
Se acabó la luna de miel con los microservicios. Uber está refactorizando miles de microservicios hacia una solución más manejable [1]; Kelsey Hightower predice que los monolitos son el futuro [2]; e incluso Sam Newman sostiene que los microservicios nunca deberían ser la opción por defecto, sino un último recurso [3].
¿Qué está pasando? ¿Por qué tantos proyectos terminan siendo imposibles de mantener, a pesar de la promesa de simplicidad y flexibilidad de los microservicios? ¿O será que los monolitos son mejores, después de todo?
En este post quiero responder a estas preguntas. Vas a conocer los problemas de diseño más comunes que convierten a los microservicios en grandes bolas de lodo distribuidas y, claro, cómo evitarlos.
Pero antes, dejemos claro qué es un monolito.
Monolito
Los microservicios siempre se han presentado como la solución para las bases de código monolíticas. Pero ¿son los monolitos un problema en sí mismos? Según la definición de Wikipedia [4], una aplicación monolítica es autocontenida e independiente de otras aplicaciones de cómputo. ¿Independencia de otras aplicaciones? ¿No es justo eso lo que perseguimos, muchas veces sin éxito, cuando diseñamos microservicios? David Heinemeier Hansson [5] salió rápidamente a defender a los monolitos del descrédito. Advirtió sobre las desventajas y los retos propios de los sistemas distribuidos y usó Basecamp como prueba de que un sistema grande, que atiende a millones de clientes, puede implementarse y mantenerse en una base de código monolítica.
Por lo tanto, los microservicios no "arreglan" los monolitos. El verdadero problema que se supone que resuelven los microservicios es la incapacidad de cumplir los objetivos del negocio. Muchas veces, los equipos no logran sus metas por el costo —que crece de forma exponencial o, peor aún, impredecible— de hacer un cambio. En otras palabras, el sistema no logra seguir el ritmo de las necesidades del negocio. Ese costo de cambio incontrolable no es una característica del monolito, sino más bien de una gran bola de lodo [6]:
Una Big Ball of Mud es una jungla de código spaghetti, mal estructurada, desordenada, llena de parches y cinta adhesiva. Estos sistemas muestran señales inequívocas de un crecimiento sin control y de reparaciones repetidas y apresuradas. La información se comparte de forma promiscua entre elementos lejanos del sistema, hasta el punto en que casi toda la información importante se vuelve global o queda duplicada.
La complejidad de modificar y hacer evolucionar una gran bola de lodo puede deberse a varios factores: coordinar el trabajo de varios equipos, requerimientos no funcionales en conflicto o un dominio de negocio enrevesado. Sea como sea, lo común es que intentemos atacar esa complejidad descomponiendo estas soluciones torpes en microservicios.
Micro… ¿qué?
El término "microservicio" da a entender que algunas partes de un servicio se pueden medir y que su tamaño debería minimizarse. Pero ¿qué significa exactamente microservicio? Veamos algunas formas habituales de usar el término.
Microequipos
La primera tiene que ver con el tamaño del equipo que trabaja en un servicio. Y esa métrica debería medirse en pizzas. En serio. Dicen que si al equipo que trabaja en un servicio se le puede alimentar con dos pizzas, entonces es un microservicio. La heurística me parece anecdótica, ya que he construido proyectos con equipos a los que les bastaba una sola pizza… ¡y desafío a cualquiera a llamar microservicios a esas bolas de lodo!
Microbases de código
Otro enfoque muy difundido es diseñar un microservicio en función del tamaño de su base de código. Algunos llevan esta idea al extremo y tratan de limitar el tamaño de los servicios a cierto número de líneas de código. Eso sí, todavía está por descubrirse el número exacto de líneas que constituye un microservicio. Una vez que se encuentre ese santo grial de la arquitectura de software, pasaremos a la siguiente pregunta: ¿cuál es el ancho de editor recomendado para construir microservicios?
Hablando más en serio, una versión menos extrema de este enfoque es la dominante. El tamaño de la base de código suele usarse como heurística para decidir si algo es un microservicio o no.
