Presentamos una nueva herramienta para medir throughput y latencia entre regiones
A veces la nube parece un espacio extradimensional, donde cualquier volumen de datos puede fluir en un tiempo casi nulo. Pero los límites fundamentales del espacio-tiempo y del protocolo TCP hacen que la simple distancia física marque una gran diferencia. Si te cuesta mover grandes volúmenes de datos de una nube a otra, conviene ubicar el destino lo más cerca posible del origen.
En este artículo analizamos el throughput y la latencia, dos métricas de red muy distintas pero correlacionadas para medir flujos de datos, y presentamos una nueva herramienta para medirlas entre regiones.
La latencia impacta el throughput
La latencia, o tiempo de ida y vuelta, mide los milisegundos que pasan desde que se envía una solicitud hasta que se recibe la respuesta. El throughput es la cantidad de bits por segundo que se transmiten.
Puedes tener un throughput alto sin baja latencia, y viceversa. Como el río Mississippi, los datos pueden fluir en grandes volúmenes por segundo y tardar mucho en ir del punto A al punto B, o moverse como rápidos veloces (con apenas unos pocos bytes por segundo) y aun así llegar a destino a la velocidad del rayo.
Aun así, en la práctica, la latencia afecta directamente al throughput en el protocolo más común: TCP. Es un protocolo orientado a conexión que requiere acuses de recibo por cada paquete y los reenvía cuando hace falta. El buffer de envío de TCP guarda todos los datos enviados pero aún no confirmados por el host remoto, lo que permite retransmitir paquetes no confirmados. Sin embargo, el buffer tiene un tamaño limitado, así que la transmisión se pausa si quedan demasiados mensajes sin confirmar dentro de esa ventana. Por ejemplo, con un tiempo de ida y vuelta de 80 ms y una ventana TCP típica de 64 KByte, el throughput máximo apenas llega a 66 Mbit/seg ( consulta esta calculadora). Es muchísimo menos que los gigabytes por segundo que se anuncian en la nube.
Esa última métrica es el ancho de banda: la cantidad máxima de bits por segundo que podrías obtener según el canal que pagaste. El throughput puede ser mucho menor que el ancho de banda cuando cuellos de botella como la ventana TCP imponen límites.
Cómo maximizar el throughput cuando hay alta latencia
Si quieres que grandes volúmenes de datos circulen por un canal TCP de alta latencia, vas a tener que hacer algo distinto.
- Envía varios streams a la vez, hasta el límite del ancho de banda. Pero esto suele estar limitado por la forma en que se espera usar una API determinada; por ejemplo, si está pensada para enviar grandes volúmenes de datos en una sola respuesta o impone rate-limits a las invocaciones.
- Usa un protocolo sin conexión como UDP y encárgate tú mismo de la retransmisión. Solo es posible cuando tienes control sobre todo el stack. En particular, la mayoría de las versiones de HTTP(S), que hoy se usa habitualmente para APIs, corren sobre TCP. (Ten en cuenta que algunos protocolos sobre UDP, como el reciente HTTP 3/QUIC, también ofrecen retransmisión y, por lo tanto, presentan el mismo problema básico de buffers de transmisión).
- Cambia parámetros de TCP, como el tamaño de ventana, a nivel del sistema operativo. Sin embargo, en la nube muchas veces trabajas con servicios serverless que no te dan ese control.
- Eso significa que la única variable que queda es minimizar la distancia. Esto cobra especial relevancia cuando te mueves entre nubes, porque cada proveedor cloud suele tener redes privadas que conectan sus regiones.
En la nube, la capa de red suele ser confiable y ofrece alto ancho de banda, porque los grandes proveedores cloud pueden invertir en lo mejor. El tráfico dentro de una misma nube es extremadamente rápido y, aun entre proveedores cloud distintos, sigue siendo muy superior al de hogares, oficinas e incluso data centers on-premise.
La velocidad de la luz es finita
Más allá de la congestión en internet pública, la distancia y la velocidad de la luz son los mayores límites de la latencia. La distancia máxima posible es entre dos puntos antípodas, donde el ida y vuelta equivale a la circunferencia completa de la Tierra: 130 milisegundos-luz, y otras rutas transcontinentales son una buena fracción de eso. Si a eso le sumas los retrasos del procesamiento en ruta, incluso con los routers altamente optimizados que se usan hoy, enviar datos a miles de kilómetros y recibir respuesta toma una cantidad considerable de milisegundos. Y esa latencia limita de raíz el throughput de la transmisión TCP.
