Utilisez Cloud Run et Eventarc pour superviser et automatiser des actions sur vos projets GCP.
Fin d'année dernière, Google a annoncé très discrètement un nouveau service baptisé Eventarc, présenté comme une fonctionnalité de déclenchement d'événements intégrée à Google Cloud Platform et reposant sur CloudEvents. Le concept se rapproche fortement de CloudWatch Events chez AWS.

Décollage !
Passé en disponibilité générale quelques jours seulement avant la publication de cet article, c'est une fonctionnalité très puissante mais encore peu connue. Eventarc offre un fort potentiel aux organisations qui cherchent à pousser plus loin l'automatisation ou à mieux superviser leurs ressources.
Ce service restant largement méconnu, j'ai voulu prolonger le guide de démarrage rapide de Google et illustrer, à travers un exemple concret, ce qu'il permet de faire.
Présentation du service
Le quickstart de Google porte sur la réception d'événements Cloud Storage, un service très pratique pour être notifié lorsque des données changent et fréquemment utilisé par Cloud Functions pour réagir à la création, à la mise à jour ou à la suppression d'un objet. C'est aussi un excellent point de départ pour découvrir Eventarc.
Pour aller plus loin que le quickstart de Google, j'y ajoute la possibilité de charger automatiquement dans BigQuery les fichiers déposés dans un bucket GCS — une demande très fréquente chez DoiT International.
Le service présenté dans cet article se déclenche à la création d'un nouveau fichier CSV dans un bucket GCS et lance un job de chargement de ce fichier dans une table BigQuery.
Remarque : Eventarc est un produit récemment sorti de bêta et certaines fonctionnalités manquent encore, à commencer par le ciblage de ressources spécifiques. Le code déclenché doit donc vérifier lui-même qu'il s'agit bien de la bonne ressource, ce que fait celui de cet article.
**Construction de l'image**
La première étape consiste à cloner un dépôt contenant le code que j'ai écrit pour cet article, puis à le soumettre à Cloud Build pour générer une image de conteneur exploitable par Cloud Run.
Ouvrez d'abord Cloud Shell depuis votre console GCP. Vérifiez qu'il pointe sur le projet voulu en exécutant la commande suivante (remplacez
gcloud config set project <project id>
Une fois le bon projet sélectionné, exécutez la commande suivante pour cloner le dépôt git :
git clone https://github.com/sayle-doit/eventarc-blog.git
cd eventarc-blog
Une fois le clonage terminé, je vous conseille de jeter un œil au code — en particulier au Dockerfile et au fichier main.py — pour bien comprendre ce qu'il fait.
Il faut ensuite construire une image de conteneur à partir de ce Dockerfile. Exécutez la commande suivante dans Cloud Shell, en remplaçant
gcloud builds submit --tag gcr.io/<project id>/<tag>
La construction prend environ 30 à 60 secondes et renvoie un message de succès accompagné d'un build ID.
Notez bien le tag utilisé : il servira à la création du service Cloud Run dans la section suivante.
Notes de sécurité
Dans les deux sections qui suivent, j'utilise certaines options qui ne constituent PAS de bonnes pratiques pour un environnement de production. La sécurisation de l'environnement dépasse largement le cadre de cet article. Je me contente ici de présenter une configuration que vous pouvez reproduire pour découvrir et tester ces services dans un cadre maîtrisé ; commencez donc par exécuter cet exemple dans un projet GCP isolé et hors production.
Premièrement, j'utilise le compte de service par défaut, à savoir le compte de service par défaut Compute Engine, lors de la création des ressources. Je recommande fortement d'éviter cette approche en production. La bonne pratique consiste à créer un compte de service dédié auquel s'applique le principe du moindre privilège.
