CloudRunとEventarcを活用して、GCPプロジェクトの監視と自動化を実現する方法を解説します。
昨年末、GoogleはEventarcという新サービスをひっそりと発表しました。CloudEventsをベースに、Google Cloud Platformへ組み込まれたイベントトリガー機能と位置づけられており、AWSのCloudWatch Eventsによく似た機能です。

Blast Off!
本記事の公開直前にGAとなったばかりで、まだあまり知られていませんが、非常に強力な機能です。Eventarcは、自動化を進めたい組織やリソース監視を強化したい組織にとって大きな可能性を秘めています。
まだ認知度の低いサービスですので、Googleのクイックスタートをさらに発展させ、実用的な例を交えてこのサービスで何ができるのかをご紹介します。
サービスの概要
Googleのクイックスタートでは、Cloud Storageイベントを受け取る例が紹介されています。Cloud Storageはデータ変更時に通知を行ってくれる便利なサービスで、Cloud Functionsからオブジェクトの作成・更新・削除などのタイミングで処理を実行する用途でよく使われます。Eventarcを試す出発点としても最適です。
本記事ではGoogleのクイックスタートをさらに一歩進め、GCSバケットに作成されたファイルをBigQueryへ自動的にロードする機能を追加します。これはDoiT Internationalでもよくいただくご要望です。
本記事で扱うサービスは、GCSバケットに新しいCSVファイルが作成されたタイミングでトリガーされ、そのファイルをBigQueryテーブルへロードするジョブを実行します。
注: Eventarcはベータ版を出たばかりの新しいプロダクトのため、まだ機能面で不足している部分があります。最も大きな制約は、特定のリソースをターゲットに指定できない点です。そのため、トリガーされたコード側で対象のリソースかどうかを判定する必要があり、本記事のコードでもその処理を実装しています。
**イメージのビルド**
最初のステップは、本記事用に用意したコードを含むリポジトリをクローンし、Cloud Buildへ送信してCloud Run用のコンテナイメージを作成することです。
まず、GCPコンソール内でCloud Shellを開きます。次のコマンドを実行し、
gcloud config set project <project id>
正しいプロジェクトが設定できたら、次のコマンドでgitリポジトリをクローンします:
git clone https://github.com/sayle-doit/eventarc-blog.git
cd eventarc-blog
クローンが完了したら、コードの内容、特にDockerfileとmain.pyに目を通して、何を行っているか確認しておくことをおすすめします。
続いて、このDockerfileからコンテナイメージをビルドします。Cloud Shellで次のコマンドを実行し、
gcloud builds submit --tag gcr.io/<project id>/<tag>
ビルドには30〜60秒ほどかかり、成功するとビルドIDを含むメッセージが返ってきます。
使用したタグは次のセクションでCloud Runサービスを作成する際に使うので、控えておいてください。
セキュリティに関する注意事項
続く2つのセクションでは、本番環境では推奨されないオプションをいくつか使用します。環境のセキュリティ強化は本記事の対象範囲を大きく超えるためです。本記事はあくまで管理された環境で再現・学習・検証していただくためのセットアップを示すものですので、まずは本番環境とは隔離されたGCPプロジェクトで実行してください。
まず、リソース作成時にデフォルトのサービスアカウントであるCompute Engine default service accountを使用します。本番環境ではこの方法を使わないことを強く推奨します。ベストプラクティスとしては、これらのサービスを作成する際に最小権限の原則を適用した専用のサービスアカウントを用意するべきです。
次に、簡略化のためにランタイムデータの保存に環境変数を使用しています。本番環境ではCloud Runサービスが機密データを扱う可能性が高いため、本番ワークロードでは、GCPのSecret ManagerやHashiCorpのVaultといった、よりセキュアな方法でデータを保管することを強くおすすめします。
Cloud Runサービスの作成 — 概要
EventarcはリリースされたばかりでUIが急速に変化しており、スクリーンショットを掲載しても1〜2か月後には実際の画面と一致しない可能性が高いため、ここではコマンドラインでCloud Runサービスを作成します。
新しいサービスである以上、機能追加に伴ってコマンドラインも予告なく変わることはあり得ますが、これまでの傾向としてUIに比べてコマンドラインの変更頻度ははるかに低いです。
以下のコマンドはすべてGoogle Cloudコンソール内のCloud Shellで実行する想定ですが、ご自身のターミナルで実行しても問題ありません。いずれの場合も、本記事執筆時点で最新版にしか含まれていないコマンドが多いため、最新バージョンのGoogle Cloud SDK CLIがインストールされていることを確認してください。次のコマンドを実行し、更新を求められたら「yes」を選択します:
gcloud components update
環境変数の作成
最初に、後続の作成コマンドで使用する環境変数をいくつか設定します。EventarcとCloud Runではリージョン名の定義や形式が異なるため、それぞれ別の変数に分けています。
各変数の概要は次のとおりです:
TAG_NAME: 先ほどのCloud Build submitコマンドで指定したコンテナイメージのタグ
CLOUD_RUN_SERVICE: 作成するCloud Runサービスのサービス名