De alguna manera, este enfoque tiene sentido. Mientras menor sea la base de código, menor es el alcance del dominio de negocio. Por lo tanto, es más simple de entender, implementar y evolucionar. Además, una base de código más pequeña tiene menos probabilidades de convertirse en una gran bola de lodo y, si llega a pasar, es más fácil refactorizarla.
Por desgracia, esa simplicidad de la que hablamos es solo una ilusión. Cuando evaluamos el diseño de un servicio basándonos solo en el servicio en sí, dejamos fuera una parte crucial del diseño del sistema. Olvidamos el sistema mismo, ese del que el servicio es un componente.
"Hay muchas heurísticas útiles y reveladoras para definir los límites de un servicio. El tamaño es una de las menos útiles." ~ Nick Tune
¡Construimos sistemas!
Construimos sistemas, no conjuntos de servicios. Usamos una arquitectura basada en microservicios para optimizar el diseño del sistema, no el diseño de los servicios individuales. Digan lo que digan, los microservicios no pueden, ni podrán, estar completamente desacoplados ni ser totalmente independientes. ¡No se puede construir un sistema a partir de componentes separados! Eso iría en contra de la definición misma del término "sistema" [7]:
1. Un conjunto de cosas o dispositivos conectados que operan en conjunto
2. Un conjunto de equipos y programas de cómputo usados juntos para un propósito particular
Los servicios siempre tendrán que interactuar entre sí para formar un sistema. Si diseñas un sistema optimizando sus servicios pero ignoras las interacciones entre ellos, puedes terminar con algo así:

Esos "microservicios" pueden ser simples por separado, pero ¡el sistema en su conjunto es un infierno de complejidad!
Entonces, ¿cómo diseñamos microservicios que aborden la complejidad no solo de los servicios, sino del sistema como un todo?
Es una pregunta difícil, pero por suerte para nosotros, ya se respondió hace mucho tiempo.
Una mirada a la complejidad desde todo el sistema
Hace cuarenta años no existía el cómputo en la nube, no había requerimientos a escala global ni necesidad de desplegar un sistema cada 11.7 segundos. Pero los ingenieros igual tenían que domar la complejidad de los sistemas. Aunque las herramientas de aquella época eran distintas, los retos —y, más importante aún, la solución— siguen siendo relevantes hoy y se pueden aplicar al diseño de sistemas basados en microservicios.
En su libro "Composite/Structured Design" [8], Glenford J. Myers analiza cómo estructurar el código procedural para reducir su complejidad. En la primera página del libro escribe:
El tema de la complejidad va mucho más allá de simplemente intentar minimizar la complejidad local de cada parte de un programa. Un tipo de complejidad mucho más importante es la complejidad global: la complejidad de la estructura general de un programa o sistema (es decir, el grado de asociación o interdependencia entre las piezas principales de un programa).
En nuestro contexto, la complejidad local es la complejidad de cada microservicio individual, mientras que la complejidad global es la complejidad de todo el sistema. La complejidad local depende de la implementación de un servicio; la complejidad global se define por las interacciones y dependencias entre los servicios.
Entonces, ¿cuál complejidad es más importante: la local o la global? Veamos qué pasa cuando solo se atiende una de ellas.
Es sorprendentemente fácil reducir la complejidad global al mínimo. Basta con eliminar cualquier interacción entre los componentes del sistema, es decir, implementar toda la funcionalidad en un solo servicio monolítico. Como ya vimos, esta estrategia puede funcionar en escenarios específicos. En otros, puede llevar a la temida gran bola de lodo, probablemente el nivel más alto posible de complejidad local.
Por otro lado, ya sabemos lo que pasa cuando solo optimizas la complejidad local pero descuidas la complejidad global del sistema: la aún más temida gran bola de lodo distribuida.
