· Por que entender as limitações de rede da AWS é importante
· Placement de EC2 e compartilhamento de recursos
· Como investigar throttling de banda
∘ Banda de saída para a Internet
∘ Como ler as métricas de rede do CloudWatch
· Como investigar throttling de Connection Tracking
· Como investigar throttling para os Local Proxy Services
· Como investigar throttling de pacotes
Por que entender as limitações de rede da AWS é importante
No vasto universo dos serviços da AWS, as instâncias EC2 e a rede do EC2 são os blocos fundamentais sobre os quais a maior parte dos demais serviços é construída, sustentando uma série de aplicações e serviços críticos para a infraestrutura digital de hoje. Só que, para entender o desempenho dessas instâncias, é preciso mergulhar nas particularidades da rede da AWS — em especial, no throttling de rede. Esse throttling, que aparece de várias formas, impacta diretamente o desempenho e a escalabilidade das instâncias EC2 e, por consequência, de muitos outros serviços do ecossistema AWS.
A AWS aplica throttling de rede por meio de dois mecanismos principais: limites de banda e restrições de pacotes por segundo (PPS). O throttling de banda afeta o volume de dados que pode trafegar pela rede em um determinado período, enquanto o de PPS limita a quantidade de pacotes que podem ser enviados ou recebidos. Essas restrições são pensadas com cuidado para preservar a saúde e a eficiência da infraestrutura da AWS como um todo. Mesmo assim, podem trazer desafios consideráveis na hora de otimizar o desempenho das aplicações e o uso dos recursos.
Para piorar, falta documentação oficial sobre vários aspectos do throttling de rede na AWS. As informações específicas sobre como e quando a AWS aplica esses mecanismos são difíceis de achar, e os desenvolvedores acabam tendo que percorrer um labirinto de fóruns, relatos de outros usuários e investigações por tentativa e erro para entender e mitigar os impactos nos seus serviços. Essa falta de documentação clara e acessível adiciona uma camada extra de complexidade ao gerenciamento e à otimização do desempenho de rede dentro da AWS.
Neste artigo, vamos juntar as peças desse quebra-cabeça espalhado e montar um panorama claro e completo de como a AWS aplica os mecanismos de throttling na rede do EC2.
Quais são as limitações?
Nas gerações modernas de instâncias EC2 baseadas em Nitro, a AWS expõe algumas métricas como contadores de pacotes que sofrem throttling de rede, listadas na documentação oficial [1].
- bw_in_allowance_exceeded: número de pacotes enfileirados ou descartados porque a banda agregada de entrada ultrapassou o máximo desse tipo/tamanho de instância;
- bw_out_allowance_exceeded: número de pacotes enfileirados ou descartados porque a banda agregada de saída ultrapassou o máximo desse tipo/tamanho de instância;
- conntrack_allowance_exceeded: número de pacotes descartados porque o connection tracking ultrapassou o máximo da instância e novas conexões não puderam ser estabelecidas. Isso pode causar perda de pacotes no tráfego de ou para a instância.
- conntrack_allowance_available: número de conexões rastreadas que ainda podem ser estabelecidas pela instância antes de bater no limite de Connections Tracked daquele tipo de instância.
- linklocal_allowance_exceeded: número de pacotes descartados porque o PPS do tráfego para os local proxy services ultrapassou o máximo da interface de rede. Isso afeta o tráfego para o serviço de DNS, o Instance Metadata Service e o Amazon Time Sync Service.
- pps_allowance_exceeded: número de pacotes enfileirados ou descartados porque o PPS bidirecional ultrapassou o máximo da instância.
Apesar dessas métricas só serem expostas em instâncias baseadas em Nitro pelo driver ENA, as limitações não são exclusivas das instâncias Nitro. Instâncias não-Nitro, virtualizadas em Xen, também têm limitações de rede (muitas vezes mais baixas que as das próprias Nitro, inclusive); só que faz sentido a AWS conseguir expor essas métricas customizadas apenas no driver proprietário ENA.
Esses contadores podem ser consultados a partir da própria instância com o comando abaixo:
[root@ip-172-31-82-248 ~]# ethtool -S eth0 | grep allowance
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
conntrack_allowance_available: 136812
Como o tráfego é moldado?
