Ein neues Tool, das Throughput und Latenz regionsübergreifend misst
Die Cloud wirkt manchmal wie ein extradimensionaler Raum, in dem sich beliebig große Datenmengen quasi in Nullzeit bewegen lassen. Doch die fundamentalen Grenzen von Raumzeit und TCP-Protokoll sorgen dafür, dass die schlichte physische Distanz einen großen Unterschied macht. Wer Mühe hat, riesige Datenmengen von einer Cloud in eine andere zu schaufeln, sollte das Ziel so nah wie möglich an der Quelle platzieren.
In diesem Artikel schauen wir uns Throughput und Latenz genauer an – zwei sehr unterschiedliche, aber miteinander korrelierte Netzwerk-Metriken zur Messung von Datenflüssen – und stellen ein neues Tool vor, mit dem sich beide regionsübergreifend messen lassen.
Latenz beeinflusst den Throughput
Die Latenz, also die Round-Trip-Zeit, misst die Millisekunden vom Absenden einer Anfrage bis zum Eintreffen der Antwort. Throughput bezeichnet die Anzahl der pro Sekunde übertragenen Bits.
Hoher Throughput ist auch ohne niedrige Latenz möglich – und umgekehrt. Wie der Mississippi können Daten in sehr großen Mengen pro Sekunde fließen und dennoch lange von Punkt A nach Punkt B brauchen, oder sie schießen wie eine reißende Stromschnelle dahin: nur wenige Bytes pro Sekunde, dafür blitzschnell am Ziel.
In der Praxis wirkt sich die Latenz im am weitesten verbreiteten Protokoll TCP allerdings direkt auf den Throughput aus. TCP ist verbindungsorientiert, verlangt für jedes Paket eine Bestätigung und sendet bei Bedarf erneut. Der TCP-Sendepuffer enthält alle Daten, die gesendet, vom Remote-Host aber noch nicht bestätigt wurden – das ermöglicht die erneute Übertragung nicht bestätigter Pakete. Der Puffer ist jedoch begrenzt, sodass die Übertragung pausiert, sobald innerhalb dieses Fensters genügend Nachrichten unbestätigt bleiben. Beispiel: Bei einer Round-Trip-Zeit von 80 ms und einem typischen TCP-Fenster von 64 KByte liegt der maximale Throughput bei lediglich rund 66 Mbit/s ( siehe diesen Rechner). Das ist deutlich weniger als die Gigabyte pro Sekunde, mit denen in der Cloud geworben wird.
Diese letzte Größe ist die Bandbreite – die maximale Anzahl Bits pro Sekunde, die der von Ihnen gebuchte Kanal überhaupt liefern kann. Throughput kann weit unter der Bandbreite liegen, sobald Engpässe wie das TCP-Fenster bremsen.
Throughput bei hoher Latenz maximieren
Wenn riesige Datenmengen durch einen TCP-Kanal mit hoher Latenz fließen sollen, müssen Sie andere Wege gehen.
- Mehrere Streams gleichzeitig senden, bis zum Bandbreitenlimit. Das ist allerdings oft durch die Nutzungsweise einer API begrenzt – etwa wenn diese große Datenmengen in einer einzigen Antwort liefert oder Rate-Limits für Aufrufe vorgibt.
- Ein verbindungsloses Protokoll wie UDP nutzen und die erneute Übertragung selbst implementieren. Das funktioniert nur, wenn Sie den gesamten Stack kontrollieren. Insbesondere die meisten HTTP(S)-Versionen, die heute für APIs üblich sind, laufen über TCP. (Hinweis: Manche UDP-basierten Protokolle wie das jüngere HTTP 3/QUIC sehen ebenfalls erneute Übertragungen vor und haben damit dasselbe Grundproblem mit Sendepuffern.)
- TCP-Parameter wie die Fenstergröße auf Betriebssystemebene anpassen. In der Cloud arbeiten Sie jedoch häufig mit serverlosen Diensten, die Ihnen diese Kontrolle gar nicht erst geben.
- Damit bleibt nur eine Stellschraube: die Distanz minimieren. Besonders wichtig wird das beim Wechsel zwischen Clouds, denn ein Cloud-Anbieter verbindet seine Regionen in den meisten Fällen über eigene private Netze.
