is especially relevant to services encompassing core business domains[13].
Microservices Outside of Distributed Systems
Even though microservices were “invented” only recently, you can find plenty of implementations of the same design principles in other industries. These implementations include:
Cross-Functional Teams
We all know that cross-functional teams are the most effective ones. Such team is a diverse group of professionals all working on the same task. An efficient cross-functional team maximizes the communication inside of the team and minimizes the communication outside of it.
Our industry discovered cross-functional teams only recently, but task forces have been around forever. The underlying principles for these are the same as those for a microservices-based system: high cohesion inside the team, and low coupling between teams. The team’s “public interface” is minimized by incorporating the skills needed to achieve the task into the team (i.e., implementation details).
Microprocessors
I stumbled upon this example in Vaughn Vernon’s wonderful blog on the same topic. In his post, Vaughn draws an interesting parallel between micro services and micro processors. In particular, he discusses the difference between processors and microprocessors:
I find it interesting that there is a size classification given that helps determine whether or not a central processing unit (CPU) is considered a Microprocessor: the size of its data bus [21]
A microprocessor’s data bus is its public interface — it defines the amount of data that can be passed between the microprocessor and other components. There is a strict size classification for the public interface that defines whether or not a central processing unit (CPU) is considered a microprocessor.
Unix Philosophy
Unix philosophy, or the Unix way, is a set of cultural norms and philosophical approaches to minimalist, modular software development [22].
One may argue that the Unix philosophy contradicts my case that you cannot build a system out of fully independent components: Aren’t Unix programs fully independent, and yet do form a working system? The opposite is true. The Unix way almost literally defines that programs have to expose micro-interfaces. Let’s see how the principles of the Unix philosophy relate to the notion of microservices:
The first principle calls for programs’ public interfaces to expose one coherent function, instead of cluttering programs with functionality not related to their original goal:
Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new “features”.
Even though Unix commands are considered fully independent from each other, they are not. They still have to communicate with others, and the second principle defines how communication interfaces should be designed:
Expect the output of every program to become the input to another, as yet unknown, program. Don’t clutter output with extraneous information. Avoid stringently columnar or binary input formats. Don’t insist on interactive input.
Not only the communication interface is strictly limited (standard input, standard output, and standard error), but according to this principle, the data passed between the commands should be strictly limited as well. I.e., Unix commands have to expose micro-interfaces and never depend on each other’s implementation details.
What About Nano services?
The term “nanoservice” is often used to describe a service that is too small. One can say that those naïve one-method-services in the previous example are nanoservices. However, I don’t necessarily agree with this classification.
Nanoservices are used to describe individual services while ignoring the overarching system. In the above example, once we put the system into the equation, the services’ interfaces had to grow. In fact, if we compare the original single service implementation with the naïve decomposition, we can see that once we connect the services into a system, the system goes from 8 public methods overall to 38. Moreover, the average number of public methods per service jumps from the desired 1 all the way to 4.75.
Hence, if instead of codebases, we optimize services (public interfaces), the term nano-service doesn’t hold up any more, as the service is forced to grow back up to support its system’s use-cases.
Is That All There Is To It?
No. Although minimizing the public interfaces of services is a good guiding principle for designing microservices, it’s still just a heuristic and doesn’t replace common sense. In fact, the micro-interface is just a kind of abstraction over the more fundamental, but much more complex design principles of coupling and cohesion.
For example, if two services have micro-public interfaces, but they have to be coordinated in a distributed transaction, they are still highly coupled to each other.
That said, aiming for micro-interfaces is still a strong heuristic that addresses different types of coupling, such as functional, development, and semantic. But that’s a topic for another blog.
From Theory to Practice
Unfortunately, we don’t have an objective way to quantify local and global complexities yet. On the other hand, we do have some design heuristics that can improve the design of distributed systems.
The main message of this post is that you should continuously evaluate the public interfaces of your services by asking:
- What is the ratio of business- and integration-oriented endpoints in a given service?
- Are there, business-wise, unrelated endpoints in a service? Can you split them across two or more services without introducing integration-oriented endpoints?
- Would merging two services eliminate endpoints that were added to integrate the original services?
Use these heuristics to guide the design of your services’ boundaries and interfaces.
Summary
I want to sum it all up with a quote by Eliyahu Goldratt. In his books, he often repeated these words:
“Tell me how you measure me, and I will tell you how I will behave” ~ Eliyahu Goldratt
When designing microservices-based systems, it’s crucial to measure and optimize the right metric. Designing boundaries for micro codebases, and micro teams is definitely easier. However, to build a system, we have to take it into account. Microservices are about designing systems, not individual services.
And that brings us back to the title of the post — “Untangling Microservices, or Balancing Complexity in Distributed Systems”. The only way to untangle microservices is to balance the local complexity of each service, and the global complexity of the whole system.
Bibliography
- Gergely Orosz’s tweet on Uber
- Monoliths are the future
- Microservices guru warns devs that trendy architecture shouldn’t be the default for every app, but ‘a last resort’
- Monolithic Application(Wikipedia)
- The Majestic Monolith — DHH
- Big Ball of Mud(Wikipedia)
- Definition of a System
- Composite/Structures Design — book by Glenford J. Myers
- Reference Model for Service Oriented Architecture
- Managing Data in Microservices — talk by Randy Shoup
- Tackling Complexity in Microservices
- Bounded Contexts are NOT Microservices
- Revisiting the Basics of Domain-Driven Design
- Implementing Domain-Driven Design — book by Vaughn Vernon
- Modular Monolith: A Primer — Kamil Grzybek
- A Design Methodology for Reliable Software Systems — Barbara Liskov
- Designing Autonomous Teams and Services
- Emergent Boundaries — a talk by Mathias Verraes
- Long Sad Story of Microservices — talk by Greg Young
- Principles of Design — Tim Berners-Lee
- Microservices and [Micro]services — Vaughn Vernon
- Unix Philosophy
Originally published at vladikk.com on April 09, 2020.