
Die Flitterwochen mit Microservices sind vorbei. Uber baut tausende Microservices in eine besser handhabbare Lösung um [1]; Kelsey Hightower prophezeit, dass Monolithen die Zukunft sind [2]; und selbst Sam Newman erklärt, dass Microservices nie die Standardwahl sein sollten, sondern bestenfalls die letzte Option [3].
Was läuft hier schief? Warum sind so viele Projekte unwartbar geworden, obwohl Microservices doch Einfachheit und Flexibilität versprachen? Oder sind Monolithen am Ende doch die bessere Wahl?
In diesem Beitrag will ich diesen Fragen nachgehen. Sie erfahren, welche typischen Designfehler Microservices in verteilte Big Balls of Mud verwandeln – und natürlich, wie Sie das vermeiden.
Zuerst sollten wir aber klären, was ein Monolith überhaupt ist.
Monolith
Microservices wurden von Anfang an als Lösung für monolithische Codebases positioniert. Aber sind Monolithen zwangsläufig ein Problem? Laut der Wikipedia-Definition [4] ist eine monolithische Anwendung in sich geschlossen und unabhängig von anderen Anwendungen. Unabhängigkeit von anderen Anwendungen? Ist das nicht genau das, was wir – oft vergeblich – beim Entwurf von Microservices anstreben? David Heinemeier Hansson [5] hat die Schmähung von Monolithen früh angeprangert. Er warnte vor den Risiken und Herausforderungen verteilter Systeme und führte Basecamp als Beleg an, dass sich ein großes System mit Millionen Kunden in einer monolithischen Codebase umsetzen und pflegen lässt.
Microservices "reparieren" Monolithen also nicht. Das eigentliche Problem, das Microservices lösen sollen, ist die Unfähigkeit, Geschäftsziele zu erreichen. Häufig scheitern Teams daran, weil die Kosten für Änderungen exponentiell wachsen – oder, schlimmer noch, völlig unvorhersehbar werden. Mit anderen Worten: Das System hält mit den Anforderungen des Geschäfts nicht mehr Schritt. Diese unkontrollierbaren Änderungskosten sind keine Eigenschaft eines Monolithen, sondern eines Big Ball of Mud [6]:
Ein Big Ball of Mud ist ein willkürlich strukturierter, ausufernder, schlampiger, mit Klebeband und Draht zusammengeflickter Spaghetti-Code-Dschungel. Solche Systeme zeigen unverkennbare Anzeichen ungebremsten Wachstums und wiederholter Notreparaturen. Informationen werden wahllos zwischen weit entfernten Teilen des Systems geteilt – oft so weit, dass nahezu alle wichtigen Informationen global oder dupliziert vorliegen.
Die Komplexität, einen Big Ball of Mud zu verändern und weiterzuentwickeln, kann viele Ursachen haben: die Koordination mehrerer Teams, widersprüchliche nicht-funktionale Anforderungen oder eine verzwickte Geschäftsdomäne. Wie auch immer – wir versuchen oft, dieser Komplexität durch Zerlegung in Microservices Herr zu werden.
Mikro – was?
Der Begriff "Microservice" impliziert, dass sich bestimmte Eigenschaften eines Service messen lassen und ihr Wert minimiert werden sollte. Aber was bedeutet Microservice eigentlich genau? Schauen wir uns einige gängige Lesarten des Begriffs an.
Mikro-Teams
Die erste Variante ist die Größe des Teams, das an einem Service arbeitet. Und diese Metrik soll in Pizzen gemessen werden. Im Ernst. Es heißt: Wenn ein Team, das an einem Service arbeitet, mit zwei Pizzen satt wird, handelt es sich um einen Microservice. Diese Heuristik halte ich für anekdotisch, denn ich habe Projekte mit Teams gebaut, die mit einer einzigen Pizza auskamen … und ich möchte sehen, wer diese Schlammbälle als Microservices bezeichnet!
