· Warum es wichtig ist, die Netzwerk-Limits von AWS zu verstehen
· Wie wird der Traffic geshaped?
· EC2-Placements und Ressourcen-Sharing
· Bandbreiten-Throttling analysieren
∘ CloudWatch-Netzwerkmetriken richtig lesen
· Connection-Tracking-Throttling analysieren
· Throttling der lokalen Proxy-Services analysieren
· Packet-Throttling analysieren
· Quellen
Warum es wichtig ist, die Netzwerk-Limits von AWS zu verstehen
Im breiten AWS-Service-Portfolio bilden EC2-Instanzen und das EC2-Netzwerk das Fundament, auf dem die meisten anderen AWS-Dienste aufsetzen – und damit auch zahlreiche Anwendungen und Services, die für moderne digitale Infrastrukturen unverzichtbar sind. Wer die Performance dieser Instanzen verstehen will, kommt jedoch nicht um die Feinheiten des AWS-Netzwerks herum – allen voran das Network Throttling. Es tritt in unterschiedlichen Formen auf und wirkt sich direkt auf Performance und Skalierbarkeit von EC2-Instanzen aus – und damit auf zahlreiche weitere Services im AWS-Ökosystem.
AWS setzt Network Throttling über zwei zentrale Mechanismen um: Bandbreiten-Limits und Beschränkungen der Pakete pro Sekunde (PPS). Bandbreiten-Throttling begrenzt die Datenmenge, die in einem bestimmten Zeitraum übertragen werden kann; PPS-Throttling limitiert die Anzahl der Netzwerkpakete, die gesendet oder empfangen werden dürfen. Diese Beschränkungen sind bewusst so ausgelegt, dass Stabilität und Effizienz der gesamten AWS-Infrastruktur gewahrt bleiben. Gleichzeitig können sie zur echten Hürde werden, sobald es darum geht, Anwendungs-Performance und Ressourcennutzung zu optimieren.
Erschwerend kommt hinzu, dass es zu einigen Aspekten des AWS Network Throttling kaum offizielle Dokumentation gibt. Informationen darüber, wie und wann AWS diese Mechanismen genau anwendet, sind schwer zu finden. Engineers müssen sich daher durch ein Dickicht aus Foren, Erfahrungsberichten und eigenem Trial-and-Error arbeiten, um die Auswirkungen auf ihre Services zu verstehen und abzufedern. Diese fehlende klare und zugängliche Dokumentation macht das Management und die Optimierung der Netzwerk-Performance im AWS-Ökosystem zusätzlich komplex.
In diesem Artikel fügen wir die verstreuten Puzzleteile rund um AWS Network Throttling zusammen und zeichnen ein klares, vollständiges Bild davon, wie AWS Throttling-Mechanismen für das EC2-Netzwerk umsetzt.
Welche Limits gibt es?
Auf modernen, auf Nitro basierenden EC2-Instanz-Generationen stellt AWS mehrere Metriken bereit, die als Zähler für die durch Network Throttling geshapten Pakete dienen. Sie sind in der offiziellen Dokumentation [1] aufgeführt.
- bw_in_allowance_exceeded: Anzahl der Pakete, die in die Warteschlange gestellt oder verworfen wurden, weil die aggregierte Eingangsbandbreite das Maximum für diesen Instanztyp bzw. diese Größe überschritten hat.
- bw_out_allowance_exceeded: Anzahl der Pakete, die in die Warteschlange gestellt oder verworfen wurden, weil die aggregierte Ausgangsbandbreite das Maximum für diesen Instanztyp bzw. diese Größe überschritten hat.
- conntrack_allowance_exceeded: Anzahl der verworfenen Pakete, weil das Connection Tracking das Maximum für die Instanz überschritten hat und keine neuen Verbindungen mehr aufgebaut werden konnten. Das kann zu Paketverlust beim ein- und ausgehenden Traffic der Instanz führen.
- conntrack_allowance_available: Anzahl der getrackten Verbindungen, die die Instanz noch aufbauen kann, bevor das Connections-Tracked-Limit dieses Instanztyps erreicht wird.
- linklocal_allowance_exceeded: Anzahl der verworfenen Pakete, weil die PPS des Traffics zu lokalen Proxy-Services das Maximum der Netzwerkschnittstelle überschritten hat. Betroffen sind der DNS-Service, der Instance Metadata Service und der Amazon Time Sync Service.