In der Cloud ist die Netzwerkebene meist zuverlässig und bietet hohe Bandbreite – schließlich können die großen Cloud-Anbieter in das Beste investieren. Traffic innerhalb einer Cloud ist extrem schnell, und selbst zwischen verschiedenen Cloud-Anbietern ist er noch deutlich besser als in Privathaushalten, Büros oder On-Premise-Rechenzentren.
Die Lichtgeschwindigkeit ist endlich
Neben der Auslastung des öffentlichen Internets sind Distanz und Lichtgeschwindigkeit die größten Bremsen für die Latenz. Die längste denkbare Strecke verläuft zwischen zwei antipodischen Punkten – dort entspricht der Round-Trip dem gesamten Erdumfang – und beträgt 130 Lichtmillisekunden; andere transkontinentale Routen erreichen einen erheblichen Bruchteil davon. Zusammen mit den Verzögerungen durch die Verarbeitung unterwegs – selbst bei den hochoptimierten Routern von heute – heißt das: Daten über tausende Kilometer und zurück zu schicken, kostet eine merkliche Zahl Millisekunden. Und genau diese Latenz begrenzt grundsätzlich den Throughput einer TCP-Übertragung.
Anmerkung zu den Kosten
In diesem Artikel geht es vor allem um Throughput und Latenz, doch die andere wichtige Größe sollte nicht vergessen werden: die Kosten. Clouds berechnen Datenübertragungen in absteigender Höhe wie folgt: Egress aus dem Service heraus, zwischen Regionen innerhalb der Cloud und zwischen Zonen.
Throughput-Messung in der Cloud: ein neues Tool
Ich habe ein Open-Source-Tool geschrieben, das Throughput und Latenz regionsübergreifend misst – sowohl innerhalb einer Cloud als auch zwischen Clouds. Es unterstützt AWS und Google Cloud Platform.
Soweit mir bekannt ist, gehört es zu den ersten seiner Art. Bestehende Metriken konzentrieren sich eher auf Latenz als auf Throughput, und die meisten betrachten nur das Netzwerk innerhalb einer einzelnen Cloud, nicht zwischen mehreren.
So funktioniert es
Throughput und Latenz
Das Intercloud-Latency-Tool startet kleine virtuelle Maschinen in verschiedenen Regionen. Anschließend führt es einen Test mit iperf – einem Tool zur Throughput-Messung – sowie mit ping zur Latenzmessung aus.
Mit performance_test.py --help rufen Sie die Dokumentation auf.
Tests zwischen Regionen
Die Tests laufen jeweils von einer Region in eine andere. Standardmäßig finden keine Tests innerhalb derselben Region statt, weil die Werte dort zu gut sind, um mit Inter-Region-Tests vergleichbar zu sein.
Mit allen GCP-Regionen und allen standardmäßig aktivierten AWS-Regionen ergibt das 46 Regionen und n * (n - 1) – also 2070 – Testpaare.
Distanzen
Die Distanzen basieren auf Rechenzentrumsstandorten, die aus verschiedenen offenen Quellen zusammengetragen wurden. Auch wenn die Cloud-Anbieter die genauen Standorte nicht öffentlich kommunizieren, sind sie kein Geheimnis.
Die Standorte sollten dennoch nicht als exakt verstanden werden. Jede Region erstreckt sich aus Robustheitsgründen über mehrere (Availability) Zones, die teilweise dutzende Kilometer auseinanderliegen. (Siehe die Wikileaks-Karte hier, die das anschaulich zeigt.) Als Näherung dienen die Koordinaten der jeweiligen Stadtmitte. Bei den hier gemessenen Geschwindigkeiten sind Statistiken, die auf der ungefähren Lage einer Region beruhen, jedoch präzise genug – etwaige Fehler verschwinden in den ohnehin vorhandenen Schwankungen des Netzwerkverhaltens.
Optionen
Wenn Sie nicht alle Regionen auf einmal testen möchten, lässt sich die Auswahl an Region-Paaren über entsprechende Optionen einschränken.
Sie können bestimmte Region-Paare festlegen. Alternativ trifft das System die Auswahl, und Sie schränken sie ein auf:
- eine einzelne Cloud,
- bestimmte Cloud-Kombinationen (z. B. nur GCP-zu-AWS oder GCP-zu-GCP),
- einen bestimmten Distanzbereich zwischen Regionen: minimale und maximale Entfernung zwischen zwei gemeinsam getesteten Regionen.