A redação da documentação da AWS sobre como o tráfego é moldado quando um limite é atingido é importante, porque ela diz que os pacotes são enfileirados ou descartados. Só que não sabemos por quanto tempo esses pacotes ficam enfileirados.
Não dá para saber se o throttling foi aplicado via enfileiramento ou descarte, mas, pelos testes que fizemos, dá para afirmar que, quando o tráfego de rede passa só um pouquinho dos limites, a moldagem normalmente é só de enfileiramento — e, na maior parte das vezes, esse enfileiramento não passa de alguns milissegundos, com pouco ou nenhum impacto.
O descarte de pacotes parece ocorrer só quando os limites são forçados de forma agressiva e, mesmo nesses casos, quando o descarte é pequeno, aplicações baseadas em TCP costumam se recuperar tranquilamente, simplesmente retransmitindo os pacotes perdidos.
Outro ponto: as métricas do ENA sobre throttling de rede são contadores de pacotes desde o último reset do ENA, ou seja, são uma soma dos pacotes que foram moldados.
Encontrar um valor diferente de zero nesses contadores nem sempre é um problema, já que o dado pode estar antigo. Para visualizar isso melhor, dá para exportar essas métricas como métrica do CloudWatch via CloudWatch Agent [2], o que permite acompanhá-las ao longo do tempo e ver se o contador continua subindo, e em quantos pacotes por segundo.
Placement de EC2 e compartilhamento de recursos
Instâncias EC2 são máquinas virtuais; e uma máquina virtual é, no fundo, mais uma camada de abstração sobre o hardware físico, que é compartilhado entre múltiplos tenants.
Como regra geral, quanto maior o tamanho de uma instância EC2 dentro da sua família, menos ela compartilha o hardware com outros tenants, até chegar ao ponto de ser a única máquina virtual naquele hardware — ou de fato uma instância metal.
Ou seja, dá para supor que, por exemplo, uma c5.24xlarge — o maior tamanho dessa família — provavelmente tem o host físico inteiro só para ela, sem dividir os limites de rede com outros tenants. Isso significa que ela tem toda a capacidade do hardware à disposição e limites de rede bem maiores que os de tamanhos menores.
Já uma c5.large, que é o menor tamanho da família, muito provavelmente compartilha o host físico com vários tenants. Por isso, terá 1/x da capacidade do hardware, sendo x o número máximo de tenants daquele hardware.
Não temos visibilidade de como esses placements funcionam por trás dos panos, mas a noção geral é a de que, como regra, quanto maior a instância, maiores são os limites de rede.
Vale lembrar também que, para o tráfego que sai da instância, podem existir restrições ligadas à stack de rede fora do hypervisor, por causa dos switches e roteadores em camadas mais acima.
Não temos visibilidade da stack de rede da AWS para o EC2, mas a stack de rede de um datacenter típico se pareceria com algo assim:
A AWS, no entanto, permite que a gente defina placement strategies [3], que controlam o quão distantes as instâncias ficam umas das outras. Isso impacta não só a latência, mas também a banda por fluxo, em relação aos limites de fluxo.
Criar um Cluster Placement Group faz com que as instâncias fiquem o mais próximas possível umas das outras — por exemplo, no mesmo host físico, no mesmo switch ToR, no mesmo switch agregador, e por aí vai. Essa estratégia garante a menor latência possível entre as instâncias do placement group e os maiores limites de banda por fluxo.
Se você não definir nenhuma placement strategy, a AWS aloca as instâncias aleatoriamente, conforme a capacidade disponível. Por pura sorte, elas podem cair no mesmo switch ToR/agregador; outras vezes, não.
Toda vez que você para e inicia uma instância EC2, ela é realocada em um lugar diferente da infraestrutura da AWS [4], podendo acabar in-placement (perto da sua outra instância) ou out-of-placement (longe dela); e estar in ou out of placement afeta a latência e o throughput máximo por fluxo.
Por causa desse fenômeno, já vi casos em que duas instâncias EC2 que rodavam aplicações de baixa latência e alto throughput por fluxo estavam in-placement por pura sorte; só que, depois de um stop/start, acabaram out-of-placement e começaram a apresentar problemas de rede do nada, por causa da redução do throughput máximo por fluxo após a mudança e do aumento da latência.
