
La luna di miele dei microservizi è finita. Uber sta riscrivendo migliaia di microservizi in una soluzione più gestibile [1]; Kelsey Hightower prevede che il futuro sia dei monoliti [2]; persino Sam Newman sostiene che i microservizi non dovrebbero mai essere la scelta predefinita, ma l'ultima spiaggia [3].
Cosa sta succedendo? Perché così tanti progetti sono diventati ingestibili, nonostante la promessa di semplicità e flessibilità dei microservizi? O forse, in fondo, i monoliti sono la scelta migliore?
In questo articolo voglio rispondere a queste domande. Vedremo i tipici errori di design che trasformano i microservizi in big ball of mud distribuite e, ovviamente, come evitarli.
Ma prima, facciamo chiarezza su cosa sia davvero un monolite.
Il monolite
I microservizi sono sempre stati presentati come la soluzione ai codebase monolitici. Ma i monoliti sono per forza un problema? Secondo la definizione di Wikipedia [4], un'applicazione monolitica è autonoma e indipendente da altre applicazioni informatiche. Indipendenza da altre applicazioni? Non è proprio quello che inseguiamo, spesso invano, quando progettiamo microservizi? David Heinemeier Hansson [5] ha smontato subito la cattiva fama dei monoliti. Ha messo in guardia sui rischi e sulle sfide intrinseche ai sistemi distribuiti e ha portato Basecamp come prova che un grande sistema al servizio di milioni di clienti può essere realizzato e mantenuto in un codebase monolitico.
I microservizi, dunque, non "risolvono" i monoliti. Il vero problema che i microservizi dovrebbero affrontare è l'incapacità di raggiungere gli obiettivi di business. Spesso i team falliscono perché i costi del cambiamento crescono in modo esponenziale o, peggio, imprevedibile. In altre parole, il sistema non riesce a stare al passo con le esigenze del business. Questo costo incontrollabile del cambiamento non è una caratteristica del monolite, bensì della big ball of mud [6]:
Una Big Ball of Mud è una giungla di codice spaghetti strutturata alla rinfusa, sciatta, dispersiva, tenuta insieme con nastro adesivo e fil di ferro. Questi sistemi mostrano segni inequivocabili di crescita incontrollata e di rattoppi continui e improvvisati. Le informazioni vengono condivise senza criterio tra elementi distanti del sistema, al punto che quasi tutti i dati importanti diventano globali o duplicati.
La complessità nel modificare e far evolvere una big ball of mud può dipendere da molti fattori: il coordinamento tra più team, requisiti non funzionali in conflitto o un dominio di business intricato. In ogni caso, la strada che si imbocca per affrontare questa complessità è spesso la stessa: scomporre quelle soluzioni ingombranti in microservizi.
Micro- cosa?
Il termine "microservizio" suggerisce che alcune caratteristiche di un servizio possano essere misurate e che il loro valore vada ridotto al minimo. Ma cosa significa, esattamente, microservizio? Esaminiamo alcuni dei modi più comuni in cui il termine viene usato.
Micro-team
Il primo riguarda la dimensione del team che lavora a un servizio. E questa metrica andrebbe misurata in pizze. Sul serio. Si dice che, se un team che lavora a un servizio si sazia con due pizze, allora si tratta di un microservizio. Trovo questa euristica del tutto aneddotica: ho lavorato a progetti con team che si sarebbero saziati con una sola pizza… e sfido chiunque a definire microservizi quelle big ball of mud!
Micro-codebase
Un altro approccio diffuso è progettare un microservizio in base alla dimensione del suo codebase. C'è chi porta questa idea all'estremo, cercando di limitare i servizi a un numero preciso di righe di codice. Detto ciò, il numero esatto di righe necessarie per costituire un microservizio resta tutto da scoprire. Una volta trovato questo Sacro Graal dell'architettura software, passeremo alla domanda successiva: qual è la larghezza dell'editor consigliata per scrivere microservizi?
