
La lune de miel des microservices est terminée. Uber refactorise des milliers de microservices en une solution plus maîtrisable [1] ; Kelsey Hightower prédit que l'avenir appartient aux monolithes [2] ; et même Sam Newman affirme que les microservices ne devraient jamais être le choix par défaut, mais plutôt un dernier recours [3].
Que se passe-t-il ? Pourquoi tant de projets sont-ils devenus impossibles à maintenir, malgré la promesse de simplicité et de flexibilité des microservices ? Les monolithes seraient-ils finalement préférables ?
Dans cet article, je souhaite répondre à ces questions. Vous y découvrirez les écueils de conception courants qui transforment les microservices en grosses boules de boue distribuées — et, bien sûr, comment les éviter.
Mais commençons par clarifier ce qu'est réellement un monolithe.
Le monolithe
Les microservices ont toujours été présentés comme une réponse aux bases de code monolithiques. Mais les monolithes posent-ils nécessairement problème ? Selon la définition de Wikipédia [4], une application monolithique est autonome et indépendante des autres applications informatiques. Indépendante des autres applications ? N'est-ce pas précisément ce que nous cherchons, souvent en vain, lorsque nous concevons des microservices ? David Heinemeier Hansson [5] a immédiatement dénoncé ce dénigrement des monolithes. Il a alerté sur les contraintes et défis inhérents aux systèmes distribués et s'est appuyé sur Basecamp pour démontrer qu'un grand système servant des millions de clients peut être implémenté et maintenu dans une base de code monolithique.
Les microservices ne " réparent " donc pas les monolithes. Le véritable problème qu'ils sont censés résoudre, c'est l'incapacité à atteindre les objectifs métier. Bien souvent, les équipes échouent à cause d'un coût du changement qui croît de façon exponentielle — voire, pire encore, imprévisible. Autrement dit, le système ne suit plus le rythme des besoins de l'entreprise. Or ce coût incontrôlable n'est pas le propre d'un monolithe, mais bien d'une grosse boule de boue [6] :
Une grosse boule de boue est une jungle de code spaghetti, désordonnée, tentaculaire, négligée, tenue avec du ruban adhésif et du fil de fer. Ces systèmes présentent les signes indéniables d'une croissance non régulée et de réparations répétées et expéditives. L'information y est partagée sans discernement entre des éléments éloignés du système, au point que presque toutes les informations importantes deviennent globales ou dupliquées.
La complexité de modification et d'évolution d'une grosse boule de boue peut résulter de plusieurs facteurs : la coordination entre plusieurs équipes, des exigences non fonctionnelles contradictoires, ou encore un domaine métier touffu. Quoi qu'il en soit, on cherche souvent à apprivoiser cette complexité en décomposant ces solutions maladroites en microservices.
Micro… quoi ?
Le terme " microservice " sous-entend que certains aspects d'un service sont mesurables et que leur valeur doit être réduite au minimum. Mais que signifie exactement " microservice " ? Examinons quelques usages courants du terme.
Les micro-équipes
Le premier critère, c'est la taille de l'équipe qui travaille sur un service. Et cette mesure devrait s'exprimer en pizzas. Sans rire. On dit que si une équipe travaillant sur un service peut être nourrie avec deux pizzas, alors il s'agit d'un microservice. Je trouve cette heuristique anecdotique : j'ai mené des projets avec des équipes qu'on pouvait nourrir avec une seule pizza… et je mets quiconque au défi de qualifier ces boules de boue de microservices !
Les micro-bases de code
Une autre approche répandue consiste à concevoir un microservice en fonction de la taille de sa base de code. Certains poussent l'idée à l'extrême et tentent de plafonner les services à un certain nombre de lignes de code. Cela dit, le nombre exact de lignes nécessaires pour constituer un microservice reste à découvrir. Une fois ce Saint Graal de l'architecture logicielle trouvé, on s'attaquera à la question suivante : quelle est la largeur d'éditeur recommandée pour développer des microservices ?
