Un nouvel outil pour mesurer le débit et la latence entre régions
Le cloud apparaît parfois comme un espace extra-dimensionnel, où n'importe quel volume de données peut transiter en un temps quasi nul. Pourtant, les limites fondamentales de l'espace-temps et du protocole TCP font que la simple distance physique change tout. Si vous peinez à transférer d'énormes volumes de données d'un cloud à un autre, il faut rapprocher autant que possible la destination de la source.
Dans cet article, nous nous penchons sur le débit et la latence — deux indicateurs réseau très différents mais corrélés pour mesurer les flux de données — et présentons un nouvel outil pour les mesurer d'une région à l'autre.
La latence influe sur le débit
La latence, ou temps d'aller-retour, mesure les millisecondes qui s'écoulent entre l'envoi d'une requête et la réception d'une réponse. Le débit désigne quant à lui le nombre de bits transmis par seconde.
On peut avoir un débit élevé sans latence faible, et inversement. À l'image du Mississippi, les données peuvent s'écouler en très grandes quantités par seconde et mettre du temps à aller du point A au point B, ou bien filer comme des rapides — quelques octets seulement par seconde — mais arriver à destination à la vitesse de l'éclair.
En pratique, la latence affecte directement le débit dans le protocole le plus répandu, TCP. Il s'agit d'un protocole orienté connexion qui exige un accusé de réception pour chaque paquet et procède à des retransmissions si nécessaire. Le tampon d'envoi TCP contient toutes les données envoyées mais pas encore acquittées par l'hôte distant ; cela permet de retransmettre les paquets non acquittés. Or ce tampon a une taille limitée : la transmission s'interrompt donc dès qu'un nombre suffisant de messages restent non acquittés dans cette fenêtre. Par exemple, avec un temps d'aller-retour de 80 ms et une fenêtre TCP classique de 64 Ko, le débit maximal plafonne à environ 66 Mbit/s ( voir ce calculateur). On est très loin des gigaoctets par seconde annoncés dans le cloud.
Cette dernière mesure correspond à la bande passante : le nombre maximal de bits par seconde que vous pouvez espérer obtenir sur le canal payé. Le débit peut être bien inférieur à la bande passante lorsque des goulots d'étranglement comme la fenêtre TCP imposent leurs limites.
Maximiser le débit malgré une latence élevée
Pour faire transiter de gros volumes de données dans un canal TCP à forte latence, il faut adopter une autre approche.
- Envoyer plusieurs flux en parallèle, jusqu'à la limite de la bande passante. Mais on est souvent contraint par l'usage prévu d'une API donnée, par exemple si elle s'attend à transmettre de gros volumes dans une seule réponse ou applique des limites de fréquence aux appels.
- Utiliser un protocole sans connexion comme UDP et gérer soi-même la retransmission. Ce n'est possible que si vous maîtrisez l'ensemble de la pile. En particulier, la plupart des versions de HTTP(S), couramment utilisé pour les API aujourd'hui, s'appuient sur TCP. (À noter que certains protocoles sur UDP, comme le récent HTTP 3/QUIC, assurent malgré tout la retransmission et présentent donc le même problème de tampons de transmission.)
- Modifier les paramètres TCP, comme la taille de la fenêtre, au niveau du système d'exploitation. Toutefois, dans le cloud, on travaille souvent avec des services serverless qui ne donnent pas un tel contrôle.
- La seule variable qui reste est donc la réduction de la distance. C'est particulièrement important lors d'un transfert entre clouds, car un fournisseur donné dispose dans la plupart des cas de réseaux privés reliant ses régions.
Dans le cloud, la couche réseau est généralement fiable et offre une bande passante élevée — parce que les grands fournisseurs ont les moyens d'investir dans le meilleur. Le trafic au sein d'un même cloud est extrêmement rapide, et même entre fournisseurs, il reste bien meilleur que dans les foyers, les bureaux ou même les datacenters on-premise.
