Use o CloudRun e o Eventarc para monitorar e automatizar ações nos seus projetos do GCP.
No fim do ano passado, o Google anunciou de forma bem discreta um novo serviço chamado Eventarc. A descrição é de uma funcionalidade de disparo de eventos nativa do Google Cloud Platform, baseada em CloudEvents. É bem parecida com o CloudWatch Events da AWS.

Decolagem!
O serviço entrou em GA poucos dias antes da publicação deste artigo. É um recurso bastante poderoso, mas ainda pouco conhecido. O Eventarc tem grande potencial para empresas que querem automatizar mais processos ou que precisam de um monitoramento mais detalhado dos seus recursos.
Como ainda é um serviço pouco explorado, resolvi ir além do quickstart oficial e mostrar como usá-lo na prática, com um exemplo que evidencia o que dá para fazer.
Visão geral do serviço
O quickstart do Google sobre o tema recebe eventos do Cloud Storage, um serviço bem prático para notificar quando os dados mudam e muito usado pelas Cloud Functions para executar algo quando um objeto é criado, atualizado, excluído etc. Também é um ótimo ponto de partida para quem quer usar o Eventarc.
Para ir além do quickstart do Google, vou adicionar uma funcionalidade que carrega automaticamente no BigQuery os arquivos criados em um bucket do GCS — uma necessidade muito comum entre os clientes que atendemos aqui na DoiT International.
O serviço apresentado neste artigo é disparado pela criação de um novo arquivo CSV em um bucket do GCS e executa um job de carga desse arquivo em uma tabela do BigQuery.
Observação: o Eventarc ainda é um produto novo, recém-saído do beta, então algumas funcionalidades ainda estão em falta — a principal delas é a possibilidade de mirar recursos específicos. Por isso, o código disparado precisa verificar se aquele é o recurso correto, e é isso que faço no código deste artigo.
**Construindo a imagem**
O primeiro passo é clonar um repositório com o código que escrevi para este artigo e enviá-lo ao Cloud Build, que vai criar uma imagem de container para o Cloud Run.
Primeiro, abra o Cloud Shell no seu Console do GCP. Garanta que ele está apontando para o projeto desejado executando o comando abaixo e substituindo
gcloud config set project <project id>
Com o projeto correto definido, execute o comando a seguir para clonar o repositório git:
git clone https://github.com/sayle-doit/eventarc-blog.git
cd eventarc-blog
Depois de clonar, vale dar uma olhada no código — em especial nos arquivos Dockerfile e main.py — só para entender o que ele faz.
Em seguida, é hora de construir uma imagem de container a partir desse Dockerfile. Execute o comando abaixo no Cloud Shell, substituindo
gcloud builds submit --tag gcr.io/<project id>/<tag>
O build leva de 30 a 60 segundos e retorna uma mensagem de sucesso com um build ID.
Anote a tag usada, porque ela será necessária na criação do serviço do Cloud Run na próxima seção.
Notas de segurança
Nas duas próximas seções, vou usar algumas opções que NÃO são boas práticas para um ambiente de produção. Proteger o ambiente vai muito além do escopo deste artigo. Aqui, mostro apenas uma configuração que você pode reproduzir para aprender e testar os serviços em um ambiente controlado, então rode tudo isso em um projeto GCP isolado e fora de produção.
Primeiro, vou usar a service account padrão, a Compute Engine default service account, ao criar os recursos. Recomendo fortemente não fazer isso em produção. Como boa prática, crie uma service account específica e aplique o princípio do menor privilégio a ela ao criar esses serviços.
Em segundo lugar, estou usando variáveis de ambiente para guardar dados de runtime, por uma questão de simplicidade. Em produção, é bem provável que existam dados sensíveis usados pelo serviço do Cloud Run. Para um workload de produção, recomendo fortemente um método mais seguro de armazenamento, como o Secret Manager do GCP ou o Vault da HashiCorp.
Visão geral da criação do serviço Cloud Run
Vou usar a linha de comando para criar o serviço do Cloud Run aqui porque o Eventarc é um serviço novo e a UI dele está mudando muito rápido — qualquer screenshot tem grande chance de ficar desatualizado em um ou dois meses.
Dito isso, como o serviço é novo, coisas também podem mudar na linha de comando sem aviso, à medida que novos recursos são adicionados. Mas, historicamente, a CLI muda bem menos do que a UI.
Tudo será executado dentro do Cloud Shell no console do Google Cloud, a menos que você prefira usar o seu próprio terminal. Em ambos os casos, garanta que está com a versão mais recente da CLI do Google Cloud SDK instalada, já que a maior parte dos comandos abaixo só existe nas versões mais novas até o momento da publicação. Para isso, execute o comando abaixo e responda "sim" quando solicitado a atualizar:
gcloud components update
Criando variáveis de ambiente
O primeiro passo é criar algumas variáveis de ambiente que serão usadas pelos comandos de criação a seguir. Como o Eventarc e o Cloud Run usam definições e formatos diferentes para nomes de regiões, separei isso em duas variáveis distintas.
Resumo rápido de cada variável:
TAG_NAME: tag da imagem de container que você definiu no comando do Cloud Build anteriormente
CLOUD_RUN_SERVICE: nome do serviço do Cloud Run criado
CLOUD_RUN_REGION: região onde o serviço do Cloud Run será executado
BUCKET_NAME: nome do bucket do GCS que será monitorado
BQ_TABLE: nome completo da tabela do BigQuery, incluindo projeto e dataset (ou seja, project.dataset.table). Esse valor OBRIGATORIAMENTE precisa estar nesse formato, senão dará erro.