Plus sérieusement, c'est une version moins extrême de cette approche qui prévaut. La taille d'une base de code sert souvent d'heuristique pour décider s'il s'agit ou non d'un microservice.
D'une certaine manière, cette approche se tient. Plus la base de code est petite, plus la portée du domaine métier est restreinte. Elle est donc plus simple à comprendre, à implémenter et à faire évoluer. Et une base de code réduite a moins de risques de virer à la grosse boule de boue — et si cela arrive, elle est plus facile à refactoriser.
Malheureusement, cette simplicité n'est qu'une illusion. Lorsqu'on évalue la conception d'un service à la lumière du seul service, on passe à côté d'un aspect crucial de la conception système. On oublie le système lui-même, ce système dont le service n'est qu'un composant.
" Il existe de nombreuses heuristiques utiles et révélatrices pour définir les frontières d'un service. La taille est l'une des moins utiles. " ~ Nick Tune
Nous construisons des systèmes !
Nous construisons des systèmes, pas des collections de services. Nous adoptons une architecture en microservices pour optimiser la conception d'un système, et non celle de chaque service pris isolément. Quoi qu'on en dise, les microservices ne pourront jamais être ni totalement découplés, ni entièrement indépendants. On ne peut pas construire un système à partir de composants séparés ! Cela irait à l'encontre même de la définition du terme " système " [7] :
1. Un ensemble de choses ou d'appareils connectés qui fonctionnent ensemble
2. Un ensemble d'équipements informatiques et de programmes utilisés ensemble dans un but particulier
Les services devront toujours interagir entre eux pour former un système. Si vous concevez un système en optimisant ses services tout en ignorant leurs interactions, voici à quoi vous risquez d'aboutir :

Ces " microservices " sont peut-être simples pris un à un, mais le système, lui, est un véritable enfer de complexité !
Alors, comment concevoir des microservices qui maîtrisent la complexité non seulement des services, mais aussi du système dans son ensemble ?
C'est une question difficile, mais heureusement pour nous, la réponse a été apportée il y a bien longtemps.
Une perspective systémique sur la complexité
Il y a quarante ans, il n'y avait ni cloud computing, ni exigences à l'échelle mondiale, ni besoin de déployer un système toutes les 11,7 secondes. Mais les ingénieurs devaient déjà dompter la complexité des systèmes. Les outils de l'époque étaient différents, certes, mais les défis — et surtout la solution — restent d'actualité et s'appliquent à la conception des systèmes en microservices.
Dans son livre " Composite/Structured Design " [8], Glenford J. Myers explique comment structurer du code procédural pour en réduire la complexité. Dès la première page de l'ouvrage, il écrit :
Le sujet de la complexité va bien au-delà de la simple minimisation de la complexité locale de chaque partie d'un programme. Un type de complexité bien plus important est la complexité globale : la complexité de la structure d'ensemble d'un programme ou d'un système (c'est-à-dire le degré d'association ou d'interdépendance entre ses principaux éléments).
Dans notre contexte, la complexité locale est celle de chaque microservice pris individuellement, tandis que la complexité globale est celle de l'ensemble du système. La complexité locale dépend de l'implémentation d'un service ; la complexité globale est définie par les interactions et dépendances entre les services.
Alors, quelle complexité prime — la locale ou la globale ? Voyons ce qui se passe lorsqu'on ne traite que l'une des deux.
Il est étonnamment simple de réduire la complexité globale au minimum. Il suffit d'éliminer toute interaction entre les composants du système — autrement dit, d'implémenter toutes les fonctionnalités dans un seul service monolithique. Comme on l'a vu, cette stratégie peut fonctionner dans certains cas. Dans d'autres, elle mène à la redoutable grosse boule de boue — sans doute le plus haut niveau possible de complexité locale.
À l'inverse, on sait ce qui se produit lorsqu'on optimise uniquement la complexité locale en négligeant la complexité globale du système : la plus redoutable encore grosse boule de boue distribuée.
