· Perché è importante conoscere i limiti del networking AWS
· Come viene modellato il traffico?
· Placement EC2 e condivisione delle risorse
· Troubleshooting del bandwidth throttling
∘ Bandwidth in egress verso Internet
∘ Come leggere le metriche di rete CloudWatch
· Troubleshooting del throttling sul Connection Tracking
· Troubleshooting del throttling verso i Local Proxy Services
· Troubleshooting del Packet Throttling
Perché è importante conoscere i limiti del networking AWS
Nel vasto panorama dei servizi AWS, le istanze EC2 e la rete EC2 sono i mattoni fondamentali su cui poggia la maggior parte degli altri servizi AWS, a supporto di applicazioni e servizi critici per l'infrastruttura digitale moderna. Ottenere il massimo dalle prestazioni di queste istanze richiede però di entrare nei meccanismi della rete AWS e, in particolare, del network throttling. Quest'ultimo, che può manifestarsi in varie forme, incide direttamente sulle prestazioni e sulla scalabilità delle istanze EC2 e, di riflesso, di molti altri servizi dell'ecosistema AWS.
AWS applica il network throttling tramite due meccanismi principali: limiti di bandwidth e limiti sui pacchetti al secondo (PPS). Il throttling sulla bandwidth incide sul volume di dati trasferibili in un dato intervallo, mentre quello sui PPS limita il numero di pacchetti che possono essere inviati o ricevuti. Sono vincoli pensati con cura per preservare salute ed efficienza complessive dell'infrastruttura AWS, ma possono diventare un ostacolo significativo quando si vuole ottimizzare le prestazioni applicative e l'utilizzo delle risorse.
A complicare il quadro c'è la scarsità di documentazione ufficiale su alcuni aspetti del network throttling AWS. Le informazioni sul come e sul quando AWS attivi questi meccanismi sono difficili da reperire e gli sviluppatori si trovano spesso a doversi muovere fra forum, esperienze altrui e prove sul campo per capire come mitigarne gli effetti sui propri servizi. Questa carenza di documentazione chiara e accessibile aggiunge un ulteriore livello di complessità alla gestione e all'ottimizzazione delle prestazioni di rete in AWS.
In questo articolo ricomporremo i pezzi sparsi del puzzle del network throttling AWS per offrire un quadro chiaro e completo di come AWS implementa i meccanismi di throttling sulla rete EC2.
Quali sono i limiti?
Sulle generazioni moderne di istanze EC2 basate su Nitro, AWS espone alcune metriche come contatori dei pacchetti soggetti al network throttling, elencati nella documentazione ufficiale [1].
- bw_in_allowance_exceeded: numero di pacchetti messi in coda o scartati perché la bandwidth aggregata in ingresso ha superato il massimo previsto per quel tipo/dimensione di istanza;
- bw_out_allowance_exceeded: numero di pacchetti messi in coda o scartati perché la bandwidth aggregata in uscita ha superato il massimo previsto per quel tipo/dimensione di istanza;
- conntrack_allowance_exceeded: numero di pacchetti scartati perché il connection tracking ha superato il massimo per l'istanza e non è stato possibile aprire nuove connessioni. Può tradursi in perdita di pacchetti per il traffico da o verso l'istanza.
- conntrack_allowance_available: numero di connessioni tracciate che l'istanza può ancora aprire prima di raggiungere l'allowance di Connections Tracked previsto per quel tipo di istanza.
- linklocal_allowance_exceeded: numero di pacchetti scartati perché i PPS del traffico verso i local proxy services hanno superato il massimo previsto per l'interfaccia di rete. Riguarda il traffico verso il servizio DNS, l'Instance Metadata Service e l'Amazon Time Sync Service.
- pps_allowance_exceeded: numero di pacchetti messi in coda o scartati perché i PPS bidirezionali hanno superato il massimo dell'istanza.
Queste metriche sono disponibili solo sulle istanze basate su Nitro tramite il driver ENA, ma i limiti non sono esclusivi delle istanze Nitro. Anche le istanze non-Nitro, virtualizzate in Xen, hanno limiti di rete (spesso persino più stringenti rispetto a quelle Nitro); è però naturale che AWS possa esporre queste metriche custom solo sul proprio driver proprietario ENA.
Lato istanza, i contatori si visualizzano con il comando seguente:
[root@ip-172-31-82-248 ~]# ethtool -S eth0 | grep allowance
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
conntrack_allowance_available: 136812
Come viene modellato il traffico?
