· Por qué es clave entender las limitaciones de red en AWS
· ¿Cuáles son las limitaciones?
· Placement de EC2 y uso compartido de recursos
· Troubleshooting del throttling de ancho de banda
∘ Ancho de banda de salida a internet
∘ Cómo leer las métricas de red de CloudWatch
· Troubleshooting del throttling por connection tracking
· Troubleshooting del throttling hacia los servicios de proxy local
· Troubleshooting del throttling de paquetes
Por qué es clave entender las limitaciones de red en AWS
Dentro del amplio ecosistema de servicios de AWS, las instancias EC2 y la red de EC2 son los bloques fundamentales sobre los que se construye la mayoría de los demás servicios, dando soporte a una gran variedad de aplicaciones críticas para la infraestructura digital moderna. Sin embargo, entender el rendimiento de estas instancias implica adentrarse en los detalles de la red de AWS, en particular en el network throttling. Este, que puede manifestarse de varias formas, influye directamente en el rendimiento y la escalabilidad de las instancias EC2 y, por extensión, en muchos otros servicios del ecosistema.
AWS aplica el network throttling mediante dos mecanismos principales: limitaciones de ancho de banda y restricciones de paquetes por segundo (PPS). El throttling de ancho de banda afecta el volumen de datos que se puede transferir por la red en un período determinado, mientras que el de PPS limita la cantidad de paquetes que se pueden enviar o recibir. Estas restricciones están cuidadosamente diseñadas para preservar la salud y la eficiencia general de la infraestructura de AWS. Aun así, pueden representar retos importantes a la hora de optimizar el rendimiento de las aplicaciones y el uso de los recursos.
A esto se suma la falta de documentación oficial sobre algunos aspectos del network throttling en AWS. La información sobre cómo y cuándo se aplican estos mecanismos es difícil de encontrar, lo que obliga a los desarrolladores a recorrer un laberinto de foros, experiencias de otros usuarios e investigaciones de prueba y error para entender y mitigar el impacto en sus servicios. Esta ausencia de documentación clara y accesible añade una capa extra de complejidad a la gestión y optimización del rendimiento de red en AWS.
En este artículo vamos a juntar las piezas dispersas de este rompecabezas para ofrecer un panorama claro y completo sobre cómo AWS implementa los mecanismos de throttling en la red de EC2.
¿Cuáles son las limitaciones?
En las generaciones modernas de instancias EC2 basadas en Nitro, AWS expone varias métricas como contadores de paquetes moldeados por el network throttling. Todas están listadas en su documentación oficial [1].
- bw_in_allowance_exceeded: cantidad de paquetes encolados o descartados porque el ancho de banda agregado de entrada superó el máximo de ese tipo/tamaño de instancia.
- bw_out_allowance_exceeded: cantidad de paquetes encolados o descartados porque el ancho de banda agregado de salida superó el máximo de ese tipo/tamaño de instancia.
- conntrack_allowance_exceeded: cantidad de paquetes descartados porque el connection tracking superó el máximo de la instancia y no se pudieron establecer nuevas conexiones. Esto puede provocar pérdida de paquetes en el tráfico hacia o desde la instancia.
- conntrack_allowance_available: cantidad de conexiones rastreadas que la instancia puede establecer antes de alcanzar el límite de Connections Tracked de ese tipo de instancia.
- linklocal_allowance_exceeded: cantidad de paquetes descartados porque el PPS del tráfico hacia los servicios de proxy local superó el máximo de la interfaz de red. Afecta al tráfico hacia el servicio DNS, al Instance Metadata Service y al Amazon Time Sync Service.
- pps_allowance_exceeded: cantidad de paquetes encolados o descartados porque el PPS bidireccional superó el máximo de la instancia.
Si bien estas métricas solo se exponen en instancias basadas en Nitro a través del driver ENA, las limitaciones no son exclusivas de Nitro. Las instancias no-Nitro, virtualizadas en Xen, también tienen limitaciones de red (muchas veces incluso menores que las de Nitro), pero tiene sentido que AWS solo pueda exponer estas métricas personalizadas en su propio driver propietario ENA.
