Conheça uma nova ferramenta para medir throughput e latência entre regiões
A nuvem às vezes parece um espaço extradimensional, em que qualquer volume de dados pode trafegar em tempo quase zero. Mas os limites fundamentais do espaço-tempo e do protocolo TCP fazem com que a simples distância física pese muito. Se você está penando para transferir grandes volumes de dados de uma nuvem para outra, precisa colocar o destino o mais perto possível da origem.
Neste artigo, analisamos throughput e latência — duas métricas de rede bem distintas, mas correlacionadas, usadas para medir fluxos de dados — e apresentamos uma nova ferramenta para medi-las entre regiões.
A latência impacta o throughput
A latência, ou tempo de ida e volta, mede os milissegundos entre o envio de uma requisição e o recebimento da resposta. Já o throughput é o número de bits por segundo que são transmitidos.
Dá para ter throughput alto sem latência baixa, e vice-versa. Como o rio Mississippi, os dados podem fluir em grandes volumes por segundo e levar muito tempo para ir do ponto A ao ponto B; ou se mover como corredeiras velozes — apenas alguns bytes por segundo —, mas chegar ao destino num piscar de olhos.
Ainda assim, na prática, a latência afeta diretamente o throughput no protocolo mais usado, o TCP. Trata-se de um protocolo orientado a conexão, que exige confirmação para cada pacote e reenvia quando necessário. O buffer de envio do TCP guarda todos os dados que já foram enviados, mas ainda não confirmados pelo host remoto; é isso que permite a retransmissão dos pacotes não confirmados. Acontece que o buffer tem tamanho limitado, então a transmissão é pausada se mensagens suficientes ficarem sem confirmação dentro dessa janela. Por exemplo, com tempo de ida e volta de 80 ms e janela TCP típica de 64 KByte, o throughput máximo chega a apenas 66 Mbit/s ( veja esta calculadora). É muito menos do que os gigabytes por segundo anunciados na nuvem.
Essa última métrica é a banda (bandwidth), o número máximo de bits por segundo que você pode obter no canal pelo qual pagou. O throughput pode ficar bem abaixo da banda quando gargalos como a janela TCP entram em ação.
Como maximizar o throughput quando a latência é alta
Se você quer que grandes volumes de dados passem por um canal TCP de alta latência, vai precisar mudar de estratégia.
- Envie vários streams ao mesmo tempo, até o limite da banda. Mas isso costuma esbarrar na forma como uma determinada API foi pensada — por exemplo, se ela espera enviar grandes volumes de dados em uma única resposta ou impõe rate limits nas invocações.
- Use um protocolo sem conexão, como o UDP, e cuide você mesmo da retransmissão. Isso só é viável quando se tem controle sobre toda a stack. Em particular, a maioria das versões de HTTP(S), hoje muito usadas em APIs, roda sobre TCP. (Vale notar que alguns protocolos sobre UDP, como o recente HTTP 3/QUIC, ainda fazem retransmissão e, portanto, têm o mesmo problema básico de buffers de transmissão.)
- Altere parâmetros do TCP, como o tamanho da janela, no nível do sistema operacional. Mas, na nuvem, você costuma trabalhar com serviços serverless que não dão esse tipo de controle.
- Ou seja, a única variável que sobra é minimizar a distância. Isso é especialmente importante na transição entre nuvens, porque, na maioria dos casos, cada provedor mantém redes privadas conectando suas regiões.
Na nuvem, a camada de rede costuma ser confiável e oferece banda alta — afinal, os grandes provedores podem investir no que há de melhor. O tráfego dentro de uma mesma nuvem é extremamente rápido e, mesmo entre provedores, ainda é muito superior ao de residências, escritórios e até data centers on-premise.
A velocidade da luz é finita
Tirando o congestionamento na internet pública, distância e velocidade da luz são os maiores limitadores da latência. A maior distância possível é entre dois pontos antípodas — em que a ida e volta equivale à circunferência completa da Terra — e corresponde a 130 milissegundos-luz; outras rotas transcontinentais representam uma boa fração disso. Somado aos atrasos de processamento ao longo do caminho, mesmo com os roteadores altamente otimizados de hoje, isso significa que enviar dados a milhares de quilômetros e voltar leva uma quantidade significativa de milissegundos. E essa latência limita, na essência, o throughput da transmissão TCP.
Uma observação sobre custo
Este artigo trata principalmente de throughput e latência, mas não dá para esquecer da outra métrica: custo. As nuvens cobram pela transferência de dados, em ordem decrescente: data egress para fora do serviço, entre regiões da mesma nuvem e entre zonas.
Medindo throughput na nuvem: uma nova ferramenta
Escrevi uma ferramenta open-source para medir throughput e latência entre regiões, tanto dentro de cada nuvem quanto entre nuvens. Ela tem suporte a AWS e Google Cloud Platform.