- Außerdem können Sie die maximale Anzahl ausgewählter Regionen begrenzen.
Standardmäßig laufen die Tests aus Geschwindigkeits- und Kostengründen parallel; Sie können sie aber auch in sequenziellen Batches ausführen lassen.
Die verwendeten Instance-Typen der virtuellen Maschinen sind klein und zwischen AWS und GCP vergleichbar. Die Maschinentypen lassen sich auch selbst wählen. Wichtig zu bedenken: Es geht hier nicht darum, niedrige Latenz und hohen Throughput zu erreichen, sondern darum, diese Metriken über verschiedene Distanzen hinweg zu vergleichen. Entscheidend ist also nur, dass die Tests untereinander vergleichbar bleiben. Da selbst den kleinsten Instances Bandbreiten im Gigabit-pro-Sekunde-Bereich zugewiesen werden und der Test durch Netzwerk und TCP-Stack-Vorgaben begrenzt wird – nicht durch CPU, RAM oder Disk –, machen größere Instances kaum einen Unterschied.
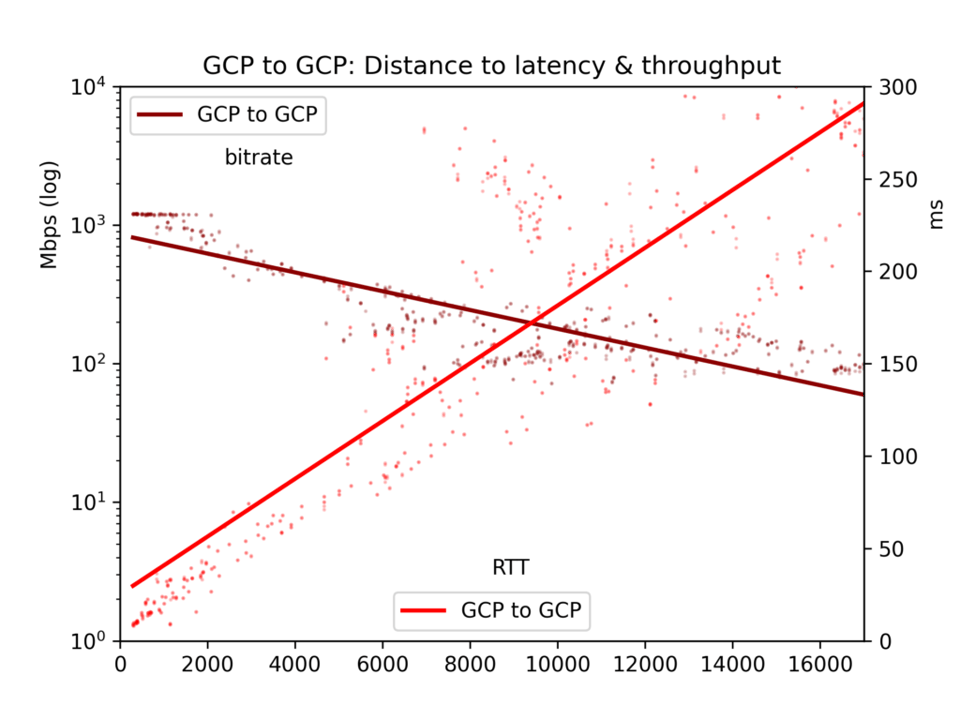
Eine Ausnahme gibt es jedoch: In sehr nah beieinanderliegenden GCP-Regionen stößt der Throughput an Grenzen, die sich aus den verfügbaren Ressourcen ergeben. Siehe die Charts. Auf die unten zusammengefassten Ergebnisse hat das aber keinen Einfluss.
Kosten
Eine Instance in jeder Region zu starten, ist nicht teuer: Diese kleinen Instances kosten 0,5 bis 2 Cent pro Stunde. Dank Parallelisierung läuft die Test-Suite zügig durch, und die Instance-Kosten liegen für einen kompletten Test unter 2 US-Dollar. Pro Test werden 10 MB an Daten übertragen; Egress-Gebühren machen den Großteil der Kosten aus – bis zu 20 US-Dollar bei einem Test, der alle Regionen abdeckt.