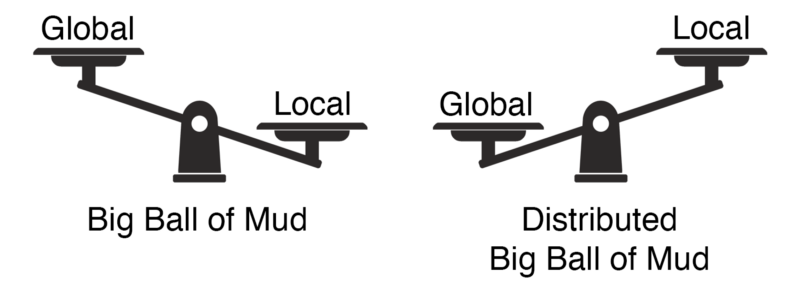
Por eso, si nos concentramos en un solo tipo de complejidad, no importa cuál elijamos: en un sistema distribuido medianamente complejo, la complejidad opuesta se dispara. Por lo tanto, no podemos optimizar solo una. Hay que equilibrar tanto la complejidad local como la global.
Curiosamente, los métodos para equilibrar la complejidad descritos en el libro "Composite/Structured Design" no solo son relevantes para los sistemas distribuidos. También aportan ideas valiosas sobre cómo diseñar microservicios.
Microservicios
Empecemos por definir qué son exactamente esos servicios y microservicios de los que estamos hablando.
¿Qué es un servicio?
Según el OASIS Standard [9], un servicio es:
Un mecanismo que habilita el acceso a una o más capacidades, donde el acceso se proporciona mediante una interfaz prescrita.
La parte de la "interfaz prescrita" es clave. La interfaz de un servicio define la funcionalidad que expone al mundo. Según Randy Shoup [10], la interfaz pública de un servicio es simplemente cualquier mecanismo que permite que los datos entren o salgan del servicio. Puede ser síncrona, como un modelo simple de petición/respuesta, o asíncrona, una que produce y consume eventos. En cualquier caso, síncrona o asíncrona, la interfaz pública es solo el medio por el cual los datos entran o salen del servicio. Randy también describe las interfaces públicas del servicio como su puerta principal.
Un servicio se define por su interfaz pública, y esa definición basta para entender qué hace que un servicio sea un microservicio.
¿Qué es un microservicio?
Si un servicio se define por su interfaz pública, entonces:
Un microservicio es un servicio con una micro interfaz pública: una micro puerta principal.
Esta heurística sencilla ya se aplicaba en los días de la programación procedural y es más que pertinente en el ámbito de los sistemas distribuidos. Mientras menor sea el servicio que expones, más simple es su implementación y menor su complejidad local. Desde el punto de vista de la complejidad global, las interfaces públicas más pequeñas generan menos dependencias y conexiones entre servicios.
La idea de las micro-interfaces también explica la práctica tan extendida de que los microservicios no expongan sus bases de datos. Ningún microservicio puede acceder a la base de datos de otro microservicio salvo a través de su interfaz pública. ¿Por qué? — Pues porque una base de datos sería una interfaz pública enorme. Solo piensa en cuántas operaciones distintas se pueden ejecutar contra una base de datos relacional.
Entonces, para reiterar, en los sistemas distribuidos equilibramos la complejidad local y global minimizando las interfaces públicas de los servicios y, así, convirtiéndolos en micro servicios.