- pps_allowance_exceeded: Anzahl der Pakete, die in die Warteschlange gestellt oder verworfen wurden, weil die bidirektionalen PPS das Maximum für die Instanz überschritten haben.
Diese Metriken werden zwar nur auf Nitro-basierten Instanzen über den ENA-Treiber ausgegeben, die Limits gelten aber nicht ausschließlich für Nitro-Instanzen. Auch nicht-Nitro-Instanzen, die in Xen virtualisiert werden, unterliegen Netzwerk-Limits – oft sogar niedrigeren als bei Nitro-Instanzen. Es ist allerdings nachvollziehbar, dass AWS diese spezifischen Metriken nur über den eigenen ENA-Treiber bereitstellen kann.
Die Zähler lassen sich von der Instanz aus mit folgendem Befehl auslesen:
[root@ip-172-31-82-248 ~]# ethtool -S eth0 | grep allowance
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
conntrack_allowance_available: 136812
Wie wird der Traffic geshaped?
Die Formulierung in der AWS-Dokumentation, wie der Traffic beim Erreichen eines Limits geshaped wird, ist hier entscheidend: Pakete werden in die Warteschlange gestellt oder verworfen. Wie lange diese Pakete in der Warteschlange verbleiben, bleibt offen.
Ob das Throttling als Queueing oder als Drop angewandt wurde, lässt sich nicht direkt feststellen. Tests zeigen aber: Wird der Netzwerk-Traffic nur leicht über die Limits gedrückt, beschränkt sich das Shaping meist auf Queueing – und das in der Regel nur für wenige Millisekunden, sodass kaum oder gar keine Auswirkungen spürbar sind.
Pakete werden offenbar erst dann verworfen, wenn die Limits deutlich überschritten werden. Selbst dann erholen sich TCP-basierte Anwendungen meist problemlos, sofern der Drop überschaubar bleibt – schlicht durch Re-Transmission der verlorenen Pakete.
Wichtig zu wissen: Die ENA-Metriken zum Network Throttling sind Paketzähler seit dem letzten ENA-Reset – also eine Summe aller geshapten Pakete.
Ein Zähler ungleich Null bedeutet daher nicht zwangsläufig ein aktives Problem – die Werte können veraltet sein. Für mehr Transparenz lassen sich diese Zähler über den CloudWatch Agent [2] als CloudWatch-Metrik exportieren. So können Sie den Verlauf über die Zeit nachvollziehen und erkennen, ob der Zähler weiter steigt – und um wie viele Pakete pro Sekunde.
EC2-Placements und Ressourcen-Sharing
EC2-Instanzen sind virtuelle Maschinen – und eine virtuelle Maschine ist im Grunde eine weitere Abstraktionsschicht über der physischen Hardware, die sich mehrere Tenants teilen.
Als grobe Faustregel gilt: Je größer eine EC2-Instanz innerhalb ihrer Familie, desto weniger teilt sie sich die Hardware mit anderen Tenants – bis sie schließlich die einzige virtuelle Maschine auf dieser Hardware ist (oder eine echte Bare-Metal-Instanz).
Eine c5.24xlarge – die größte Größe dieser Familie – hat also mit hoher Wahrscheinlichkeit den gesamten zugrundeliegenden Host für sich allein. Sie teilt ihre Netzwerk-Limits mit niemandem und kann die volle Kapazität der Hardware sowie deutlich höhere Netzwerk-Limits nutzen als kleinere Instanzgrößen.
Eine c5.large dagegen – die kleinste Größe der Familie – teilt sich den Host sehr wahrscheinlich mit mehreren Tenants. Sie verfügt also nur über 1/x der Hardware-Kapazität, wobei x der maximalen Anzahl an Tenants auf dieser Hardware entspricht.
Wir haben zwar keinen Einblick darin, wie diese Placements im Backend funktionieren, aber als Faustregel gilt: Je größer die Instanz, desto höher die Netzwerk-Limits.
Beim ausgehenden Traffic können zudem Beschränkungen außerhalb des Hypervisors greifen – etwa durch Switches und Router weiter oben im Netzwerk-Stack.