La vitesse de la lumière est finie
En dehors de la congestion sur l'internet public, la distance et la vitesse de la lumière sont les principaux facteurs limitant la latence. Le trajet le plus long possible — entre deux points antipodaux, où l'aller-retour équivaut à la circonférence complète de la Terre — représente 130 millisecondes-lumière, et les autres routes intercontinentales en représentent une part non négligeable. Ajoutez les délais de traitement en chemin, même avec les routeurs très optimisés d'aujourd'hui, et envoyer des données sur des milliers de kilomètres puis les recevoir prendra un nombre significatif de millisecondes. Or cette latence limite fondamentalement le débit d'une transmission TCP.
Une remarque sur le coût
Cet article porte essentiellement sur le débit et la latence, mais n'oublions pas l'autre indicateur : le coût. Les clouds facturent les transferts de données, par ordre décroissant de coût : la sortie hors de leur service, entre régions au sein de leur cloud, puis entre zones.
Mesurer le débit dans le cloud : un nouvel outil
J'ai développé un outil open source pour mesurer le débit et la latence entre régions, à la fois au sein de chaque cloud et entre clouds. Il prend en charge AWS et Google Cloud Platform.
À ma connaissance, c'est l'un des premiers à le faire. Les indicateurs existants se concentrent davantage sur la latence que sur le débit, et la plupart portent sur le réseau interne d'un cloud plutôt que sur les échanges entre clouds.
Comment ça fonctionne
Débit et latence
L'outil Intercloud Latency lance de petites machines virtuelles dans diverses régions. Il exécute ensuite un test avec iperf, un outil de mesure de débit, ainsi qu'un ping pour mesurer la latence.
Lancez performance_test.py --help pour la documentation.
Tests inter-régions
Les tests sont exécutés d'une région à une autre. Par défaut, l'outil ne réalise pas de tests intra-région, car les indicateurs au sein d'une même région sont trop bons pour être comparables à ceux des tests inter-régions.
En incluant toutes les régions GCP et toutes les régions AWS activées par défaut, on obtient 46 régions, soit n * (n - 1) paires de tests (autrement dit, 2 070).
Distances
Les distances reposent sur les emplacements des datacenters, recueillis via diverses sources ouvertes. Bien que les fournisseurs de cloud ne publient pas les emplacements exacts, ceux-ci ne sont pas secrets.
Ces emplacements ne doivent toutefois pas être considérés comme exacts. Chaque région est répartie sur plusieurs zones (de disponibilité), parfois distantes les unes des autres de plusieurs dizaines de kilomètres, par souci de robustesse. (Voir la carte Wikileaks ici, qui l'illustre clairement.) Les coordonnées du centre-ville servent d'approximation. Mais compte tenu des vitesses mesurées ici, les statistiques fondées sur une localisation approximative des régions sont suffisamment précises pour que toute erreur soit absorbée par les autres variations du comportement réseau.
Options
Si vous ne voulez pas tester toutes les régions à la fois, des options permettent de restreindre le choix des paires de régions.
Vous pouvez désigner des paires de régions précises. Vous pouvez aussi laisser le système choisir les paires, en limitant la sélection à :
- un seul cloud,
- des paires inter-cloud spécifiques (par exemple, uniquement GCP-vers-AWS ou GCP-vers-GCP),
- une plage de distances inter-régions précise : la distance minimale et maximale entre deux régions testées ensemble.
- Vous pouvez également limiter le nombre maximal de régions sélectionnées.
Bien que les tests s'exécutent par défaut en parallèle pour gagner en rapidité et maîtriser les coûts, vous pouvez les configurer pour qu'ils s'enchaînent par lots séquentiels.
Les types de machines virtuelles (instances) utilisés sont petits et comparables entre AWS et GCP. Vous pouvez aussi choisir les types d'instances. Important : il ne s'agit pas d'un test visant à atteindre une latence faible et un débit élevé, mais d'une comparaison de ces indicateurs en fonction de la distance ; seul compte donc le fait que les tests soient comparables. Cependant, comme même les plus petites instances bénéficient d'une bande passante de l'ordre du gigabit par seconde, et comme ce test est limité par le réseau et les paramètres de la pile TCP — et non par le CPU, la RAM ou le disque — utiliser des instances plus grandes ne change pas grand-chose.