Até onde sei, é uma das primeiras a fazer isso. As métricas existentes focam mais em latência do que em throughput, e a maioria se concentra na rede dentro de uma nuvem, e não entre nuvens.
Como funciona
Throughput e latência
A Intercloud Latency tool funciona iniciando pequenas máquinas virtuais em várias regiões. Em seguida, ela executa um teste com iperf, uma ferramenta de medição de throughput, e com ping, para medir a latência.
Execute performance_test.py --help para ver a documentação.
Testes inter-região
Os testes são executados de uma região para outra. Por padrão, ela não faz testes intra-região, porque as métricas dentro de uma região são boas demais para serem comparáveis aos testes inter-região.
Considerando todas as regiões do GCP e todas as regiões da AWS habilitadas por padrão, são 46 regiões e n * (n - 1) (ou seja, 2070) pares de teste.
Distâncias
As distâncias são baseadas em localizações de data centers coletadas em diversas fontes abertas. Os provedores de nuvem não divulgam as localizações exatas, mas elas não são segredo.
Ainda assim, as localizações não devem ser tomadas como exatas. Cada região se distribui em várias zonas (de disponibilidade), que em alguns casos ficam separadas por dezenas de quilômetros, para garantir robustez. (Veja o mapa do Wikileaks, que ilustra isso bem.) As coordenadas do centro da cidade são usadas como aproximação. Mesmo assim, dadas as velocidades medidas aqui, as estatísticas que dependem da localização aproximada da região são precisas o suficiente para que qualquer erro seja absorvido por outras variações no comportamento da rede.
Opções
Se você não quiser testar todas as regiões de uma vez, há opções para limitar a escolha de pares de regiões.
Você pode definir pares específicos de regiões. Também pode deixar que o sistema escolha os pares, restringindo a escolha a:
- Uma única nuvem,
- Pares específicos entre nuvens (por exemplo, só GCP-AWS ou GCP-GCP),
- Uma faixa específica de distâncias inter-região: as distâncias mínima e máxima entre dois quaisquer regiões a serem testadas em conjunto.
- E você pode limitar o número máximo de regiões selecionadas.
Por padrão, os testes rodam em paralelo por questões de velocidade e controle de custo, mas dá para configurá-los em lotes sequenciais.
Os tipos de máquina virtual (instância) usados são pequenos e comparáveis entre AWS e GCP. Você também pode escolher os tipos de máquina. Vale lembrar que este não é um teste para alcançar baixa latência e alto throughput — é uma comparação dessas métricas em diferentes distâncias, então o que importa é que os testes sejam comparáveis. De toda forma, como até as menores instâncias têm banda alocada na faixa dos gigabits por segundo, e como o teste é limitado pela rede e pelas definições da stack TCP — não por CPU, RAM ou disco —, usar instâncias maiores não faz muita diferença.
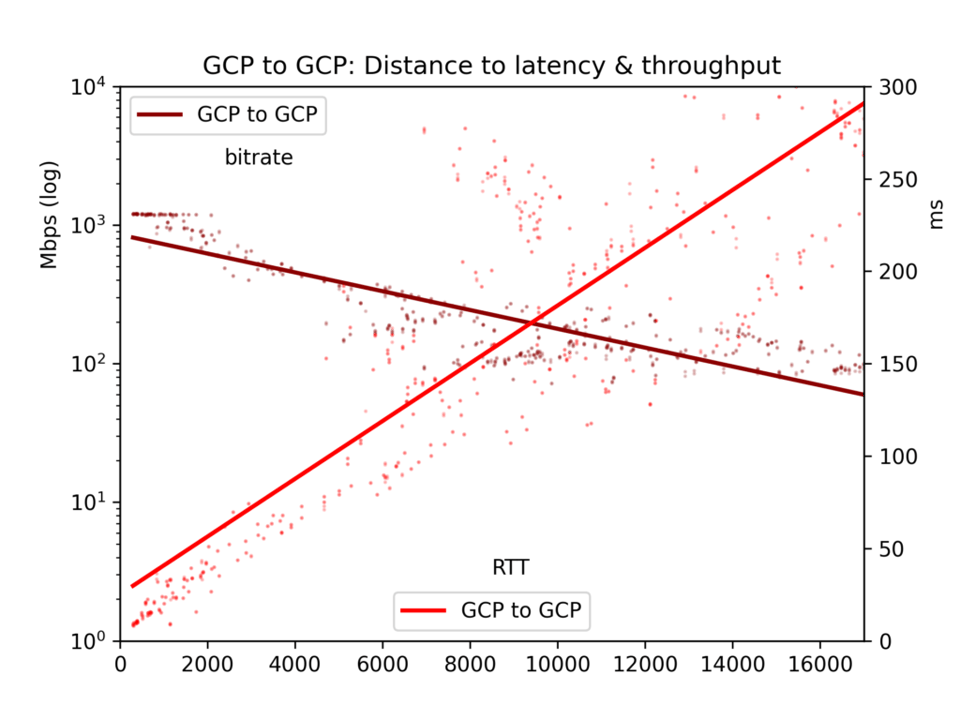
A única exceção a destacar são as regiões do GCP muito próximas entre si, onde o throughput esbarra em tetos definidos pelos recursos disponíveis. Veja os gráficos. Mas isso não afeta as conclusões, resumidas abaixo.