Deuxièmement, je m'appuie sur des variables d'environnement pour stocker les données d'exécution, par souci de simplicité. En production, il y a fort à parier que des données sensibles transiteront par le service Cloud Run. Pour un workload de production, je recommande vivement d'utiliser une méthode de stockage plus sûre, par exemple le Secret Manager de GCP ou Vault de HashiCorp.
Création du service Cloud Run — vue d'ensemble
Je passe ici par la ligne de commande pour créer le service Cloud Run, car Eventarc est un service récent dont l'interface évolue très rapidement : il est très probable qu'une capture d'écran ne reflète plus l'interface réelle un mois ou deux après la rédaction de cet article.
Cela dit, comme il s'agit d'un service récent, la ligne de commande peut elle aussi évoluer sans préavis au fil de l'ajout de nouvelles fonctionnalités, mais elle change historiquement bien moins souvent que l'interface graphique.
Toutes ces commandes sont à exécuter depuis Cloud Shell dans la console Google Cloud, sauf si vous préférez votre propre terminal. Dans les deux cas, assurez-vous d'avoir installé la dernière version de la CLI du SDK Google Cloud, car la plupart des commandes ci-dessous ne sont disponibles que dans les versions les plus récentes au moment de la rédaction. Pour cela, exécutez la commande suivante et répondez oui à l'invite de mise à jour :
gcloud components update
Création des variables d'environnement
La première étape consiste à définir des variables d'environnement utilisées par les commandes de création ci-dessous. Comme Eventarc et Cloud Run emploient des définitions et des formats de noms de région différents, je les ai séparées en deux variables distinctes.
Voici un récapitulatif rapide de chaque variable :
TAG_NAME : tag de l'image de conteneur indiqué dans la commande Cloud Build précédente
CLOUD_RUN_SERVICE : nom du service Cloud Run créé
CLOUD_RUN_REGION : région dans laquelle le service Cloud Run s'exécutera
BUCKET_NAME : nom du bucket GCS surveillé
BQ_TABLE : nom complet de la table BigQuery, projet et dataset compris (c'est-à-dire project.dataset.table). Cette valeur DOIT respecter ce format, faute de quoi une erreur sera levée.
TRIGGER_NAME : nom du trigger Eventarc.
TRIGGER_LOCATION : région Google Cloud dans laquelle le trigger surveillera le bucket. Si vous utilisez un bucket multi-régional et souhaitez le surveiller intégralement, indiquez plutôt la chaîne global.
Renseignez vos valeurs et exécutez les commandes suivantes :
TAG_NAME=<tag>
CLOUD_RUN_SERVICE=<service name>
CLOUD_RUN_REGION=<region>
BUCKET_NAME=<bucket name>
BQ_TABLE=<BigQuery full table name>
TRIGGER_NAME=<trigger name>
TRIGGER_LOCATON=<global or region># These next two variables rely on the above to be set
PROJECT=$(gcloud config get-value project)
IMAGE=gcr.io/"$PROJECT"/"$TAG_NAME":latest
Création du service Cloud Run
Pour créer le service Cloud Run à proprement parler, exécutez la commande suivante :
gcloud run deploy $CLOUD_RUN_SERVICE \
--region="$CLOUD_RUN_REGION"
--tag "$IMAGE" \
--platform managed \
--set-env-vars=BUCKET="$BUCKET",BIGQUERY_TABLE="$BQ_TABLE"
L'opération peut prendre jusqu'à 5 minutes avec l'image minimaliste fournie sur GitHub.
Une fois le service Cloud Run créé, créez ensuite le trigger Eventarc qui s'y rattache :
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com
Remarque : à l'avenir, lorsque le ciblage de ressources spécifiques sera disponible, c'est plutôt la commande suivante qu'il faudra utiliser :
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com \
--matching-criteria resourceName=projects/_/buckets/"$BUCKET_NAME"
Note de sécurité : comme indiqué plus haut, j'utilise ici le compte de service par défaut Compute Engine, à la fois pour le service Cloud Run et pour la création du trigger Eventarc, par souci de simplicité (c'est la valeur par défaut). Pour modifier ce comportement en production, utilisez l'option service-account sur les commandes gcloud run et gcloud eventarc. Pour en savoir plus à ce sujet et sur les autres options disponibles, exécutez les commandes suivantes :
gcloud run deploy --help
gcloud eventarc triggers create --help
Tester la configuration
Cette étape est très simple. J'ai même inclus un fichier CSV de test très basique pour l'occasion.