ADVERTENCIA
Esta heurística puede sonar engañosamente simple. Si un microservicio es solo un servicio con una micro interfaz pública, entonces basta con limitar las interfaces públicas a un solo método. Y como la puerta principal no puede ser más pequeña que eso, esos serían los microservicios perfectos, ¿no? Pues no. Para mostrar por qué no, voy a usar el ejemplo de mi otro post [11] sobre este tema:
Supongamos que tenemos el siguiente servicio de gestión de backlog:
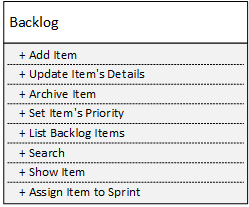
Una vez que lo descomponemos en ocho servicios, cada uno con un único método público, obtenemos servicios con complejidades locales perfectas:
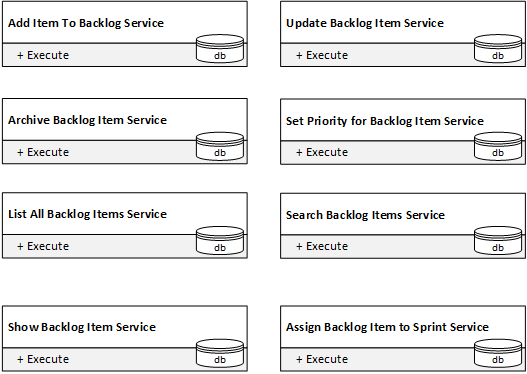
Pero ¿podemos conectarlos en un sistema que realmente gestione el backlog? La verdad, no. Para formar el sistema, los servicios tienen que interactuar entre sí y compartir cambios en el estado de cada uno. Pero no pueden. Las interfaces públicas de los servicios no lo permiten.
Por eso, hay que ampliar las puertas principales con métodos públicos que permitan la integración entre los servicios:
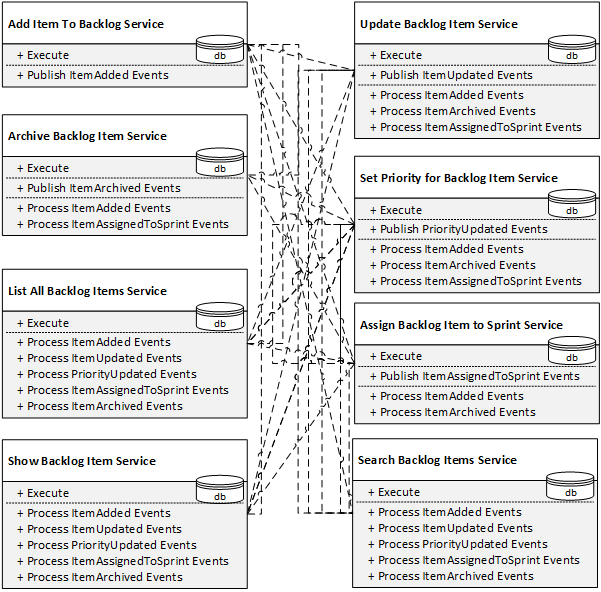
Pum. Si optimizamos la complejidad de cada servicio por separado, la descomposición ingenua funciona de maravilla. Sin embargo, cuando intentamos conectar los servicios en un sistema, entra en juego la complejidad global. No solo el sistema resultante se vuelve un enredo, sino que además hay que extender las interfaces públicas más allá de la intención original, todo por la integración. Parafraseando a Randy Shoup, además de la diminuta puerta principal, ¡creamos una enorme entrada "solo para personal"! Lo cual nos lleva a un punto importante:
¡Que un servicio tenga más métodos relacionados con la integración que con el negocio es una fuerte señal de que se está formando una gran bola de lodo distribuida!
Así, el umbral hasta el cual la interfaz pública de un servicio puede minimizarse depende no solo del servicio en sí, sino (sobre todo) del sistema del que ese servicio forma parte. Una descomposición adecuada en microservicios debe equilibrar la complejidad global del sistema con las complejidades locales de sus servicios.
Diseñando los límites de los servicios
"Encontrar los límites de los servicios es jodidamente difícil… ¡No hay un diagrama de flujo!" — Udi Dahan
La afirmación de Udi Dahan es especialmente cierta en los sistemas basados en microservicios. Diseñar los límites de los microservicios es difícil y, probablemente, imposible de acertar a la primera. Por eso, diseñar un sistema basado en microservicios medianamente complejo es un proceso iterativo.
Por eso conviene empezar con límites más amplios —probablemente los de los bounded contexts adecuados[12]— e ir descomponiéndolos en microservicios más adelante, conforme se gana más conocimiento sobre el sistema y su dominio de negocio. Esto es especialmente relevante para los servicios que abarcan los dominios de negocio centrales[13].