Scherzi a parte, una versione meno radicale di questo approccio è quella più diffusa: la dimensione del codebase viene spesso usata come euristica per stabilire se un servizio sia o meno un microservizio.
In un certo senso, il ragionamento ha una sua logica. Più piccolo è il codebase, più ristretto è l'ambito del dominio di business. È quindi più semplice da capire, da implementare e da far evolvere. Inoltre, un codebase più piccolo ha meno probabilità di trasformarsi in una big ball of mud e, se accade, è più facile da rifattorizzare.
Purtroppo, questa semplicità è solo un'illusione. Quando valutiamo il design di un servizio guardando solo al servizio stesso, ci sfugge una parte cruciale del design del sistema. Dimentichiamo il sistema, ovvero ciò di cui il servizio è un componente.
"Esistono molte euristiche utili e illuminanti per definire i confini di un servizio. La dimensione è una delle meno utili." ~ Nick Tune
Costruiamo sistemi!
Costruiamo sistemi, non insiemi di servizi. Adottiamo un'architettura a microservizi per ottimizzare il design del sistema, non quello dei singoli servizi. Checché ne dicano gli altri, i microservizi non potranno mai essere completamente disaccoppiati né del tutto indipendenti. Non si può costruire un sistema fatto di componenti separati! Sarebbe in contrasto con la definizione stessa di "sistema" [7]:
1. Un insieme di cose o dispositivi collegati che operano insieme
2. Un insieme di apparecchiature e programmi informatici utilizzati insieme per uno scopo specifico
I servizi dovranno sempre interagire tra loro per formare un sistema. Se progetta un sistema ottimizzando i singoli servizi ma ignorando le loro interazioni, ecco il risultato che rischia di ottenere:

Quei "microservizi" possono anche essere semplici se presi singolarmente, ma il sistema nel suo insieme è un inferno di complessità!
Allora, come si progettano microservizi capaci di tenere a bada la complessità non solo dei servizi, ma del sistema nel suo complesso?
È una domanda difficile, ma per nostra fortuna ha trovato risposta molto tempo fa.
La complessità in un'ottica di sistema
Quarant'anni fa non esistevano il cloud computing, i requisiti su scala globale né la necessità di rilasciare un sistema ogni 11,7 secondi. Ma gli ingegneri dovevano comunque domare la complessità dei sistemi. Anche se gli strumenti erano diversi, le sfide — e, soprattutto, la soluzione — sono ancora attualissime e si possono applicare al design dei sistemi a microservizi.
Nel suo libro "Composite/Structured Design" [8], Glenford J. Myers spiega come strutturare il codice procedurale per ridurne la complessità. Già nella prima pagina scrive:
Il tema della complessità va ben oltre il semplice tentativo di minimizzare la complessità locale di ciascuna parte di un programma. Un tipo di complessità molto più importante è quella globale: la complessità della struttura complessiva di un programma o di un sistema (ossia il grado di associazione o di interdipendenza tra le sue parti principali).
Nel nostro contesto, la complessità locale è quella di ogni singolo microservizio, mentre la complessità globale è quella dell'intero sistema. La complessità locale dipende dall'implementazione di un servizio; quella globale è definita dalle interazioni e dipendenze tra i servizi.
Quale delle due conta di più, dunque: quella locale o quella globale? Vediamo cosa accade quando ci si occupa di una sola.
Ridurre al minimo la complessità globale è sorprendentemente semplice: basta eliminare ogni interazione tra i componenti, cioè implementare tutto in un unico servizio monolitico. Come abbiamo visto, in alcuni scenari questa strategia funziona; in altri porta dritti alla temuta big ball of mud, probabilmente il livello più alto possibile di complessità locale.
D'altro canto, sappiamo cosa succede quando si ottimizza solo la complessità locale trascurando quella globale: si finisce nella ancora più temuta big ball of mud distribuita.
