Un nuovo strumento per misurare throughput e latenza tra regioni diverse
Il cloud sembra a volte uno spazio extradimensionale, in cui qualsiasi quantità di dati può fluire in tempi quasi azzerati. Ma i limiti fondamentali dello spazio-tempo e del protocollo TCP fanno sì che la semplice distanza fisica conti eccome. Se si fatica a spostare enormi volumi di dati da un cloud a un altro, conviene collocare la destinazione il più vicino possibile alla sorgente.
In questo articolo analizziamo throughput e latenza, due metriche di rete molto diverse ma correlate per misurare i flussi di dati, e presentiamo un nuovo strumento per misurarle tra regioni diverse.
La latenza incide sul throughput
La latenza, ovvero il tempo di andata e ritorno, misura i millisecondi che intercorrono tra l'invio di una richiesta e la ricezione della risposta. Il throughput indica invece il numero di bit al secondo trasmessi.
Si può avere un throughput elevato senza una bassa latenza, e viceversa. Come il fiume Mississippi, i dati possono scorrere in grandi quantità al secondo impiegando molto tempo per andare dal punto A al punto B, oppure muoversi come rapide impetuose — pochi byte al secondo — e raggiungere comunque la destinazione in un lampo.
In pratica, però, la latenza incide direttamente sul throughput nel protocollo più diffuso, TCP. Si tratta di un protocollo orientato alla connessione che richiede un acknowledgement per ogni pacchetto e ne effettua la ritrasmissione quando necessario. Il buffer di invio TCP contiene tutti i dati inviati ma non ancora confermati dall'host remoto, in modo da consentire la ritrasmissione dei pacchetti non confermati. Il buffer ha però una dimensione limitata: la trasmissione si interrompe se all'interno di questa finestra rimangono troppi messaggi senza conferma. Per esempio, con un round-trip time di 80 ms e una tipica finestra TCP di 64 KByte, il throughput massimo arriva ad appena 66 Mbit/sec ( si veda questo calcolatore). Ben lontano dai gigabyte al secondo pubblicizzati nel cloud.
Quest'ultima metrica è la bandwidth, ossia il numero massimo di bit al secondo che si può ottenere dal canale acquistato. Il throughput può essere molto inferiore alla bandwidth quando colli di bottiglia come la finestra TCP impongono dei limiti.
Massimizzare il throughput in presenza di alta latenza
Per far scorrere grandi masse di dati attraverso un canale TCP ad alta latenza occorre adottare strategie diverse.
- Inviare più stream contemporaneamente, fino al limite di bandwidth. Spesso però questo è vincolato dalle modalità d'uso previste da una determinata API: ad esempio se restituisce grandi volumi di dati in un'unica risposta o impone rate-limit sulle chiamate.
- Utilizzare un protocollo connectionless come UDP e gestire la ritrasmissione in proprio. È fattibile solo quando si controlla l'intero stack. In particolare, la maggior parte delle versioni di HTTP(S), oggi comunemente usato per le API, gira su TCP. (Si noti che alcuni protocolli su UDP, come il recente HTTP 3/QUIC, prevedono comunque la ritrasmissione e quindi presentano lo stesso problema di fondo legato ai buffer di trasmissione.)
- Modificare i parametri TCP, come la dimensione della finestra, a livello di sistema operativo. Nel cloud, però, si lavora spesso con servizi serverless che non offrono questo livello di controllo.
- Resta quindi una sola variabile su cui agire: ridurre al minimo la distanza. Aspetto particolarmente importante quando ci si sposta da un cloud all'altro, perché un singolo cloud provider dispone nella maggior parte dei casi di reti private che collegano le proprie regioni.
Nel cloud lo strato di rete è in genere affidabile e offre una bandwidth elevata, perché i grandi cloud provider possono permettersi di investire nelle migliori infrastrutture. Il traffico interno a un singolo cloud è estremamente veloce e, anche tra cloud provider diversi, resta di gran lunga superiore a quello disponibile in case, uffici e persino data center on-premise.