Mikro-Codebases
Ein weiterer verbreiteter Ansatz besteht darin, einen Microservice anhand der Größe seiner Codebase zu definieren. Manche treiben das auf die Spitze und versuchen, die Service-Größe auf eine bestimmte Anzahl Codezeilen zu begrenzen. Allerdings ist die genaue Zeilenzahl, die einen Microservice ausmacht, noch nicht gefunden. Sobald dieser heilige Gral der Software-Architektur entdeckt ist, kommt die nächste Frage: Welche Editorbreite empfiehlt sich beim Bau von Microservices?
Etwas ernsthafter betrachtet: Eine moderatere Variante dieses Ansatzes ist weit verbreitet. Die Größe einer Codebase dient häufig als Heuristik für die Frage, ob es sich um einen Microservice handelt oder nicht.
In gewisser Weise hat das seine Logik. Je kleiner die Codebase, desto geringer der Umfang der Geschäftsdomäne. Sie ist also einfacher zu verstehen, zu implementieren und weiterzuentwickeln. Außerdem läuft eine kleinere Codebase weniger Gefahr, zum Big Ball of Mud zu werden – und falls doch, lässt sie sich leichter refaktorieren.
Leider ist diese Einfachheit nur eine Illusion. Wenn wir das Design eines Service ausschließlich am Service selbst bewerten, übersehen wir einen entscheidenden Aspekt des System-Designs. Wir vergessen das System – das System, dessen Komponente der Service ist.
"Es gibt viele nützliche und aufschlussreiche Heuristiken, um die Grenzen eines Service zu definieren. Die Größe gehört zu den am wenigsten nützlichen." ~ Nick Tune
Wir bauen Systeme!
Wir bauen Systeme, keine losen Sammlungen von Services. Wir nutzen Microservices-Architekturen, um das Design eines Systems zu optimieren – nicht das Design einzelner Services. Was auch immer andere behaupten: Microservices können und werden nie vollständig entkoppelt oder völlig unabhängig sein. Aus separaten Komponenten lässt sich kein System bauen! Das widerspräche schon der Definition des Begriffs "System" [7]:
1. Eine Menge verbundener Dinge oder Geräte, die zusammen funktionieren
2. Eine Menge an Computer-Equipment und Programmen, die für einen bestimmten Zweck zusammen verwendet werden
Services müssen immer miteinander interagieren, um ein System zu bilden. Wer ein System entwirft, indem er nur die einzelnen Services optimiert, die Interaktionen dazwischen aber ignoriert, landet schnell hier:

Diese "Microservices" mögen einzeln einfach sein – das System als Ganzes ist die Hölle der Komplexität!
Wie also entwerfen wir Microservices, die nicht nur die Komplexität der Services, sondern die des gesamten Systems im Griff haben?
Eine knifflige Frage – aber zum Glück wurde sie schon vor langer Zeit beantwortet.
Eine systemweite Perspektive auf Komplexität
Vor vierzig Jahren gab es kein Cloud Computing, keine Anforderungen an globale Skalierung und keinen Bedarf, ein System alle 11,7 Sekunden zu deployen. Doch Engineers mussten schon damals die Komplexität von Systemen bändigen. Auch wenn die Werkzeuge andere waren, sind die Herausforderungen – und vor allem die Lösung – heute genauso relevant und auf das Design Microservices-basierter Systeme übertragbar.
In seinem Buch "Composite/Structured Design" [8] beschreibt Glenford J. Myers, wie sich prozeduraler Code strukturieren lässt, um seine Komplexität zu reduzieren. Bereits auf der allerersten Seite schreibt er:
Beim Thema Komplexität geht es um weit mehr, als nur die lokale Komplexität jedes Programmteils zu minimieren. Eine viel wichtigere Form ist die globale Komplexität: die Komplexität der Gesamtstruktur eines Programms oder Systems (also der Grad der Verbindungen oder Abhängigkeiten zwischen den Hauptbestandteilen eines Programms).
