Usa CloudRun ed Eventarc per monitorare e automatizzare le azioni sui tuoi progetti GCP.
Verso la fine dell'anno scorso Google ha annunciato in sordina un nuovo servizio chiamato Eventarc, descritto come una funzionalità di event-triggering integrata in Google Cloud Platform e basata su CloudEvents. È molto simile a CloudWatch Events di AWS.

Blast Off!
È diventato GA solo pochi giorni prima della pubblicazione di questo articolo: una funzionalità molto potente, ma ancora poco conosciuta. Eventarc offre grandi potenzialità a chi vuole spingere l'automazione o ha bisogno di un monitoraggio più puntuale delle proprie risorse.
Trattandosi di un servizio ancora poco diffuso, ho voluto andare oltre la guida rapida ufficiale e mostrare come usarlo con un esempio pratico, per evidenziarne le possibilità.
Una panoramica del servizio
La guida rapida di Google riceve eventi da Cloud Storage, un servizio molto utile per notificare le modifiche ai dati e usato spesso dalle Cloud Functions per eseguire operazioni alla creazione, all'aggiornamento o all'eliminazione di un oggetto. È inoltre un ottimo punto di partenza per iniziare a usare Eventarc.
Per ampliare la guida rapida di Google, aggiungo la possibilità di caricare automaticamente in BigQuery i file creati in un bucket GCS: una richiesta molto frequente che riceviamo qui in DoiT International.
Il servizio illustrato in questo articolo si attiva alla creazione di un nuovo file CSV all'interno di un bucket GCS ed esegue un job di caricamento di quel file in una tabella BigQuery.
Nota: Eventarc è un prodotto ancora giovane, appena uscito dalla beta, quindi presenta alcune funzionalità mancanti, la più rilevante delle quali è il targeting di risorse specifiche. Per questo motivo il codice attivato deve verificare se la risorsa è quella corretta: un controllo che ho implementato nel codice di questo articolo.
**Costruire l'immagine**
Il primo passo è clonare un repository contenente il codice che ho scritto per questo articolo, per poi inviarlo a Cloud Build e ottenere un'immagine container da utilizzare con Cloud Run.
Per prima cosa, apri Cloud Shell dalla tua GCP Console. Assicurati che sia impostata sul progetto che intendi utilizzare eseguendo il comando seguente e sostituendo il tuo project ID al posto di
gcloud config set project <project id>
Una volta impostato il progetto corretto, esegui il comando seguente per clonare il repository git:
git clone https://github.com/sayle-doit/eventarc-blog.git
cd eventarc-blog
Al termine della clonazione, ti consiglio di dare un'occhiata al codice — in particolare ai file Dockerfile e main.py — per capire cosa fa.
A questo punto va creata un'immagine container a partire da questo Dockerfile. Esegui il comando seguente in Cloud Shell sostituendo il tuo project ID al posto di
gcloud builds submit --tag gcr.io/<project id>/<tag>
La build dovrebbe richiedere circa 30–60 secondi e restituire un messaggio di successo con un build ID.
Prendi nota del tag utilizzato: ti servirà per la creazione del servizio Cloud Run nella sezione successiva.
Note sulla sicurezza
Nelle prossime due sezioni utilizzerò alcune opzioni che NON rappresentano una best practice per un ambiente di produzione. La messa in sicurezza dell'ambiente esula dallo scopo di questo articolo: qui mi limito a mostrare una configurazione che puoi ricreare per imparare e testare i servizi in un ambiente controllato, quindi all'inizio ti consiglio di eseguirla in un progetto GCP isolato e non di produzione.
Anzitutto, durante la creazione delle risorse utilizzerò il service account predefinito, ovvero il Compute Engine default service account. Sconsiglio vivamente di adottare questo approccio in un ambiente di produzione: come best practice, è opportuno creare un service account dedicato applicando il principio del minimo privilegio.