Por isso, é importante levar em conta a natureza da sua aplicação e definir uma placement strategy de antemão para a sua infraestrutura na AWS.
Claro que cluster placement não é a única estratégia válida, já que aproximar ao máximo as instâncias também aumenta a chance de todas serem afetadas por problemas de hardware. Se todas as instâncias estiverem no mesmo host físico e ele falhar, todas vão embora ao mesmo tempo.
Como alternativa, a AWS oferece a estratégia spread placement group, que faz exatamente o contrário, mantendo as instâncias o mais distantes fisicamente possível.
Como investigar throttling de banda
Apesar do throttling de banda ser a limitação de rede mais direta imposta pela AWS, alguns detalhes podem deixá-lo um pouco mais complicado.
Primeiro, é preciso entender qual é a real capacidade de banda de cada tipo de instância, já que a AWS tem dois limites diferentes para instâncias EC2: a banda baseline e o teto burstable.
Sempre que a documentação diz "Up to" tal valor, ela está se referindo ao teto burstable — você consegue chegar nessa banda máxima, mas só por um período específico, até esgotar os créditos de burst. Quanto maior a instância, menos hardware ela compartilha e mais tempo dá para ficar em burst.
Quando a instância esgota esses créditos de burst, o limite cai para o baseline (bem menor que o burstable), e o throttling de rede começa.
Para tamanhos em que a AWS diz "25 Gigabit" ou outro valor sem o termo "Up to", esse é o seu limite baseline, e não há teto burstable.
Para alguns tipos de instância, a AWS divulga tanto a banda baseline quanto a burstable na documentação [5], mas só algumas famílias estão lá.
Já o tempo que dá para ficar em burst em instâncias burstable nunca é divulgado pela AWS. Mas, com alguns testes, não é tão difícil descobrir.
Subindo uma c5.large e uma c5.24xlarge na minha conta da AWS, dá para descobrir esses limites para a c5.large, por exemplo, usando o iperf3.
[root@ip-172-31-82-248 ~]# iperf3 -c 172.31.23.48 -i 60 -t 480 -P 5
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.82.248 port 42202 connected to 172.31.23.48 port 5201
[ 7] local 172.31.82.248 port 42204 connected to 172.31.23.48 port 5201
[ 9] local 172.31.82.248 port 42208 connected to 172.31.23.48 port 5201
[ 11] local 172.31.82.248 port 42212 connected to 172.31.23.48 port 5201
[ 13] local 172.31.82.248 port 42218 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-60.05 sec 11.4 GBytes 1.64 Gbits/sec 19684 376 KBytes
[ 7] 0.00-60.05 sec 11.2 GBytes 1.60 Gbits/sec 17814 341 KBytes
[ 9] 0.00-60.05 sec 11.5 GBytes 1.65 Gbits/sec 18713 428 KBytes
[ 11] 0.00-60.05 sec 16.8 GBytes 2.40 Gbits/sec 24552 507 KBytes
[ 13] 0.00-60.05 sec 17.0 GBytes 2.44 Gbits/sec 22710 524 KBytes
[SUM] 0.00-60.05 sec 68.0 GBytes 9.72 Gbits/sec 103473
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 19955 341 KBytes
[ 7] 60.05-120.05 sec 11.3 GBytes 1.62 Gbits/sec 18304 428 KBytes
[ 9] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 18976 428 KBytes
[ 11] 60.05-120.05 sec 16.8 GBytes 2.41 Gbits/sec 25220 498 KBytes
[ 13] 60.05-120.05 sec 16.9 GBytes 2.42 Gbits/sec 23265 481 KBytes
[SUM] 60.05-120.05 sec 67.9 GBytes 9.72 Gbits/sec 105720
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 120.05-180.05 sec 11.5 GBytes 1.65 Gbits/sec 19194 454 KBytes
[ 7] 120.05-180.05 sec 11.1 GBytes 1.59 Gbits/sec 18328 454 KBytes
[ 9] 120.05-180.05 sec 11.5 GBytes 1.64 Gbits/sec 19259 358 KBytes
[ 11] 120.05-180.05 sec 16.7 GBytes 2.39 Gbits/sec 24946 542 KBytes
[ 13] 120.05-180.05 sec 17.1 GBytes 2.45 Gbits/sec 23032 323 KBytes
[SUM] 120.05-180.05 sec 67.9 GBytes 9.72 Gbits/sec 104759
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 180.05-240.05 sec 11.5 GBytes 1.65 Gbits/sec 20069 446 KBytes