Una nota sobre el costo
Este artículo trata sobre todo del throughput y la latencia, pero no olvides la otra métrica: el costo. Las nubes cobran por la transferencia de datos, en orden decreciente de costo: egreso de datos fuera de su servicio, entre regiones de su nube y entre zonas.
Medición de throughput en la nube: una nueva herramienta
Escribí una herramienta open-source para medir throughput y latencia entre regiones, tanto dentro de cada nube como entre nubes. Es compatible con AWS y Google Cloud Platform.
Hasta donde sé, es una de las primeras en hacerlo. Las métricas existentes se enfocan más en la latencia que en el throughput, y la mayoría se concentra en la red dentro de una nube, no entre nubes.
Cómo funciona
Throughput y latencia
La herramienta Intercloud Latency funciona lanzando pequeñas máquinas virtuales en distintas regiones. Luego ejecuta una prueba con iperf, una herramienta para medir throughput, y con ping, para medir latencia.
Ejecuta performance_test.py --help para ver la documentación.
Pruebas inter-región
Las pruebas se ejecutan de una región a otra. Por defecto, no se realizan pruebas intra-región, porque las métricas dentro de una región son demasiado buenas para ser comparables con las inter-región.
Considerando todas las regiones de GCP y todas las regiones de AWS habilitadas por defecto, son 46 regiones y n * (n - 1) (es decir, 2070) pares de prueba.
Distancias
Las distancias se basan en las ubicaciones de los data centers recopiladas de diversas fuentes abiertas. Aunque los proveedores cloud no publican las ubicaciones exactas, tampoco son un secreto.
Aun así, esas ubicaciones no deben tomarse como exactas. Cada región se distribuye en varias zonas (de disponibilidad), que en algunos casos están separadas entre sí por decenas de kilómetros para mayor robustez. (Mira aquí el mapa de Wikileaks, que lo ilustra claramente). Se usan las coordenadas del centro de la ciudad como aproximación. Aun así, dadas las velocidades medidas aquí, las estadísticas que dependen de la ubicación aproximada de la región son lo bastante precisas como para que cualquier error quede absorbido por otras variaciones del comportamiento de la red.
Opciones
Si no quieres probar todas las regiones a la vez, hay opciones para limitar la elección de pares de regiones.
Puedes designar pares de regiones específicos. También puedes dejar que el sistema elija los pares, restringiendo la selección a:
- Una sola nube,
- Pares inter-nube específicos (por ejemplo, solo GCP-a-AWS o GCP-a-GCP),
- Un rango específico de distancias inter-región: la distancia mínima y máxima entre dos regiones para probarlas juntas.
- También puedes limitar la cantidad máxima de regiones seleccionadas.
Aunque por defecto las pruebas se ejecutan en paralelo para optimizar velocidad y costo, puedes configurarlas para que corran en lotes secuenciales.
Los tipos de máquina virtual (instancia) que se usan son pequeños y comparables entre AWS y GCP. También puedes elegir los tipos de máquina. Es importante recordar que esto no es una prueba para lograr baja latencia y alto throughput: es una comparación de esas métricas a distintas distancias, así que lo único que importa es que las pruebas sean comparables. Sin embargo, como incluso las instancias más pequeñas tienen ancho de banda asignado en gigabits por segundo, y como esta prueba está limitada por la red y por las definiciones del stack TCP, no por CPU, RAM o disco, usar instancias más grandes no marca mucha diferencia.