Estos contadores se consultan desde el lado de la instancia con el siguiente comando:
[root@ip-172-31-82-248 ~]# ethtool -S eth0 | grep allowance
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
conntrack_allowance_available: 136812
¿Cómo se moldea el tráfico?
La forma en que la documentación de AWS describe el moldeado del tráfico una vez alcanzado un límite es muy importante, ya que indica que los paquetes son encolados o descartados. Lo que no sabemos es por cuánto tiempo permanecen encolados.
Aunque no hay manera de saber si el throttling se aplicó como encolamiento o descarte, las pruebas indican que normalmente, cuando el tráfico de red apenas roza los límites, el moldeado se traduce solo en encolamiento, y casi siempre dura unos pocos milisegundos, generando poco o ningún impacto.
El descarte de paquetes parece ocurrir solo cuando los límites se sobrepasan de forma significativa, e incluso así, mientras el descarte sea moderado, las aplicaciones basadas en TCP suelen recuperarse con facilidad simplemente retransmitiendo los paquetes perdidos.
Además, las métricas de ENA sobre network throttling son contadores de paquetes desde el último reset de ENA, por lo que representan una suma de paquetes que fueron moldeados.
Revisar estos contadores y encontrar uno distinto de cero no siempre es señal de un problema, ya que los datos pueden estar desactualizados. Para visualizarlos mejor, también puedes exportarlos como métrica de CloudWatch a través del CloudWatch Agent [2], lo que permite seguirlos a lo largo del tiempo y ver si el contador sigue creciendo, y a qué ritmo de paquetes por segundo.
Placement de EC2 y uso compartido de recursos
Las instancias EC2 son máquinas virtuales, y una máquina virtual es esencialmente otra capa de abstracción sobre el hardware físico, el cual se comparte entre múltiples tenants.
Como regla general, cuanto mayor es el tamaño de una instancia EC2 dentro de su familia, menos comparte el hardware con otros tenants, hasta el punto de ser la única máquina virtual en ese hardware, o directamente una instancia metal.
Por ejemplo, podemos asumir que una c5.24xlarge, el tamaño más grande de esa familia, muy probablemente tenga el host subyacente entero para sí misma, sin compartir sus límites de red con otros tenants. Esto significa que dispondrá de toda la capacidad del hardware y de límites de red mucho mayores que un tamaño de instancia más pequeño.
En cambio, una c5.large, el tamaño más chico de esa familia, muy probablemente comparta el host subyacente con varios tenants. Por lo tanto, tendrá 1/x de la capacidad de ese hardware, siendo x el número máximo de tenants para ese hardware.
Aunque no tenemos visibilidad sobre cómo funcionan estos placements en el backend, esto da una idea aproximada de que, como regla general, cuanto mayor es el tamaño de una instancia, mayores son sus límites de red.
Además, cuando se considera el tráfico que sale de la instancia, también pueden existir restricciones que tienen en cuenta el stack de red fuera del hipervisor, debido a los switches y routers más arriba en el stack.
Aunque tampoco tenemos visibilidad sobre el stack de red de AWS para EC2, el stack típico de un datacenter se vería más o menos así:
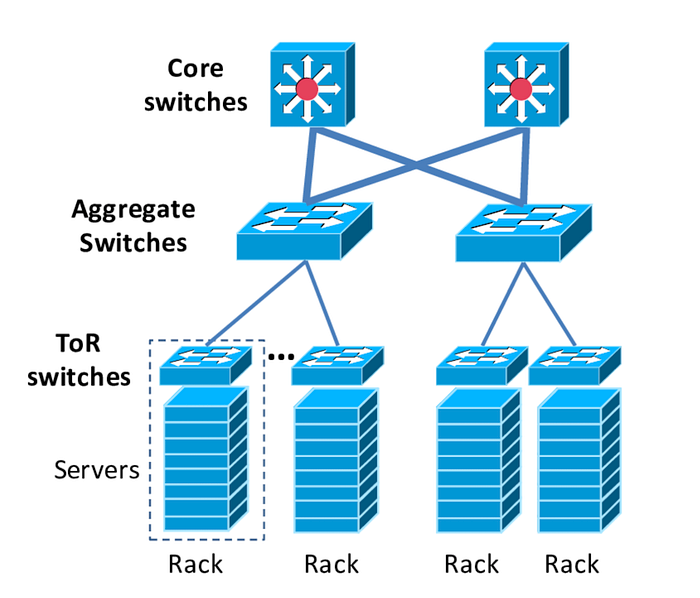
AWS sí nos permite, sin embargo, definir estrategias de placement [3], las cuales regulan qué tan cerca quedan las instancias entre sí. Esto afecta no solo a la latencia, sino también al ancho de banda por flujo en los límites por flujo.