[ 7] 180.05-240.05 sec 11.2 GBytes 1.60 Gbits/sec 17967 463 KBytes
[ 9] 180.05-240.05 sec 11.4 GBytes 1.64 Gbits/sec 18942 323 KBytes
[ 11] 180.05-240.05 sec 16.7 GBytes 2.39 Gbits/sec 24645 498 KBytes
[ 13] 180.05-240.05 sec 17.0 GBytes 2.44 Gbits/sec 22380 507 KBytes
[SUM] 180.05-240.05 sec 67.9 GBytes 9.72 Gbits/sec 104003
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 13304 323 KBytes
[ 7] 240.05-300.05 sec 7.85 GBytes 1.12 Gbits/sec 12274 498 KBytes
[ 9] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 12763 350 KBytes
[ 11] 240.05-300.05 sec 11.5 GBytes 1.65 Gbits/sec 16480 454 KBytes
[ 13] 240.05-300.05 sec 11.9 GBytes 1.71 Gbits/sec 15472 647 KBytes
[SUM] 240.05-300.05 sec 47.1 GBytes 6.74 Gbits/sec 70293
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 300.05-360.05 sec 879 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 300.05-360.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 360.05-420.05 sec 881 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 360.05-420.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 420.05-480.05 sec 782 MBytes 109 Mbits/sec 0 323 KBytes
[ 7] 420.05-480.05 sec 933 MBytes 130 Mbits/sec 0 498 KBytes
[ 9] 420.05-480.05 sec 932 MBytes 130 Mbits/sec 0 350 KBytes
[ 11] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 454 KBytes
[ 13] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 647 KBytes
[SUM] 420.05-480.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
Acima, temos o iperf3 conectando da minha c5.large à c5.24xlarge maior (assim, garantimos que os limites da c5.large vão ser atingidos primeiro, e é ela que vai fazer o papel de limitador), reportando em intervalos de 60s (-i 60), rodando por 8 minutos (-t 480), com 5 streams paralelas (-P 5).
Pela saída, dá para ver que, nos primeiros 5 minutos, a taxa ficou em torno de 10 Gbps, que é o que a AWS anuncia como "Up to" para instâncias c5.large. Só que depois de 5 minutos, a taxa cai para apenas 750 Mbps.
Isso nos dá agora dois limites não documentados para instâncias c5.large:
- banda baseline de 750 Mbps;
- limite de burst de até 10 Gbps por 5 minutos.
Agora sabemos que instâncias c5.large têm 750 Mbps de banda baseline e podem dar burst de até 10 Gbps por apenas 5 minutos.
Também dá para notar que, depois que o throttling de rede começou a entrar em ação, os contadores do ENA para moldagem de banda de saída também começaram a subir:
[root@ip-172-31-82-248 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 42427304
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
[root@ip-172-31-82-248 ~]#
Banda de saída para a Internet
Instâncias EC2 conseguem atingir o potencial máximo de banda quando a origem e o destino do tráfego estão dentro da AWS e na mesma região. Mas isso muda quando a origem ou o destino estão fora da região, seja em outra região da AWS, seja indo para a Internet.
Nesses casos, se a instância usada for grande e tiver pelo menos 32 vCPUs, o limite de banda para outras regiões ou para a internet vai ser de 50% da banda de rede dela. [6]
Se a instância tiver menos de 32 vCPUs, o limite fica fixo em no máximo 5 Gbps. [6]
Limitações de fluxo
Outra limitação de banda menos óbvia é que a AWS limita a banda por fluxo. O throughput máximo por fluxo é de 5 Gbps, independente da família ou tamanho da instância, e esse é um limite rígido. [6]
Uma das duas únicas formas de aumentar esse limite é fazer com que tanto a instância de origem quanto a de destino estejam no mesmo placement EC2. Isso pode ser feito colocando as instâncias no mesmo cluster placement group, ou por pura sorte, caso elas caiam dentro dos mesmos switches agregadores, conforme explicado na seção sobre EC2 Placement deste artigo.