In den AWS-eigenen Netzwerk-Stack für EC2 haben wir keinen Einblick, doch ein typischer Datacenter-Netzwerk-Stack sieht in etwa so aus:
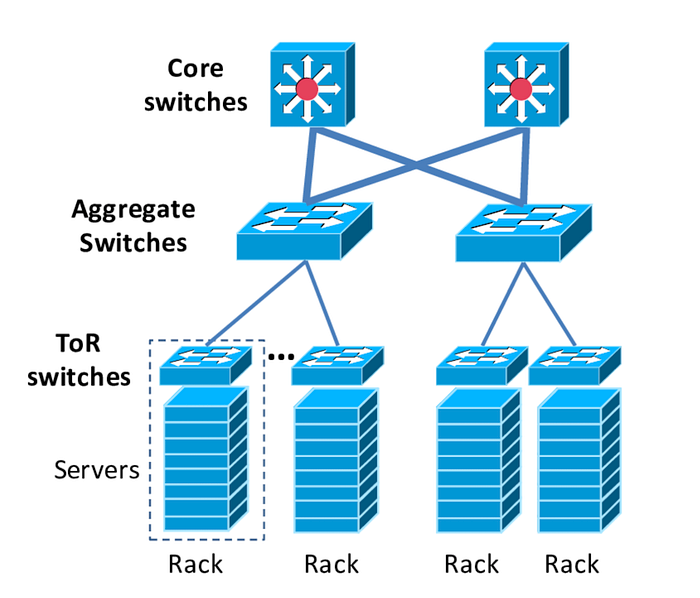
AWS erlaubt uns aber, Placement-Strategien [3] zu definieren, die regeln, wie nah Instanzen physisch beieinander platziert werden. Das beeinflusst nicht nur die Latenz, sondern auch die verfügbare Bandbreite pro Flow im Rahmen der Flow-Limits.
Eine Cluster Placement Group sorgt dafür, dass Instanzen so nah wie möglich beieinander liegen – etwa auf demselben Host, am selben ToR-Switch, am selben Aggregate-Switch usw. Diese Strategie liefert die geringstmögliche Latenz zwischen den Instanzen und die höchstmöglichen Bandbreiten-Limits pro Flow.
Ohne explizite Placement-Strategie verteilt AWS Instanzen abhängig von der Kapazität zufällig. Mit etwas Glück landen sie dann am selben ToR- oder Aggregate-Switch – manchmal aber eben auch nicht.
Bei jedem Stop und Start einer EC2-Instanz wird sie irgendwo neu in der AWS-Infrastruktur platziert [4]. Das heißt: Sie kann in-placement (nahe an Ihren anderen Instanzen) oder out-of-placement (weit entfernt) landen – und das wirkt sich direkt auf Latenz und maximalen Durchsatz pro Flow aus.
Genau aus diesem Grund habe ich schon Fälle gesehen, in denen zwei EC2-Instanzen mit latenzkritischen Anwendungen und hohem Durchsatz pro Flow rein zufällig in-placement waren. Nach einem Stop/Start landeten sie out-of-placement – und plötzlich tauchten Netzwerkprobleme auf, weil der maximale Durchsatz pro Flow sank und die Latenz stieg.
Es lohnt sich also, die Anforderungen der eigenen Anwendung zu kennen und schon im Vorfeld eine Placement-Strategie für die AWS-Infrastruktur festzulegen.
Cluster-Placement ist allerdings nicht die einzig sinnvolle Strategie. Denn je näher die Instanzen beieinander platziert sind, desto höher ist auch die Wahrscheinlichkeit, dass alle gleichzeitig von Hardware-Ausfällen betroffen sind. Laufen alle Instanzen auf demselben Host und dieser fällt aus, sind sie auf einen Schlag weg.
Alternativ bietet AWS auch eine Spread Placement Group an, die genau das Gegenteil bewirkt: Sie platziert Ihre Instanzen physisch so weit wie möglich auseinander.
Bandbreiten-Throttling analysieren
Bandbreiten-Throttling ist zwar das offensichtlichste Netzwerk-Limit, das AWS verhängt – ein paar Stolperfallen gibt es trotzdem.
Zunächst muss man die tatsächliche Bandbreitenkapazität jedes Instanztyps kennen. AWS arbeitet hier mit zwei verschiedenen Limits: der Baseline-Bandbreite und der Burst-Obergrenze.
Steht in der Dokumentation "Up to" vor einem Wert, ist damit die Burst-Obergrenze gemeint – Sie können diese Bandbreite zwar erreichen, aber nur für einen begrenzten Zeitraum, bis die Burst-Credits aufgebraucht sind. Je größer die Instanz, desto weniger teilt sie sich die zugrundeliegende Hardware und desto länger kann sie bursten.
Sind die Burst-Credits aufgebraucht, fällt das Limit auf die Baseline-Bandbreite zurück (deutlich niedriger als das Burst-Limit), und das Network Throttling setzt ein.