TRIGGER_NAME: nome do trigger do Eventarc.
TRIGGER_LOCATION: região do Google Cloud em que o trigger vai monitorar o bucket. Se você estiver usando um bucket multirregional e quiser monitorá-lo por completo, use a string global aqui.
Substitua pelos seus valores e execute os comandos abaixo:
TAG_NAME=<tag>
CLOUD_RUN_SERVICE=<service name>
CLOUD_RUN_REGION=<region>
BUCKET_NAME=<bucket name>
BQ_TABLE=<BigQuery full table name>
TRIGGER_NAME=<trigger name>
TRIGGER_LOCATON=<global or region># These next two variables rely on the above to be set
PROJECT=$(gcloud config get-value project)
IMAGE=gcr.io/"$PROJECT"/"$TAG_NAME":latest
Criando o serviço do Cloud Run
Agora, para criar o serviço do Cloud Run propriamente dito, execute o comando a seguir:
gcloud run deploy $CLOUD_RUN_SERVICE \
--region="$CLOUD_RUN_REGION"
--tag "$IMAGE" \
--platform managed \
--set-env-vars=BUCKET="$BUCKET",BIGQUERY_TABLE="$BQ_TABLE"
Isso pode levar até 5 minutos usando a imagem mínima fornecida no GitHub.
Com o serviço do Cloud Run criado, é hora de criar o trigger do Eventarc que se conecta a ele:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com
Observação: no futuro, quando a funcionalidade de recursos específicos for implementada, o comando a seguir deverá ser usado no lugar:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com \
--matching-criteria resourceName=projects/_/buckets/"$BUCKET_NAME"
Nota de segurança: como mencionei acima, estou usando a Compute Engine default service account tanto na criação do serviço do Cloud Run quanto na do trigger do Eventarc por uma questão de simplicidade, já que é o padrão. Para mudar isso em produção, use a flag service-account nos comandos gcloud run e gcloud eventarc. Para saber mais sobre essa e outras opções que podem ser úteis, execute os seguintes comandos:
gcloud run deploy --help
gcloud eventarc triggers create --help
Testando a configuração
Esta é a parte fácil. Inclusive, deixei um arquivo CSV de teste bem simples para você usar.
Observação: se for usar o meu arquivo de exemplo, garanta que a tabela definida na sua variável de ambiente ainda não existe no BigQuery. Caso contrário, pode rolar erro no job de carga, porque os schemas provavelmente não vão coincidir.
No seu Cloud Shell (ou terminal), entre no diretório eventarc onde o código do GitHub foi baixado. Em seguida, execute o comando a seguir:
gsutil cp sample-bq-load.csv gs://"$BUCKET"/
Isso vai copiar o arquivo para o seu bucket e deve disparar o trigger e todo o processo.
Verificando o resultado
Na página do serviço do Cloud Run, clique na aba Triggers e procure pelo trigger que você criou. Cerca de 20 segundos depois de executar o comando, você já deve ver um gráfico com algumas invocações, parecido com o do exemplo abaixo.
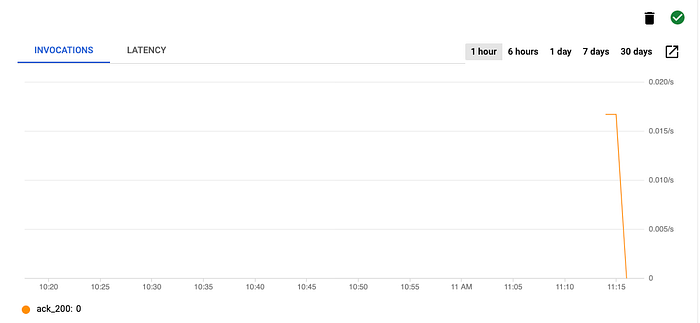
Invocações do trigger do Eventarc
Indo até a seção do BigQuery no Console do GCP e navegando até o projeto e o dataset, na aba Preview deve aparecer o dado inserido, como no exemplo abaixo com os dados de amostra. Você também pode olhar a aba Details e ver a data da última modificação da tabela, que deve coincidir com a última execução do trigger no seu gráfico.
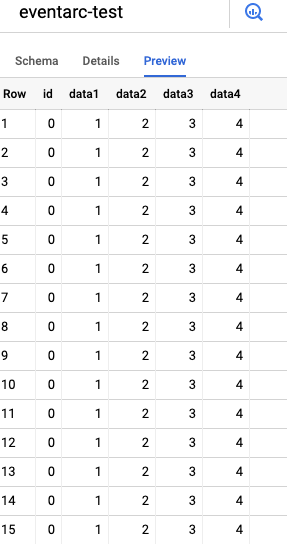
Dados carregados a partir do arquivo CSV de exemplo
Não esqueça de excluir essa tabela depois de testar com esses dados e antes de usar dados reais!
Em caso de erro
Se os dados não aparecerem, vá até o seu serviço do Cloud Run e clique na aba Logs.
Se aparecer um registro de erro POST 500 nos logs, olhe ao redor para ver se há linhas de erro. A maioria delas traz algo como ERROR in app: Exception on / [POST], seguido por um Traceback do código Python no próximo registro de log. Em geral, é aí que está o erro que ocorreu.
Se aparecer um registro POST 200, mas os dados não estão indo para o BigQuery, procure o motivo nos logs. O código exibe uma mensagem caso o arquivo não seja um CSV ou alguma variável de ambiente esteja configurada incorretamente.