Quando origem e destino estão no mesmo placement EC2, o limite máximo de banda por fluxo passa para 10 Gbps. [6]
A outra forma é usar o ENA Express em instâncias elegíveis dentro da mesma sub-rede; nesse caso, o limite vai para 25 Gbps por fluxo entre elas. [6]
Como alternativa, sempre que possível, use tráfego multi-fluxo para garantir banda e desempenho máximos, já que isso também impacta os limitadores de PPS, que veremos mais adiante.
Um ponto importante aqui é que o throttling causado por limitações de fluxo não aparece em lugar nenhum nas métricas de throttling do ENA.
Dá para comprovar isso facilmente, de novo com o iperf3. Se eu rodar uma única stream da minha c5.large (que deveria conseguir chegar a 10 Gbps) para a c5.24xlarge, com elas out-of-placement, dá para ver que o throughput máximo em um único fluxo fica limitado a 5 Gbps:
[root@ip-172-31-92-221 ~]# iperf3 -c 172.31.23.48 -t 60 -P 1
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.92.221 port 42472 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 594 MBytes 4.98 Gbits/sec 0 1.43 MBytes
[ 5] 1.00-2.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
[ 5] 2.00-3.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
Ainda assim, nenhum contador subiu nas métricas de throttling do ENA:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Isso é especialmente importante porque significa que o throttling de rede causado por limitações de fluxo é silencioso e bem difícil de identificar enquanto está acontecendo.
Micro-bursting
Outro ponto a considerar quando o assunto é throttling de banda é o micro-bursting. Ele acontece quando você bate nos limites de banda por períodos muito curtos, o que costuma ser difícil de detectar.
O cenário típico é aquele em que as métricas de throttling do ENA estão subindo bem devagar, mas, sempre que você consulta as métricas do CloudWatch para o tráfego de rede, ele nunca aparece encostando no teto de banda.
O throttling da AWS acontece em intervalos extremamente curtos. Não temos visibilidade sobre o quão rápido isso ocorre, mas eu já vi situações em que só medições com granularidade abaixo de 1 segundo conseguiam capturar o micro-bursting.
Já o CloudWatch, por padrão, traz pontos de dados em intervalos de 5 minutos; com monitoramento aprimorado, dá para baixar para 1 minuto.
Às vezes, o burst é tão curto que se dilui nos intervalos de 5 minutos do CloudWatch, e você simplesmente não enxerga.
A solução mais simples aqui é confiar que os contadores do ENA da AWS estão corretos, mesmo que você não consiga visualizar os picos de tráfego. Mas também dá, usando o CloudWatch Agent, para ter pontos de dados a cada 1 segundo, o que normalmente já captura a maior parte dos picos de banda.
Além disso, outra alternativa é comparar o volume de tráfego nas filas RX/TX do ENA com a quantidade de moldagem reportada.
Mesmo assim, na maioria dos cenários de micro-bursting, a quantidade de moldagem nem chega a ser significativa o bastante para se preocupar, já que ela é predominantemente enfileiramento e, em aplicações baseadas em TCP, a recuperação de pequenas perdas é simples.
Como ler as métricas de rede do CloudWatch
Outro erro comum é interpretar mal as métricas de rede do CloudWatch. Enquanto todos os limites de rede da AWS são em bits por segundo, as métricas de rede do CloudWatch são em bytes ao longo de um período. Isso torna confuso entender, de fato, o quão perto do teto de banda você está só de olhar para as métricas NetworkIn e NetworkOut.
Na minha c5.24xlarge de exemplo, ao abrir NetworkIn, o gráfico mostra algo assim:
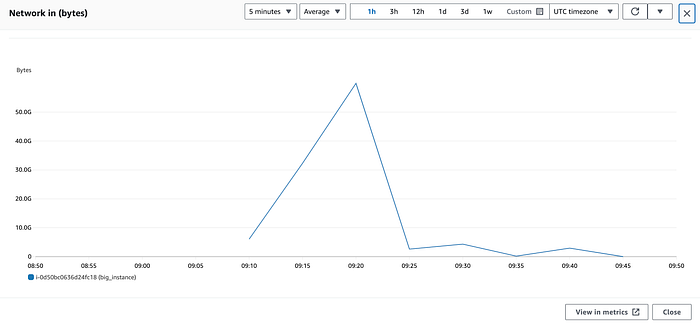
Aqui, é fácil cair na armadilha de achar que essa instância teve um pico acima de 50 Gbps de tráfego de entrada às 09:20; só que isso está errado.