Microservicios fuera de los sistemas distribuidos
Aunque los microservicios fueron "inventados" hace relativamente poco, hay muchas implementaciones de los mismos principios de diseño en otras industrias. Algunas son:
Equipos multidisciplinarios
Todos sabemos que los equipos multidisciplinarios son los más efectivos. Un equipo así es un grupo diverso de profesionales trabajando en la misma tarea. Un equipo multidisciplinario eficiente maximiza la comunicación dentro del equipo y la minimiza hacia afuera.
Nuestra industria descubrió los equipos multidisciplinarios hace poco, pero los grupos de trabajo (task forces) existen desde siempre. Sus principios subyacentes son los mismos que los de un sistema basado en microservicios: alta cohesión dentro del equipo y bajo acoplamiento entre equipos. La "interfaz pública" del equipo se minimiza al incorporar dentro de él las habilidades necesarias para cumplir la tarea (es decir, los detalles de implementación).
Microprocesadores
Me topé con este ejemplo en el maravilloso blog de Vaughn Vernon sobre el mismo tema. En su post, Vaughn establece un paralelo interesante entre micro servicios y micro procesadores. En particular, analiza la diferencia entre procesadores y microprocesadores:
Me parece interesante que exista una clasificación de tamaño que ayuda a determinar si una unidad central de procesamiento (CPU) se considera o no un microprocesador: el tamaño de su bus de datos [21]
El bus de datos de un microprocesador es su interfaz pública: define la cantidad de datos que pueden pasar entre el microprocesador y otros componentes. Existe una clasificación estricta de tamaño para la interfaz pública que define si una unidad central de procesamiento (CPU) se considera o no un microprocesador.
La filosofía Unix
La filosofía Unix, o el "Unix way", es un conjunto de normas culturales y enfoques filosóficos para el desarrollo de software minimalista y modular [22].
Alguien podría argumentar que la filosofía Unix contradice mi tesis de que no se puede construir un sistema a partir de componentes totalmente independientes: ¿No son los programas Unix totalmente independientes y, aun así, forman un sistema funcional? Es justo lo contrario. El Unix way casi literalmente exige que los programas expongan micro-interfaces. Veamos cómo se relacionan los principios de la filosofía Unix con la noción de microservicios:
El primer principio pide que las interfaces públicas de los programas expongan una única función coherente, en lugar de saturarlos con funcionalidad ajena a su objetivo original:
Haz que cada programa haga una sola cosa bien. Para hacer un nuevo trabajo, construye desde cero en lugar de complicar viejos programas agregándoles nuevas "funciones".
Aunque los comandos de Unix se consideran totalmente independientes entre sí, no lo son. Aún tienen que comunicarse con otros, y el segundo principio define cómo deben diseñarse las interfaces de comunicación:
Espera que la salida de cada programa se convierta en la entrada de otro, aún desconocido. No satures la salida con información extraña. Evita formatos de entrada estrictamente columnares o binarios. No insistas en la entrada interactiva.
No solo la interfaz de comunicación está estrictamente limitada (entrada estándar, salida estándar y error estándar), sino que, según este principio, los datos que se pasan entre los comandos también deben estarlo. Es decir, los comandos de Unix tienen que exponer micro-interfaces y nunca depender de los detalles de implementación de los demás.
¿Y los nano servicios?
El término "nanoservicio" suele usarse para describir un servicio que es demasiado pequeño. Se podría decir que esos ingenuos servicios de un solo método del ejemplo anterior son nanoservicios. Sin embargo, no comparto del todo esa clasificación.
Los nanoservicios se usan para describir servicios individuales ignorando el sistema que los engloba. En el ejemplo anterior, una vez que metimos al sistema en la ecuación, las interfaces de los servicios tuvieron que crecer. De hecho, si comparamos la implementación original de un solo servicio con la descomposición ingenua, vemos que cuando conectamos los servicios en un sistema, este pasa de tener 8 métodos públicos en total a 38. Además, el promedio de métodos públicos por servicio salta del deseado 1 hasta 4.75.