Le parole usate dalla documentazione AWS per descrivere come viene modellato il traffico al raggiungimento di un limite sono qui fondamentali: i pacchetti vengono messi in coda o scartati. Quanto a lungo restino in coda, però, non è dato saperlo.
Non c'è modo di stabilire a priori se il throttling si traduca in pacchetti accodati o scartati, ma dai test si nota che, in genere, quando il traffico di rete supera i limiti solo di poco lo shaping consiste nel solo accodamento, e spesso la coda dura non più di qualche millisecondo, con un impatto trascurabile o nullo.
Lo scarto dei pacchetti, invece, sembra entrare in gioco solo quando i limiti vengono superati nettamente; e anche in quei casi, se la quantità scartata resta contenuta, le applicazioni TCP riescono di solito a recuperare con relativa facilità ritrasmettendo i pacchetti persi.
Le metriche ENA sul network throttling sono peraltro contatori di pacchetti dall'ultimo reset di ENA, quindi rappresentano la somma dei pacchetti che sono stati modellati.
Trovare uno di questi contatori a un valore diverso da zero non è di per sé sintomo di un problema, perché il dato potrebbe essere ormai datato. Per averne una visione più chiara conviene esportarli come metrica CloudWatch tramite il CloudWatch Agent [2]: in questo modo se ne può seguire l'andamento nel tempo e capire se il contatore continua a crescere e a quale ritmo in pacchetti al secondo.
Placement EC2 e condivisione delle risorse
Le istanze EC2 sono macchine virtuali; e una macchina virtuale è di fatto un ulteriore livello di astrazione rispetto all'hardware fisico, che viene condiviso fra più tenant.
Come regola di massima, più grande è la dimensione di un'istanza EC2 nella sua famiglia, meno l'hardware viene condiviso con altri tenant, fino al caso in cui l'istanza è l'unica macchina virtuale su quell'hardware — o, addirittura, è un'istanza metal vera e propria.
Si può quindi assumere che, ad esempio, una c5.24xlarge — la dimensione più grande della famiglia — abbia con tutta probabilità l'intero host sottostante a propria disposizione, senza condividerne i limiti di rete con altri tenant: avrà quindi a disposizione l'intera capacità dell'hardware e limiti di rete molto più ampi rispetto a una taglia inferiore.
Al contrario, una c5.large — la dimensione più piccola della famiglia — condividerà con ogni probabilità l'host sottostante con più tenant. Avrà quindi 1/x della capacità dell'hardware sottostante, dove x è il numero massimo di tenant ammessi su quell'hardware.
Pur non avendo visibilità sul funzionamento di questi placement nel backend, ne deriva un'idea di massima: più grande è la taglia di un'istanza, più alti saranno i limiti di rete.
Inoltre, sul traffico in uscita dall'istanza possono pesare anche vincoli legati allo stack di rete a valle dell'hypervisor, dovuti a switch e router più a monte.
Sebbene non si abbia visibilità sullo stack di rete EC2 di AWS, lo stack di un tipico datacenter avrebbe più o meno questo aspetto:
AWS permette però di definire strategie di placement [3], che regolano la distanza fra le istanze. Questo non incide solo sulla latenza, ma anche sulla bandwidth per flusso ai fini dei flow limit.
Creare un Cluster Placement Group significa collocare le istanze il più vicino possibile fra loro — ad esempio sullo stesso host sottostante, sullo stesso switch ToR, sullo stesso aggregate switch e così via. Questa strategia garantisce la latenza più bassa possibile fra le istanze del placement group e i limiti di bandwidth per flusso più alti possibili.
Senza una strategia di placement esplicita, AWS alloca le istanze in modo casuale in base alla capacità: a volte, per pura fortuna, possono finire sullo stesso ToR/aggregate switch; altre volte no.
Ogni volta che si arresta e si riavvia un'istanza EC2, questa viene ricollocata in un punto diverso dell'infrastruttura AWS [4]: può finire in-placement (vicino alle altre istanze) oppure out-of-placement (lontano dalle altre); e questa condizione incide su latenza e throughput massimo per flusso.
