· Pourquoi comprendre les limitations réseau d'AWS
· Quelles sont ces limitations ?
· Comment le trafic est-il modelé ?
· Placements EC2 et partage des ressources
· Diagnostiquer le throttling de bande passante
∘ Bande passante sortante vers Internet
∘ Lecture des métriques réseau CloudWatch
· Diagnostiquer le throttling du suivi de connexions
· Diagnostiquer le throttling vers les services proxy locaux
· Diagnostiquer le throttling de paquets
Pourquoi comprendre les limitations réseau d'AWS
Dans le vaste écosystème des services AWS, les instances EC2 et le réseau EC2 forment les briques fondamentales sur lesquelles repose la majorité des autres services AWS, et soutiennent une multitude d'applications critiques pour l'infrastructure numérique moderne. Optimiser les performances de ces instances exige toutefois de plonger dans les rouages du réseau AWS, et notamment du throttling réseau. Celui-ci, qui peut prendre plusieurs formes, influe directement sur les performances et la scalabilité des instances EC2 et, par ricochet, sur de nombreux autres services de l'écosystème AWS.
AWS applique le throttling réseau via deux mécanismes principaux : les limitations de bande passante et les restrictions sur le nombre de paquets par seconde (PPS). Le throttling de bande passante limite le volume de données pouvant transiter sur le réseau pendant une période donnée, tandis que le throttling PPS plafonne le nombre de paquets envoyés ou reçus. Ces contraintes sont conçues avec soin pour préserver la santé et l'efficacité globales de l'infrastructure AWS. Elles peuvent toutefois représenter un véritable défi lorsqu'il s'agit d'optimiser les performances applicatives et l'utilisation des ressources.
À cela s'ajoute un déficit de documentation officielle sur certains aspects du throttling réseau AWS. Les informations relatives aux modalités précises d'application de ces mécanismes sont difficiles à trouver, contraignant les développeurs à écumer forums, retours d'expérience et tests par tâtonnement pour en comprendre et en atténuer les effets. Cette absence de documentation claire et accessible ajoute une couche de complexité à la gestion et à l'optimisation des performances réseau dans l'écosystème AWS.
Dans cet article, nous allons rassembler les pièces éparses de ce puzzle pour dresser un panorama clair et complet de la manière dont AWS met en œuvre les mécanismes de throttling sur le réseau EC2.
Quelles sont ces limitations ?
Sur les générations modernes d'instances EC2 reposant sur Nitro, AWS expose plusieurs métriques sous forme de compteurs de paquets affectés par le throttling réseau, listées dans sa documentation officielle [1].
- bw_in_allowance_exceeded : nombre de paquets mis en file d'attente ou rejetés parce que la bande passante entrante agrégée a dépassé le maximum autorisé pour ce type/taille d'instance ;
- bw_out_allowance_exceeded : nombre de paquets mis en file d'attente ou rejetés parce que la bande passante sortante agrégée a dépassé le maximum autorisé pour ce type/taille d'instance ;
- conntrack_allowance_exceeded : nombre de paquets rejetés parce que le suivi de connexions a dépassé le maximum autorisé pour l'instance et qu'aucune nouvelle connexion n'a pu être établie. Cela peut entraîner des pertes de paquets sur le trafic entrant ou sortant de l'instance.
- conntrack_allowance_available : nombre de connexions suivies que l'instance peut encore établir avant d'atteindre le quota Connections Tracked de ce type d'instance.
- linklocal_allowance_exceeded : nombre de paquets rejetés parce que le PPS du trafic vers les services proxy locaux a dépassé le maximum autorisé pour l'interface réseau. Cela impacte le trafic vers le service DNS, l'Instance Metadata Service et l'Amazon Time Sync Service.
- pps_allowance_exceeded : nombre de paquets mis en file d'attente ou rejetés parce que le PPS bidirectionnel a dépassé le maximum autorisé pour l'instance.