Remarque : si vous utilisez mon fichier d'exemple, vérifiez que la table indiquée dans votre variable d'environnement n'existe pas déjà dans BigQuery. Sinon, le job de chargement risque d'échouer car les schémas ne correspondront vraisemblablement pas.
Dans Cloud Shell (ou votre terminal), placez-vous (cd) dans le répertoire eventarc où le code GitHub a été récupéré, puis exécutez la commande suivante :
gsutil cp sample-bq-load.csv gs://"$BUCKET"/
Le fichier sera copié dans votre bucket et devrait déclencher le trigger ainsi que l'ensemble du processus.
Vérifier le résultat
Sur la page du service Cloud Run, cliquez sur l'onglet Triggers et recherchez celui que vous avez créé : environ 20 secondes après l'exécution de la commande, un graphique présentant des invocations devrait apparaître, comme ci-dessous.
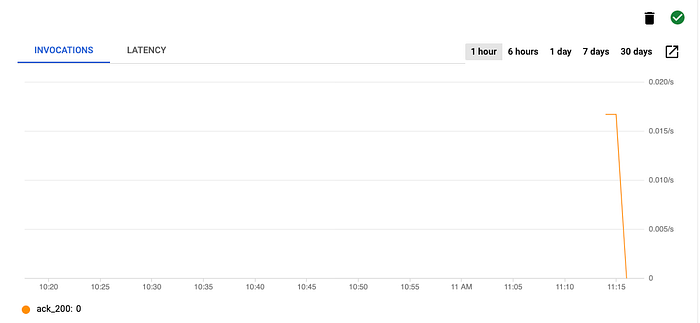
Invocations du trigger Eventarc
Rendez-vous ensuite dans la section BigQuery de votre console GCP, puis dans le projet et le dataset concernés : l'onglet Preview doit afficher les données insérées comme ci-dessous, à partir des données d'exemple. Vous pouvez aussi consulter l'onglet Details pour voir la date de dernière modification de votre table, qui doit correspondre à la dernière exécution du trigger visible sur le graphique.
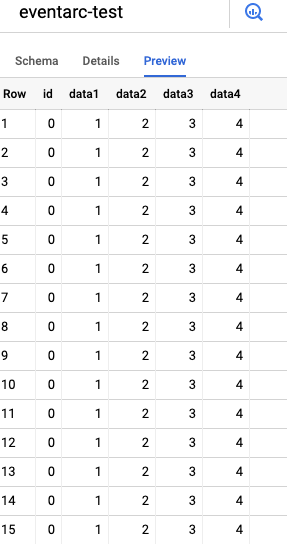
Données chargées depuis le fichier CSV d'exemple
Pensez bien à supprimer cette table après vos tests et avant de l'utiliser avec des données réelles !
En cas d'erreur
Si les données n'apparaissent pas, ouvrez votre service Cloud Run et cliquez sur l'onglet Logs.
Si une entrée d'erreur POST 500 apparaît dans les journaux, examinez les lignes alentour pour repérer d'éventuelles erreurs. La plupart ressembleront à ERROR in app: Exception on / [POST], suivi d'un Traceback du code Python dans l'entrée de log suivante. C'est généralement là que figure l'erreur survenue.
Si vous voyez plutôt une entrée POST 200 sans que les données soient chargées dans BigQuery, cherchez la cause dans les journaux. Le code affiche un message si le fichier n'est pas un CSV ou si une variable d'environnement est mal définie.