Output
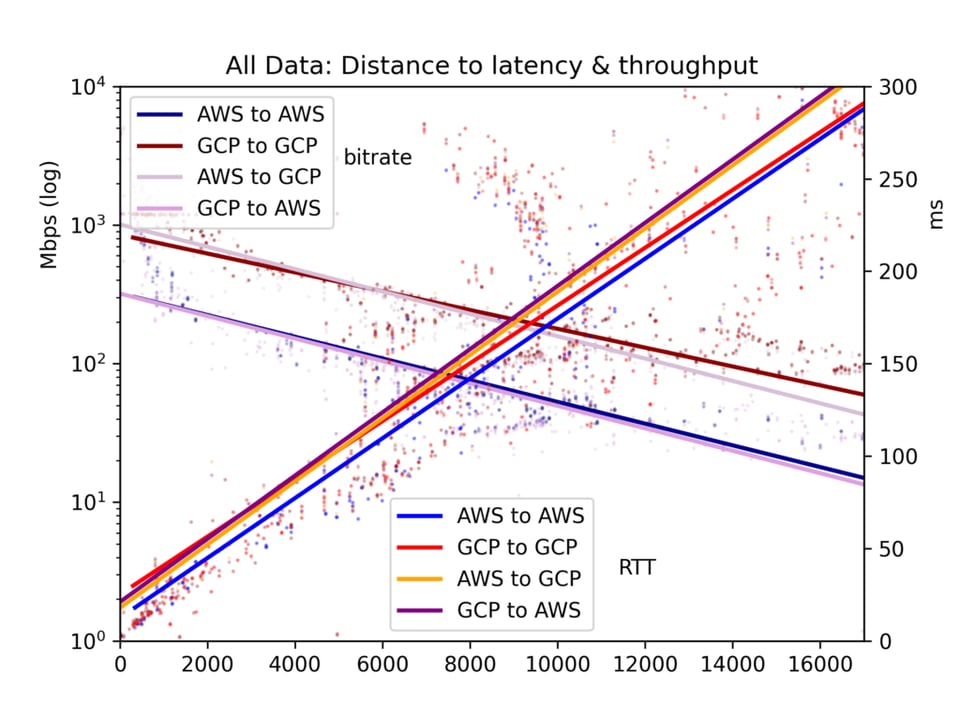
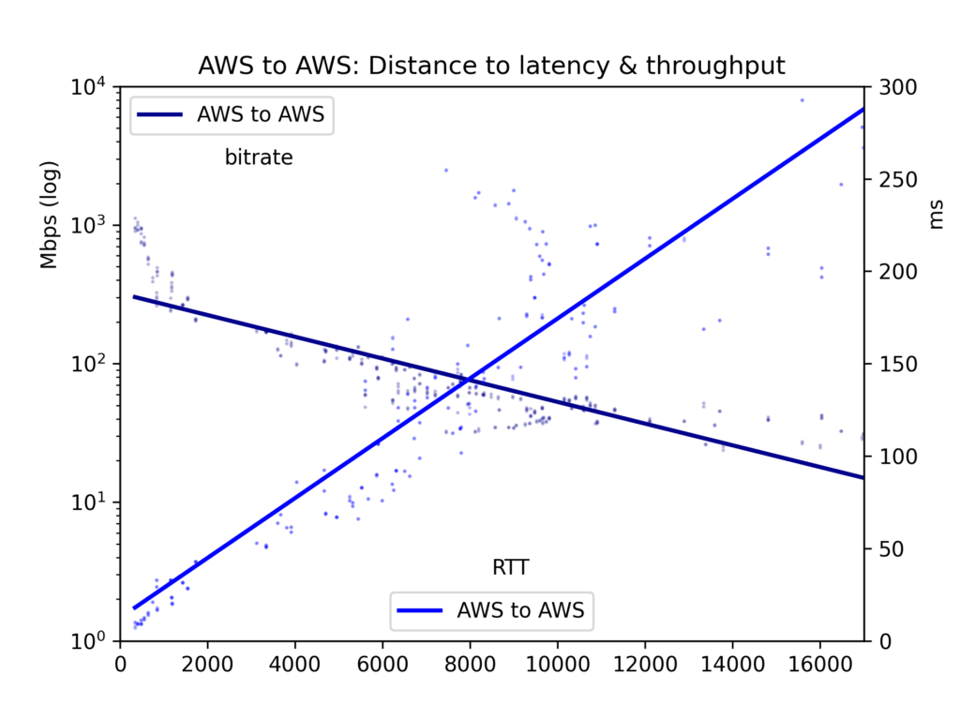
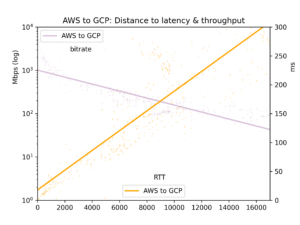
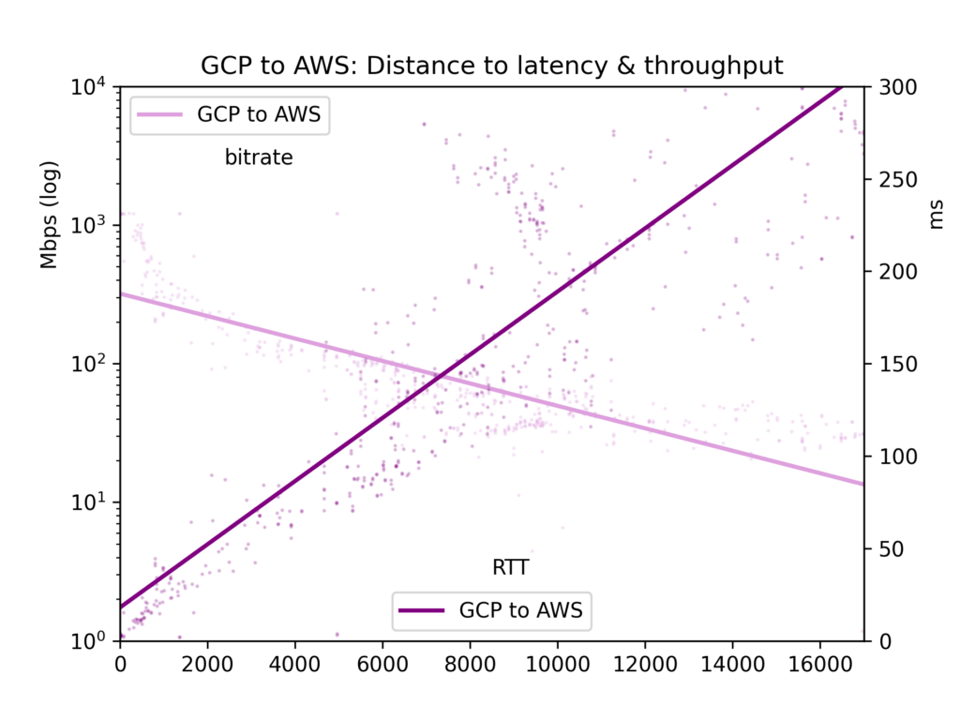
Durchschnittliche Round-Trip-Zeit und Bitrate landen in einer CSV-Datei und werden in fünf Charts dargestellt: alle Cloud-Paare, GCP-zu-GCP, GCP-zu-AWS, AWS-zu-GCP und AWS-zu-AWS.
Ergebnisse der Throughput-Tests
Die Ergebnisse sind verrauscht. Im öffentlichen Internet können Auslastung und BGP-Rebalancing sowohl Latenz als auch Throughput stark beeinflussen. Dennoch zeigt sich ein klares Bild: Latenz und Throughput sind innerhalb einer Cloud tatsächlich besser als zwischen Clouds – wenn auch vielleicht weniger deutlich, als man vermuten würde.
Für unseren Hauptfokus, den Effekt der Distanz, gilt: Latenz verläuft linear zur Distanz (Korrelation r=0,92). Lichtgeschwindigkeit und ein Mindestmaß an Router-Verarbeitung kosten also recht geradlinig Zeit. Der Throughput schwankt deutlich stärker, da TCP-Puffer und andere Engpässe die Übertragung weniger linear ausbremsen – er verhält sich aber klar log-proportional zur Distanz (r=-0,7).
Siehe die Charts unten. Das zentrale Ergebnis: Auch wenn ein gewaltiger Datenstrom prinzipiell langsam über große Entfernungen fließen kann, sorgen TCP-Puffer in der Praxis dafür, dass Latenz – und damit Distanz – den Throughput ausbremsen. Wenn Sie große Datenmengen zwischen Clouds verschieben wollen, schlagen Sie die physischen Standorte nach und wählen Sie die nächstgelegene Region.