Si ces métriques ne sont exposées que sur les instances Nitro via le pilote ENA, les limitations elles-mêmes ne sont pas exclusives à Nitro. Les instances non-Nitro, virtualisées sous Xen, sont également soumises à des limitations réseau (souvent inférieures à celles des instances Nitro), mais il est logique qu'AWS ne puisse exposer ces métriques personnalisées que via son pilote propriétaire ENA.
Ces compteurs peuvent être consultés depuis l'instance avec la commande suivante :
[root@ip-172-31-82-248 ~]# ethtool -S eth0 | grep allowance
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
conntrack_allowance_available: 136812
Comment le trafic est-il modelé ?
La formulation employée dans la documentation AWS au sujet du modelage du trafic une fois la limite atteinte est ici cruciale : elle indique que les paquets sont mis en file d'attente ou rejetés. Reste qu'on ignore combien de temps ces paquets restent en file d'attente.
Bien qu'il soit impossible de savoir si le throttling s'est traduit par une mise en file d'attente ou par un rejet, nos tests montrent que, lorsque le trafic réseau ne dépasse que légèrement les limites, le modelage se résume généralement à une mise en file d'attente, qui n'excède souvent pas quelques millisecondes et n'a donc que peu, voire pas, d'impact.
Le rejet de paquets ne semble survenir que lorsque les limites sont fortement dépassées et, même dans ces cas, lorsque les pertes restent modérées, les applications TCP s'en remettent généralement sans difficulté en retransmettant simplement les paquets perdus.
Par ailleurs, les métriques ENA relatives au throttling réseau sont des compteurs de paquets cumulés depuis le dernier reset ENA : il s'agit donc d'une somme des paquets ayant subi un modelage.
Trouver un compteur non nul ne traduit pas nécessairement un problème, car la donnée peut être obsolète. Pour mieux les visualiser, vous pouvez les exporter sous forme de métrique CloudWatch via le CloudWatch Agent [2], ce qui permet d'en suivre l'évolution et de déterminer si le compteur progresse encore, et à quel rythme en paquets par seconde.
Placements EC2 et partage des ressources
Les instances EC2 sont des machines virtuelles ; or, une machine virtuelle constitue avant tout une couche d'abstraction supplémentaire au-dessus du matériel physique, partagé entre plusieurs locataires.
En règle générale, plus la taille d'une instance EC2 est grande au sein de sa famille, moins elle partagera le matériel avec d'autres locataires, jusqu'à devenir la seule machine virtuelle sur ce matériel — voire une véritable instance bare metal.
On peut ainsi supposer qu'une c5.24xlarge, taille la plus grande de sa famille, occupe très probablement seule l'hôte sous-jacent, sans partager ses limites réseau avec d'autres locataires : elle disposera donc de l'intégralité de la capacité matérielle, et bénéficiera de limites réseau bien plus élevées qu'une instance plus petite.
À l'inverse, une c5.large, taille la plus petite de la famille, partage très probablement l'hôte sous-jacent avec plusieurs locataires. Elle disposera donc d'environ 1/x de la capacité du matériel, x étant le nombre maximum de locataires sur cet hôte.
Bien que nous n'ayons aucune visibilité sur le fonctionnement de ces placements en backend, cela donne une idée générale : plus une instance est grande, plus ses limites réseau sont élevées.
De plus, lorsqu'on considère le trafic sortant de l'instance, des contraintes peuvent également intervenir au niveau de la pile réseau située en dehors de l'hyperviseur, en raison des switches et routeurs situés plus haut dans la pile.