Crear un Cluster Placement Group implica que las instancias quedarán lo más cerca posible entre sí, por ejemplo, dentro del mismo host subyacente, dentro del mismo switch ToR, dentro del mismo aggregate switch, etc. Esta estrategia garantiza la menor latencia posible entre las instancias del placement group y los límites de ancho de banda por flujo más altos posibles.
Si no defines ninguna estrategia de placement, AWS asignará tus instancias de forma aleatoria según la capacidad disponible, lo que significa que a veces, por pura suerte, quedarán dentro del mismo switch ToR/aggregate, y otras veces no.
Cada vez que detienes y arrancas una instancia EC2, esta se reubica en algún punto distinto de la infraestructura de AWS [4], lo que significa que puede quedar en placement (cerca de tus otras instancias) o fuera de placement (lejos de ellas), y estar en uno u otro estado afecta la latencia y el throughput máximo por flujo.
Por este fenómeno, he visto casos en los que dos instancias EC2 que alojaban aplicaciones de baja latencia y alto throughput por flujo estaban en placement por pura suerte, pero al ser detenidas y reiniciadas quedaron fuera de placement, y de repente comenzaron a tener problemas de red, debido al menor throughput máximo por flujo y al aumento de la latencia tras el cambio.
Por esta razón, es importante considerar la naturaleza de tu aplicación y definir una estrategia de placement con anticipación para tu infraestructura en AWS.
Por supuesto, el cluster placement no es la única estrategia válida, ya que colocar las instancias lo más cerca posible también aumenta la probabilidad de que todas se vean afectadas por problemas de hardware. Si todas tus instancias están dentro del mismo host subyacente y ocurre una falla de hardware en ese host, todas se caen al mismo tiempo.
Como alternativa, AWS también ofrece la estrategia de spread placement group, que hace exactamente lo contrario: mantiene tus instancias lo más alejadas posible físicamente.
Troubleshooting del throttling de ancho de banda
Aunque el throttling de ancho de banda es la limitación de red más directa que impone AWS, hay algunos detalles que pueden complicar el panorama.
Primero, hay que establecer la capacidad real de ancho de banda de cada tipo de instancia, ya que AWS define dos límites distintos para las instancias EC2: el baseline bandwidth y el burstable ceiling.
Cuando la documentación dice "Up to" una determinada cantidad, se refiere al burstable ceiling: puedes alcanzar ese ancho de banda máximo, pero solo durante un cierto tiempo, hasta que se agoten tus burst credits. Cuanto mayor sea el tamaño de la instancia, menos compartirá el hardware subyacente y por más tiempo podrás hacer burst.
Una vez que la instancia agota esos burst credits, el límite cae al baseline (mucho menor que el burstable), y comienza el network throttling.
Para los tamaños de instancia donde AWS indica "25 Gigabit" u otra cantidad sin el término "Up to", ese es tu límite baseline y no hay burstable ceiling.
Para algunos tipos de instancia, AWS publica tanto el baseline bandwidth como el burstable bandwidth en su documentación [5], aunque solo para algunas familias.
En cuanto al tiempo durante el cual puedes hacer burst en instancias burstables, AWS no lo divulga. Sin embargo, con algunas pruebas no debería ser tan difícil descubrirlo.
Lanzando una c5.large y una c5.24xlarge en mi propia cuenta de AWS podemos averiguar estos límites para una c5.large, por ejemplo, usando iperf3.