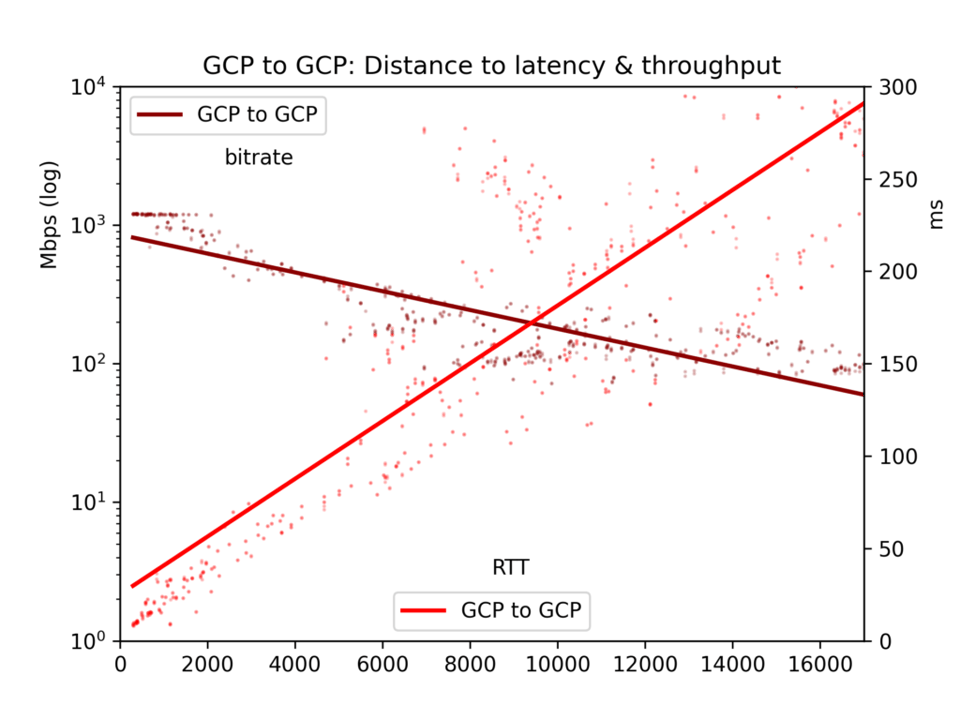
Hay una excepción: en regiones de GCP muy cercanas entre sí, el throughput choca con techos basados en los recursos disponibles. Mira las gráficas. De todos modos, esto no afecta las conclusiones que se resumen abajo.
Costo
Lanzar una instancia en cada región no cuesta mucho: estas instancias pequeñas cuestan entre 0,5 y 2 centavos por hora. Gracias a la paralelización, la suite de pruebas corre rápido y los cargos por instancia se mantienen por debajo de los 2 USD para una prueba completa. El volumen de