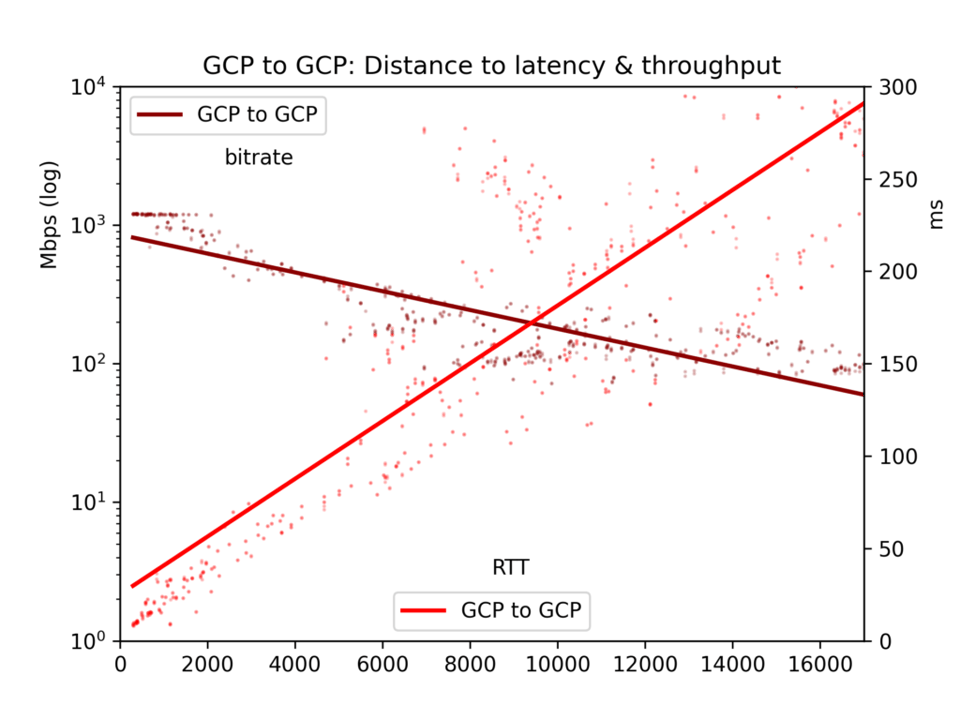
À noter une exception : les régions GCP très proches les unes des autres, où le débit atteint des plafonds liés aux ressources disponibles. Voir les graphiques. Cela n'affecte toutefois pas les conclusions résumées ci-dessous.
Coût
Lancer une instance dans chaque région ne coûte pas grand-chose : ces petites instances reviennent à 0,5 à 2 centimes de l'heure. Grâce à la parallélisation, la suite de tests s'exécute rapidement et le coût des instances reste sous les 2 $ pour un test complet. Le volume de données est de 10 Mo par test, et les frais d'egress représentent l'essentiel de la dépense, jusqu'à 20 $ pour un test couvrant l'ensemble des régions.