[root@ip-172-31-82-248 ~]# iperf3 -c 172.31.23.48 -i 60 -t 480 -P 5
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.82.248 port 42202 connected to 172.31.23.48 port 5201
[ 7] local 172.31.82.248 port 42204 connected to 172.31.23.48 port 5201
[ 9] local 172.31.82.248 port 42208 connected to 172.31.23.48 port 5201
[ 11] local 172.31.82.248 port 42212 connected to 172.31.23.48 port 5201
[ 13] local 172.31.82.248 port 42218 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-60.05 sec 11.4 GBytes 1.64 Gbits/sec 19684 376 KBytes
[ 7] 0.00-60.05 sec 11.2 GBytes 1.60 Gbits/sec 17814 341 KBytes
[ 9] 0.00-60.05 sec 11.5 GBytes 1.65 Gbits/sec 18713 428 KBytes
[ 11] 0.00-60.05 sec 16.8 GBytes 2.40 Gbits/sec 24552 507 KBytes
[ 13] 0.00-60.05 sec 17.0 GBytes 2.44 Gbits/sec 22710 524 KBytes
[SUM] 0.00-60.05 sec 68.0 GBytes 9.72 Gbits/sec 103473
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 19955 341 KBytes
[ 7] 60.05-120.05 sec 11.3 GBytes 1.62 Gbits/sec 18304 428 KBytes
[ 9] 60.05-120.05 sec 11.4 GBytes 1.64 Gbits/sec 18976 428 KBytes
[ 11] 60.05-120.05 sec 16.8 GBytes 2.41 Gbits/sec 25220 498 KBytes
[ 13] 60.05-120.05 sec 16.9 GBytes 2.42 Gbits/sec 23265 481 KBytes
[SUM] 60.05-120.05 sec 67.9 GBytes 9.72 Gbits/sec 105720
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 120.05-180.05 sec 11.5 GBytes 1.65 Gbits/sec 19194 454 KBytes
[ 7] 120.05-180.05 sec 11.1 GBytes 1.59 Gbits/sec 18328 454 KBytes
[ 9] 120.05-180.05 sec 11.5 GBytes 1.64 Gbits/sec 19259 358 KBytes
[ 11] 120.05-180.05 sec 16.7 GBytes 2.39 Gbits/sec 24946 542 KBytes
[ 13] 120.05-180.05 sec 17.1 GBytes 2.45 Gbits/sec 23032 323 KBytes
[SUM] 120.05-180.05 sec 67.9 GBytes 9.72 Gbits/sec 104759
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 180.05-240.05 sec 11.5 GBytes 1.65 Gbits/sec 20069 446 KBytes
[ 7] 180.05-240.05 sec 11.2 GBytes 1.60 Gbits/sec 17967 463 KBytes
[ 9] 180.05-240.05 sec 11.4 GBytes 1.64 Gbits/sec 18942 323 KBytes
[ 11] 180.05-240.05 sec 16.7 GBytes 2.39 Gbits/sec 24645 498 KBytes
[ 13] 180.05-240.05 sec 17.0 GBytes 2.44 Gbits/sec 22380 507 KBytes
[SUM] 180.05-240.05 sec 67.9 GBytes 9.72 Gbits/sec 104003
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 13304 323 KBytes
[ 7] 240.05-300.05 sec 7.85 GBytes 1.12 Gbits/sec 12274 498 KBytes
[ 9] 240.05-300.05 sec 7.89 GBytes 1.13 Gbits/sec 12763 350 KBytes
[ 11] 240.05-300.05 sec 11.5 GBytes 1.65 Gbits/sec 16480 454 KBytes
[ 13] 240.05-300.05 sec 11.9 GBytes 1.71 Gbits/sec 15472 647 KBytes
[SUM] 240.05-300.05 sec 47.1 GBytes 6.74 Gbits/sec 70293
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 300.05-360.05 sec 879 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 300.05-360.05 sec 878 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 300.05-360.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 300.05-360.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 323 KBytes
[ 7] 360.05-420.05 sec 880 MBytes 123 Mbits/sec 0 498 KBytes
[ 9] 360.05-420.05 sec 881 MBytes 123 Mbits/sec 0 350 KBytes
[ 11] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 454 KBytes
[ 13] 360.05-420.05 sec 1.31 GBytes 188 Mbits/sec 0 647 KBytes
[SUM] 360.05-420.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
[ 5] 420.05-480.05 sec 782 MBytes 109 Mbits/sec 0 323 KBytes
[ 7] 420.05-480.05 sec 933 MBytes 130 Mbits/sec 0 498 KBytes
[ 9] 420.05-480.05 sec 932 MBytes 130 Mbits/sec 0 350 KBytes
[ 11] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 454 KBytes
[ 13] 420.05-480.05 sec 1.31 GBytes 187 Mbits/sec 0 647 KBytes
[SUM] 420.05-480.05 sec 5.20 GBytes 745 Mbits/sec 0
- - - - - - - - - - - - - - - - - - - - - - - - -
Lo que vemos arriba es iperf3 conectándose desde mi instancia c5.large hacia la c5.24xlarge más grande (de modo que se garantice que los límites de la c5.large se alcancen primero, y sea ese el limitador), reportando en intervalos de 60s (-i 60), ejecutándose por 8 minutos (-t 480), con 5 streams en paralelo (-P 5).