Per via di questo fenomeno, mi è capitato di vedere casi in cui due istanze EC2 che ospitavano applicazioni a bassa latenza e ad alto throughput per flusso erano in-placement per pura fortuna; dopo uno stop/start sono finite out-of-placement e di colpo hanno iniziato ad avere problemi di rete, a causa del throughput massimo per flusso ridotto e della latenza più alta.
Per questo è importante valutare la natura della propria applicazione e definire in anticipo una strategia di placement per la propria infrastruttura AWS.
Il cluster placement non è ovviamente l'unica strategia valida: tenere le istanze il più vicino possibile aumenta anche la probabilità che vengano colpite tutte insieme da un guasto hardware. Se tutte le istanze condividono lo stesso host sottostante e quell'host si guasta, vanno giù tutte simultaneamente.
In alternativa, AWS offre la strategia spread placement group, che fa l'esatto opposto: tiene le istanze il più distanti possibile fisicamente.
Troubleshooting del bandwidth throttling
Sebbene il bandwidth throttling sia il limite di rete più immediato fra quelli imposti da AWS, alcuni dettagli lo rendono più insidioso di quanto sembri.
Per prima cosa occorre stabilire la reale capacità di bandwidth di ciascun tipo di istanza, perché AWS prevede due limiti distinti per le istanze EC2: la baseline bandwidth e il burstable ceiling.
Quando la documentazione riporta "Up to" seguito da un valore, si riferisce al burstable ceiling: quel massimo di bandwidth è raggiungibile, ma solo per un certo lasso di tempo, fino a esaurire i burst credit. Più grande è la taglia dell'istanza, meno condivide l'hardware sottostante e più a lungo può sostenere il burst.
Una volta esauriti i burst credit, il limite scende alla baseline (molto più bassa del limite burstable) e parte il network throttling.
Per le taglie in cui AWS dichiara "25 Gigabit" o un altro valore senza il "Up to", quello è il limite di baseline e non esiste un burstable ceiling.
Per alcuni tipi di istanza, AWS pubblica nella propria documentazione sia la baseline bandwidth sia la burstable bandwidth [5], anche se solo per poche famiglie.
Per quanto tempo si possa mantenere il burst sulle istanze burstable, AWS non lo dichiara mai. Con qualche test, però, non è troppo difficile scoprirlo.
Avviando una c5.large e una c5.24xlarge sul mio account AWS, possiamo individuare questi limiti per una c5.large, ad esempio, usando iperf3.
[root@ip-172-31-82-248 ~]# iperf3 -c 172.31.23.48 -i 60 -t 480 -P 5
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.82.248 port 42202 connected to 172.31.23.48 port 5201
[ 7] local 172.31.82.248 port 42204 connected to 172.31.23.48 port 5201
[ 9] local 172.31.82.248 port 42208 connected to 172.31.23.48 port 5201
[ 11] local 172.31.82.248 port 42212 connected to 172.31.23.48 port 5201
[ 13] local 172.31.82.248 port 42218 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-60.05 sec 11.4 GBytes 1.64 Gbits/sec 19684 376 KBytes
[ 7] 0.00-60.05 sec 11.2 GBytes 1.60 Gbits/sec 17814 341 KBytes
[ 9] 0.00-60.05 sec 11.5 GBytes 1.65 Gbits/sec 18713 428 KBytes
[ 11] 0.00-60.05 sec 16.8 GBytes 2.40 Gbits/sec 24552 507 KBytes
[ 13] 0.00-60.05 sec 17.0 GBytes 2.44 Gbits/sec 22710 524 KBytes
[SUM] 0.00-60.05 sec 68.0 GBytes 9.72 Gbits/sec 103473
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 19955 341 KBytes
[ 7] 60.05-120.05 sec 11.3 GBytes 1.62 Gbits/sec 18304 428 KBytes
[ 9] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 18976 428 KBytes
[ 11] 60.05-120.05 sec 16.8 GBytes 2.41 Gbits/sec 25220 498 KBytes
[ 13] 60.05-120.05 sec 16.9 GBytes 2.42 Gbits/sec 23265 481 KBytes
[SUM] 60.05-120.05 sec 67.9 GBytes 9.72 Gbits/sec 105720
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 120.05-180.05 sec 11.5 GBytes 1.65 Gbits/sec 19194 454 KBytes
[ 7] 120.05-180.05 sec 11.1 GBytes 1.59 Gbits/sec 18328 454 KBytes
[ 9] 120.05-180.05 sec 11.5 GBytes 1.64 Gbits/sec 19259 358 KBytes
[ 11] 120.05-180.05 sec 16.7 GBytes 2.39 Gbits/sec 24946 542 KBytes