Si nous n'avons pas non plus de visibilité sur la pile réseau d'AWS pour EC2, celle d'un datacenter classique ressemblerait à ceci :
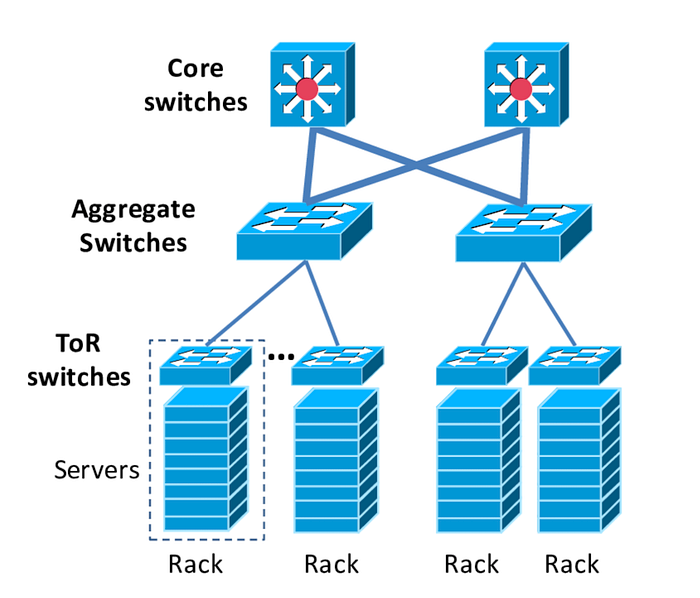
AWS nous permet toutefois de définir des stratégies de placement [3], qui régulent la distance entre les instances. Cela influe non seulement sur la latence, mais aussi sur la bande passante par flux pour les limites de flux.
Créer un Cluster Placement Group permet de rapprocher au maximum les instances les unes des autres — par exemple sur le même hôte sous-jacent, sous le même switch ToR, sous le même switch d'agrégation, etc. Cette stratégie garantit la latence la plus faible possible entre les instances du groupe et la bande passante maximale par flux la plus élevée.
Si vous ne définissez aucune stratégie de placement, AWS répartit vos instances aléatoirement en fonction de la capacité disponible : il arrive donc, par pur hasard, que des instances se retrouvent sous le même switch ToR/d'agrégation, et d'autres fois non.
À chaque arrêt et redémarrage d'une instance EC2, celle-ci est replacée à un autre endroit de l'infrastructure AWS [4], ce qui signifie qu'elle peut se retrouver in-placement (proche de votre autre instance) ou out-of-placement (éloignée de votre autre instance) — ce qui affecte la latence et le débit maximum par flux.
En raison de ce phénomène, j'ai déjà rencontré des cas où deux instances EC2 hébergeant des applications à faible latence et à fort débit par flux se trouvaient in-placement par pur hasard mais, après un stop/start, atterrissaient out-of-placement et se mettaient soudainement à rencontrer des problèmes réseau, en raison de la baisse du débit maximum par flux et de l'augmentation de la latence.
C'est pour cette raison qu'il est important de prendre en compte la nature de votre application et de définir à l'avance une stratégie de placement pour votre infrastructure AWS.
Bien entendu, le cluster placement n'est pas la seule stratégie pertinente : rapprocher au maximum les instances accroît aussi le risque qu'elles soient toutes touchées par une panne matérielle. Si toutes vos instances sont sur le même hôte sous-jacent et que ce dernier subit une défaillance, elles disparaissent toutes simultanément.
AWS propose aussi à l'inverse une stratégie de spread placement group, qui éloigne physiquement vos instances autant que possible.
Diagnostiquer le throttling de bande passante
Bien que le throttling de bande passante soit la limitation réseau la plus directe imposée par AWS, plusieurs éléments peuvent en compliquer le diagnostic.
Il faut d'abord établir la véritable capacité de bande passante de chaque type d'instance, car AWS applique deux limites distinctes aux instances EC2 : la bande passante de base (baseline) et le plafond burstable.
Lorsque la documentation indique Up to (jusqu'à) un certain débit, elle fait référence au plafond burstable : vous pouvez atteindre cette bande passante maximale, mais seulement pendant une durée limitée, jusqu'à épuisement de vos crédits de burst. Plus la taille de l'instance est grande, moins elle partage le matériel sous-jacent et plus la durée de burst est longue.
Une fois ces crédits de burst épuisés, la limite redescend au baseline (bien plus faible que la limite burstable) et le throttling réseau s'enclenche.