De esta salida podemos ver que durante los primeros 5 minutos el bitrate fue de aproximadamente 10Gbps, que es lo que AWS anuncia como "Up to" para instancias c5.large. Sin embargo, después de 5 minutos el bitrate cae a solo 750Mbps.
Esto nos da dos límites no documentados para las instancias c5.large:
- 750Mbps de baseline bandwidth.
- Burst de hasta 10Gbps por 5 minutos.
Ahora sabemos que las instancias c5.large tienen 750Mbps de baseline bandwidth y pueden hacer burst hasta 10Gbps durante solo 5 minutos.
También se observa que, una vez que el network throttling empezó a actuar, los contadores de ENA para el moldeado del ancho de banda de salida también empezaron a aumentar:
[root@ip-172-31-82-248 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 42427304
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
[root@ip-172-31-82-248 ~]#
Ancho de banda de salida a internet
Las instancias EC2 alcanzan su máximo potencial de ancho de banda siempre que el origen y el destino del tráfico estén dentro de AWS y en la misma región. Pero esto cambia cuando el origen o el destino están fuera de la región, ya sea en otra región de AWS o ruteado hacia internet.
En esos casos, si el tamaño de instancia que estás usando es muy grande y tiene un mínimo de 32 vCPUs, el límite de ancho de banda hacia otras regiones o hacia internet será del 50% de su ancho de banda de red. [6]
Si la instancia tiene menos de 32 vCPUs, el límite queda fijo en un máximo de 5Gbps. [6]
Limitaciones por flujo
Otra limitación de ancho de banda menos evidente es que AWS limita la cantidad de ancho de banda por flujo. El throughput máximo por flujo es de 5Gbps, sin importar la familia o el tamaño de la instancia, y se trata de un límite duro. [6]
Una de las dos únicas formas de aumentar este límite es lograr que las instancias de origen y destino estén dentro del mismo placement de EC2. Esto se consigue colocándolas dentro del mismo cluster placement group, o por pura suerte si quedan dentro de los mismos aggregate switches, como se explicó antes en la sección de Placement de EC2.
Cuando ambas instancias están en el mismo placement de EC2, el ancho de banda máximo por flujo es de 10Gbps. [6]
La otra opción es usar ENA Express en instancias compatibles dentro de la misma subnet, donde el límite será de 25Gbps por flujo entre esas instancias. [6]
Como alternativa, siempre que sea posible, conviene usar tráfico multi-flow, para asegurar la máxima capacidad y rendimiento de ancho de banda, ya que también impacta en los limitadores de PPS que veremos más adelante.
Algo importante a tener en cuenta es que el throttling debido a las limitaciones por flujo no se expone en ninguna de las métricas de throttling de ENA.