[ 13] 120.05-180.05 sec 17.1 GBytes 2.45 Gbits/sec 23032 323 KBytes
[SUM] 120.05-180.05 sec 67.9 GBytes 9.72 Gbits/sec 104759
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 180.05-240.05 sec 11.5 GBytes 1.65 Gbits/sec 20069 446 KBytes
[ 7] 180.05-240.05 sec 11.2 GBytes 1.60 Gbits/sec 17967 463 KBytes
[ 9] 180.05-240.05 sec 11.4 GBytes 1.64 Gbits/sec 18942 323 KBytes
[ 11] 180.05-240.05 sec 16.7 GBytes 2.39 Gbits/sec 24645 498 KBytes
[ 13] 180.05-240.05 sec 17.0 GBytes 2.44 Gbits/sec 22380 507 KBytes
[SUM] 180.05-240.05 sec 67.9 GBytes 9.72 Gbits/sec 104003
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 13304 323 KBytes
[ 7] 240.05-300.05 sec 7.85 GBytes 1.12 Gbits/sec 12274 498 KBytes
[ 9] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 12763 350 KBytes
[ 11] 240.05-300.05 sec 11.5 GBytes 1.65 Gbits/sec 16480 454 KBytes
[ 13] 240.05-300.05 sec 11.9 GBytes 1.71 Gbits/sec 15472 647 KBytes
[SUM] 240.05-300.05 sec 47.1 GBytes 6.74 Gbits/sec 70293
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 300.05-360.05 sec 879 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 300.05-360.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 360.05-420.05 sec 881 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 360.05-420.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 420.05-480.05 sec 782 MBytes 109 Mbits/sec 0 323 KBytes
[ 7] 420.05-480.05 sec 933 MBytes 130 Mbits/sec 0 498 KBytes
[ 9] 420.05-480.05 sec 932 MBytes 130 Mbits/sec 0 350 KBytes
[ 11] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 454 KBytes
[ 13] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 647 KBytes
[SUM] 420.05-480.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
Sopra vediamo iperf3 collegarsi dalla mia istanza c5.large alla c5.24xlarge più grande (così siamo certi che a essere colpiti per primi siano i limiti della c5.large, ed è proprio questo il limite che vogliamo misurare), con report a intervalli di 60s (-i 60), per 8 minuti (-t 480) e con 5 stream paralleli (-P 5).
L'output mostra che per i primi 5 minuti il bitrate si attesta intorno ai 10 Gbps, valore che AWS pubblicizza come "Up to" per le c5.large. Tuttavia, dopo 5 minuti il bitrate scende a soli 750 Mbps.
Otteniamo così due limiti non documentati per le istanze c5.large:
- baseline bandwidth di 750 Mbps;
- burst limit fino a 10 Gbps per 5 minuti.
Ora sappiamo che le c5.large hanno una baseline bandwidth di 750 Mbps e possono fare burst fino a 10 Gbps per soli 5 minuti.
Vediamo anche che, una volta entrato in azione il network throttling, i contatori ENA per lo shaping della bandwidth in uscita hanno iniziato a crescere:
[root@ip-172-31-82-248 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 42427304
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
[root@ip-172-31-82-248 ~]#
Bandwidth in egress verso Internet
Le istanze EC2 raggiungono il loro potenziale massimo di bandwidth solo quando origine e destinazione del traffico sono entrambe in AWS e nella stessa region. La situazione cambia quando origine o destinazione si trovano fuori region, in un'altra region AWS o instradate verso Internet.
In questi casi, se la taglia di istanza utilizzata è molto grande e dispone di almeno 32 vCPU, il limite di bandwidth verso altre region o Internet è pari al 50% della network bandwidth. [6]
Se la taglia ha meno di 32 vCPU, il limite è fissato a un massimo di 5 Gbps. [6]
Limiti per flusso
Un altro limite di bandwidth meno evidente è quello applicato da AWS al singolo flusso. Il throughput massimo per flusso è di 5 Gbps, indipendentemente dalla famiglia o dalla taglia dell'istanza, ed è un hard limit. [6]
Uno dei due unici modi per superare questo limite è che istanza di origine e di destinazione si trovino entrambe nello stesso EC2 placement. Lo si può ottenere collocando le istanze nello stesso cluster placement group oppure, per pura fortuna, se finiscono sugli stessi aggregate switch, come visto nella sezione EC2 Placement di questo articolo.