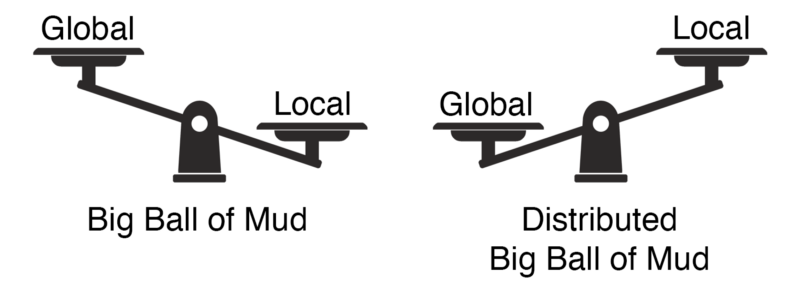
Ainsi, si l'on se focalise sur un seul type de complexité, peu importe lequel : dans un système distribué un tant soit peu complexe, l'autre explose. Impossible donc de n'en optimiser qu'une seule. Il faut au contraire équilibrer les deux : la complexité locale et la complexité globale.
Fait intéressant, les moyens d'équilibrer la complexité décrits dans " Composite/Structured Design " ne s'appliquent pas qu'aux systèmes distribués. Ils éclairent aussi la conception des microservices.
Les microservices
Commençons par définir ce que sont au juste ces services et microservices dont nous parlons.
Qu'est-ce qu'un service ?
Selon la norme OASIS [9], un service est :
Un mécanisme permettant l'accès à une ou plusieurs capacités, l'accès étant fourni via une interface prescrite.
La notion d'interface prescrite est cruciale. L'interface d'un service définit les fonctionnalités qu'il expose au monde extérieur. Selon Randy Shoup [10], l'interface publique d'un service, c'est tout simplement n'importe quel mécanisme permettant aux données d'entrer ou de sortir du service. Elle peut être synchrone, comme un simple modèle requête/réponse, ou asynchrone, à base d'événements produits et consommés. Synchrone ou asynchrone, l'interface publique n'est qu'un moyen de faire entrer ou sortir des données. Randy compare aussi ces interfaces à la porte d'entrée du service.
Un service se définit par son interface publique, et cette définition suffit à cerner ce qui fait d'un service un microservice.
Qu'est-ce qu'un microservice ?
Si un service se définit par son interface publique, alors —
Un microservice est un service doté d'une micro-interface publique — une micro-porte d'entrée.
Cette heuristique simple était déjà appliquée à l'époque de la programmation procédurale, et elle est plus que jamais pertinente dans l'univers des systèmes distribués. Plus le service exposé est petit, plus son implémentation est simple, et plus sa complexité locale est faible. Côté complexité globale, des interfaces publiques plus restreintes engendrent moins de dépendances et de connexions entre services.
La notion de micro-interfaces explique aussi pourquoi les microservices n'exposent généralement pas leurs bases de données. Aucun microservice ne peut accéder à la base d'un autre, sinon via son interface publique. Pourquoi ? — Tout simplement parce qu'une base de données serait une interface publique gigantesque ! Songez au nombre d'opérations que l'on peut exécuter sur une base relationnelle.
Pour résumer, dans les systèmes distribués, on équilibre les complexités locale et globale en réduisant au minimum les interfaces publiques des services — qui deviennent ainsi des micro-services.