Esto se comprueba fácilmente otra vez con iperf3. Si ejecuto un solo stream desde mi c5.large (que debería poder alcanzar 10Gbps) hacia mi c5.24xlarge, estando fuera de placement, se observa que el throughput máximo en un solo flujo se limita a 5Gbps:
[root@ip-172-31-92-221 ~]# iperf3 -c 172.31.23.48 -t 60 -P 1
Connecting to host 172.31.23.48, port 5201
[ 5] local 172.31.92.221 port 42472 connected to 172.31.23.48 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 594 MBytes 4.98 Gbits/sec 0 1.43 MBytes
[ 5] 1.00-2.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
[ 5] 2.00-3.00 sec 592 MBytes 4.97 Gbits/sec 0 1.52 MBytes
Sin embargo, ningún contador aumentó en las métricas de throttling de ENA:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep exceeded
bw_in_allowance_exceeded: 0
bw_out_allowance_exceeded: 0
pps_allowance_exceeded: 0
conntrack_allowance_exceeded: 0
linklocal_allowance_exceeded: 0
Esto es especialmente importante porque significa que el network throttling por limitaciones de flujo es silencioso y muy difícil de detectar mientras ocurre.
Micro-bursting
Otra consideración importante respecto al throttling de ancho de banda es el micro-bursting. Ocurre cuando se alcanzan los límites de ancho de banda durante períodos muy breves, lo cual suele ser difícil de detectar.
El escenario típico es cuando las métricas de throttling de ENA aumentan muy lentamente, pero al revisar las métricas de CloudWatch para el tráfico de red no se ve que el ancho de banda se acerque siquiera al techo.
El throttling de AWS sucede en intervalos increíblemente pequeños y, aunque no tenemos visibilidad de qué tan rápido ocurre, ya he visto situaciones en las que solo mediciones a nivel sub-segundo lograron detectar el micro-bursting.
CloudWatch, por su parte, ofrece puntos de datos en intervalos de 5 minutos por defecto, y con monitoreo mejorado se pueden reducir a 1 minuto.
A veces el burst es tan corto que se diluye dentro de los intervalos de 5 minutos que ofrece CloudWatch y se vuelve invisible.
Aunque la solución más sencilla es confiar en que los contadores de ENA de AWS son correctos, incluso si no logras detectar los picos de tráfico, usando el CloudWatch Agent es posible obtener puntos de datos cada 1s, lo que debería bastar para captar la mayoría de los picos de ancho de banda.
Más allá de eso, la solución sería comparar la cantidad de tráfico en las colas RX/TX de ENA contra la cantidad de moldeado reportado.
Sin embargo, en la mayoría de los escenarios de micro-bursting el moldeado no es lo suficientemente significativo como para preocuparse, ya que consistirá mayoritariamente en encolamiento, y si se trata de aplicaciones basadas en TCP, también se recuperarán fácilmente de pequeñas pérdidas.
Cómo leer las métricas de red de CloudWatch
Otro error común es interpretar mal las métricas de red de CloudWatch. Mientras que todos los límites de red de AWS están en bits por segundo, las métricas de red de CloudWatch están en bytes durante un período de tiempo. Esto hace muy confuso entender realmente qué tan cerca estás del techo de ancho de banda con solo mirar las métricas NetworkIn y NetworkOut.
En mi instancia c5.24xlarge de ejemplo, si abrimos NetworkIn, nos mostrará algo así:
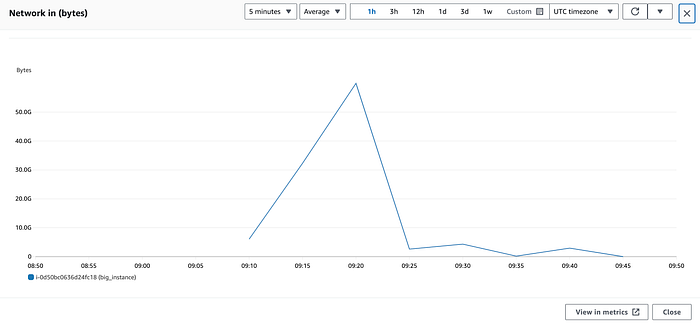
A primera vista, uno podría caer en la trampa de creer que esta instancia llegó a más de 50Gbps de tráfico de red entrante a las 09:20; pero eso es incorrecto.
Para entender el tráfico de red real en bps, hay que cambiar la estadística a Sum y dividirla por el período en segundos (por defecto, 5 minutos), para obtener un promedio de tráfico por segundo durante ese intervalo.