In unserem Kontext ist lokale Komplexität die Komplexität jedes einzelnen Microservice, während globale Komplexität die Komplexität des Gesamtsystems beschreibt. Lokale Komplexität hängt von der Implementierung eines Service ab; globale Komplexität ergibt sich aus den Interaktionen und Abhängigkeiten zwischen den Services.
Welche Komplexität ist nun wichtiger – die lokale oder die globale? Schauen wir uns an, was passiert, wenn nur eine von beiden berücksichtigt wird.
Die globale Komplexität auf ein Minimum zu reduzieren, ist überraschend einfach. Wir müssen lediglich jegliche Interaktion zwischen den Komponenten unterbinden – also die gesamte Funktionalität in einem monolithischen Service implementieren. Wie wir bereits gesehen haben, kann diese Strategie in bestimmten Szenarien funktionieren. In anderen führt sie zum gefürchteten Big Ball of Mud – wahrscheinlich der höchstmöglichen lokalen Komplexität.
Auf der anderen Seite wissen wir, was passiert, wenn man nur die lokale Komplexität optimiert, die globale aber vernachlässigt: den noch gefürchteteren verteilten Big Ball of Mud.
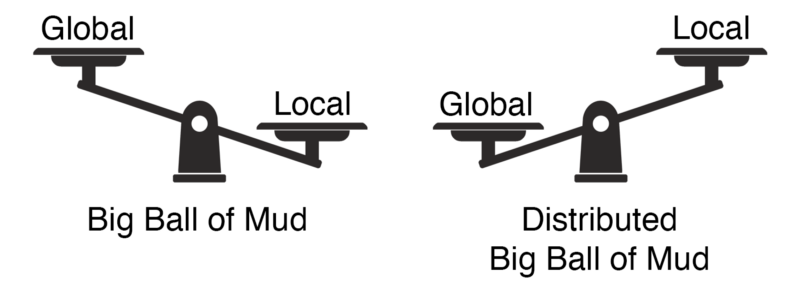
Konzentrieren wir uns also nur auf eine Art von Komplexität, ist es egal, welche. In einem hinreichend komplexen verteilten System schießt die jeweils andere durch die Decke. Wir können also nicht nur eine optimieren, sondern müssen lokale und globale Komplexität in Balance bringen.
Bemerkenswert: Die Mittel, die in "Composite/Structured Design" zum Austarieren der Komplexität beschrieben werden, sind nicht nur für verteilte Systeme relevant. Sie liefern auch wertvolle Hinweise für den Entwurf von Microservices.
Microservices
Beginnen wir damit, zu definieren, was diese Services und Microservices, von denen wir sprechen, eigentlich sind.
Was ist ein Service?
Laut OASIS-Standard [9] ist ein Service:
Ein Mechanismus, der den Zugriff auf eine oder mehrere Fähigkeiten ermöglicht, wobei der Zugriff über eine vorgeschriebene Schnittstelle erfolgt.
Der Aspekt der vorgeschriebenen Schnittstelle ist entscheidend. Die Schnittstelle eines Service definiert die Funktionalität, die er nach außen freigibt. Laut Randy Shoup [10] ist die öffentliche Schnittstelle eines Service schlicht jeder Mechanismus, über den Daten in den Service hinein- oder aus ihm herausgelangen. Sie kann synchron sein – etwa ein einfaches Request/Response-Modell – oder asynchron, also Events erzeugen und konsumieren. Synchron oder asynchron: Die öffentliche Schnittstelle ist einfach das Mittel, mit dem Daten in den Service hinein- oder aus ihm herausgelangen. Randy beschreibt die öffentlichen Schnittstellen eines Service auch als seine Vordertür.
Ein Service wird durch seine öffentliche Schnittstelle definiert – und diese Definition reicht aus, um zu bestimmen, was einen Service zu einem Microservice macht.
Was ist ein Microservice?
Wenn ein Service durch seine öffentliche Schnittstelle definiert ist, dann gilt:
Ein Microservice ist ein Service mit einer Mikro-Schnittstelle – einer Mikro-Vordertür.
