Mit CloudRun und Eventarc Aktionen in Ihren GCP-Projekten überwachen und automatisieren.
Ende letzten Jahres hat Google ganz leise einen neuen Dienst namens Eventarc vorgestellt. Beschrieben wird er als in die Google Cloud Platform integrierte Event-Trigger-Funktion auf Basis von CloudEvents – vergleichbar mit den CloudWatch Events von AWS.

Auf geht's!
Wenige Tage vor Veröffentlichung dieses Artikels wurde der Dienst als GA freigegeben. Es handelt sich um ein sehr leistungsfähiges Feature, das bislang kaum bekannt ist. Eventarc bietet enormes Potenzial für Unternehmen, die mehr automatisieren oder ihre Ressourcen umfassender überwachen wollen.
Da der Dienst noch weitgehend unbekannt ist, möchte ich den Quickstart von Google erweitern und an einem praktischen Beispiel zeigen, was damit möglich ist.
Der Dienst im Überblick
Googles Quickstart verarbeitet Cloud-Storage-Events – ein sehr praktischer Dienst, um über Datenänderungen zu informieren. Cloud Functions nutzen ihn häufig, um auf das Erstellen, Aktualisieren oder Löschen von Objekten zu reagieren. Außerdem eignet er sich hervorragend als Einstieg in Eventarc.
Als Erweiterung des Google-Quickstarts ergänze ich die Funktionalität, in einem GCS-Bucket erstellte Dateien automatisch nach BigQuery zu laden – eine Anforderung, die uns bei DoiT International sehr häufig begegnet.
Der in diesem Artikel verwendete Dienst wird durch das Anlegen einer neuen CSV-Datei in einem GCS-Bucket ausgelöst und führt einen Load-Job dieser Datei in eine BigQuery-Tabelle aus.
Hinweis: Eventarc ist ein junges Produkt direkt nach dem Beta-Stadium, daher fehlen noch einige Funktionen – am wichtigsten das gezielte Adressieren bestimmter Ressourcen. Der ausgelöste Code muss deshalb selbst prüfen, ob es sich um die richtige Ressource handelt. Genau das übernimmt der Code in diesem Artikel.
**Das Image bauen**
Im ersten Schritt klonen wir ein Repository mit dem Code, den ich für diesen Artikel geschrieben habe, und übergeben ihn anschließend an Cloud Build, um daraus ein Container-Image für Cloud Run zu erstellen.
Öffnen Sie zunächst die Cloud Shell in Ihrer GCP Console. Stellen Sie sicher, dass das gewünschte Projekt aktiv ist, indem Sie folgenden Befehl ausführen und Ihre Projekt-ID anstelle von
gcloud config set project <project id>
Sobald das richtige Projekt aktiv ist, klonen Sie das Git-Repository mit folgendem Befehl:
git clone https://github.com/sayle-doit/eventarc-blog.git
cd eventarc-blog
Nach dem Klonen empfehle ich, einen Blick in den Code zu werfen – insbesondere in die Dateien Dockerfile und main.py – um zu verstehen, was dort passiert.
Als Nächstes wird aus diesem Dockerfile ein Container-Image gebaut. Führen Sie folgenden Befehl in der Cloud Shell aus und ersetzen Sie
gcloud builds submit --tag gcr.io/<project id>/<tag>
Der Build dauert etwa 30–60 Sekunden und schließt mit einer Erfolgsmeldung samt Build-ID ab.
Notieren Sie sich das verwendete Tag – es wird im nächsten Abschnitt beim Anlegen des Cloud-Run-Dienstes benötigt.
Sicherheitshinweise
In den nächsten beiden Abschnitten verwende ich einige Optionen, die für eine Produktionsumgebung NICHT als Best Practice gelten. Die Absicherung der Umgebung würde den Rahmen dieses Artikels deutlich sprengen. Ich zeige hier lediglich ein Setup zum Nachbauen, mit dem Sie die Dienste in einer kontrollierten Umgebung kennenlernen und testen können – nutzen Sie dafür zunächst ein isoliertes, nicht produktives GCP-Projekt.
Erstens verwende ich beim Anlegen der Ressourcen den Standard-Service-Account, das Compute Engine default service account. Davon rate ich für Produktionsumgebungen dringend ab. Als Best Practice sollten Sie für diese Dienste einen eigenen Service-Account anlegen und das Prinzip der geringsten Berechtigung anwenden.