La velocità della luce è finita
Oltre alla congestione sull'internet pubblica, la distanza e la velocità della luce sono i maggiori limiti alla latenza. La distanza massima a cui si può trasmettere è quella tra due punti antipodali — dove il round-trip equivale all'intera circonferenza terrestre — pari a 130 millisecondi-luce, e altre tratte transcontinentali ne rappresentano una buona frazione. Considerando anche i ritardi di elaborazione lungo il percorso, persino con i router altamente ottimizzati oggi in uso, l'invio di dati a migliaia di chilometri di distanza e ritorno richiede un numero significativo di millisecondi. E quella latenza limita in modo strutturale il throughput della trasmissione TCP.
Una nota sui costi
Questo articolo si concentra principalmente su throughput e latenza, ma non bisogna dimenticare l'altra metrica fondamentale: il costo. I cloud applicano tariffe per il trasferimento dei dati che, in ordine decrescente di costo, riguardano: data egress al di fuori del servizio, traffico tra regioni dello stesso cloud e traffico tra zone.
Misurare il throughput nel cloud: un nuovo strumento
Ho sviluppato uno strumento open source per misurare throughput e latenza tra regioni, sia all'interno di ciascun cloud sia tra cloud diversi. Supporta AWS e Google Cloud Platform.
Per quanto ne so, è uno dei primi strumenti a farlo. Le metriche esistenti si concentrano sulla latenza più che sul throughput, e nella maggior parte dei casi guardano alla rete interna a un singolo cloud, non a quella tra cloud diversi.
Come funziona
Throughput e latenza
L'Intercloud Latency tool avvia piccole macchine virtuali in varie regioni. Esegue poi un test con iperf, uno strumento per la misurazione del throughput, e con ping per misurare la latenza.
Eseguire performance_test.py --help per la documentazione.
Test inter-regionali
I test vengono eseguiti da una regione all'altra. Per impostazione predefinita non si effettuano test intra-regione, perché le metriche all'interno di una stessa regione sono troppo buone per essere paragonabili a quelle dei test inter-regionali.
Includendo tutte le regioni GCP e tutte le regioni AWS abilitate per impostazione predefinita, si arriva a 46 regioni e n * (n - 1) coppie di test (cioè 2070).
Distanze
Le distanze si basano sulle posizioni dei data center raccolte da varie fonti aperte. I cloud provider non rendono pubbliche le posizioni esatte, ma non si tratta di un segreto.
Le posizioni, tuttavia, non vanno considerate esatte. Ogni regione si articola su più zone (di disponibilità), in alcuni casi separate tra loro da decine di chilometri per garantire robustezza. (Si veda la mappa di Wikileaks, che lo illustra chiaramente.) Come approssimazione si usano le coordinate del centro città. Date le velocità misurate, però, le statistiche basate sulla posizione approssimativa della regione sono sufficientemente precise: qualsiasi errore viene assorbito dalle altre variazioni del comportamento di rete.
Opzioni
Se non si vogliono testare tutte le regioni in una sola volta, sono disponibili opzioni per limitare la scelta delle coppie di regioni.
Si possono indicare coppie di regioni specifiche, oppure lasciare che sia il sistema a sceglierle, restringendo la selezione a:
- Un singolo cloud,
- Coppie inter-cloud specifiche (ad esempio solo GCP-to-AWS o GCP-to-GCP),
- Un intervallo specifico di distanze inter-regionali: la distanza minima e massima tra due regioni da testare insieme.
- È inoltre possibile limitare il numero massimo di regioni selezionate.
Per impostazione predefinita i test vengono eseguiti in parallelo, per ragioni di velocità e controllo dei costi, ma è possibile configurarli anche in batch sequenziali.