Diese einfache Heuristik wurde schon zu Zeiten der prozeduralen Programmierung befolgt und ist im Bereich verteilter Systeme aktueller denn je. Je kleiner der Service, den Sie nach außen anbieten, desto einfacher seine Implementierung und desto geringer seine lokale Komplexität. Aus Sicht der globalen Komplexität erzeugen kleinere öffentliche Schnittstellen weniger Abhängigkeiten und Verbindungen zwischen Services.
Das Konzept der Mikro-Schnittstellen erklärt auch die weit verbreitete Praxis, dass Microservices ihre Datenbanken nicht freigeben. Kein Microservice darf direkt auf die Datenbank eines anderen zugreifen, sondern nur über dessen öffentliche Schnittstelle. Warum? – Nun, eine Datenbank wäre eine riesige öffentliche Schnittstelle! Bedenken Sie nur, wie viele unterschiedliche Operationen sich auf einer relationalen Datenbank ausführen lassen.
Um es noch einmal auf den Punkt zu bringen: In verteilten Systemen tarieren wir lokale und globale Komplexität aus, indem wir die öffentlichen Schnittstellen der Services minimieren – und sie damit zu Mikro-Services machen.
WARNUNG
Diese Heuristik klingt verführerisch einfach. Wenn ein Microservice nichts weiter ist als ein Service mit einer Mikro-Schnittstelle, dann lassen sich die öffentlichen Schnittstellen ja einfach auf eine einzige Methode beschränken. Kleiner kann eine Vordertür kaum sein – das müssten dann doch die perfekten Microservices sein, oder? Nicht ganz. Warum nicht, zeige ich anhand des Beispiels aus meinem anderen Beitrag [11] zum Thema:
Angenommen, wir haben den folgenden Backlog-Management-Service:
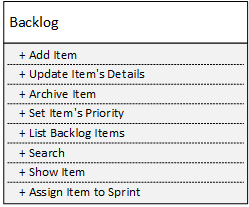
Sobald wir ihn in acht Services zerlegen, von denen jeder genau eine öffentliche Methode hat, erhalten wir Services mit perfekter lokaler Komplexität:
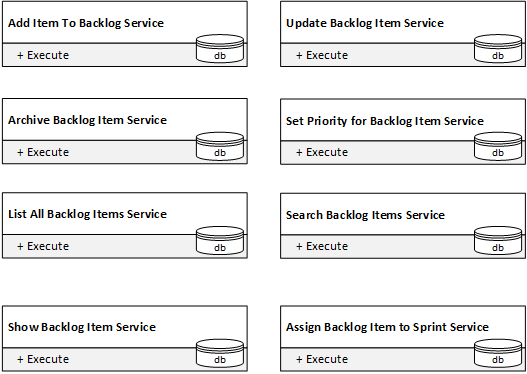
Aber lassen sie sich zu einem System verbinden, das tatsächlich das Backlog verwaltet? Nicht wirklich. Damit ein System entsteht, müssen die Services miteinander interagieren und Zustandsänderungen austauschen. Das können sie aber nicht. Die öffentlichen Schnittstellen geben das nicht her.