Zweitens speichere ich Laufzeitdaten der Einfachheit halber in Umgebungsvariablen. In einer Produktionsumgebung verarbeitet der Cloud-Run-Dienst sehr wahrscheinlich auch sensible Daten. Für produktive workloads empfehle ich daher dringend eine sicherere Speichermethode, etwa GCPs Secret Manager oder Vault von HashiCorp.
Cloud-Run-Dienst anlegen – Überblick
Ich nutze hier die Kommandozeile, um den Cloud-Run-Dienst anzulegen, denn Eventarc ist ein neuer Dienst und die zugehörige UI verändert sich rasant. Screenshots wären schon in ein bis zwei Monaten höchstwahrscheinlich überholt.
Da es sich um einen neuen Dienst handelt, kann sich allerdings auch auf der Kommandozeile etwas ohne Vorankündigung ändern, sobald weitere Features hinzukommen. Erfahrungsgemäß ändert sich die Kommandozeile aber deutlich seltener als die UI.
Alle folgenden Befehle führen Sie in Ihrer Cloud Shell innerhalb der Google Cloud Console aus – sofern Sie nicht Ihr eigenes Terminal nutzen möchten. Stellen Sie in beiden Fällen sicher, dass die neueste Version des Google Cloud SDK CLI installiert ist, da die meisten der untenstehenden Befehle zum Zeitpunkt des Schreibens nur in den aktuellsten Versionen verfügbar sind. Führen Sie dazu folgenden Befehl aus und bestätigen Sie das Update:
gcloud components update
Umgebungsvariablen anlegen
Im ersten Schritt legen wir einige Umgebungsvariablen an, die in den nachfolgenden Create-Befehlen zum Einsatz kommen. Da Eventarc und Cloud Run unterschiedliche Definitionen und Formate für Regionsnamen verwenden, habe ich diese auf zwei separate Variablen aufgeteilt.
Hier eine kurze Übersicht der einzelnen Variablen:
TAG_NAME: Container-Image-Tag, das Sie zuvor beim Cloud-Build-Submit-Befehl angegeben haben
CLOUD_RUN_SERVICE: Service-Name für den erstellten Cloud-Run-Dienst
CLOUD_RUN_REGION: Region, in der der Cloud-Run-Dienst läuft
BUCKET_NAME: Name des überwachten GCS-Buckets
BQ_TABLE: Vollständiger BigQuery-Tabellenname inklusive Projekt und Dataset (z. B. project.dataset.table). Dieser Wert MUSS in diesem Format vorliegen, sonst läuft der Befehl auf einen Fehler.
TRIGGER_NAME: Name des Eventarc-Triggers.
TRIGGER_LOCATION: Google-Cloud-Region, in der der Trigger den Bucket überwacht. Bei einem multiregionalen Bucket, der vollständig überwacht werden soll, tragen Sie hier stattdessen den String global ein.
Setzen Sie Ihre Werte ein und führen Sie folgende Befehle aus:
TAG_NAME=<tag>
CLOUD_RUN_SERVICE=<service name>
CLOUD_RUN_REGION=<region>
BUCKET_NAME=<bucket name>
BQ_TABLE=<BigQuery full table name>
TRIGGER_NAME=<trigger name>
TRIGGER_LOCATON=<global or region># These next two variables rely on the above to be set
PROJECT=$(gcloud config get-value project)
IMAGE=gcr.io/"$PROJECT"/"$TAG_NAME":latest
Cloud-Run-Dienst erstellen
Um den eigentlichen Cloud-Run-Dienst anzulegen, führen Sie folgenden Befehl aus:
gcloud run deploy $CLOUD_RUN_SERVICE \
--region="$CLOUD_RUN_REGION"
--tag "$IMAGE" \
--platform managed \
--set-env-vars=BUCKET="$BUCKET",BIGQUERY_TABLE="$BQ_TABLE"
Mit dem auf GitHub bereitgestellten Bare-Bones-Image kann das bis zu 5 Minuten dauern.
Sobald der Cloud-Run-Dienst erstellt ist, legen Sie als Nächstes den dazugehörigen Eventarc-Trigger an:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com
Hinweis: Sobald die Adressierung spezifischer Ressourcen verfügbar ist, sollte stattdessen folgender Befehl verwendet werden:
gcloud eventarc triggers create "$TRIGGER_NAME" \
--location="$TRIGGER_LOCATON" \
--destination-run-service "$CLOUD_RUN_SERVICE" \
--matching-criteria type=google.cloud.audit.log.v1.written \
--matching-criteria methodName=storage.objects.create \
--matching-criteria serviceName=storage.googleapis.com \
--matching-criteria resourceName=projects/_/buckets/"$BUCKET_NAME"
Sicherheitshinweis: Wie oben erwähnt, verwende ich hier sowohl beim Cloud-Run-Dienst als auch beim Anlegen des Eventarc-Triggers der Einfachheit halber das Compute Engine default service account, da es ohnehin als Standard hinterlegt ist. Für eine Produktionsumgebung passen Sie das über das Flag service-account bei den Befehlen gcloud run und gcloud eventarc an. Mehr zu diesem und weiteren Argumenten erfahren Sie über folgende Befehle:
gcloud run deploy --help
gcloud eventarc triggers create --help
Setup testen
Dieser Teil ist denkbar einfach. Ich habe sogar eine ganz schlichte Test-CSV-Datei zum Ausprobieren beigelegt.