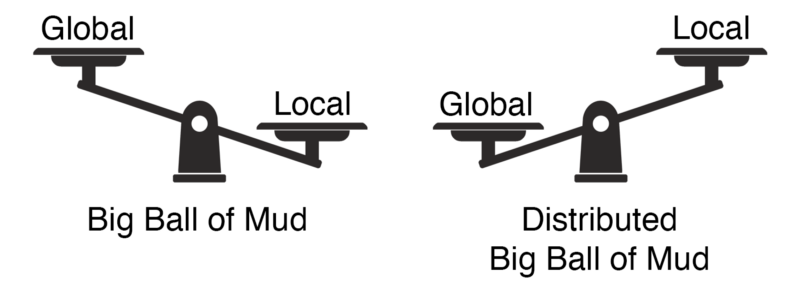
Quindi, se ci si concentra su un solo tipo di complessità, non importa quale. In un sistema distribuito di una certa complessità, l'altra schizzerà alle stelle. Non possiamo ottimizzarne solo una: dobbiamo bilanciare complessità locale e globale.
Curiosamente, gli strumenti per bilanciare la complessità descritti in "Composite/Structured Design" non valgono solo per i sistemi distribuiti: offrono spunti preziosi anche per progettare microservizi.
Microservizi
Cominciamo col definire cosa siano davvero questi servizi e microservizi di cui stiamo parlando.
Cos'è un servizio?
Secondo lo standard OASIS [9], un servizio è:
Un meccanismo che consente l'accesso a una o più capacità, dove l'accesso è fornito tramite un'interfaccia prescritta.
La parte sull'interfaccia prescritta è cruciale. L'interfaccia di un servizio definisce le funzionalità che esso espone all'esterno. Secondo Randy Shoup [10], l'interfaccia pubblica di un servizio è semplicemente qualunque meccanismo che faccia entrare o uscire dati dal servizio. Può essere sincrona, come un classico modello richiesta/risposta, o asincrona, ovvero basata sulla produzione e sul consumo di eventi. In ogni caso, sincrona o asincrona, l'interfaccia pubblica è solo il mezzo per far entrare o uscire dati dal servizio. Randy descrive le interfacce pubbliche del servizio anche come la sua porta principale.
Un servizio è definito dalla sua interfaccia pubblica, e questa definizione è già sufficiente per stabilire cosa renda un servizio un microservizio.
Cos'è un microservizio?
Se un servizio è definito dalla sua interfaccia pubblica, allora —
Un microservizio è un servizio con un'interfaccia pubblica micro: una micro porta principale.
Questa semplice euristica veniva già seguita ai tempi della programmazione procedurale ed è più che mai attuale nel mondo dei sistemi distribuiti. Più piccolo è il servizio che si espone, più semplice è la sua implementazione e più bassa la sua complessità locale. Sul fronte della complessità globale, interfacce pubbliche più piccole producono meno dipendenze e connessioni tra i servizi.
Il concetto di micro-interfaccia spiega anche la pratica diffusa di non esporre i database dei microservizi. Nessun microservizio può accedere al database di un altro se non attraverso l'interfaccia pubblica. Perché? — Beh, un database sarebbe un'interfaccia pubblica enorme! Basti pensare a quante operazioni diverse si possono eseguire su un database relazionale.
Riassumendo: nei sistemi distribuiti bilanciamo complessità locale e globale minimizzando le interfacce pubbliche dei servizi, rendendoli così micro servizi.