Para entender o tráfego de rede real em bps, precisamos mudar a estatística para Sum e dividir o valor pelo período em segundos (por padrão, 5 minutos), obtendo a média de tráfego por segundo durante aquele intervalo.
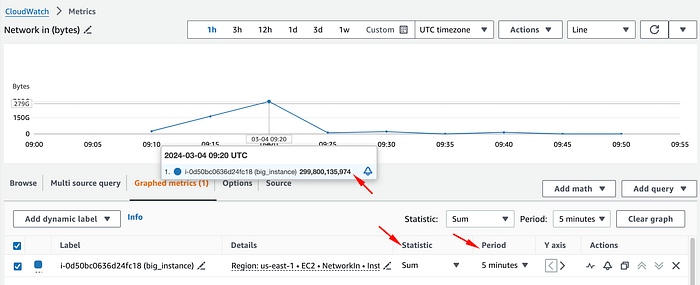
No nosso caso, dividimos o total de bytes do ponto de dados (299800135974) por 300 segundos (5 minutos) e chegamos a 999333786,58 bytes por segundo.
Em seguida, é preciso converter bytes em bits. Para simplificar, dá para converter direto em Mbps multiplicando por 0,000008, já que 1 byte por segundo equivale a 0,000008 Mbps.
Depois da conversão, dá para ver que essa métrica, na verdade, mostra uma média de tráfego de entrada de 7994 Mbps durante esse período de 5 minutos, bem longe da impressão inicial de 50 Gbps.
Para obter o tráfego total de rede daquele período, também precisaríamos converter o NetworkOut e somar os dois valores.
Como investigar throttling de Connection Tracking
Saindo das limitações de banda, a AWS também impõe um limite na quantidade de conexões rastreadas; depois desse limite, ela passa a recusar novas conexões.
Isso pode ser uma grande dor de cabeça, porque, uma vez atingido o limite, a AWS recusa qualquer nova conexão para sua instância EC2 até que o número de conexões caia para um valor abaixo do máximo permitido.
Até bem pouco tempo atrás, a AWS não divulgava nada disso, e não havia menção a esses limites na documentação. Felizmente, ela começou a divulgar a quantidade máxima de conexões rastreadas por tipo de instância EC2, mas só para instâncias de geração moderna baseadas em Nitro.
Esses limites também existem em instâncias não-Nitro, mas não são divulgados, e a única forma de descobri-los é testando a partir de quantas conexões a sua instância começa a recusar novas conexões.
A quantidade máxima de conexões rastreadas em uma instância Nitro pode ser consultada com o comando abaixo:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep conntrack_allowance_available
conntrack_allowance_available: 136813
[root@ip-172-31-92-221 ~]#
O motivo de tudo isso existir, em primeiro lugar, são os security groups. Eles são stateful, ou seja, rastreiam as conexões via conntrack para permitir que as respostas ao tráfego de entrada saiam da instância independentemente das regras de saída do security group, e vice-versa.
Dito isso, existe um jeito de contornar essa limitação sem precisar aumentar o tamanho da instância: simplesmente não usar security groups.
Sempre que um security group tem regras de entrada e saída que liberam todo o tráfego, esses fluxos são marcados como NOTRACK e não são rastreados pela AWS, ou seja, não contam para o conntrack allowance. [7]
Como alternativa, dá para usar network ACLs stateless, ou até regras de iptables direto, que podem ser stateless ou stateful. No caso stateful, você teria controle do conntrack do Linux a partir da própria instância e poderia aumentar os limites conforme a necessidade.