Quando origine e destinazione sono nello stesso EC2 placement, la bandwidth massima per flusso passa a 10 Gbps. [6]
L'altra strada è usare ENA Express su istanze idonee all'interno della stessa subnet: in quel caso il limite sale a 25 Gbps per flusso fra quelle istanze. [6]
In alternativa, ogniqualvolta sia possibile, conviene usare traffico multi-flow per garantire la massima capacità di bandwidth e le migliori prestazioni: questo aiuta anche con i limiter PPS che vedremo più avanti.
Un punto importante da sottolineare è che il throttling dovuto ai limiti per flusso non è esposto da nessuna delle metriche ENA di throttling.
Lo si può verificare facilmente, anche in questo caso, con iperf3. Eseguendo un singolo stream dalla mia c5.large (che dovrebbe poter raggiungere 10 Gbps) alla c5.24xlarge, fuori placement, vediamo il throughput massimo del singolo flusso fermarsi a 5 Gbps:
[root@ip-172-31-92-221 ~]# iperf3 -c 172.31.23.48 -t 60 -P 1
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.92.221 port 42472 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 594 MBytes 4.98 Gbits/sec 0 1.43 MBytes
[ 5] 1.00-2.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
[ 5] 2.00-3.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
Eppure, nessun contatore è cresciuto nelle metriche ENA di throttling:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Il punto è cruciale, perché significa che il network throttling per limiti di flusso è silenzioso e molto difficile da intercettare quando si verifica.
Micro-bursting
Un altro aspetto da considerare nel bandwidth throttling è il micro-bursting: si verifica quando si raggiungono i limiti di bandwidth per intervalli molto brevi, spesso difficili da rilevare.
Lo scenario tipico è quello in cui le metriche ENA di throttling crescono molto lentamente, ma controllando le metriche CloudWatch del traffico di rete non si vede mai il valore avvicinarsi al bandwidth ceiling.
Il throttling AWS opera su intervalli incredibilmente brevi e, pur non avendo visibilità su quanto rapidamente accada, mi sono trovato in situazioni in cui solo misurazioni inferiori al secondo riuscivano a cogliere il micro-bursting.
CloudWatch, invece, ha datapoint con intervalli di 5 minuti per impostazione predefinita; con il monitoraggio avanzato si scende a 1 minuto.
A volte il burst è così breve da diluirsi negli intervalli di 5 minuti di CloudWatch, e non lo si vede.
La soluzione più semplice è fidarsi del fatto che i contatori ENA di AWS siano corretti anche quando non si riescono a individuare i picchi di traffico; usando il CloudWatch Agent è comunque possibile ottenere datapoint anche di 1 secondo, sufficienti a catturare la maggior parte dei picchi di bandwidth.
Oltre a questo, l'opzione è confrontare il traffico nelle code ENA RX/TX con la quantità di shaping segnalata.
Nella maggior parte degli scenari di micro-bursting, però, l'entità dello shaping non è abbastanza significativa da preoccuparsene, perché si traduce per lo più in accodamento; e con applicazioni TCP è facile recuperare da piccole perdite.
Come leggere le metriche di rete CloudWatch
Un altro errore frequente è interpretare male le metriche di rete CloudWatch. Tutti i limiti di rete AWS sono espressi in bit al secondo, mentre le metriche di rete CloudWatch sono in byte su un intervallo di tempo. Capire quanto si è vicini al bandwidth ceiling guardando semplicemente le metriche NetworkIn e NetworkOut diventa quindi davvero confuso.
Sulla mia istanza c5.24xlarge di esempio, aprendo NetworkIn vedremmo qualcosa di simile a questo:
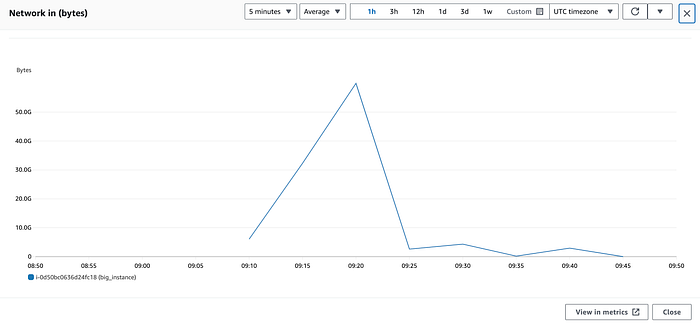
Si potrebbe facilmente cadere nell'inganno di credere che questa istanza abbia avuto un picco oltre i 50 Gbps di traffico in ingresso alle 09:20; in realtà, non è così.