I tipi di macchina virtuale (instance) utilizzati sono di piccole dimensioni e paragonabili tra AWS e GCP. Si possono comunque scegliere i tipi di macchina. È importante ricordare che non si tratta di un test volto a ottenere la latenza più bassa e il throughput più alto in assoluto, ma di un confronto di queste metriche su distanze diverse: ciò che conta è solo che i test siano confrontabili tra loro. Inoltre, dato che anche le instance più piccole hanno bandwidth allocata nell'ordine dei gigabit al secondo, e che questo test è limitato dalla rete e dalle definizioni dello stack TCP, non da CPU, RAM o disco, usare instance più grandi non cambia granché.
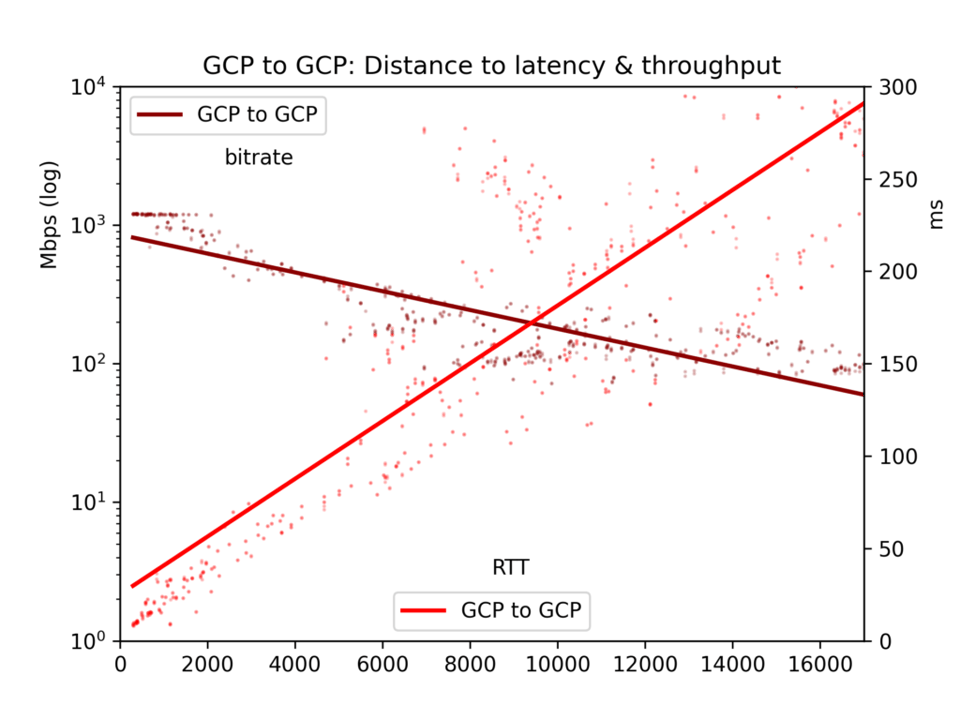
L'unica eccezione riguarda le regioni GCP molto vicine tra loro, dove il throughput raggiunge dei tetti legati alle risorse disponibili. Si vedano i grafici. Questo, comunque, non incide sulle conclusioni riassunte di seguito.
Costi
Avviare un'instance in ogni regione non comporta una spesa elevata: queste piccole instance costano tra 0,5 e 2 centesimi all'ora. Grazie alla parallelizzazione, la suite di test si esegue rapidamente e i costi delle instance restano sotto i 2 dollari per un test completo. Il volume di dati è di 10 MB per test, e i costi di egress rappresentano la maggior parte della spesa: fino a 20 dollari per un test che copre tutte le regioni.