ATTENTION
Cette heuristique peut sembler trompeusement simple. Si un microservice n'est qu'un service doté d'une micro-interface publique, il suffirait de limiter cette interface à une seule méthode. Et puisque la porte d'entrée ne peut guère être plus étroite, on obtiendrait les microservices parfaits, non ? Pas vraiment. Pour expliquer pourquoi, je reprends l'exemple de mon précédent article [11] sur le sujet :
Imaginons le service de gestion de backlog suivant :
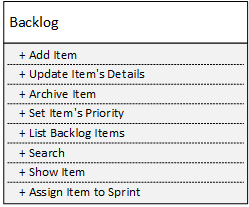
Une fois décomposé en huit services dotés chacun d'une seule méthode publique, on obtient des services à la complexité locale parfaite :
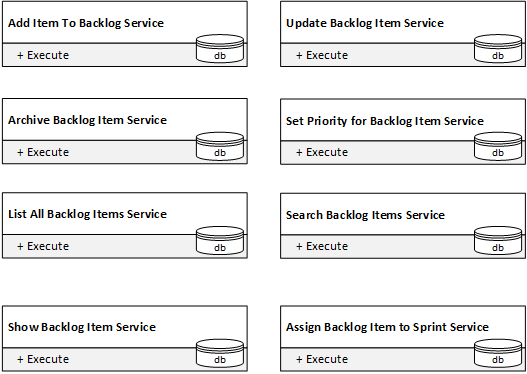
Mais peut-on les connecter pour former le système qui gère réellement le backlog ? Pas vraiment. Pour constituer le système, les services doivent interagir et partager les changements d'état de chacun. Or ils en sont incapables. Leurs interfaces publiques ne le permettent pas.
Il faut donc élargir les portes d'entrée avec des méthodes publiques qui permettent l'intégration entre les services :
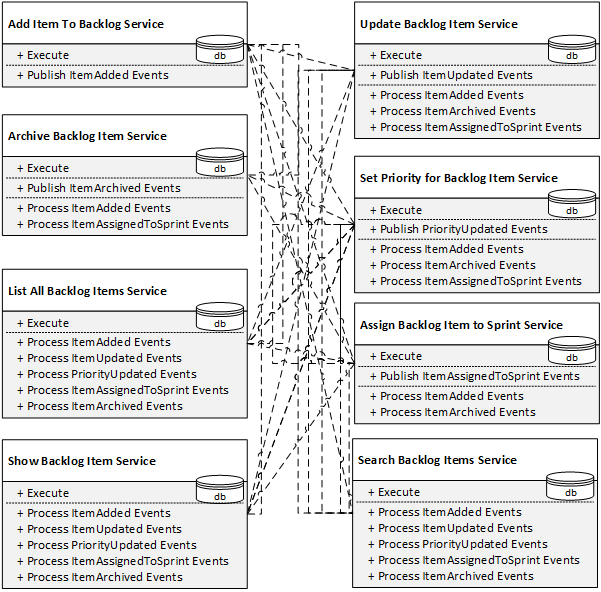
Bingo. Si l'on optimise la complexité de chaque service séparément, la décomposition naïve fonctionne à merveille. Mais dès qu'on relie les services pour former un système, la complexité globale entre en scène. Non seulement le système final devient un fouillis enchevêtré, mais on doit aussi étoffer les interfaces publiques bien au-delà de l'intention initiale — pour les besoins de l'intégration. Pour paraphraser Randy Shoup : en plus de la porte d'entrée minuscule, on a créé une énorme entrée " réservée au personnel " ! Ce qui nous amène à un point important :
Un service comportant plus de méthodes d'intégration que de méthodes métier est un fort indice de grosse boule de boue distribuée en formation !
Le seuil jusqu'auquel on peut réduire l'interface publique d'un service ne dépend donc pas seulement du service lui-même, mais (surtout) du système dont il fait partie. Une décomposition correcte en microservices doit équilibrer la complexité globale du système et les complexités locales de ses services.
Concevoir les frontières des services
" Trouver les frontières des services, c'est sacrément difficile… Il n'y a pas d'organigramme magique ! " — Udi Dahan
Cette affirmation d'Udi Dahan vaut tout particulièrement pour les systèmes en microservices. Concevoir les frontières des microservices est ardu, et probablement impossible à réussir du premier coup. La conception d'un système en microservices un tant soit peu complexe est donc un processus itératif.
Mieux vaut alors partir de frontières plus larges — typiquement celles de bounded contexts bien définis [12] — et les décomposer ensuite en microservices, à mesure que la connaissance du système et de son domaine métier s'affine. Cela vaut particulièrement pour les services couvrant des domaines métier centraux [13].