ATTENZIONE
Questa euristica può sembrare ingannevolmente semplice. Se un microservizio è solo un servizio con un'interfaccia pubblica micro, basta limitare le interfacce pubbliche a un solo metodo. Visto che la porta principale non può essere più piccola di così, dovremmo aver creato i microservizi perfetti, no? Non proprio. Per spiegare il perché, riprendo l'esempio del mio altro articolo [11] sull'argomento:
Supponiamo di avere il seguente servizio di gestione del backlog:
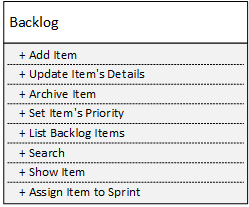
Una volta scomposto in otto servizi, ognuno con un solo metodo pubblico, otteniamo servizi con complessità locali perfette:
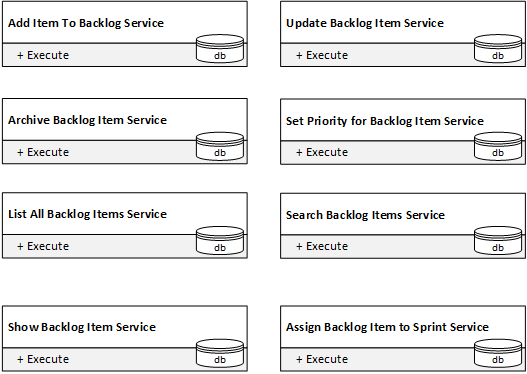
Ma riusciamo a collegarli per formare il sistema che gestisce davvero il backlog? Non proprio. Per dare vita al sistema, i servizi devono interagire e condividere le modifiche al proprio stato. Ma non possono. Le loro interfacce pubbliche non lo permettono.
Dobbiamo quindi ampliare le porte principali con metodi pubblici che abilitino l'integrazione tra i servizi:
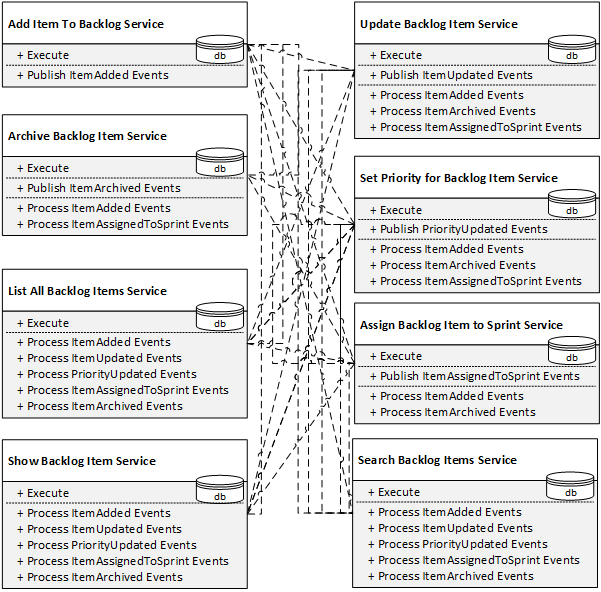
Boom. Se ottimizziamo la complessità di ciascun servizio singolarmente, la decomposizione ingenua funziona alla grande. Ma quando proviamo a collegare i servizi in un sistema, entra in gioco la complessità globale. Il sistema risultante non solo si trasforma in un groviglio intricato: siamo anche costretti ad ampliare le interfacce pubbliche oltre l'intento originario, in nome dell'integrazione. Parafrasando Randy Shoup, oltre alla minuscola porta principale abbiamo creato un enorme ingresso "riservato al personale". Il che ci porta a un punto importante:
Quando un servizio ha più metodi orientati all'integrazione che al business, è un forte segnale di una big ball of mud distribuita in fase di crescita!
La soglia entro cui l'interfaccia pubblica di un servizio può essere ridotta dipende quindi non solo dal servizio in sé, ma (soprattutto) dal sistema di cui fa parte. Una corretta decomposizione in microservizi deve bilanciare la complessità globale del sistema con le complessità locali dei singoli servizi.
Progettare i confini dei servizi
"Trovare i confini dei servizi è dannatamente difficile… Non esiste un diagramma di flusso!" — Udi Dahan
L'affermazione di Udi Dahan è particolarmente vera per i sistemi a microservizi. Progettare i confini dei microservizi è difficile e probabilmente impossibile da azzeccare al primo tentativo. Per questo, progettare un sistema a microservizi di una certa complessità è un processo iterativo.
È più prudente partire da confini più ampi — probabilmente quelli di bounded context ben definiti [12] — e scomporli poi in microservizi man mano che si acquisisce maggiore conoscenza del sistema e del suo dominio di business. Vale soprattutto per i servizi che racchiudono i domini di business core [13].