Bei Instanzgrößen, für die AWS einen Wert wie "25 Gigabit" ohne den Zusatz "Up to" angibt, handelt es sich um die Baseline – eine Burst-Obergrenze gibt es in dem Fall nicht.
Für einige Instanztypen veröffentlicht AWS sowohl die Baseline- als auch die Burst-Bandbreite in der Dokumentation [5], allerdings nur für wenige Familien.
Wie lange Sie auf Burst-fähigen Instanzen tatsächlich bursten können, gibt AWS nirgends bekannt. Mit etwas Testaufwand lässt sich das aber relativ einfach herausfinden.
Starten wir auf meinem AWS-Account eine c5.large und eine c5.24xlarge, lassen sich die Limits einer c5.large beispielsweise mit iperf3 ermitteln.
[root@ip-172-31-82-248 ~]# iperf3 -c 172.31.23.48 -i 60 -t 480 -P 5
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.82.248 port 42202 connected to 172.31.23.48 port 5201
[ 7] local 172.31.82.248 port 42204 connected to 172.31.23.48 port 5201
[ 9] local 172.31.82.248 port 42208 connected to 172.31.23.48 port 5201
[ 11] local 172.31.82.248 port 42212 connected to 172.31.23.48 port 5201
[ 13] local 172.31.82.248 port 42218 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-60.05 sec 11.4 GBytes 1.64 Gbits/sec 19684 376 KBytes
[ 7] 0.00-60.05 sec 11.2 GBytes 1.60 Gbits/sec 17814 341 KBytes
[ 9] 0.00-60.05 sec 11.5 GBytes 1.65 Gbits/sec 18713 428 KBytes
[ 11] 0.00-60.05 sec 16.8 GBytes 2.40 Gbits/sec 24552 507 KBytes
[ 13] 0.00-60.05 sec 17.0 GBytes 2.44 Gbits/sec 22710 524 KBytes
[SUM] 0.00-60.05 sec 68.0 GBytes 9.72 Gbits/sec 103473
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 19955 341 KBytes
[ 7] 60.05-120.05 sec 11.3 GBytes 1.62 Gbits/sec 18304 428 KBytes
[ 9] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 18976 428 KBytes
[ 11] 60.05-120.05 sec 16.8 GBytes 2.41 Gbits/sec 25220 498 KBytes
[ 13] 60.05-120.05 sec 16.9 GBytes 2.42 Gbits/sec 23265 481 KBytes
[SUM] 60.05-120.05 sec 67.9 GBytes 9.72 Gbits/sec 105720
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 120.05-180.05 sec 11.5 GBytes 1.65 Gbits/sec 19194 454 KBytes
[ 7] 120.05-180.05 sec 11.1 GBytes 1.59 Gbits/sec 18328 454 KBytes
[ 9] 120.05-180.05 sec 11.5 GBytes 1.64 Gbits/sec 19259 358 KBytes
[ 11] 120.05-180.05 sec 16.7 GBytes 2.39 Gbits/sec 24946 542 KBytes
[ 13] 120.05-180.05 sec 17.1 GBytes 2.45 Gbits/sec 23032 323 KBytes
[SUM] 120.05-180.05 sec 67.9 GBytes 9.72 Gbits/sec 104759
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 180.05-240.05 sec 11.5 GBytes 1.65 Gbits/sec 20069 446 KBytes
[ 7] 180.05-240.05 sec 11.2 GBytes 1.60 Gbits/sec 17967 463 KBytes
[ 9] 180.05-240.05 sec 11.4 GBytes 1.64 Gbits/sec 18942 323 KBytes
[ 11] 180.05-240.05 sec 16.7 GBytes 2.39 Gbits/sec 24645 498 KBytes
[ 13] 180.05-240.05 sec 17.0 GBytes 2.44 Gbits/sec 22380 507 KBytes
[SUM] 180.05-240.05 sec 67.9 GBytes 9.72 Gbits/sec 104003
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 13304 323 KBytes
[ 7] 240.05-300.05 sec 7.85 GBytes 1.12 Gbits/sec 12274 498 KBytes
[ 9] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 12763 350 KBytes
[ 11] 240.05-300.05 sec 11.5 GBytes 1.65 Gbits/sec 16480 454 KBytes
[ 13] 240.05-300.05 sec 11.9 GBytes 1.71 Gbits/sec 15472 647 KBytes
[SUM] 240.05-300.05 sec 47.1 GBytes 6.74 Gbits/sec 70293
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 300.05-360.05 sec 879 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 300.05-360.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 360.05-420.05 sec 881 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 360.05-420.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 420.05-480.05 sec 782 MBytes 109 Mbits/sec 0 323 KBytes
[ 7] 420.05-480.05 sec 933 MBytes 130 Mbits/sec 0 498 KBytes
[ 9] 420.05-480.05 sec 932 MBytes 130 Mbits/sec 0 350 KBytes
[ 11] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 454 KBytes
[ 13] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 647 KBytes
[SUM] 420.05-480.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
Hier verbindet sich iperf3 von meiner c5.large mit der größeren c5.24xlarge (damit die Limits der c5.large als Erstes greifen und wir den Begrenzer sehen), mit Reports im 60-Sekunden-Takt (-i 60), einer Laufzeit von 8 Minuten (-t 480) und 5 parallelen Streams (-P 5).