Sortie
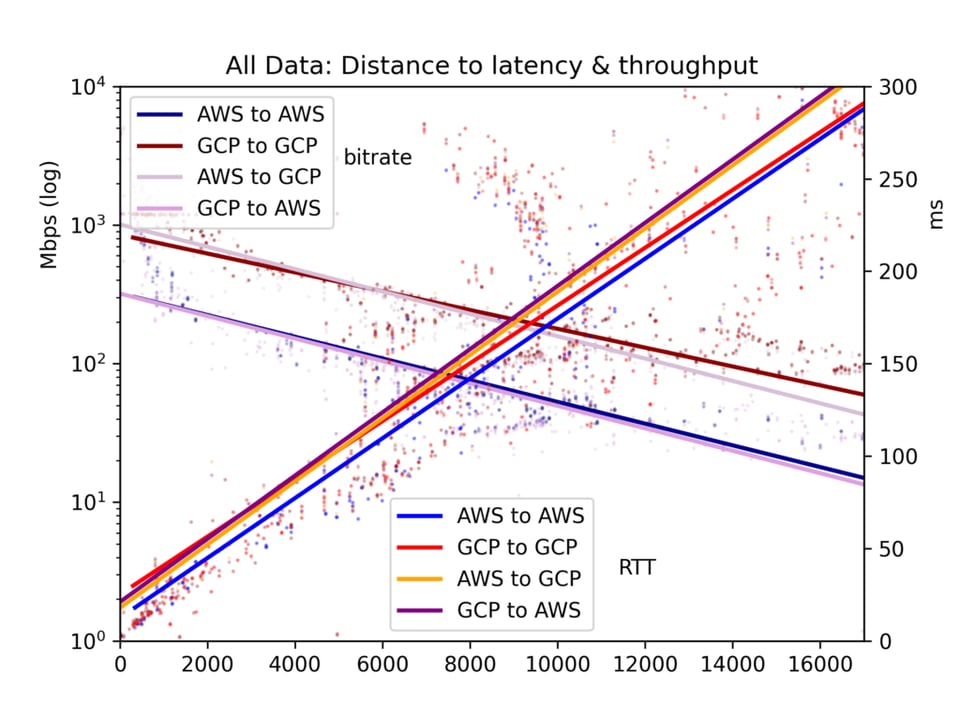
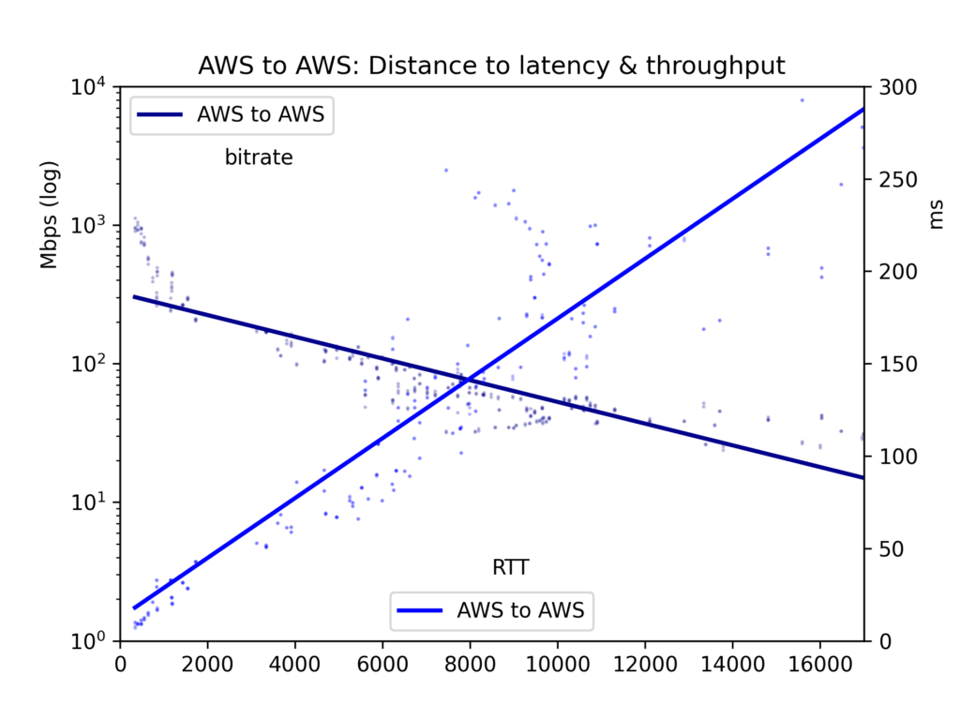
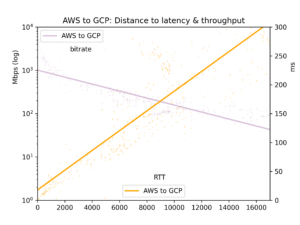
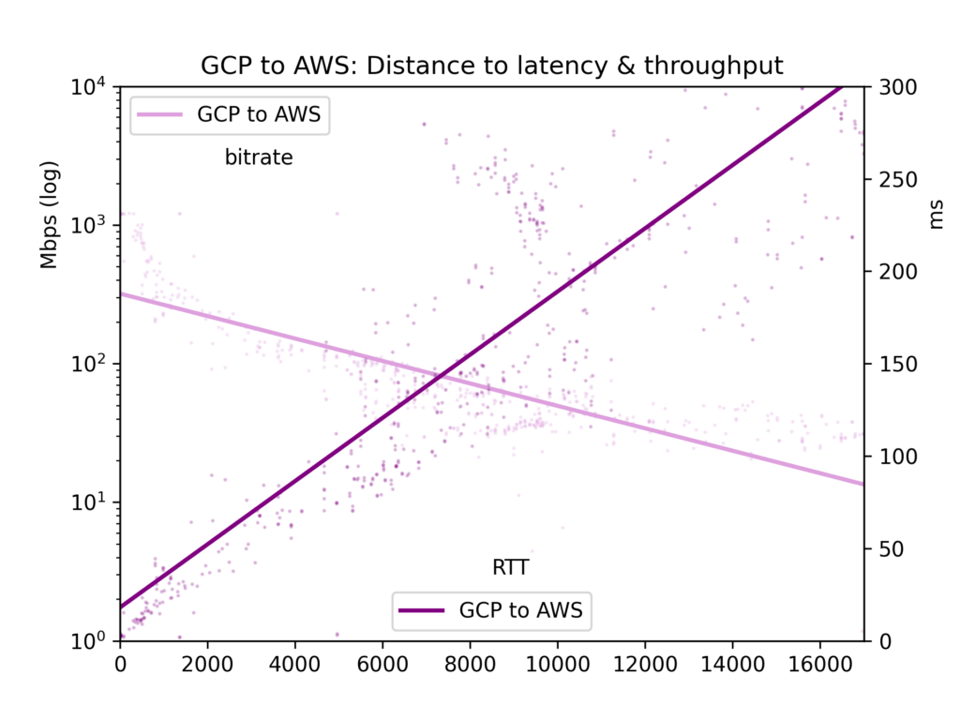
Le temps moyen d'aller-retour et le débit sont consignés dans un fichier CSV et présentés sous forme de cinq graphiques : toutes les paires de clouds, GCP-vers-GCP, GCP-vers-AWS, AWS-vers-GCP et AWS-vers-AWS.
Résultats des tests de débit
Les résultats sont bruités. Sur l'internet public, la congestion et le rééquilibrage BGP peuvent fortement affecter à la fois la latence et le débit. Mais les résultats permettent de tirer des conclusions claires. La latence et le débit sont effectivement meilleurs au sein d'un cloud qu'entre clouds, même si la différence n'est peut-être pas aussi marquée qu'on pourrait le croire.
Concernant notre sujet principal ici, l'effet de la distance, on observe que la latence est linéaire par rapport à la distance (corrélation r=0,92). La vitesse de la lumière et un traitement minimal par les routeurs prennent donc un temps assez prévisible. Le débit est bien plus irrégulier, car les tampons TCP et autres goulots d'étranglement ralentissent la transmission de manière moins linéaire ; il reste néanmoins nettement log-proportionnel à la distance (r=-0,7).
Voir les graphiques ci-dessous. Le constat principal : si en théorie un fleuve massif de données peut s'écouler lentement sur de longues distances, en pratique les tampons TCP font que la latence — et donc la distance — bride le débit. Pour transférer de grands volumes de données entre clouds, repérez les emplacements physiques et choisissez la région la plus proche.