Por lo tanto, si en vez de las bases de código optimizamos los servicios (las interfaces públicas), el término nano-servicio ya no se sostiene, ya que el servicio se ve obligado a crecer de nuevo para soportar los casos de uso de su sistema.
¿Y eso es todo?
No. Aunque minimizar las interfaces públicas de los servicios es un buen principio guía para diseñar microservicios, sigue siendo solo una heurística y no reemplaza al sentido común. De hecho, la micro-interfaz es solo una abstracción sobre los principios de diseño más fundamentales, pero mucho más complejos, de acoplamiento y cohesión.
Por ejemplo, si dos servicios tienen micro-interfaces públicas pero deben coordinarse en una transacción distribuida, siguen estando altamente acoplados entre sí.
Dicho esto, apuntar a las micro-interfaces sigue siendo una heurística sólida que aborda distintos tipos de acoplamiento, como el funcional, el de desarrollo y el semántico. Pero ese es tema para otro blog.
De la teoría a la práctica
Por desgracia, todavía no tenemos una forma objetiva de cuantificar la complejidad local y la global. Por otro lado, sí contamos con algunas heurísticas de diseño que pueden mejorar el diseño de los sistemas distribuidos.
El mensaje principal de este post es que debes evaluar continuamente las interfaces públicas de tus servicios preguntándote:
- ¿Cuál es la proporción entre endpoints orientados al negocio y endpoints orientados a la integración en un servicio dado?
- ¿Hay endpoints en un servicio que, en términos de negocio, no estén relacionados entre sí? ¿Puedes dividirlos en dos o más servicios sin introducir endpoints orientados a la integración?
- ¿Fusionar dos servicios eliminaría endpoints que se agregaron solo para integrar los servicios originales?
Usa estas heurísticas como guía para diseñar los límites e interfaces de tus servicios.
Resumen
Quiero cerrar con una cita de Eliyahu Goldratt. En sus libros, repetía mucho estas palabras:
"Dime cómo me mides y te diré cómo me comportaré" ~ Eliyahu Goldratt
Al diseñar sistemas basados en microservicios, es crucial medir y optimizar la métrica correcta. Diseñar los límites para micro bases de código y micro equipos es definitivamente más sencillo. Sin embargo, para construir un sistema, hay que tomarlo en cuenta. Los microservicios se tratan de diseñar sistemas, no servicios individuales.
Y eso nos regresa al título del post: "Desenredando microservicios, o cómo equilibrar la complejidad en sistemas distribuidos". La única manera de desenredar los microservicios es equilibrar la complejidad local de cada servicio con la complejidad global de todo el sistema.
Bibliografía
- Tweet de Gergely Orosz sobre Uber
- Monoliths are the future
- Microservices guru warns devs that trendy architecture shouldn’t be the default for every app, but ‘a last resort’
- Monolithic Application (Wikipedia)
- The Majestic Monolith — DHH
- Big Ball of Mud (Wikipedia)
- Definition of a System
- Composite/Structures Design — libro de Glenford J. Myers
- Reference Model for Service Oriented Architecture
- Managing Data in Microservices — charla de Randy Shoup
- Tackling Complexity in Microservices
- Bounded Contexts are NOT Microservices
- Revisiting the Basics of Domain-Driven Design
- Implementing Domain-Driven Design — libro de Vaughn Vernon
- Modular Monolith: A Primer — Kamil Grzybek
- A Design Methodology for Reliable Software Systems — Barbara Liskov
- Designing Autonomous Teams and Services
- Emergent Boundaries — charla de Mathias Verraes
- Long Sad Story of Microservices — charla de Greg Young
- Principles of Design — Tim Berners-Lee
- Microservices and [Micro]services — Vaughn Vernon
- Unix Philosophy
Publicado originalmente en vladikk.com el 9 de abril de 2020.