Im Output sehen wir, dass die Bitrate in den ersten 5 Minuten bei rund 10 Gbps liegt – also genau bei dem Wert, den AWS für c5.large als "Up to" angibt. Doch nach 5 Minuten fällt die Bitrate auf nur noch 750 Mbps.
Damit haben wir zwei undokumentierte Limits für c5.large-Instanzen ermittelt:
- 750 Mbps Baseline-Bandbreite
- 5-Minuten-Burst-Limit von bis zu 10 Gbps
Jetzt wissen wir: c5.large-Instanzen haben eine Baseline-Bandbreite von 750 Mbps und können für maximal 5 Minuten auf bis zu 10 Gbps bursten.
Wir sehen außerdem, dass parallel zum einsetzenden Network Throttling auch die ENA-Zähler für das Outbound-Bandbreiten-Shaping angestiegen sind:
[root@ip-172-31-82-248 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 42427304
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
[root@ip-172-31-82-248 ~]#
Internet-Egress-Bandbreite
EC2-Instanzen erreichen ihr Bandbreiten-Maximum nur dann, wenn Quelle und Ziel des Traffics innerhalb von AWS und in derselben Region liegen. Sobald Quelle oder Ziel außerhalb der Region liegen – sei es in einer anderen AWS-Region oder im Internet – sieht die Sache anders aus.
In diesen Fällen liegt das Bandbreiten-Limit zu anderen Regionen oder zum Internet bei 50 % der Netzwerkbandbreite – vorausgesetzt, die Instanz hat mindestens 32 vCPUs. [6]
Hat die Instanz weniger als 32 vCPUs, ist das Limit fix bei maximal 5 Gbps. [6]
Flow-Limits
Ein weiteres, weniger offensichtliches Bandbreiten-Limit: AWS begrenzt die Bandbreite pro Flow. Der maximale Durchsatz pro Flow liegt bei 5 Gbps – unabhängig von Instanzfamilie oder -größe. Das ist ein hartes Limit. [6]
Es gibt nur zwei Wege, dieses Limit zu erhöhen. Der erste: Quell- und Zielinstanz liegen im selben EC2-Placement. Das erreichen Sie entweder, indem Sie die Instanzen in derselben Cluster Placement Group platzieren – oder durch reines Glück, wenn sie zufällig an denselben Aggregate-Switches landen, wie im Abschnitt zu EC2-Placements bereits erläutert.
Liegen Quelle und Ziel im selben EC2-Placement, beträgt die maximale Bandbreite pro Flow 10 Gbps. [6]
Der zweite Weg: ENA Express auf entsprechend geeigneten Instanzen im selben Subnetz nutzen. Hier liegt das Limit bei 25 Gbps pro Flow zwischen diesen Instanzen. [6]
Alternativ sollten Sie nach Möglichkeit auf Multi-Flow-Traffic setzen, um maximale Bandbreitenkapazität und Performance zu erzielen – das wirkt sich auch positiv auf die PPS-Limiter aus, auf die wir später noch eingehen.
Wichtig zu wissen: Throttling aufgrund von Flow-Limits taucht in keiner der ENA-Throttling-Metriken auf.