Pour les tailles d'instances pour lesquelles AWS annonce 25 Gigabit ou tout autre débit sans la mention Up to, il s'agit de votre limite baseline et il n'y a pas de plafond burstable.
Pour quelques types d'instances, AWS divulgue à la fois la bande passante baseline et la bande passante burstable dans sa documentation [5], mais seulement pour quelques familles.
Quant à la durée pendant laquelle on peut burster sur les instances burstable, AWS ne la divulgue jamais. Quelques tests permettent toutefois de la découvrir sans trop de difficulté.
En lançant une c5.large et une c5.24xlarge sur mon propre compte AWS, nous pouvons par exemple identifier ces limites pour une c5.large à l'aide d'iperf3.
[root@ip-172-31-82-248 ~]# iperf3 -c 172.31.23.48 -i 60 -t 480 -P 5
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.82.248 port 42202 connected to 172.31.23.48 port 5201
[ 7] local 172.31.82.248 port 42204 connected to 172.31.23.48 port 5201
[ 9] local 172.31.82.248 port 42208 connected to 172.31.23.48 port 5201
[ 11] local 172.31.82.248 port 42212 connected to 172.31.23.48 port 5201
[ 13] local 172.31.82.248 port 42218 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-60.05 sec 11.4 GBytes 1.64 Gbits/sec 19684 376 KBytes
[ 7] 0.00-60.05 sec 11.2 GBytes 1.60 Gbits/sec 17814 341 KBytes
[ 9] 0.00-60.05 sec 11.5 GBytes 1.65 Gbits/sec 18713 428 KBytes
[ 11] 0.00-60.05 sec 16.8 GBytes 2.40 Gbits/sec 24552 507 KBytes
[ 13] 0.00-60.05 sec 17.0 GBytes 2.44 Gbits/sec 22710 524 KBytes
[SUM] 0.00-60.05 sec 68.0 GBytes 9.72 Gbits/sec 103473
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 19955 341 KBytes
[ 7] 60.05-120.05 sec 11.3 GBytes 1.62 Gbits/sec 18304 428 KBytes
[ 9] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 18976 428 KBytes
[ 11] 60.05-120.05 sec 16.8 GBytes 2.41 Gbits/sec 25220 498 KBytes
[ 13] 60.05-120.05 sec 16.9 GBytes 2.42 Gbits/sec 23265 481 KBytes
[SUM] 60.05-120.05 sec 67.9 GBytes 9.72 Gbits/sec 105720
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 120.05-180.05 sec 11.5 GBytes 1.65 Gbits/sec 19194 454 KBytes
[ 7] 120.05-180.05 sec 11.1 GBytes 1.59 Gbits/sec 18328 454 KBytes
[ 9] 120.05-180.05 sec 11.5 GBytes 1.64 Gbits/sec 19259 358 KBytes
[ 11] 120.05-180.05 sec 16.7 GBytes 2.39 Gbits/sec 24946 542 KBytes
[ 13] 120.05-180.05 sec 17.1 GBytes 2.45 Gbits/sec 23032 323 KBytes
[SUM] 120.05-180.05 sec 67.9 GBytes 9.72 Gbits/sec 104759
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 180.05-240.05 sec 11.5 GBytes 1.65 Gbits/sec 20069 446 KBytes
[ 7] 180.05-240.05 sec 11.2 GBytes 1.60 Gbits/sec 17967 463 KBytes
[ 9] 180.05-240.05 sec 11.4 GBytes 1.64 Gbits/sec 18942 323 KBytes
[ 11] 180.05-240.05 sec 16.7 GBytes 2.39 Gbits/sec 24645 498 KBytes
[ 13] 180.05-240.05 sec 17.0 GBytes 2.44 Gbits/sec 22380 507 KBytes
[SUM] 180.05-240.05 sec 67.9 GBytes 9.72 Gbits/sec 104003
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 13304 323 KBytes
[ 7] 240.05-300.05 sec 7.85 GBytes 1.12 Gbits/sec 12274 498 KBytes
[ 9] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 12763 350 KBytes
[ 11] 240.05-300.05 sec 11.5 GBytes 1.65 Gbits/sec 16480 454 KBytes
[ 13] 240.05-300.05 sec 11.9 GBytes 1.71 Gbits/sec 15472 647 KBytes
[SUM] 240.05-300.05 sec 47.1 GBytes 6.74 Gbits/sec 70293
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 300.05-360.05 sec 879 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 300.05-360.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 360.05-420.05 sec 881 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 360.05-420.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 420.05-480.05 sec 782 MBytes 109 Mbits/sec 0 323 KBytes