Per capire il traffico di rete reale in bps bisogna cambiare la statistica in Sum e dividere il valore per il periodo in secondi (per default 5 minuti), ottenendo così la media di traffico al secondo durante quell'intervallo.
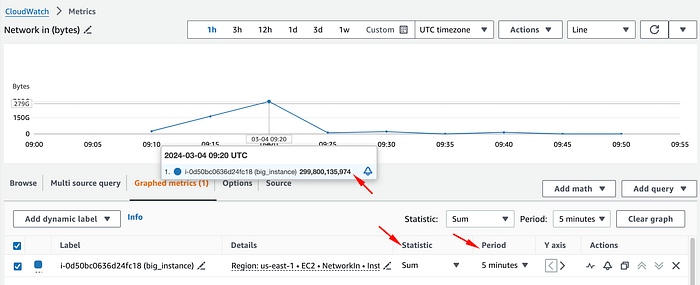
In questo caso dividiamo il totale dei byte di quel datapoint (299800135974) per 300 secondi (5 minuti), ottenendo 999333786,58 byte al secondo.
Poi convertiamo i byte in bit. Per semplificare, possiamo passare direttamente a Mbps moltiplicando per 0,000008, dato che 1 byte al secondo equivale a 0,000008 Mbps.
Una volta convertito, scopriamo che questa metrica indica in realtà una media di traffico in ingresso di 7994 Mbps in quel periodo di 5 minuti, ben lontana dall'impressione iniziale di 50 Gbps.
Per ottenere il traffico di rete totale di quel periodo dovremmo convertire allo stesso modo NetworkOut e sommare i due valori.
Troubleshooting del throttling sul Connection Tracking
Oltre ai limiti di bandwidth, AWS impone anche un limite sul numero di connessioni tracciate; superato quel valore, comincia a rifiutare nuove connessioni.
È un problema serio, perché una volta raggiunto il limite AWS rifiuta ogni nuova connessione verso la propria istanza EC2 finché il numero di connessioni non scende al di sotto del massimo consentito.
Fino a poco tempo fa, AWS non aveva mai dichiarato nulla in proposito e nella documentazione non vi era alcun riferimento a questi limiti. Per fortuna, AWS ha cominciato di recente a pubblicare il numero massimo di connessioni tracciate per ciascun tipo di istanza EC2, anche se solo per le istanze di generazione moderna basate su Nitro.
Questi limiti esistono anche sulle istanze non-Nitro, ma non sono dichiarati: l'unico modo per scoprirli è testare a quante connessioni la propria istanza inizia a rifiutarne di nuove.
Su un'istanza Nitro, il numero massimo di connessioni tracciate si ottiene con il comando seguente:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep conntrack_allowance_available
conntrack_allowance_available: 136813
[root@ip-172-31-92-221 ~]#
L'unico motivo per cui questo limite esiste è dovuto ai security group. I security group sono stateful, ovvero tracciano le connessioni tramite conntrack per consentire alle risposte del traffico in ingresso di uscire dall'istanza a prescindere dalle regole di security group in uscita, e viceversa.
Detto ciò, esiste un modo per aggirare questo limite senza aumentare la dimensione dell'istanza: semplicemente non usando i security group.
Quando un security group ha regole in ingresso e in uscita che consentono tutto il traffico, quei flussi vengono marcati come NOTRACK e non vengono tracciati da AWS, quindi non concorrono all'allowance di conntrack. [7]
In alternativa, si possono usare network ACL stateless, oppure direttamente regole iptables, che possono essere stateless o stateful: in quest'ultimo caso si avrebbe il controllo del conntrack di Linux dal lato istanza e si potrebbero aumentare i limiti come necessario.