Auch das lässt sich mit iperf3 leicht zeigen. Wenn ich einen einzelnen Stream von meiner c5.large (die eigentlich 10 Gbps schaffen sollte) zu meiner c5.24xlarge laufen lasse – out-of-placement – wird der maximale Durchsatz im Single-Flow auf 5 Gbps gedeckelt:
[root@ip-172-31-92-221 ~]# iperf3 -c 172.31.23.48 -t 60 -P 1
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.92.221 port 42472 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 594 MBytes 4.98 Gbits/sec 0 1.43 MBytes
[ 5] 1.00-2.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
[ 5] 2.00-3.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
In den ENA-Throttling-Metriken hat sich aber kein Zähler erhöht:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Das ist besonders kritisch: Network Throttling durch Flow-Limits passiert lautlos und ist im laufenden Betrieb extrem schwer zu erkennen.
Micro-Bursting
Ein weiterer Aspekt beim Bandbreiten-Throttling ist Micro-Bursting. Dabei werden die Bandbreiten-Limits nur sehr kurz gerissen – was sich oft kaum erkennen lässt.
Ein typisches Szenario: Die ENA-Throttling-Metriken steigen sehr langsam an, aber in den CloudWatch-Metriken zum Netzwerk-Traffic ist nie zu sehen, dass Sie Ihre Bandbreitenobergrenze erreichen.
AWS-Throttling greift in unglaublich kurzen Intervallen, und obwohl wir keinen Einblick haben, wie schnell genau, kenne ich Fälle, in denen sich Micro-Bursting nur über Sub-Sekunden-Messungen erkennen ließ.
CloudWatch hingegen liefert standardmäßig Datenpunkte in 5-Minuten-Intervallen – mit Enhanced Monitoring lässt sich das auf 1-Minuten-Intervalle reduzieren.
Manchmal ist der Burst aber so kurz, dass er sich in den 5-Minuten-Intervallen von CloudWatch verflüchtigt und einfach nicht sichtbar wird.
Die einfachste Lösung: den ENA-Zählern von AWS vertrauen, auch wenn Sie die Traffic-Spitzen nicht erkennen können. Mit dem CloudWatch Agent können Sie Datenpunkte mit Intervallen von bis zu 1 Sekunde erfassen – damit lassen sich die meisten Bandbreitenspitzen einfangen.
Darüber hinaus bleibt nur, die Traffic-Menge in den ENA RX/TX-Queues mit der Menge des gemeldeten Shapings zu vergleichen.
In den meisten Micro-Bursting-Szenarien gilt aber ohnehin: Das Shaping ist nicht stark genug, um sich darüber Sorgen zu machen, da es überwiegend aus Queueing besteht. Bei TCP-basierten Anwendungen werden kleinere Verluste zudem mühelos kompensiert.
CloudWatch-Netzwerkmetriken richtig lesen
Ein weiterer häufiger Fehler ist das Missverstehen der CloudWatch-Netzwerkmetriken. Während alle AWS-Netzwerk-Limits in Bits pro Sekunde angegeben sind, liefern die CloudWatch-Netzwerkmetriken Bytes über einen Zeitraum. Genau deshalb ist es so schwierig, allein aus den Metriken NetworkIn und NetworkOut abzulesen, wie nah Sie an Ihrer Bandbreitenobergrenze sind.
Auf meiner Beispielinstanz c5.24xlarge sieht NetworkIn zum Beispiel so aus:
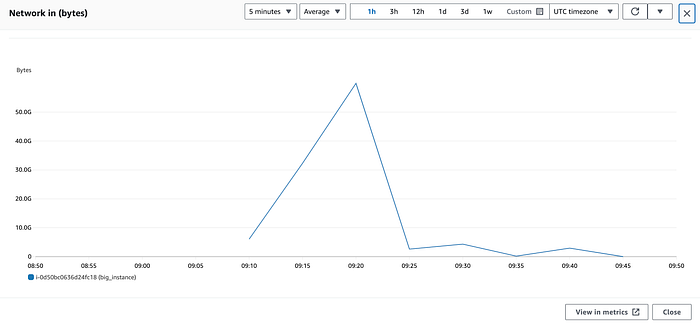
Hier könnte man leicht zu dem Schluss kommen, dass die Instanz um 09:20 Uhr über 50 Gbps Inbound-Traffic erreicht hat – das ist aber falsch.
Um den tatsächlichen Netzwerk-Traffic in bps zu ermitteln, müssen wir die Statistik auf Sum umstellen und durch die Periode in Sekunden teilen (standardmäßig 5 Minuten), um den durchschnittlichen Traffic pro Sekunde in diesem Intervall zu erhalten.