[ 7] 420.05-480.05 sec 933 MBytes 130 Mbits/sec 0 498 KBytes
[ 9] 420.05-480.05 sec 932 MBytes 130 Mbits/sec 0 350 KBytes
[ 11] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 454 KBytes
[ 13] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 647 KBytes
[SUM] 420.05-480.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
Ci-dessus, iperf3 se connecte depuis ma c5.large vers la c5.24xlarge plus grande (afin de garantir que les limites de la c5.large soient atteintes en premier et constituent le facteur limitant), en rapportant à intervalles de 60 s (-i 60), sur 8 minutes (-t 480), avec 5 flux parallèles (-P 5).
D'après cette sortie, on observe que pendant les 5 premières minutes, le débit est resté autour de 10 Gbps, ce qu'AWS annonce comme Up to pour les c5.large. Au-delà de 5 minutes, le débit chute toutefois à seulement 750 Mbps.
Cela nous donne deux limites non documentées pour les instances c5.large :
- Bande passante baseline de 750 Mbps ;
- Burst limité à 5 minutes maximum, jusqu'à 10 Gbps.
Désormais, nous savons que les c5.large disposent d'une bande passante baseline de 750 Mbps et peuvent burster jusqu'à 10 Gbps pendant 5 minutes seulement.
On constate également qu'une fois le throttling réseau enclenché, les compteurs ENA pour le modelage de la bande passante sortante se sont mis à augmenter :
[root@ip-172-31-82-248 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 42427304
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
[root@ip-172-31-82-248 ~]#
Bande passante sortante vers Internet
Les instances EC2 atteignent leur bande passante maximale lorsque la source et la destination du trafic se situent toutes deux dans AWS et dans la même région. La donne change dès que la source ou la destination se trouve hors de la région, qu'il s'agisse d'une autre région AWS ou d'un routage vers Internet.
Dans ces cas-là, si la taille d'instance utilisée est suffisamment importante pour disposer d'au moins 32 vCPUs, la limite de bande passante vers d'autres régions ou Internet correspond à 50 % de sa bande passante réseau. [6]
Si l'instance dispose de moins de 32 vCPUs, la limite est fixée à un maximum de 5 Gbps. [6]
Limitations par flux
Autre limitation de bande passante moins évidente : AWS plafonne la bande passante par flux. Le débit maximal par flux est de 5 Gbps, quel que soit le type ou la taille d'instance, et il s'agit d'une limite stricte. [6]
L'un des deux seuls moyens de relever cette limite consiste à placer les instances source et destination au sein d'un même placement EC2. Cela peut se faire en regroupant les instances dans un même cluster placement group, ou par pur hasard si elles atterrissent sous les mêmes switches d'agrégation, comme expliqué plus haut dans la section sur les placements EC2.
Lorsque les instances source et destination se trouvent dans le même placement EC2, la bande passante maximale par flux est de 10 Gbps. [6]
L'autre solution consiste à utiliser ENA Express sur des instances éligibles au sein du même sous-réseau, où la limite passe à 25 Gbps par flux entre ces instances. [6]
À défaut, dès que possible, privilégiez le trafic multi-flux pour atteindre la bande passante et les performances maximales — cela influera également sur les limiteurs PPS abordés plus loin.
Un point important à souligner : le throttling lié aux limitations par flux n'est exposé nulle part dans les métriques de throttling ENA.