Hinweis: Wenn Sie meine Beispieldatei verwenden, achten Sie darauf, dass die in Ihrer Umgebungsvariable angegebene Tabelle in BigQuery noch nicht existiert. Andernfalls kann es zu einem Load-Job-Fehler kommen, da die Schemas höchstwahrscheinlich nicht zusammenpassen.
Wechseln Sie in Ihrer Cloud Shell (oder Ihrem Terminal) in das Verzeichnis eventarc, in das der GitHub-Code ausgecheckt wurde. Führen Sie dann folgenden Befehl aus:
gsutil cp sample-bq-load.csv gs://"$BUCKET"/
Damit wird die Datei in Ihren Bucket hochgeladen und sollte den Trigger sowie den gesamten Prozess anstoßen.
Ergebnis prüfen
Öffnen Sie auf der Cloud-Run-Service-Seite den Tab Triggers und suchen Sie den von Ihnen erstellten Trigger. Etwa 20 Sekunden nach dem Befehl sollte ein Diagramm mit einigen Aufrufen erscheinen, wie unten dargestellt.
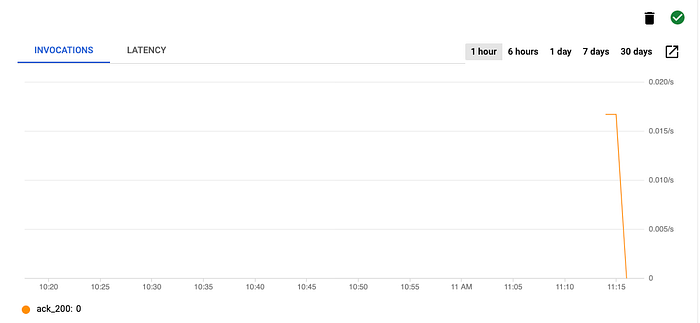
Aufrufe des Eventarc-Triggers
Wechseln Sie nun in den BigQuery-Bereich Ihrer GCP Console und navigieren Sie zum Projekt und Dataset. Im Tab Preview sollten Sie die eingefügten Daten sehen, wie unten anhand der Beispieldaten gezeigt. Im Tab Details finden Sie zudem das Datum der letzten Änderung Ihrer Tabelle, das mit dem letzten Trigger-Lauf in Ihrem Diagramm übereinstimmen sollte.
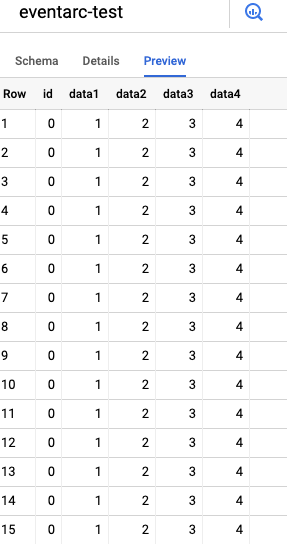
Aus der Beispiel-CSV-Datei geladene Daten
Achten Sie darauf, diese Tabelle nach dem Test mit den Beispieldaten und vor dem Einsatz echter Daten zu löschen!
Im Fehlerfall
Falls keine Daten erscheinen, öffnen Sie Ihren Cloud-Run-Dienst und klicken Sie auf den Tab Logs.
Wenn Sie dort einen POST 500-Fehlereintrag sehen, prüfen Sie die umliegenden Zeilen auf weitere Fehlermeldungen. Die meisten beginnen sinngemäß mit ERROR in app: Exception on / [POST], gefolgt von einem Traceback des Python-Codes im nächsten Log-Eintrag. Dort steht in der Regel der eigentliche Fehler.
Wird ein POST 200-Eintrag angezeigt, die Daten landen aber nicht in BigQuery, suchen Sie in den Logs nach der Ursache. Der Code gibt eine Meldung aus, falls die Datei keine CSV ist oder eine Umgebungsvariable falsch gesetzt wurde.