CLOUD_RUN_REGION: Cloud Runサービスを動作させるリージョン
BUCKET_NAME: 監視対象となるGCSバケット名
BQ_TABLE: プロジェクトとデータセットを含む完全なBigQueryテーブル名(例: project.dataset.table)。この値は必ずこの形式である必要があり、そうでないとエラーになります。
TRIGGER_NAME: Eventarcトリガーの名前。
TRIGGER_LOCATION: トリガーがバケットを監視するGoogle Cloudリージョン。マルチリージョンのバケット全体を監視したい場合は、ここに文字列「global」を指定してください。
各値を置き換えて、次のコマンドを実行します:
TAG_NAME=<tag>
CLOUD_RUN_SERVICE=<service name>
CLOUD_RUN_REGION=<region>
BUCKET_NAME=<bucket name>
BQ_TABLE=<BigQuery full table name>
TRIGGER_NAME=<trigger name>
TRIGGER_LOCATON=<global or region># These next two variables rely on the above to be set
PROJECT=$(gcloud config get-value project)
IMAGE=gcr.io/"$PROJECT"/"$TAG_NAME":latest
Cloud Runサービスの作成
それでは、実際にCloud Runサービスを作成します。次のコマンドを実行してください:
gcloud run deploy $CLOUD_RUN_SERVICE \
--region="$CLOUD_RUN_REGION"
--tag "$IMAGE" \
--platform managed \
--set-env-vars=BUCKET="$BUCKET",BIGQUERY_TABLE="$BQ_TABLE"
GitHubで提供している最小構成のイメージでは、最大5分程度かかることがあります。
Cloud Runサービスが作成できたら、次にそれに紐づくEventarcトリガーを作成します:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com
注: 将来、特定リソースを指定する機能が実装された際には、代わりに次のコマンドを使用してください:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com \
--matching-criteria resourceName=projects/_/buckets/"$BUCKET_NAME"
セキュリティに関する注意: 前述のとおり、ここでは簡略化のため、Cloud RunサービスとEventarcトリガーの両方の作成時に、デフォルトとなるCompute Engine default service accountをそのまま使用しています。本番環境では、gcloud runとgcloud eventarcの両コマンドでservice-accountフラグを指定して変更してください。これらや、その他指定したい引数について詳しく知りたい場合は、次のコマンドを実行してください:
gcloud run deploy --help
gcloud eventarc triggers create --help
セットアップのテスト
ここはとてもシンプルです。テスト用のシンプルなCSVファイルもあらかじめ用意してあります。
注: サンプルファイルを使う場合は、環境変数で指定したテーブルがBigQuery上にまだ存在していないことを確認してください。スキーマが一致せず、ロードジョブのエラーが発生する可能性が高いためです。
Cloud Shell(またはターミナル)で、GitHubのコードをチェックアウトしたeventarcディレクトリに移動し、次のコマンドを実行します:
gsutil cp sample-bq-load.csv gs://"$BUCKET"/
これでファイルがバケットへコピーされ、トリガーと一連の処理が起動するはずです。
結果の確認
Cloud RunサービスのページでTriggersタブをクリックし、作成したトリガーを開いてみてください。コマンド実行から約20秒後に、以下のような呼び出し回数を示すグラフが表示されるはずです。
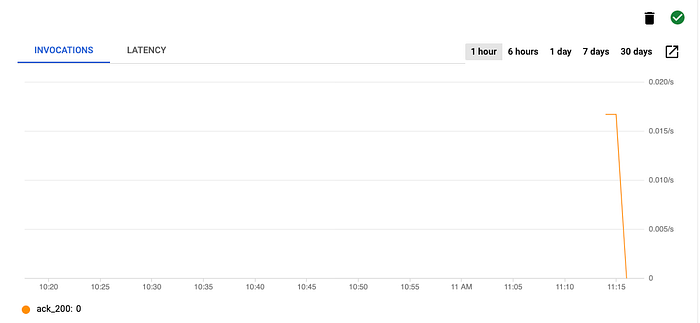
Eventarcトリガーの呼び出し
続いてGCPコンソールのBigQueryセクションへ移動し、対象のプロジェクトとデータセットを開きます。Previewタブを見ると、サンプルデータの場合は以下のようにデータが挿入されているはずです。Detailsタブからはテーブルの最終更新日時も確認でき、グラフ上の最後のトリガー実行タイミングと一致しているはずです。
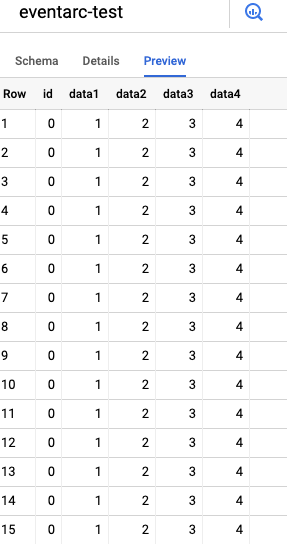
サンプルCSVファイルから読み込まれたデータ
このデータでテストしたあとは、実データを使用する前に必ずこのテーブルを削除してください!
エラーが発生した場合
データが反映されない場合は、Cloud Runサービスへ移動し、Logsタブをクリックします。
ログ内にPOST 500のエラーレコードが見つかった場合は、その前後にエラー行がないか確認してください。多くの場合、ERROR in app: Exception on / [POST]といった内容に続いて、次のログレコードにPythonコードのTracebackが表示されます。ここに発生したエラーの内容が含まれているのが一般的です。
POST 200レコードが表示されているのにBigQueryへデータがロードされない場合は、ログでその原因を確認してください。ファイルがCSVでない場合や環境変数の設定が誤っている場合には、コードがメッセージを出力するようになっています。