Wir müssen die Vordertüren also um öffentliche Methoden erweitern, die die Integration zwischen den Services ermöglichen:
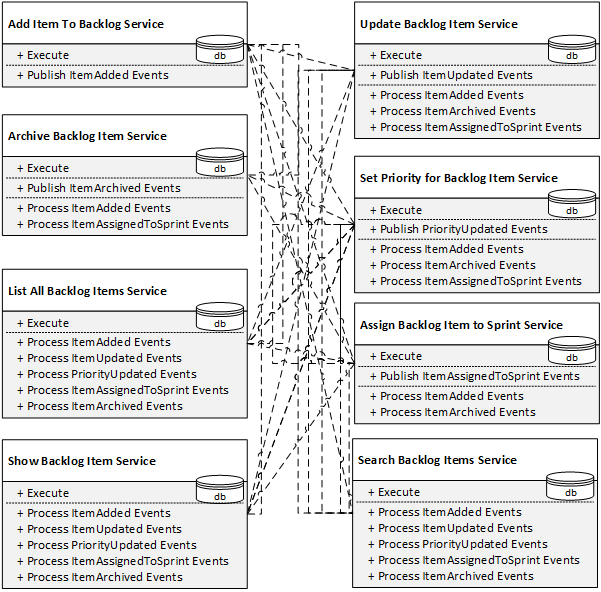
Bumm. Wenn wir die Komplexität jedes Service einzeln optimieren, funktioniert die naive Zerlegung wunderbar. Sobald wir die Services aber zu einem System verbinden, schlägt die globale Komplexität zu. Das Ergebnis ist nicht nur ein heilloses Durcheinander; wir müssen zudem die öffentlichen Schnittstellen über die ursprüngliche Absicht hinaus aufbohren – nur der Integration zuliebe. Frei nach Randy Shoup haben wir zur winzigen Vordertür einen riesigen Personaleingang dazugebaut! Das bringt uns zu einem wichtigen Punkt:
Hat ein Service mehr integrationsbezogene als geschäftsbezogene Methoden, ist das ein starkes Indiz für einen wachsenden verteilten Big Ball of Mud!
Die Schwelle, bis zu der sich die öffentliche Schnittstelle eines Service minimieren lässt, hängt also nicht nur vom Service selbst ab, sondern (vor allem) vom System, dessen Teil er ist. Eine sinnvolle Zerlegung in Microservices sollte die globale Komplexität des Systems und die lokalen Komplexitäten seiner Services austarieren.
Service-Grenzen entwerfen
"Service-Grenzen zu finden ist verdammt schwer … Es gibt kein Flussdiagramm dafür!" — Udi Dahan
Diese Aussage von Udi Dahan trifft auf Microservices-basierte Systeme besonders zu. Microservice-Grenzen zu entwerfen ist schwierig – und beim ersten Anlauf kaum richtig zu treffen. Damit wird der Entwurf eines hinreichend komplexen Microservices-Systems zu einem iterativen Prozess.
Es ist daher sicherer, mit weiter gefassten Grenzen zu beginnen – wahrscheinlich den Grenzen passender Bounded Contexts [12] – und sie später, wenn mehr Wissen über das System und seine Geschäftsdomäne vorliegt, in Microservices zu zerlegen. Das gilt besonders für Services, die Kerngeschäftsdomänen abdecken [13].
Microservices außerhalb verteilter Systeme
Auch wenn Microservices erst kürzlich "erfunden" wurden, finden sich zahlreiche Umsetzungen derselben Designprinzipien in anderen Branchen. Dazu gehören:
Cross-funktionale Teams
Wir alle wissen: Cross-funktionale Teams sind die effektivsten. Ein solches Team ist eine vielseitige Gruppe von Fachleuten, die alle gemeinsam an derselben Aufgabe arbeiten. Ein effizientes cross-funktionales Team maximiert die Kommunikation innerhalb des Teams und minimiert die nach außen.
Unsere Branche hat cross-funktionale Teams erst kürzlich entdeckt – Task Forces gibt es dagegen schon ewig. Die zugrunde liegenden Prinzipien sind dieselben wie in einem Microservices-System: hohe Kohäsion innerhalb des Teams, geringe Kopplung zwischen den Teams. Die "öffentliche Schnittstelle" des Teams wird minimiert, indem die für die Aufgabe nötigen Fähigkeiten ins Team integriert werden (also als Implementierungsdetails).
Mikroprozessoren
Auf dieses Beispiel bin ich in Vaughn Vernons wunderbarem Blog zum gleichen Thema gestoßen. In seinem Beitrag zieht Vaughn eine spannende Parallele zwischen Mikro-Services und Mikro-Prozessoren. Insbesondere diskutiert er den Unterschied zwischen Prozessoren und Mikroprozessoren:
Ich finde es interessant, dass es eine Größenklassifizierung gibt, die hilft zu bestimmen, ob eine Central Processing Unit (CPU) als Mikroprozessor gilt: die Größe ihres Datenbusses [21]
Der Datenbus eines Mikroprozessors ist seine öffentliche Schnittstelle – er bestimmt, wie viele Daten zwischen Mikroprozessor und anderen Komponenten übertragen werden können. Es gibt also eine strikte Größenklassifizierung für die öffentliche Schnittstelle, die festlegt, ob eine Central Processing Unit (CPU) als Mikroprozessor gilt oder nicht.