I microservizi al di fuori dei sistemi distribuiti
Anche se i microservizi sono stati "inventati" solo di recente, è facile trovare applicazioni degli stessi principi di design in altri ambiti. Ne vediamo alcuni:
Team cross-funzionali
Sappiamo tutti che i team cross-funzionali sono i più efficaci. Si tratta di gruppi eterogenei di professionisti che lavorano insieme allo stesso obiettivo. Un team cross-funzionale efficiente massimizza la comunicazione interna e minimizza quella verso l'esterno.
Il nostro settore ha scoperto i team cross-funzionali solo di recente, ma le task force esistono da sempre. I principi sono gli stessi di un sistema a microservizi: alta coesione all'interno del team e basso accoppiamento tra team. L'"interfaccia pubblica" del team viene ridotta al minimo includendo al suo interno tutte le competenze necessarie a portare a termine il compito (ovvero i dettagli implementativi).
Microprocessori
Mi sono imbattuto in questo esempio nel bellissimo blog di Vaughn Vernon dedicato allo stesso tema. Nel suo articolo, Vaughn traccia un parallelo molto interessante tra micro servizi e micro processori. In particolare, parla della differenza tra processori e microprocessori:
Trovo curioso che esista una classificazione dimensionale che aiuta a stabilire se una unità centrale di elaborazione (CPU) sia o meno un microprocessore: la dimensione del suo data bus [21]
Il data bus di un microprocessore è la sua interfaccia pubblica: definisce la quantità di dati trasferibili tra il microprocessore e gli altri componenti. Esiste una rigida classificazione dimensionale dell'interfaccia pubblica che stabilisce se una CPU sia o meno un microprocessore.
La filosofia Unix
La filosofia Unix, o Unix way, è un insieme di norme culturali e di approcci filosofici allo sviluppo software minimalista e modulare [22].
Si potrebbe obiettare che la filosofia Unix contraddica la mia tesi secondo cui non si può costruire un sistema fatto di componenti del tutto indipendenti: i programmi Unix non sono forse del tutto indipendenti e, ciononostante, formano un sistema funzionante? È vero il contrario. La Unix way stabilisce quasi alla lettera che i programmi devono esporre micro-interfacce. Vediamo come i suoi principi si rapportano al concetto di microservizio:
Il primo principio impone che le interfacce pubbliche dei programmi espongano un'unica funzione coerente, anziché riempirsi di funzionalità non legate al loro obiettivo originario:
Fai in modo che ogni programma faccia bene una sola cosa. Per affrontare un nuovo compito, parti da zero anziché complicare i vecchi programmi aggiungendo nuove "funzionalità".
Anche se i comandi Unix sono considerati del tutto indipendenti gli uni dagli altri, in realtà non lo sono: devono pur sempre comunicare. Il secondo principio definisce come progettare le interfacce di comunicazione:
Aspettati che l'output di ogni programma diventi l'input di un altro programma, ancora sconosciuto. Non ingombrare l'output con informazioni superflue. Evita formati di input rigidamente colonnari o binari. Non insistere sull'input interattivo.
Non solo l'interfaccia di comunicazione è strettamente limitata (input standard, output standard ed errore standard), ma secondo questo principio anche i dati scambiati tra i comandi devono esserlo. In altre parole, i comandi Unix devono esporre micro-interfacce e non dipendere mai dai dettagli implementativi gli uni degli altri.
E i _nano_servizi?
Il termine "nanoservizio" viene spesso usato per descrivere un servizio troppo piccolo. Si potrebbe sostenere che gli ingenui servizi a metodo singolo dell'esempio precedente siano nanoservizi. Personalmente, però, non sono d'accordo con questa classificazione.
Si parla di nanoservizi guardando ai singoli servizi e ignorando il sistema che li racchiude. Nell'esempio precedente, una volta inserito il sistema nell'equazione, le interfacce dei servizi hanno dovuto crescere. Anzi, confrontando l'implementazione originaria a servizio unico con la decomposizione ingenua, vediamo che, una volta collegati i servizi in un sistema, si passa da 8 metodi pubblici complessivi a 38. E il numero medio di metodi pubblici per servizio sale dall'auspicato 1 fino a 4,75.