Custo
Iniciar uma instância em cada região sai barato: essas pequenas instâncias custam de 0,5 a 2 centavos por hora. Graças à paralelização, a suíte de testes roda rápido e os custos de instância ficam abaixo de US$ 2 em um teste completo. O volume de dados é de 10 MB por teste, e os custos de egress representam a maior parte da despesa, chegando a US$ 20 em um teste que cobre todas as regiões.
Saída
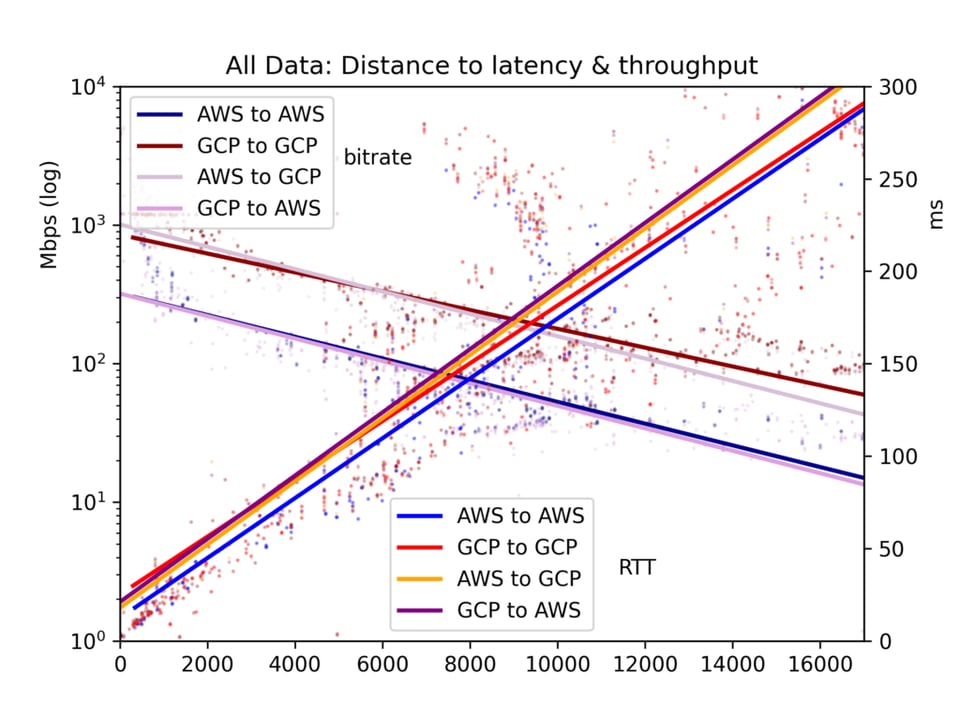
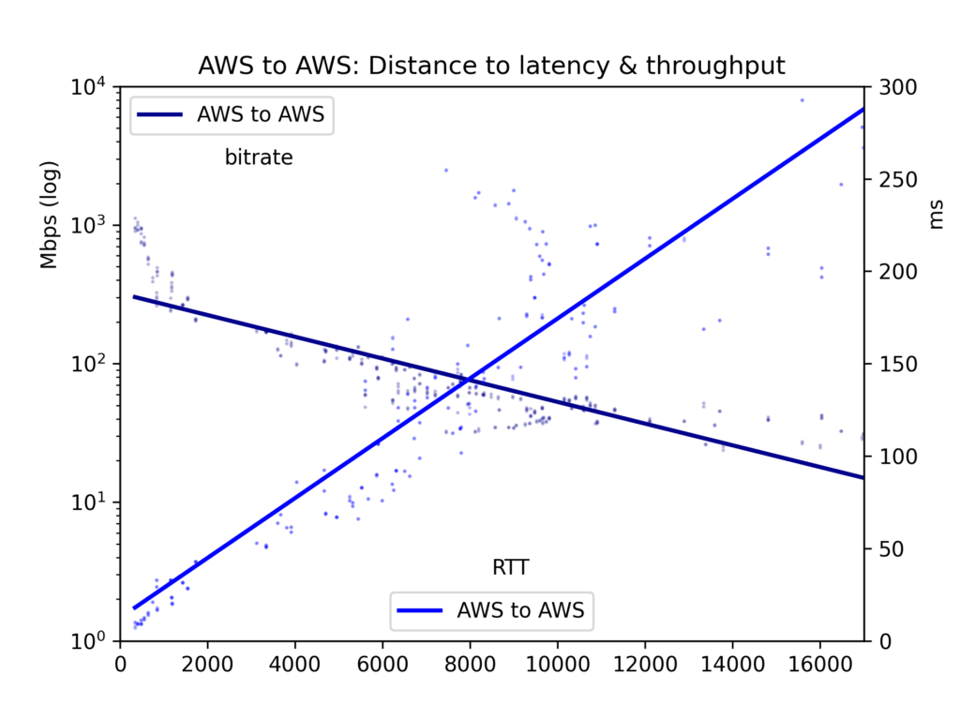
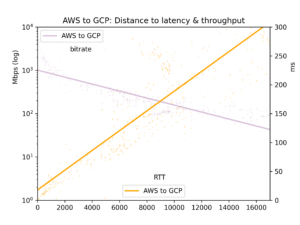
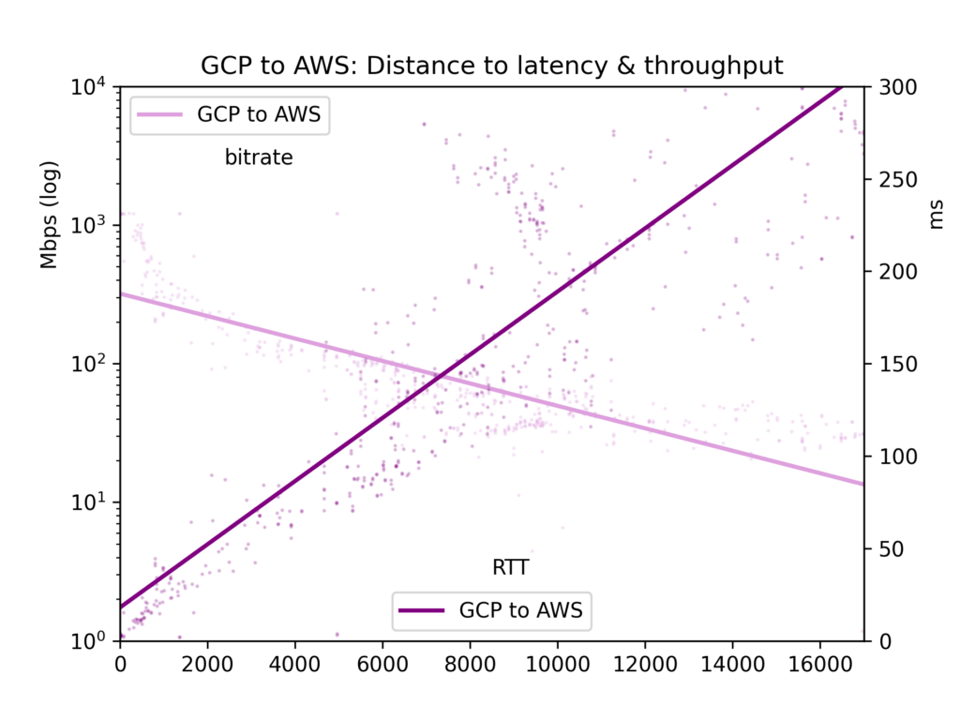
O tempo médio de ida e volta e a taxa de bits são reunidos em um arquivo CSV e apresentados em cinco gráficos: todos os pares de nuvens, GCP-GCP, GCP-AWS, AWS-GCP e AWS-AWS.
Resultados dos testes de throughput
Os resultados são ruidosos. Na internet pública, congestionamentos e rebalanceamento de BGP podem afetar bastante tanto a latência quanto o throughput. Mesmo assim, os resultados trazem algumas conclusões claras. A latência e o throughput são, de fato, melhores dentro de uma mesma nuvem do que entre nuvens — embora talvez não tão diferentes quanto você imagina.
Para o nosso foco aqui, os efeitos da distância, vemos que a latência é linear em relação à distância (correlação r=0,92). Ou seja, a velocidade da luz e o processamento mínimo dos roteadores consomem tempo de forma relativamente direta. O throughput é muito mais irregular, já que buffers TCP e outros gargalos reduzem a transmissão de forma menos linear, mas o throughput é claramente log-proporcional à distância (r=-0,7).
Veja os gráficos abaixo. O resultado principal é: embora, em tese, um enorme rio de dados possa fluir lentamente por uma longa distância, na prática os buffers TCP fazem com que a latência — e, portanto, a distância — prejudiquem o throughput. Se você quer transferir grandes volumes de dados entre nuvens, consulte as localizações físicas e escolha a região mais próxima.