Là encore, on peut le démontrer facilement avec iperf3. En lançant un seul flux depuis ma c5.large (censée pouvoir atteindre 10 Gbps) vers ma c5.24xlarge, en out-of-placement, on voit que le débit maximal sur un seul flux est plafonné à 5 Gbps :
[root@ip-172-31-92-221 ~]# iperf3 -c 172.31.23.48 -t 60 -P 1
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.92.221 port 42472 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 594 MBytes 4.98 Gbits/sec 0 1.43 MBytes
[ 5] 1.00-2.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
[ 5] 2.00-3.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
Pour autant, aucun compteur n'augmente dans les métriques de throttling ENA :
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
C'est particulièrement important, car cela signifie que le throttling lié aux limitations par flux est silencieux et très difficile à détecter lorsqu'il se produit.
Micro-bursting
Autre élément à prendre en compte côté bande passante : le micro-bursting. Il se produit lorsque vous atteignez les limites de bande passante très brièvement, ce qui est souvent difficile à repérer.
Le scénario typique : les métriques de throttling ENA augmentent très lentement, mais les métriques CloudWatch du trafic réseau ne semblent jamais atteindre votre plafond de bande passante.
Le throttling AWS se produit sur des intervalles extrêmement courts et, sans visibilité précise sur leur granularité, j'ai déjà rencontré des situations où seules des mesures sub-secondes permettaient de repérer le micro-bursting.
CloudWatch, en revanche, fournit par défaut des points de mesure toutes les 5 minutes, et avec le monitoring renforcé, on peut descendre à 1 minute.
Parfois, le burst est si bref qu'il se dilue dans les intervalles de 5 minutes proposés par CloudWatch et reste invisible.
La solution la plus simple consiste à se fier aux compteurs ENA d'AWS, même si les pics de trafic ne sont pas visibles ; le CloudWatch Agent permet par ailleurs d'obtenir des points de mesure jusqu'à 1 s, ce qui devrait capturer la plupart des pics de bande passante.
Au-delà, on peut comparer le volume de trafic dans les files RX/TX d'ENA avec le volume de modelage rapporté.
Cela dit, dans la plupart des scénarios de micro-bursting, le volume de modelage n'est pas suffisamment important pour s'en inquiéter, le modelage se résumant majoritairement à de la mise en file d'attente, et les applications TCP se remettent facilement de pertes mineures.
Lecture des métriques réseau CloudWatch
Autre erreur courante : mal interpréter les métriques réseau CloudWatch. Si toutes les limites réseau d'AWS sont exprimées en bits par seconde, les métriques réseau CloudWatch sont en octets sur une période donnée. Il devient donc très difficile de savoir à quelle distance on se trouve du plafond de bande passante en se contentant de regarder les métriques NetworkIn et NetworkOut.
Sur mon instance c5.24xlarge d'exemple, en ouvrant NetworkIn, on obtient quelque chose comme ceci :
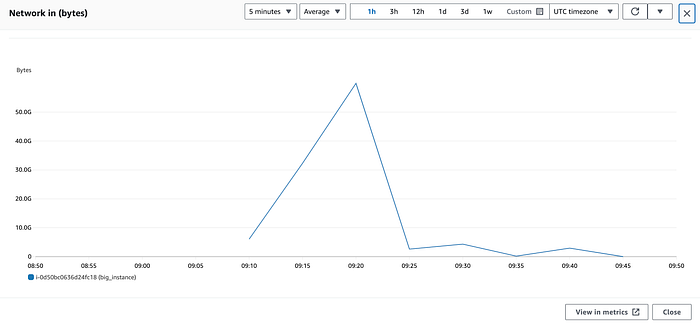
On pourrait facilement croire que cette instance a culminé à plus de 50 Gbps de trafic entrant à 09:20 — mais c'est faux.
Pour connaître le trafic réel en bps, il faut passer la statistique en Sum et la diviser par la période en secondes (5 minutes par défaut), afin d'obtenir le trafic moyen par seconde sur cet intervalle.