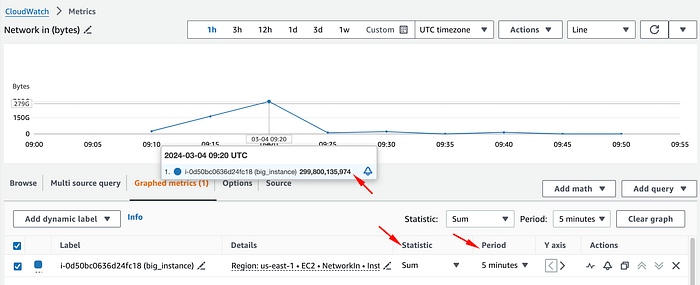
In diesem Fall teilen wir die Bytes des Datenpunkts (299800135974) durch 300 Sekunden (5 Minuten) und erhalten 999333786,58 Bytes pro Sekunde.
Anschließend müssen wir Bytes in Bits umrechnen. Zur Vereinfachung können wir direkt nach Mbps konvertieren, indem wir mit 0,000008 multiplizieren – denn 1 Byte pro Sekunde entspricht 0,000008 Mbps.
Nach der Umrechnung sehen wir: Diese Metrik zeigt einen durchschnittlichen Inbound-Traffic von 7994 Mbps über die 5 Minuten – meilenweit entfernt vom ersten Eindruck mit 50 Gbps.
Für den gesamten Netzwerk-Traffic in diesem Zeitraum müssten wir NetworkOut ebenfalls umrechnen und beide Werte addieren.
Connection-Tracking-Throttling analysieren
Neben den Bandbreiten-Limits begrenzt AWS auch die Anzahl der getrackten Verbindungen. Ist dieses Limit erreicht, lehnt AWS neue Verbindungen ab.
Das kann richtig wehtun: Sobald das Limit erreicht ist, weist AWS jede neue Verbindung zu Ihrer EC2-Instanz ab – bis die Anzahl der Verbindungen wieder unter das Maximum fällt.
Bis vor Kurzem hat AWS dazu nichts veröffentlicht – in der Dokumentation wurden diese Limits nicht erwähnt. Inzwischen gibt AWS die maximale Anzahl getrackter Verbindungen pro EC2-Instanztyp an, allerdings nur für moderne, auf Nitro basierende Generationen.
Diese Limits gelten zwar auch für nicht-Nitro-Instanzen, sind dort aber nicht dokumentiert. Den Wert kann man nur durch Tests herausfinden – nämlich, ab welcher Verbindungszahl die Instanz neue Verbindungen abweist.
Die maximale Anzahl getrackter Verbindungen einer Nitro-Instanz lässt sich mit folgendem Befehl auslesen:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep conntrack_allowance_available
conntrack_allowance_available: 136813
[root@ip-172-31-92-221 ~]#
Der einzige Grund, warum es dieses Limit überhaupt gibt, sind Security Groups. Sie sind stateful – das heißt, sie tracken Verbindungen über conntrack, damit Antworten auf eingehenden Traffic die Instanz unabhängig von Outbound-Regeln verlassen können (und umgekehrt).
Es gibt allerdings einen Trick: Sie können dieses Limit umgehen, ohne die Instanz zu vergrößern – indem Sie schlicht keine Security Groups verwenden.
Enthält eine Security Group Inbound- und Outbound-Regeln, die jeglichen Traffic erlauben, werden die entsprechenden Flows als NOTRACK markiert und nicht von AWS getrackt. Sie zählen damit nicht gegen das conntrack-Limit. [7]
Alternativ können Sie stateless Network ACLs einsetzen oder direkt iptables-Regeln nutzen – entweder stateless oder stateful. Im letzteren Fall haben Sie über conntrack auf Linux-Ebene die volle Kontrolle und können die Limits nach Bedarf erhöhen.
Die einzige Ausnahme dieses Workarounds: Verbindungen zu bestimmten AWS-Services (siehe Liste unten) werden immer automatisch getrackt – unabhängig von der Security-Group-Konfiguration. Das ist nötig, um symmetrisches Routing sicherzustellen. Hier hilft nur eine größere Instanz. [7]
- Egress-only Internet Gateways
- Gateway Load Balancers
- Global Accelerator Accelerators
- NAT Gateways
- Network Firewall Firewall Endpoints
- Network Load Balancers
- AWS PrivateLink (Interface VPC Endpoints)
- Transit Gateway Attachments
- AWS Lambda (Hyperplane Elastic Network Interfaces)
Throttling der lokalen Proxy-Services analysieren
AWS bietet innerhalb von EC2 mehrere Services als lokale Proxies an: den AWS DNS Resolver (entweder die zweite IP Ihres VPC-Subnetzes oder 169.254.169.253 in jeder EC2-Instanz), den AWS-NTP-Server (169.254.169.123) und den Instance Metadata Service (169.254.169.254).