Output
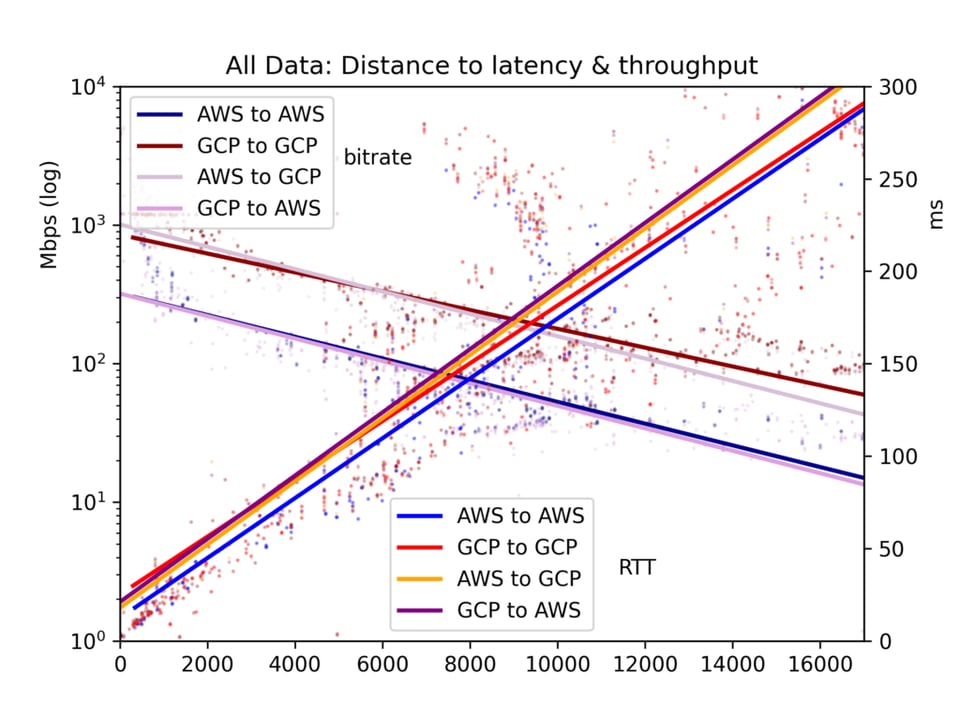
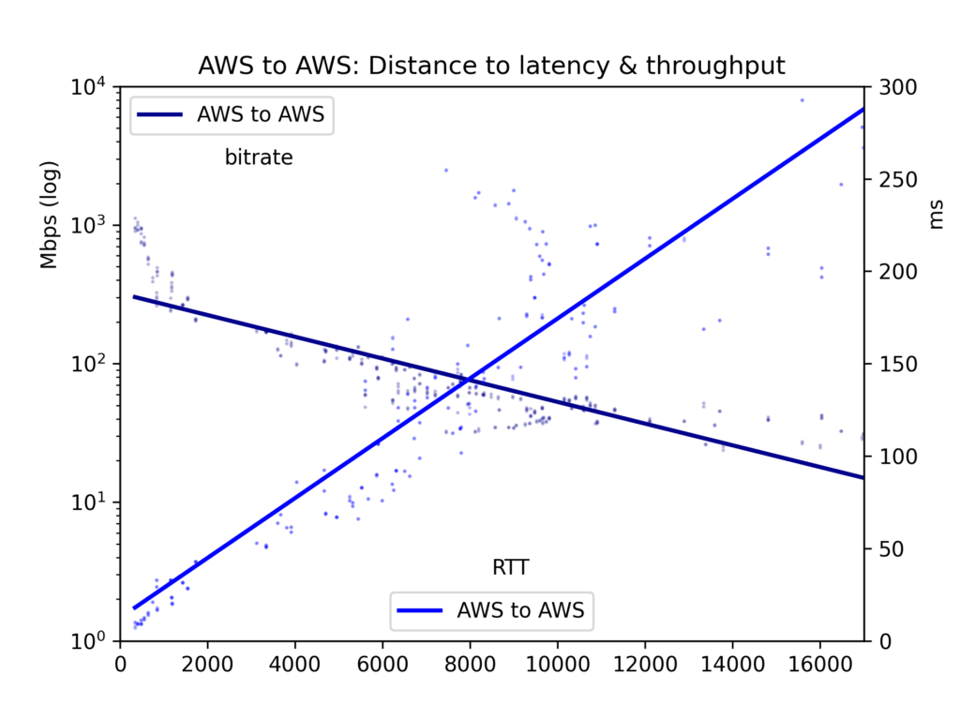
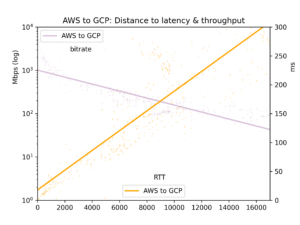
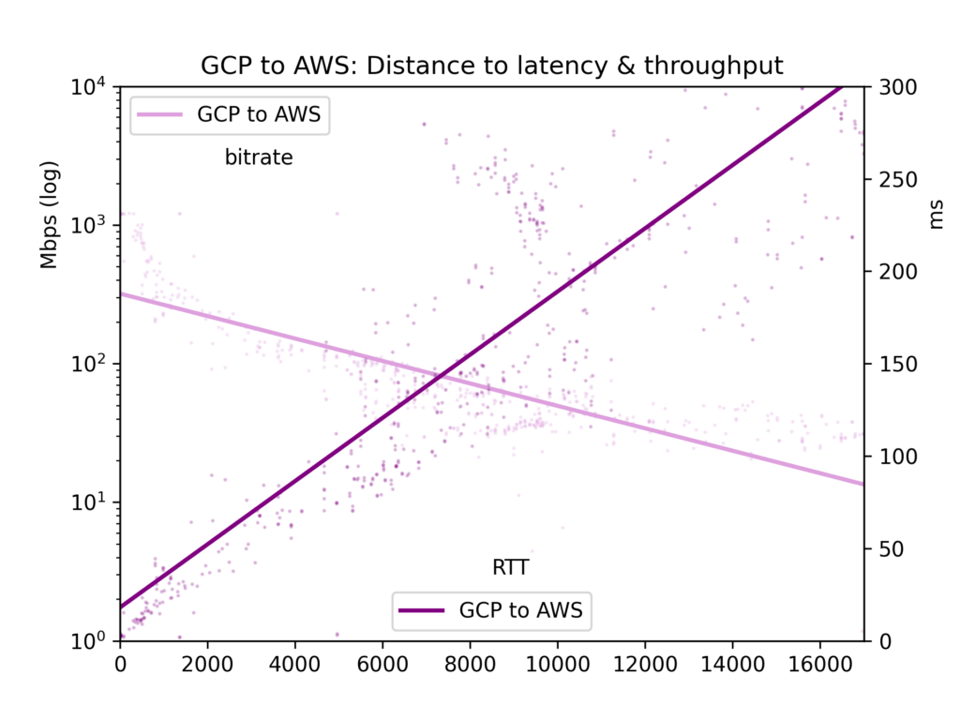
Il round-trip time medio e il bitrate vengono raccolti in un file CSV e presentati in cinque grafici: tutte le coppie di cloud, GCP-to-GCP, GCP-to-AWS, AWS-to-GCP e AWS-to-AWS.
Risultati dei test sul throughput
I risultati presentano molto rumore. Sull'internet pubblica, congestione e ribilanciamenti BGP possono influenzare in modo significativo sia la latenza sia il throughput. I dati offrono comunque indicazioni chiare. Latenza e throughput risultano effettivamente migliori all'interno di un singolo cloud rispetto alle comunicazioni cross-cloud, anche se forse la differenza è meno marcata di quanto ci si aspetti.
Sul nostro tema centrale, gli effetti della distanza, si nota che la latenza è lineare rispetto alla distanza (correlazione r=0,92). La velocità della luce e una minima elaborazione da parte dei router incidono dunque sul tempo in modo abbastanza diretto. Il throughput è molto più irregolare, perché i buffer TCP e altri colli di bottiglia rallentano la trasmissione in modo meno lineare; risulta tuttavia chiaramente log-proporzionale alla distanza (r=-0,7).
Si vedano i grafici qui sotto. Il risultato principale è questo: sebbene in linea di principio un imponente fiume di dati possa scorrere lentamente per lunghe distanze, nella pratica i buffer TCP fanno sì che la latenza — e quindi la distanza — ostacolino il throughput. Per trasferire grandi volumi di dati tra cloud, conviene individuare le posizioni fisiche e scegliere la regione più vicina.