Quindi, se invece dei codebase ottimizziamo i servizi (le interfacce pubbliche), il termine nano-servizio non regge più, perché il servizio è costretto a crescere di nuovo per supportare i casi d'uso del suo sistema.
È tutto qui?
No. Anche se ridurre al minimo le interfacce pubbliche dei servizi è un buon principio guida per progettare microservizi, resta un'euristica e non sostituisce il buon senso. La micro-interfaccia, in fondo, è solo una sorta di astrazione dei principi di design ben più fondamentali, e ben più complessi, di accoppiamento e coesione.
Per esempio, se due servizi hanno micro-interfacce pubbliche ma devono essere coordinati in una transazione distribuita, restano fortemente accoppiati tra loro.
Detto questo, puntare alle micro-interfacce è comunque un'euristica solida che affronta diversi tipi di accoppiamento: funzionale, di sviluppo e semantico. Ma questo è materiale per un altro articolo.
Dalla teoria alla pratica
Purtroppo non disponiamo ancora di un modo oggettivo per quantificare la complessità locale e quella globale. Abbiamo però alcune euristiche di design che possono migliorare la progettazione dei sistemi distribuiti.
Il messaggio centrale di questo articolo è che dovrebbe valutare costantemente le interfacce pubbliche dei suoi servizi ponendosi queste domande:
- Qual è il rapporto tra endpoint orientati al business ed endpoint orientati all'integrazione in un dato servizio?
- Esistono, dal punto di vista del business, endpoint scollegati tra loro all'interno di uno stesso servizio? È possibile distribuirli su due o più servizi senza introdurre endpoint orientati all'integrazione?
- Unire due servizi eliminerebbe gli endpoint aggiunti per integrarli?
Si lasci guidare da queste euristiche nella progettazione dei confini e delle interfacce dei suoi servizi.
In sintesi
Voglio chiudere con una citazione di Eliyahu Goldratt. Nei suoi libri ripeteva spesso queste parole:
"Dimmi come mi misuri e ti dirò come mi comporterò" ~ Eliyahu Goldratt
Quando si progettano sistemi a microservizi, è cruciale misurare e ottimizzare la metrica giusta. Definire i confini di micro codebase e micro team è senz'altro più facile. Ma per costruire un sistema, è il sistema che dobbiamo tenere in considerazione. I microservizi riguardano la progettazione dei sistemi, non dei singoli servizi.
E così torniamo al titolo di questo articolo: "Districare i microservizi: come bilanciare la complessità nei sistemi distribuiti". L'unico modo per districare i microservizi è bilanciare la complessità locale di ciascun servizio con la complessità globale dell'intero sistema.
Bibliografia
- Tweet di Gergely Orosz su Uber
- Monoliths are the future
- Microservices guru warns devs that trendy architecture shouldn't be the default for every app, but 'a last resort'
- Monolithic Application (Wikipedia)
- The Majestic Monolith — DHH
- Big Ball of Mud (Wikipedia)
- Definition of a System
- Composite/Structures Design — libro di Glenford J. Myers
- Reference Model for Service Oriented Architecture
- Managing Data in Microservices — talk di Randy Shoup
- Tackling Complexity in Microservices
- Bounded Contexts are NOT Microservices
- Revisiting the Basics of Domain-Driven Design
- Implementing Domain-Driven Design — libro di Vaughn Vernon
- Modular Monolith: A Primer — Kamil Grzybek
- A Design Methodology for Reliable Software Systems — Barbara Liskov
- Designing Autonomous Teams and Services
- Emergent Boundaries — talk di Mathias Verraes
- Long Sad Story of Microservices — talk di Greg Young
- Principles of Design — Tim Berners-Lee
- Microservices and [Micro]services — Vaughn Vernon
- Unix Philosophy
Pubblicato originariamente su vladikk.com il 9 aprile 2020.