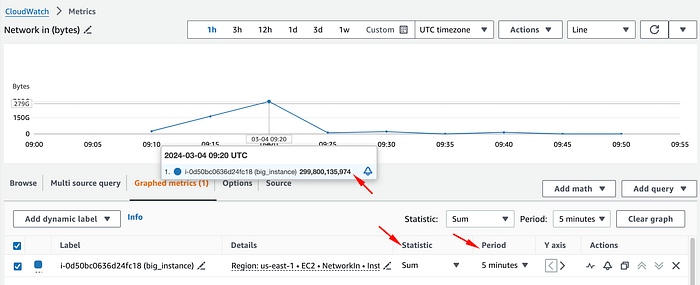
En este caso, dividimos el total de bytes de ese punto de datos (299800135974) entre 300 segundos (5 minutos), y obtenemos 999333786.58 bytes por segundo.
Después, hay que convertir bytes a bits. Para simplificar, podemos pasarlo directamente a Mbps multiplicando por 0.000008, ya que 1 byte por segundo equivale a 0.000008 Mbps.
Una vez convertido, vemos que esta métrica en realidad nos muestra un promedio de tráfico entrante de 7994 Mbps durante ese período de 5 minutos, muy lejos de la impresión inicial de 50Gbps.
Para obtener el tráfico de red total de ese período, también habría que convertir NetworkOut y sumar ambas cantidades.
Troubleshooting del throttling por connection tracking
Más allá de las limitaciones de ancho de banda, AWS también impone una limitación sobre cuántas conexiones se rastrean. Una vez alcanzado ese límite, comenzará a rechazar nuevas conexiones.
Esto puede ser un gran dolor de cabeza, ya que cuando se llega a ese límite AWS rechazará cualquier nueva conexión a tu instancia EC2 hasta que el número de conexiones baje por debajo del máximo permitido.
Hasta hace muy poco, AWS no divulgaba nada de esto y no había mención de estos límites en la documentación. Por suerte, AWS comenzó recientemente a publicar la cantidad máxima de conexiones rastreadas por tipo de instancia EC2, pero solo para las instancias de generación moderna basadas en Nitro.
Aunque estos límites también existen en instancias no-Nitro, no se divulgan, y la única forma de descubrirlos sería probar a partir de cuántas conexiones tu instancia comienza a rechazar las nuevas.
La cantidad máxima de conexiones rastreadas en una instancia Nitro se consulta con el siguiente comando:
[root@ip-172-31-92-221 ~]# ethtool -S ens5|grep conntrack_allowance_available
conntrack_allowance_available: 136813
[root@ip-172-31-92-221 ~]#
La única razón por la que esto existe son los security groups. Los security groups son stateful, lo que significa que rastrean las conexiones a través de conntrack para permitir que las respuestas al tráfico entrante salgan de la instancia sin importar las reglas de salida del security group, y viceversa.
Dicho esto, existe una manera de evitar esta limitación sin necesidad de aumentar el tamaño de la instancia: simplemente, no usar security groups.
Cuando un security group tiene reglas de entrada y salida que permiten todo el tráfico, esos flujos se marcan como NOTRACK, y no son rastreados por AWS, por lo que no cuentan dentro del conntrack allowance. [7]
Como alternativa, se pueden usar network ACLs stateless, o incluso reglas de iptables directamente, las cuales pueden ser stateless o stateful, ya que en este último caso tendrías control sobre el conntrack en Linux desde el lado de la instancia y podrías aumentar los límites según sea necesario.
La única excepción a este workaround es que las conexiones a otros servicios específicos de AWS, listados a continuación, siempre serán rastreadas automáticamente, sin importar la configuración del security group, ya que esto es necesario para garantizar el ruteo simétrico. En este caso, el único workaround sería aumentar el tamaño de la instancia. [7]
- Egress-only internet gateways
- Gateway Load Balancers
- Global Accelerator accelerators
- NAT gateways
- Network Firewall firewall endpoints
- Network Load Balancers
- AWS PrivateLink (interface VPC endpoints)
- Transit gateway attachments
- AWS Lambda (Hyperplane elastic network interfaces)
Troubleshooting del throttling hacia los servicios de proxy local
AWS ofrece varios servicios como proxies locales dentro de EC2: el AWS DNS Resolver (ya sea la segunda IP de tu subnet de VPC o la 169.254.169.253 en cualquier instancia EC2), el servidor NTP provisto por AWS (169.254.169.123) y el Instance Metadata Service (169.254.169.254).