A única exceção a esse workaround é que conexões para alguns serviços específicos da AWS, listados abaixo, são sempre rastreadas automaticamente, independentemente da configuração do security group, porque isso é necessário para garantir o roteamento simétrico. Nesse caso, o único workaround é aumentar o tamanho da instância. [7]
- Egress-only internet gateways
- Gateway Load Balancers
- Global Accelerator accelerators
- NAT gateways
- Network Firewall firewall endpoints
- Network Load Balancers
- AWS PrivateLink (interface VPC endpoints)
- Transit gateway attachments
- AWS Lambda (Hyperplane elastic network interfaces)
Como investigar throttling para os Local Proxy Services
A AWS oferece alguns serviços como local proxies dentro do EC2: o AWS DNS Resolver (seja o segundo IP da sua sub-rede VPC, seja o 169.254.169.253 em qualquer instância EC2), o servidor NTP fornecido pela AWS (169.254.169.123) e o Instance Metadata Service (169.254.169.254).
Esses serviços compartilham um limite rígido de 1024 pps (pacotes por segundo) por interface ENI. Acima disso, a interface sofre throttling devido a linklocal_allowance_exceeded.
Normalmente, o throttling nesse caso vem de uso excessivo do Instance Metadata Service. Ter uma consulta ao IMDS dentro de uma função recursiva muito chamada, por exemplo, pode bater nesse limite com facilidade. Lembre-se de que o limite é em pacotes por segundo, e uma requisição HTTP ao IMDS usa vários pacotes de rede para ser concluída, ou seja, esse limite não equivale a 1024 consultas por segundo.
Usar o IMDS de forma consciente e cachear alguns dos resultados sempre que possível é o caminho aqui, já que esse é um limite rígido que não pode ser alterado, independentemente do tamanho da instância.
Outro caso comum de throttling aqui é o de muitas consultas DNS, e a solução, nesse caso, é implementar um cache DNS local.
Sempre que o contador do ENA para linklocal_allowance_exceeded estiver subindo, dá para identificar qual desses serviços está causando o throttling fazendo uma captura de pacotes do tráfego destinado aos IPs desses serviços e isolando se o tráfego é DNS, HTTP ou NTP.
Como investigar throttling de pacotes
Outra forma de throttling dentro da AWS está ligada ao número de pacotes por segundo, e é onde as coisas ficam um pouco mais complicadas, já que a documentação sobre essas limitações é mínima.
Mesmo que uma instância EC2 esteja abaixo do limite máximo de banda, o tráfego de rede dela ainda pode sofrer throttling por bater no número máximo permitido de pacotes por segundo daquela instância. O limite aqui é por instância, e não por ENI, como acontece no linklocal_allowance_exceeded.
Acontece que a AWS não divulga o número máximo permitido de pacotes por segundo para nenhum tipo de instância EC2 sem NDA, e ele também não é fixo, ou seja, varia conforme o tipo de pacote que compõe o tráfego.
Os limites de PPS para uma instância EC2 vão variar conforme: [8]
- se o tráfego é TCP ou UDP;
- número de fluxos;
- tamanho dos pacotes;
- conexões novas ou conexões existentes (limitação de TCP SYN);
- e regras de security group aplicadas.
Isso torna quase impossível estabelecer um limite fixo de PPS com qualquer certeza, mesmo com testes exaustivos, porque a limitação real depende do padrão real do tráfego de rede.
Por exemplo, uma aplicação que cria muitas conexões novas provavelmente vai bater na limitação de TCP SYN e, portanto, atingir o limite de PPS bem antes de uma aplicação que se apoia mais em conexões já existentes.
Existem formas de fazer stress test na instância com pacotes para ter uma estimativa aproximada dos limites de PPS, e a AWS descreve esses passos neste artigo [8], só que esse caminho é bem menos confiável do que usar o iperf para descobrir os limites de banda.
A alternativa preferida é fazer stress test na própria aplicação hospedada e monitorar as métricas do ENA para throttling de PPS, já que isso leva em conta os padrões de rede da aplicação.
Felizmente, essas limitações geralmente não são tão baixas, e os limites de banda costumam ser atingidos antes. Ainda assim, os padrões de tráfego preferidos aqui seriam: uma aplicação com tráfego TCP que use majoritariamente conexões existentes, com pacotes maiores, vários fluxos diferentes, e security groups que liberem todo o tráfego de entrada e saída nas portas em questão para evitar tracking.
Em caso de throttling, adaptar o padrão de tráfego para se aproximar do descrito acima costuma ajudar; ou, alternativamente, aumentar o tamanho da instância.