Unix-Philosophie
Die Unix-Philosophie, oder der Unix-Weg, ist eine Sammlung kultureller Normen und philosophischer Ansätze für minimalistische, modulare Softwareentwicklung [22].
Man könnte einwenden, die Unix-Philosophie widerspreche meiner These, dass sich kein System aus völlig unabhängigen Komponenten bauen lässt: Sind Unix-Programme nicht völlig unabhängig und bilden trotzdem ein funktionierendes System? Das Gegenteil ist der Fall. Der Unix-Weg schreibt nahezu wörtlich vor, dass Programme Mikro-Schnittstellen bereitstellen müssen. Schauen wir uns an, wie sich die Prinzipien der Unix-Philosophie zum Konzept der Microservices verhalten:
Das erste Prinzip fordert, dass die öffentlichen Schnittstellen von Programmen genau eine zusammenhängende Funktion bieten, statt Programme mit Funktionalität zu überfrachten, die mit ihrem ursprünglichen Ziel nichts zu tun hat:
Lass jedes Programm eine Sache gut machen. Für eine neue Aufgabe baue lieber neu, statt alte Programme durch neue "Features" zu verkomplizieren.
Auch wenn Unix-Befehle als völlig unabhängig voneinander gelten, sind sie es nicht. Sie müssen miteinander kommunizieren, und das zweite Prinzip definiert, wie Kommunikationsschnittstellen gestaltet sein sollten:
Erwarte, dass die Ausgabe jedes Programms zur Eingabe eines weiteren, noch unbekannten Programms wird. Überfrachte die Ausgabe nicht mit überflüssigen Informationen. Vermeide streng spaltenbasierte oder binäre Eingabeformate. Bestehe nicht auf interaktiver Eingabe.
Nicht nur die Kommunikationsschnittstelle ist streng begrenzt (Standard-Input, Standard-Output und Standard-Error) – auch die zwischen den Befehlen ausgetauschten Daten sollen laut diesem Prinzip strikt begrenzt sein. Das heißt: Unix-Befehle müssen Mikro-Schnittstellen bereitstellen und dürfen nie von den Implementierungsdetails der anderen abhängen.
Was ist mit _Nano_services?
Der Begriff "Nanoservice" wird häufig für einen Service verwendet, der zu klein geraten ist. Man könnte sagen, die naiven Ein-Methoden-Services im vorherigen Beispiel seien Nanoservices. Dieser Klassifizierung stimme ich aber nicht unbedingt zu.
Nanoservices werden zur Beschreibung einzelner Services herangezogen, ohne das übergeordnete System mitzudenken. Im obigen Beispiel mussten die Schnittstellen wachsen, sobald wir das System mit einbezogen haben. Vergleichen wir die ursprüngliche Single-Service-Implementierung mit der naiven Zerlegung, sehen wir tatsächlich: Sobald wir die Services zu einem System verbinden, steigt die Anzahl öffentlicher Methoden insgesamt von 8 auf 38. Außerdem schnellt die durchschnittliche Anzahl öffentlicher Methoden pro Service von den gewünschten 1 auf 4,75 hoch.
Wenn wir also statt Codebases Services (öffentliche Schnittstellen) optimieren, hält der Begriff Nano-Service nicht mehr stand, da der Service wieder wachsen muss, um die Use Cases seines Systems zu unterstützen.
Ist das schon alles?