L'unica eccezione a questo workaround è che le connessioni verso alcuni servizi AWS specifici, elencati di seguito, vengono sempre tracciate automaticamente, indipendentemente dalla configurazione del security group, perché ciò è necessario per garantire il routing simmetrico. In quei casi, l'unico workaround è aumentare la dimensione dell'istanza. [7]
- Egress-only internet gateway
- Gateway Load Balancer
- Global Accelerator accelerator
- NAT gateway
- Network Firewall firewall endpoint
- Network Load Balancer
- AWS PrivateLink (interface VPC endpoint)
- Transit gateway attachment
- AWS Lambda (Hyperplane elastic network interface)
Troubleshooting del throttling verso i Local Proxy Services
AWS mette a disposizione alcuni servizi come proxy locali all'interno di EC2: l'AWS DNS Resolver (il secondo IP della propria subnet VPC, oppure 169.254.169.253 in qualunque istanza EC2), il server NTP fornito da AWS (169.254.169.123) e l'Instance Metadata Service (169.254.169.254).
Questi servizi condividono un hard limit di 1024 pps (pacchetti al secondo) per interfaccia ENI. Oltre quella soglia, l'interfaccia viene sottoposta a throttling per linklocal_allowance_exceeded.
Di solito il throttling in questi casi nasce da un uso eccessivo dell'Instance Metadata Service. Mettere una query IMDS dentro una funzione ricorsiva richiamata di frequente, ad esempio, può facilmente portare al limite. È bene ricordare che il limite è in pacchetti al secondo e che una richiesta HTTP IMDS richiede più pacchetti di rete per essere completata: il limite, quindi, non equivale a 1024 query al secondo.
Un uso oculato di IMDS, con caching dei risultati ove possibile, è la strada giusta, dato che si tratta di un hard limit non modificabile, indipendentemente dalla taglia dell'istanza.
Un altro caso comune di throttling sono numerose query DNS; in questo caso la soluzione è implementare una cache DNS locale.
Quando il contatore ENA linklocal_allowance_exceeded cresce, è possibile individuare quale di questi servizi sta causando il throttling effettuando una packet capture del traffico verso gli IP di tali servizi e isolando se il traffico è DNS, HTTP o NTP.
Troubleshooting del Packet Throttling
Un'altra forma di throttling in AWS è quella legata al numero di pacchetti al secondo, ed è qui che le cose si complicano un po', perché la documentazione su questi limiti è davvero scarsa.
Anche se un'istanza EC2 è al di sotto del limite massimo di bandwidth, il suo traffico di rete può comunque essere soggetto a throttling per aver superato il numero massimo di pacchetti al secondo consentito per quell'istanza. Il limite qui è per istanza, e non per ENI come accade in linklocal_allowance_exceeded.
AWS, però, non rivela il numero massimo di pacchetti al secondo consentito per nessun tipo di istanza EC2 senza un NDA, e tale limite non è nemmeno fisso, perché può variare in base al tipo di pacchetti che compongono il traffico.
I limiti PPS per un'istanza EC2 variano in base a: [8]
- traffico TCP o UDP;
- numero di flussi;
- dimensione dei pacchetti;
- connessioni nuove o esistenti (limite di TCP SYN);
- regole di security group applicate.
Tutto ciò rende quasi impossibile fissare con certezza un limite PPS, anche con test esaustivi, perché il limite reale dipende dal pattern effettivo del traffico di rete.
Ad esempio, un'applicazione che apre molte nuove connessioni colpirà con buona probabilità il limite di TCP SYN, raggiungendo il limite PPS molto prima di un'applicazione che si appoggia soprattutto a connessioni esistenti.
Esistono modi per stress testare l'istanza con pacchetti e ottenere una stima approssimativa dei limiti PPS; AWS ne descrive i passaggi in questo articolo [8], ma il metodo è molto meno affidabile rispetto a iperf per scoprire i limiti di bandwidth.
L'alternativa preferibile è eseguire stress test sull'applicazione effettivamente in produzione e monitorare le metriche ENA per il throttling PPS: in questo modo si tiene conto dei pattern di rete reali dell'applicazione.
Per fortuna questi limiti spesso non sono così bassi e i limiti di bandwidth si raggiungono prima. In ogni caso, il pattern di traffico ideale è quello di un'applicazione con traffico TCP che si appoggia per lo più a connessioni esistenti, con pacchetti di dimensioni maggiori, molti flussi diversi e security group che consentano tutto il traffico in ingresso e in uscita su quelle porte per evitare il tracking.
In caso di throttling, adattare il pattern di traffico per avvicinarlo a quello descritto sopra può aiutare; in alternativa, conviene aumentare la dimensione dell'istanza.