Les microservices au-delà des systèmes distribués
Si les microservices ont été " inventés " récemment, on retrouve de nombreuses incarnations des mêmes principes de conception dans d'autres domaines. Parmi elles :
Les équipes pluridisciplinaires
Nous savons tous que les équipes pluridisciplinaires sont les plus efficaces. Une telle équipe rassemble des profils variés autour d'une même mission. Une équipe pluridisciplinaire performante maximise la communication en interne et la minimise vers l'extérieur.
Notre secteur n'a découvert ces équipes que récemment, mais les task forces existent depuis toujours. Les principes sous-jacents sont les mêmes que pour un système en microservices : forte cohésion à l'intérieur de l'équipe et faible couplage entre les équipes. L'" interface publique " de l'équipe est minimisée en y intégrant les compétences nécessaires à la mission (autrement dit, les détails d'implémentation).
Les microprocesseurs
Je suis tombé sur cet exemple dans l'excellent billet de blog de Vaughn Vernon sur le même sujet. Vaughn y trace un parallèle intéressant entre micro-services et micro-processeurs. Il s'arrête notamment sur la différence entre processeurs et microprocesseurs :
Je trouve intéressant qu'il existe une classification de taille permettant de déterminer si une unité centrale (CPU) est ou non un microprocesseur : la taille de son bus de données [21]
Le bus de données d'un microprocesseur est son interface publique : il définit la quantité de données pouvant transiter entre le microprocesseur et les autres composants. Il existe une classification de taille stricte de l'interface publique qui détermine si une unité centrale (CPU) est ou non un microprocesseur.
La philosophie Unix
La philosophie Unix, ou la " voie Unix ", est un ensemble de normes culturelles et d'approches philosophiques pour un développement logiciel minimaliste et modulaire [22].
D'aucuns objecteront que la philosophie Unix contredit ma thèse selon laquelle on ne peut pas bâtir un système à partir de composants entièrement indépendants : les programmes Unix ne sont-ils pas pleinement indépendants tout en formant un système qui fonctionne ? C'est exactement l'inverse. La voie Unix impose presque littéralement aux programmes d'exposer des micro-interfaces. Voyons comment ses principes rejoignent la notion de microservices :
Le premier principe veut que les interfaces publiques des programmes exposent une fonction cohérente, plutôt que d'encombrer les programmes de fonctionnalités sans rapport avec leur objectif initial :
Faites en sorte que chaque programme fasse une seule chose, et qu'il la fasse bien. Pour accomplir une nouvelle tâche, repartez de zéro plutôt que d'alourdir d'anciens programmes en y ajoutant de nouvelles " fonctionnalités ".
Bien que les commandes Unix soient considérées comme totalement indépendantes les unes des autres, elles ne le sont pas. Elles doivent communiquer entre elles, et le second principe définit comment concevoir leurs interfaces de communication :
Attendez-vous à ce que la sortie de chaque programme devienne l'entrée d'un autre programme, encore inconnu. N'encombrez pas la sortie d'informations superflues. Évitez les formats d'entrée strictement colonnaires ou binaires. N'imposez pas une saisie interactive.
Non seulement l'interface de communication est strictement limitée (entrée standard, sortie standard et erreur standard), mais selon ce principe, les données échangées entre commandes doivent l'être tout autant. Autrement dit, les commandes Unix doivent exposer des micro-interfaces et ne jamais dépendre des détails d'implémentation des autres.
Et les _nano_services ?
Le terme " nanoservice " désigne souvent un service trop petit. On pourrait dire que les services naïfs à une seule méthode de l'exemple précédent en sont. Je ne suis cependant pas tout à fait d'accord avec cette classification.
La notion de nanoservice s'attache à des services pris isolément, en faisant abstraction du système global. Or dans l'exemple précédent, dès qu'on a réintégré le système dans l'équation, les interfaces des services ont dû s'étoffer. En comparant l'implémentation d'origine à un seul service avec la décomposition naïve, on constate qu'une fois les services connectés en un système, on passe de 8 méthodes publiques au total à 38. Et le nombre moyen de méthodes publiques par service grimpe de la cible visée — 1 — à 4,75.