In secondo luogo, per semplicità memorizzo i dati di runtime in variabili d'ambiente. In un ambiente di produzione è molto probabile che il servizio Cloud Run gestisca dati sensibili: per i workloads di produzione consiglio caldamente di adottare un metodo di archiviazione più sicuro, come il Secret Manager di GCP o Vault di HashiCorp.
Panoramica della creazione del servizio Cloud Run
Qui utilizzo la riga di comando per creare il servizio Cloud Run perché Eventarc è un servizio nuovo e la sua interfaccia utente sta cambiando molto rapidamente: è altamente probabile che eventuali screenshot non rispecchino come si presenterà a uno o due mesi dalla pubblicazione.
Detto questo, trattandosi di un servizio nuovo, anche la riga di comando potrebbe cambiare senza preavviso man mano che vengono aggiunte nuove funzionalità, ma storicamente cambia molto meno spesso rispetto alla UI.
Tutti i comandi seguenti vanno eseguiti in Cloud Shell dalla console di Google Cloud, a meno che tu non preferisca usare il tuo terminale. In entrambi i casi, assicurati di avere installata l'ultima versione della Google Cloud SDK CLI, dato che la maggior parte dei comandi qui sotto è disponibile solo nelle versioni più recenti al momento della scrittura. Per aggiornarla, esegui questo comando e seleziona "sì" alla richiesta di aggiornamento:
gcloud components update
Creazione delle variabili d'ambiente
Il primo passo consiste nel creare alcune variabili d'ambiente da utilizzare nei comandi di creazione qui sotto. Poiché Eventarc e Cloud Run usano definizioni e formati diversi per i nomi delle region, le ho separate in due variabili distinte.
Ecco un riepilogo rapido di ciascuna variabile:
TAG_NAME: tag dell'immagine container specificato in precedenza nel comando Cloud Build submit
CLOUD_RUN_SERVICE: nome del servizio Cloud Run creato
CLOUD_RUN_REGION: region in cui verrà eseguito il servizio Cloud Run
BUCKET_NAME: nome del bucket GCS da monitorare
BQ_TABLE: nome completo della tabella BigQuery, comprensivo di progetto e dataset (es. project.dataset.table). Attenzione: questo valore DEVE rispettare questo formato, altrimenti il comando restituirà un errore.
TRIGGER_NAME: nome del trigger Eventarc.
TRIGGER_LOCATION: region di Google Cloud in cui il trigger monitorerà il bucket. Se utilizzi un bucket multi-regional e vuoi monitorarlo per intero, inserisci qui la stringa global.
Sostituisci i tuoi valori ed esegui i comandi seguenti:
TAG_NAME=<tag>
CLOUD_RUN_SERVICE=<service name>
CLOUD_RUN_REGION=<region>
BUCKET_NAME=<bucket name>
BQ_TABLE=<BigQuery full table name>
TRIGGER_NAME=<trigger name>
TRIGGER_LOCATON=<global or region># These next two variables rely on the above to be set
PROJECT=$(gcloud config get-value project)
IMAGE=gcr.io/"$PROJECT"/"$TAG_NAME":latest
Creazione del servizio Cloud Run
A questo punto, per creare effettivamente il servizio Cloud Run, esegui il comando seguente:
gcloud run deploy $CLOUD_RUN_SERVICE \
--region="$CLOUD_RUN_REGION"
--tag "$IMAGE" \
--platform managed \
--set-env-vars=BUCKET="$BUCKET",BIGQUERY_TABLE="$BQ_TABLE"
L'esecuzione può richiedere fino a 5 minuti utilizzando l'immagine essenziale fornita su GitHub.