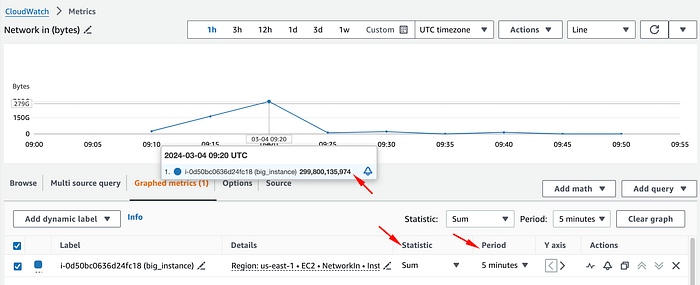
Ici, on divise le total d'octets de ce point de mesure (299800135974) par 300 secondes (5 minutes), soit 999333786,58 octets par seconde.
Il faut ensuite convertir les octets en bits. Pour simplifier, on peut convertir directement en Mbps en multipliant par 0,000008, puisque 1 octet par seconde équivaut à 0,000008 Mbps.
Une fois la conversion effectuée, on constate que cette métrique nous indique en réalité un trafic entrant moyen de 7994 Mbps sur ces 5 minutes, très loin de l'impression initiale de 50 Gbps.
Pour obtenir le trafic réseau total sur cette période, il faudrait également convertir NetworkOut et additionner les deux valeurs.
Diagnostiquer le throttling du suivi de connexions
Au-delà des limitations de bande passante, AWS impose également une limite sur le nombre de connexions suivies, au-delà de laquelle les nouvelles connexions sont rejetées.
Cela peut être très pénalisant : une fois cette limite atteinte, AWS refuse toute nouvelle connexion vers votre instance EC2, jusqu'à ce que le nombre de connexions repasse sous le seuil maximal autorisé.
Jusqu'à très récemment, AWS ne communiquait rien à ce sujet et aucune mention de ces limites ne figurait dans la documentation. Heureusement, AWS a commencé à divulguer le nombre maximal de connexions suivies par type d'instance EC2, mais uniquement pour les instances de génération moderne basées sur Nitro.
Ces limites existent également sur les instances non-Nitro, mais elles ne sont pas divulguées et le seul moyen de les découvrir est de tester à partir de combien de connexions votre instance commence à refuser les nouvelles.
Le nombre maximal de connexions suivies sur une instance Nitro peut être consulté avec la commande suivante :
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep conntrack_allowance_available
conntrack_allowance_available: 136813
[root@ip-172-31-92-221 ~]#
Cette limite n'existe que parce que les security groups sont stateful : ils suivent les connexions via conntrack pour permettre aux réponses au trafic entrant de sortir de l'instance, indépendamment des règles sortantes du security group, et inversement.
Cela étant, il existe un moyen de contourner cette limitation sans augmenter la taille de l'instance : ne pas utiliser de security groups.
Dès lors qu'un security group dispose de règles entrantes et sortantes autorisant tout le trafic, ces flux sont marqués NOTRACK et ne sont pas suivis par AWS, donc ne comptent pas dans le quota conntrack. [7]
On peut également utiliser des ACL réseau stateless, voire des règles iptables directement, qu'elles soient stateless ou stateful — dans ce dernier cas, vous gardez le contrôle du conntrack Linux côté instance et pouvez en relever les limites au besoin.
Seule exception à ce contournement : les connexions vers certains services AWS spécifiques, listés ci-dessous, sont toujours suivies automatiquement, quelle que soit la configuration du security group, afin de garantir un routage symétrique. Dans ce cas, l'unique solution consiste à augmenter la taille de l'instance. [7]
- Egress-only internet gateways
- Gateway Load Balancers
- Global Accelerator accelerators
- NAT gateways
- Network Firewall firewall endpoints
- Network Load Balancers
- AWS PrivateLink (interface VPC endpoints)
- Transit gateway attachments
- AWS Lambda (Hyperplane elastic network interfaces)
Diagnostiquer le throttling vers les services proxy locaux
AWS propose plusieurs services sous forme de proxies locaux au sein d'EC2 : l'AWS DNS Resolver (soit la deuxième IP de votre sous-réseau VPC, soit 169.254.169.253 sur n'importe quelle instance EC2), le serveur NTP fourni par AWS (169.254.169.123) et l'Instance Metadata Service (169.254.169.254).