Ainsi, si l'on optimise les services (les interfaces publiques) au lieu des bases de code, le terme nano-service ne tient plus, car le service est forcé de grossir à nouveau pour couvrir les cas d'usage de son système.
Est-ce vraiment tout ?
Non. Réduire au minimum les interfaces publiques des services est un bon principe directeur pour concevoir des microservices, mais cela reste une heuristique qui ne dispense pas du bon sens. La micro-interface n'est en réalité qu'une forme d'abstraction de principes plus fondamentaux mais bien plus complexes : le couplage et la cohésion.
Par exemple, si deux services possèdent des micro-interfaces publiques mais doivent être coordonnés au sein d'une transaction distribuée, ils restent fortement couplés.
Cela dit, viser des micro-interfaces reste une heuristique solide qui adresse plusieurs types de couplage : fonctionnel, de développement et sémantique. Mais ce sera l'objet d'un autre article.
De la théorie à la pratique
Malheureusement, nous ne disposons pas encore d'un moyen objectif de quantifier les complexités locale et globale. En revanche, quelques heuristiques de conception peuvent aider à améliorer la conception des systèmes distribués.
Le message principal de cet article : évaluez en continu les interfaces publiques de vos services en vous posant ces questions :
- Quel est le ratio entre endpoints orientés métier et endpoints orientés intégration dans un service donné ?
- Y a-t-il, sur le plan métier, des endpoints sans rapport entre eux dans un même service ? Pouvez-vous les répartir entre deux services ou plus sans introduire d'endpoints d'intégration ?
- La fusion de deux services ferait-elle disparaître des endpoints ajoutés uniquement pour intégrer les services d'origine ?
Servez-vous de ces heuristiques pour guider la conception des frontières et des interfaces de vos services.
Synthèse
Je voudrais conclure avec une citation d'Eliyahu Goldratt. Dans ses livres, il répétait souvent ces mots :
" Dis-moi comment tu me mesures, et je te dirai comment je me comporterai. " ~ Eliyahu Goldratt
Lorsqu'on conçoit un système en microservices, il est crucial de mesurer et d'optimiser la bonne métrique. Concevoir des frontières pour des micro-bases de code et des micro-équipes est nettement plus facile. Mais pour bâtir un système, il faut justement le prendre en compte. Les microservices, c'est concevoir des systèmes, pas des services individuels.
Et cela nous ramène au titre de l'article : " Démêler les microservices, ou équilibrer la complexité dans les systèmes distribués ". La seule façon de démêler les microservices, c'est d'équilibrer la complexité locale de chaque service et la complexité globale de l'ensemble du système.
Bibliographie
- Tweet de Gergely Orosz sur Uber
- Monoliths are the future
- Un gourou des microservices avertit les développeurs que cette architecture à la mode ne devrait pas être le choix par défaut, mais " un dernier recours "
- Application monolithique (Wikipédia)
- The Majestic Monolith — DHH
- Big Ball of Mud (Wikipédia)
- Définition d'un système
- Composite/Structures Design — livre de Glenford J. Myers
- Reference Model for Service Oriented Architecture
- Managing Data in Microservices — conférence de Randy Shoup
- Tackling Complexity in Microservices
- Bounded Contexts are NOT Microservices
- Revisiting the Basics of Domain-Driven Design
- Implementing Domain-Driven Design — livre de Vaughn Vernon
- Modular Monolith: A Primer — Kamil Grzybek
- A Design Methodology for Reliable Software Systems — Barbara Liskov
- Designing Autonomous Teams and Services
- Emergent Boundaries — conférence de Mathias Verraes
- Long Sad Story of Microservices — conférence de Greg Young
- Principles of Design — Tim Berners-Lee
- Microservices and [Micro]services — Vaughn Vernon
- Philosophie Unix
Article initialement publié sur vladikk.com le 9 avril 2020.