Diese Services teilen sich ein hartes Limit von 1024 PPS (Pakete pro Sekunde) pro ENI-Interface. Wird das überschritten, throttelt AWS die Schnittstelle wegen linklocal_allowance_exceeded.
In der Praxis ist meist die übermäßige Nutzung des Instance Metadata Service die Ursache. Wer eine IMDS-Abfrage in einer häufig verwendeten rekursiven Funktion platziert, läuft schnell in dieses Limit. Wichtig: Das Limit gilt in Paketen pro Sekunde – und ein HTTP-IMDS-Request umfasst mehrere Netzwerkpakete. 1024 PPS sind also nicht gleichbedeutend mit 1024 Anfragen pro Sekunde.
Bewusster Umgang mit IMDS und das Cachen von Ergebnissen, wo immer möglich, sind die richtigen Hebel – denn dieses Limit ist hart und lässt sich unabhängig von der Instanzgröße nicht erhöhen.
Ein weiterer typischer Auslöser sind viele DNS-Abfragen – die Lösung dafür: ein lokaler DNS-Cache.
Steigt der ENA-Zähler linklocal_allowance_exceeded, lässt sich der Verursacher mit einem Packet Capture des Traffics zu diesen Service-IPs eingrenzen – je nachdem, ob es sich um DNS-, HTTP- oder NTP-Traffic handelt.
Packet-Throttling analysieren
Eine weitere Throttling-Form bei AWS basiert auf der Anzahl der Pakete pro Sekunde – und genau hier wird es etwas komplexer, weil die Dokumentation zu diesen Limits sehr dünn ist.
Selbst wenn eine EC2-Instanz unterhalb des maximalen Bandbreitenlimits liegt, kann ihr Netzwerk-Traffic gethrottelt werden, weil sie das maximal zulässige PPS-Limit für diesen Instanztyp erreicht. Das Limit gilt pro Instanz – nicht pro ENI wie bei linklocal_allowance_exceeded.
AWS gibt das maximale PPS-Limit für EC2-Instanztypen jedoch ohne NDA nicht heraus – und es ist auch nicht fix, sondern hängt davon ab, aus welchen Pakettypen der Traffic besteht.
Die PPS-Limits einer EC2-Instanz hängen ab von: [8]
- TCP oder UDP
- Anzahl der Flows
- Paketgröße
- Neuen oder bestehenden Verbindungen (TCP-SYN-Limit)
- Den angewandten Security-Group-Regeln
Damit lässt sich ein festes PPS-Limit praktisch nicht verlässlich bestimmen – selbst mit umfassenden Tests, weil das tatsächliche Limit vom konkreten Traffic-Muster abhängt.
Eine Anwendung, die viele neue Verbindungen aufbaut, läuft etwa schneller in das TCP-SYN-Limit – und damit in das PPS-Limit – als eine Anwendung, die überwiegend bestehende Verbindungen nutzt.
Es gibt zwar Wege, die Instanz mit Paketen zu stresstesten und so eine grobe Schätzung der PPS-Limits zu ermitteln – AWS beschreibt das Vorgehen in diesem Artikel [8] –, aber dieser Ansatz ist deutlich weniger zuverlässig als ein iperf-basierter Bandbreitentest.
Besser ist es, Stresstests gegen die tatsächlich gehostete Anwendung zu fahren und dabei die ENA-Metriken zum PPS-Throttling zu beobachten – denn so fließt das echte Netzwerkverhalten der Anwendung in die Messung ein.
Erfreulicherweise sind diese Limits oft nicht sehr niedrig, und meist greifen die Bandbreiten-Limits zuerst. Trotzdem sind die idealen Traffic-Muster: TCP-Traffic, der überwiegend bestehende Verbindungen nutzt, größere Paketgrößen, viele unterschiedliche Flows und Security Groups, die jeglichen Inbound- und Outbound-Traffic auf den entsprechenden Ports erlauben – damit kein Tracking stattfindet.
Tritt dennoch Throttling auf, hilft eine Anpassung der Traffic-Muster in Richtung des oben genannten Profils – alternativ bleibt nur das Hochstufen der Instanzgröße.