Estos servicios comparten un límite duro de 1024 pps (paquetes por segundo) por interfaz ENI. Si se supera, la interfaz será throttled debido a linklocal_allowance_exceeded.
Generalmente, el throttling en este caso proviene de un uso excesivo del Instance Metadata Service. Por ejemplo, tener una consulta IMDS dentro de una función recursiva que se ejecuta con frecuencia puede hacer que se alcance este límite con facilidad. Ten en cuenta que el límite es en paquetes por segundo, y una consulta HTTP a IMDS utilizará varios paquetes de red para completarse, por lo que este límite no equivale a 1024 consultas por segundo.
El camino a seguir es hacer un uso consciente de IMDS y cachear algunos resultados cuando sea posible, ya que se trata de un límite duro que no se puede modificar, sin importar el tamaño de la instancia.
Otro caso común de throttling aquí son las consultas DNS en exceso, y la solución sería implementar una caché de DNS local.
Cuando los contadores de ENA para linklocal_allowance_exceeded aumenten, puedes identificar cuál de estos servicios está causando el throttling haciendo una captura de paquetes del tráfico hacia esas IPs de servicio, y aislando si el tráfico es DNS, HTTP o NTP.
Troubleshooting del throttling de paquetes
Otra forma de throttling dentro de AWS se debe al número de paquetes por segundo, y aquí es donde las cosas se complican un poco más, ya que hay muy poca documentación sobre estas limitaciones.
Aun cuando una instancia EC2 esté por debajo del límite máximo de ancho de banda, su tráfico de red puede ser throttled por alcanzar el número máximo permitido de paquetes por segundo para esa instancia. El límite aquí es por instancia, y no por ENI como ocurre con linklocal_allowance_exceeded.
Sin embargo, AWS no divulga el número máximo permitido de paquetes por segundo para ningún tipo de instancia EC2 sin un NDA, y tampoco es fijo, lo que significa que puede variar según el tipo de paquetes que componen el tráfico.
Los límites de PPS para una instancia EC2 varían según: [8]
- Si el tráfico es TCP o UDP.
- Cantidad de flujos.
- Tamaño del paquete.
- Conexiones nuevas o existentes (limitación de TCP SYN).
- Y según las reglas de security group aplicadas.
Esto hace casi imposible establecer un límite fijo de PPS con certeza, incluso mediante pruebas exhaustivas, ya que la limitación real dependerá del patrón concreto del tráfico de red.
Por ejemplo, una aplicación que genera muchas conexiones nuevas probablemente alcanzará la limitación de TCP SYN, y por ende el límite de PPS, mucho antes que una aplicación que se basa más en conexiones existentes.
Aunque hay maneras de hacer stress testing en la instancia con paquetes para tener una estimación aproximada de los límites de PPS, y AWS describe los pasos para realizar esa prueba en este artículo [8], ese método es mucho menos confiable que usar iperf para descubrir los límites de ancho de banda.
La alternativa preferida es hacer stress testing sobre la propia aplicación alojada y monitorear las métricas de ENA para el throttling de PPS, ya que así se contemplan los patrones de red reales de la aplicación.
Por suerte, estas limitaciones suelen no ser tan bajas, y los límites de ancho de banda generalmente se alcanzan primero. Aun así, los patrones de tráfico ideales serían una aplicación con tráfico TCP que use mayoritariamente conexiones existentes, paquetes de mayor tamaño, muchos flujos diferentes, y que cuente con security groups que permitan todo el tráfico de entrada y salida en esos puertos para evitar el tracking.
En caso de throttling, adaptar el patrón de tráfico para que se ajuste mejor al patrón mencionado arriba debería ayudar, o, alternativamente, aumentar el tamaño de la instancia.