Ces services partagent une limite stricte de 1024 pps (paquets par seconde) par interface ENI. Au-delà, l'interface est throttlée via linklocal_allowance_exceeded.
Le plus souvent, le throttling provient ici d'une utilisation excessive de l'Instance Metadata Service. Une requête IMDS placée dans une fonction récursive fréquemment appelée, par exemple, peut suffire à atteindre cette limite. À noter : la limite est en paquets par seconde, et une requête HTTP IMDS consomme plusieurs paquets réseau pour aboutir — cette limite n'équivaut donc pas à 1024 requêtes par seconde.
La bonne pratique consiste à utiliser IMDS avec parcimonie et à mettre en cache les résultats dès que possible, puisqu'il s'agit d'une limite stricte qui ne peut être modifiée, quelle que soit la taille de l'instance.
Un autre cas fréquent de throttling est lié à un grand nombre de requêtes DNS ; la solution consiste alors à mettre en place un cache DNS local.
Lorsque les compteurs ENA linklocal_allowance_exceeded augmentent, vous pouvez identifier le service responsable du throttling en effectuant une capture de paquets sur le trafic vers ces IPs et en isolant s'il s'agit de DNS, HTTP ou NTP.
Diagnostiquer le throttling de paquets
AWS pratique également une autre forme de throttling fondée sur le nombre de paquets par seconde, où les choses se compliquent puisque la documentation sur ces limitations est minime.
Même si une instance EC2 reste sous sa limite de bande passante maximale, son trafic réseau peut tout de même être throttlé parce qu'elle atteint le nombre maximal de paquets par seconde autorisé pour cette instance. La limite est ici par instance, et non par ENI comme pour linklocal_allowance_exceeded.
AWS ne divulgue cependant le nombre maximal de paquets par seconde autorisé pour aucun type d'instance EC2 sans NDA, et ce seuil n'est pas fixe : il peut varier en fonction du type de paquets composant le trafic.
Les limites PPS d'une instance EC2 dépendent de : [8]
- la nature du trafic, TCP ou UDP ;
- du nombre de flux ;
- de la taille des paquets ;
- du fait que les connexions soient nouvelles ou existantes (limitation des TCP SYN) ;
- et des règles de security group appliquées.
Il est donc quasiment impossible d'établir une limite PPS fixe avec certitude, même par tests exhaustifs, puisque la limite réelle dépend du profil concret du trafic réseau.
Par exemple, une application qui crée beaucoup de nouvelles connexions atteindra probablement la limitation des TCP SYN — et donc la limite PPS — bien plus tôt qu'une application qui repose majoritairement sur des connexions existantes.
S'il existe des moyens de stresser l'instance avec des paquets pour obtenir une estimation grossière des limites PPS — AWS détaille la procédure dans cet article [8] —, cette approche est nettement moins fiable que l'utilisation d'iperf pour mesurer les limites de bande passante.
Mieux vaut effectuer des tests de charge sur l'application réellement hébergée et surveiller les métriques ENA de throttling PPS, puisque cela tient compte des schémas réseau de l'application.
Heureusement, ces limitations sont souvent assez confortables et les limites de bande passante sont généralement atteintes en premier. Reste que les schémas de trafic à privilégier sont : une application en TCP s'appuyant majoritairement sur des connexions existantes, des paquets de grande taille, de nombreux flux différents, et des security groups autorisant l'ensemble du trafic entrant et sortant sur ces ports pour bénéficier du no-tracking.
En cas de throttling, adapter le profil de trafic pour se rapprocher autant que possible de ce schéma devrait aider ; à défaut, augmenter la taille de l'instance.