Nein. Auch wenn das Minimieren öffentlicher Schnittstellen ein guter Leitgedanke für den Entwurf von Microservices ist, bleibt es nur eine Heuristik und ersetzt keinen gesunden Menschenverstand. Die Mikro-Schnittstelle ist letztlich nur eine Abstraktion über den fundamentaleren, aber deutlich komplexeren Designprinzipien Kopplung und Kohäsion.
Haben beispielsweise zwei Services Mikro-Schnittstellen, müssen aber in einer verteilten Transaktion koordiniert werden, sind sie dennoch eng aneinander gekoppelt.
Trotzdem bleibt das Streben nach Mikro-Schnittstellen eine starke Heuristik, die unterschiedliche Arten von Kopplung adressiert – funktionale, entwicklungsbezogene und semantische. Aber das ist ein Thema für einen anderen Blogbeitrag.
Von der Theorie zur Praxis
Leider haben wir bislang keine objektive Möglichkeit, lokale und globale Komplexität zu quantifizieren. Es gibt aber einige Design-Heuristiken, die das Design verteilter Systeme verbessern können.
Die zentrale Botschaft dieses Beitrags lautet: Sie sollten die öffentlichen Schnittstellen Ihrer Services kontinuierlich auf den Prüfstand stellen und sich folgende Fragen stellen:
- Wie ist das Verhältnis von geschäfts- zu integrationsorientierten Endpunkten in einem Service?
- Gibt es in einem Service Endpunkte, die fachlich nicht zusammengehören? Lassen sie sich auf zwei oder mehr Services aufteilen, ohne neue integrationsorientierte Endpunkte einzuführen?
- Würde das Zusammenführen zweier Services Endpunkte überflüssig machen, die nur zur Integration der ursprünglichen Services hinzugefügt wurden?
Nutzen Sie diese Heuristiken, um den Entwurf der Grenzen und Schnittstellen Ihrer Services zu lenken.
Zusammenfassung
Ich möchte das Ganze mit einem Zitat von Eliyahu Goldratt zusammenfassen. In seinen Büchern wiederholte er häufig diese Worte:
"Sag mir, wie du mich misst, und ich sage dir, wie ich mich verhalten werde." ~ Eliyahu Goldratt
Beim Design Microservices-basierter Systeme ist es entscheidend, die richtige Metrik zu messen und zu optimieren. Grenzen für Mikro-Codebases und Mikro-Teams zu entwerfen, ist deutlich einfacher. Doch wer ein System bauen will, muss dieses System mitdenken. Bei Microservices geht es um den Entwurf von Systemen, nicht um einzelne Services.
Und damit zurück zum Titel dieses Beitrags – "Microservices entwirren: Komplexität in verteilten Systemen austarieren". Microservices lassen sich nur dann entwirren, wenn man die lokale Komplexität jedes Service und die globale Komplexität des Gesamtsystems in Balance bringt.
Literaturverzeichnis
- Tweet von Gergely Orosz zu Uber
- Monoliths are the future
- Microservices guru warns devs that trendy architecture shouldn’t be the default for every app, but ‘a last resort’
- Monolithic Application (Wikipedia)
- The Majestic Monolith — DHH
- Big Ball of Mud (Wikipedia)
- Definition of a System
- Composite/Structures Design — Buch von Glenford J. Myers
- Reference Model for Service Oriented Architecture
- Managing Data in Microservices — Vortrag von Randy Shoup
- Tackling Complexity in Microservices
- Bounded Contexts are NOT Microservices
- Revisiting the Basics of Domain-Driven Design
- Implementing Domain-Driven Design — Buch von Vaughn Vernon
- Modular Monolith: A Primer — Kamil Grzybek
- A Design Methodology for Reliable Software Systems — Barbara Liskov
- Designing Autonomous Teams and Services
- Emergent Boundaries — Vortrag von Mathias Verraes
- Long Sad Story of Microservices — Vortrag von Greg Young
- Principles of Design — Tim Berners-Lee
- Microservices and [Micro]services — Vaughn Vernon
- Unix Philosophy
Ursprünglich veröffentlicht auf vladikk.com am 9. April 2020.