Una volta creato il servizio Cloud Run, crea il trigger Eventarc da collegarvi:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com
Nota: in futuro, quando verrà implementata la funzionalità per le risorse specifiche, dovrà essere usato il comando seguente:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com \
--matching-criteria resourceName=projects/_/buckets/"$BUCKET_NAME"
Nota sulla sicurezza: come accennato sopra, per semplicità sto utilizzando il Compute Engine default service account sia per il servizio Cloud Run sia per la creazione del trigger Eventarc, dato che è il valore predefinito. Per modificarlo in un ambiente di produzione, usa il flag service-account sia con il comando gcloud run sia con gcloud eventarc. Per approfondire questo e altri parametri che potrebbero esserti utili, esegui i comandi seguenti:
gcloud run deploy --help
gcloud eventarc triggers create --help
Test della configurazione
Questa è la parte più semplice. Ho persino incluso un file CSV di test molto basilare da usare per la prova.
Nota: se utilizzi il mio file di esempio, assicurati che la tabella indicata nella variabile d'ambiente non esista già in BigQuery. In caso contrario, il job di caricamento potrebbe restituire un errore, perché molto probabilmente gli schemi non corrisponderanno.
Nella tua Cloud Shell (o terminale) spostati con cd nella directory eventarc in cui hai scaricato il codice da GitHub. Poi esegui il comando seguente:
gsutil cp sample-bq-load.csv gs://"$BUCKET"/
Il comando copierà il file nel tuo bucket e dovrebbe avviare il trigger e l'intero processo.
Verificare il risultato
Nella pagina del servizio Cloud Run, cliccando sulla scheda Triggers e cercando il trigger appena creato, circa 20 secondi dopo aver eseguito il comando dovresti vedere un grafico con alcune invocazioni come quello qui sotto.
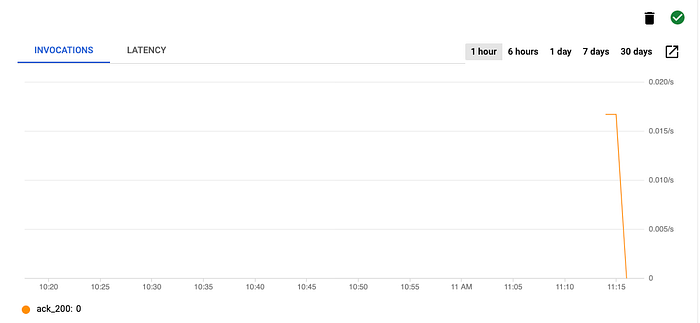
Invocazioni del trigger Eventarc
Se accedi alla sezione BigQuery della tua GCP Console e navighi fino al progetto e al dataset, nella scheda Preview dovresti vedere i dati inseriti come nell'esempio qui sotto, generati a partire dai dati di esempio. Puoi anche consultare la scheda Details per vedere la data dell'ultima modifica della tabella, che dovrebbe corrispondere all'ultima esecuzione del trigger riportata nel grafico.
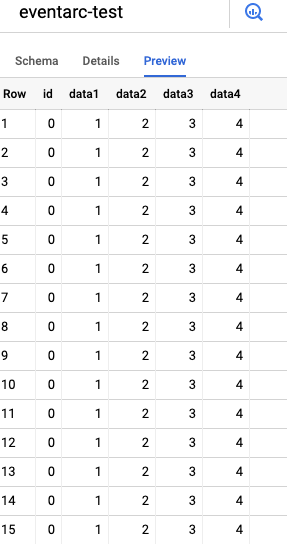
Dati caricati dal file CSV di esempio
Ricordati di eliminare questa tabella dopo aver fatto i test con questi dati e prima di passare a dati reali!
In caso di errore
Se i dati non compaiono, accedi al tuo servizio Cloud Run e clicca sulla scheda Logs.
Se nei log vedi un record di errore POST 500, controlla nelle vicinanze per individuare eventuali righe di errore. Nella maggior parte dei casi conterranno qualcosa come ERROR in app: Exception on / [POST], seguito dal Traceback del codice Python nel record di log successivo. Di solito è qui che si trova l'errore verificatosi.
Se invece compare un record POST 200, ma i dati non vengono caricati in BigQuery, cerca nei log il motivo: il codice stampa un messaggio se il file non è un CSV o se una variabile d'ambiente è impostata in modo errato.