datos es de 10 MB por prueba, y los cargos de egreso son la mayor parte del gasto, hasta 20 USD para una prueba que cubra todas las regiones.
Salida
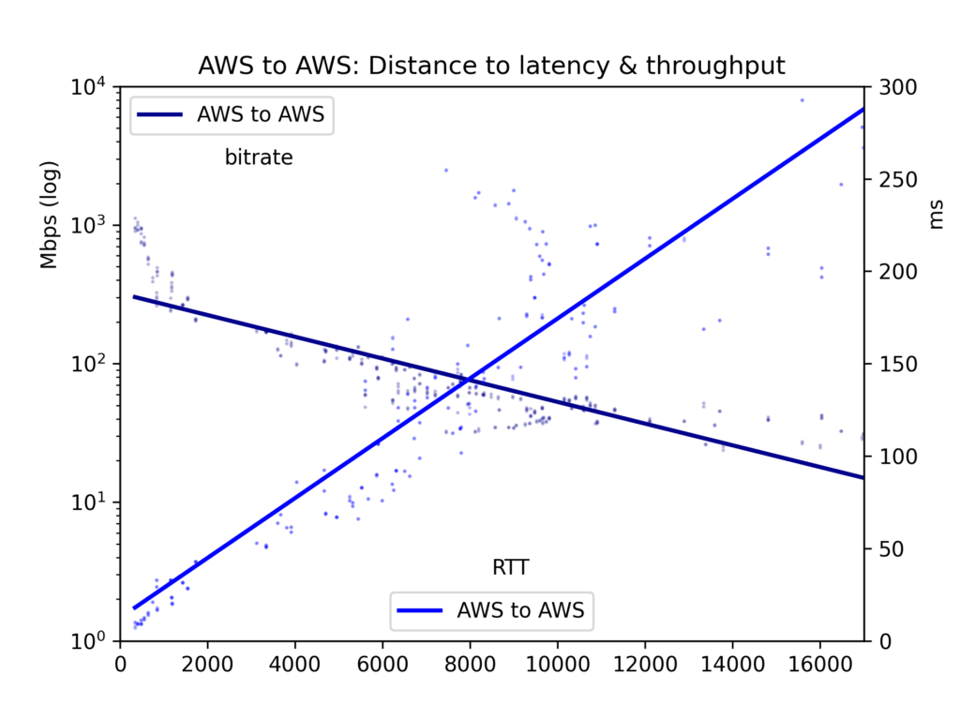
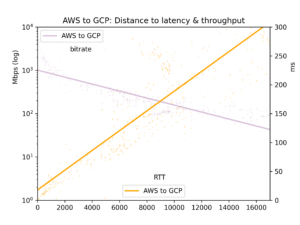
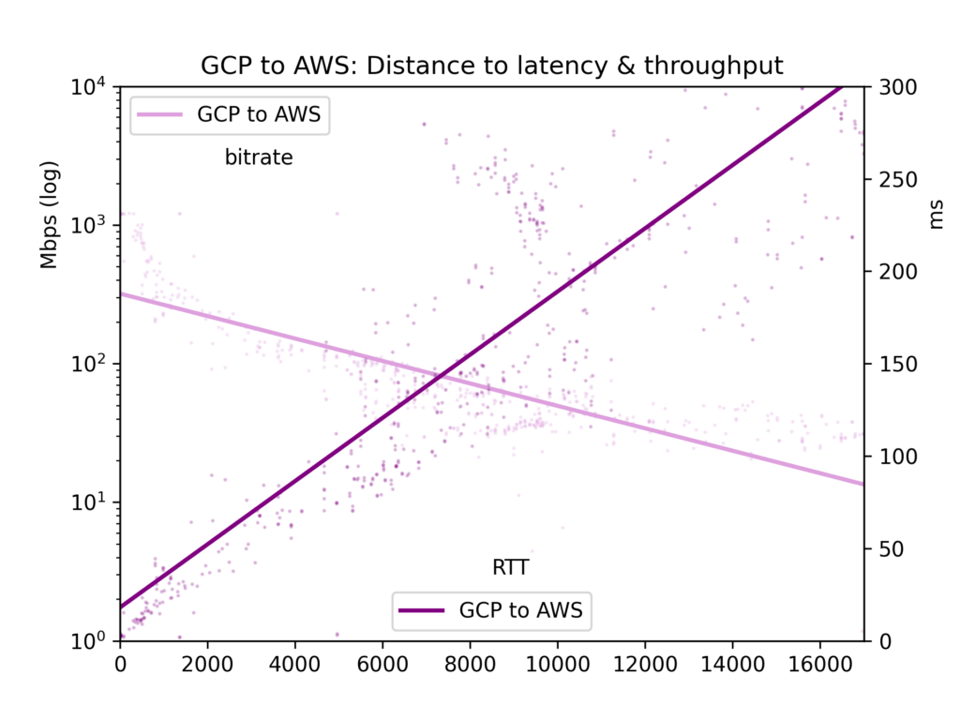
El tiempo medio de ida y vuelta y la tasa de bits se recopilan en un archivo CSV y se presentan en cinco gráficas: todos los pares de nubes, GCP-a-GCP, GCP-a-AWS, AWS-a-GCP y AWS-a-AWS.
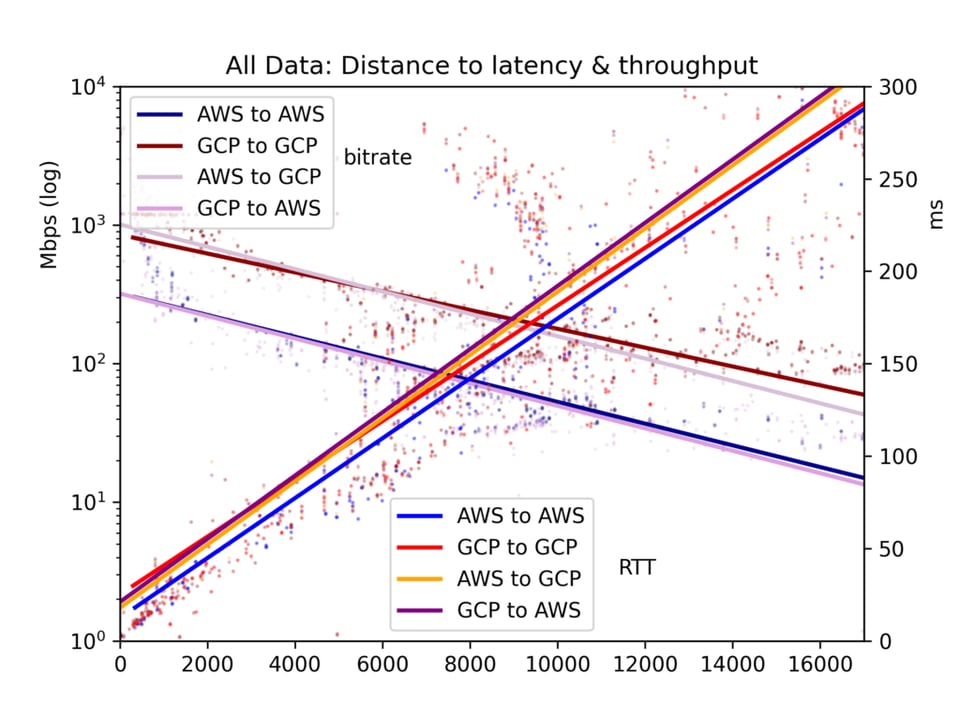
Resultados de las pruebas de throughput
Los resultados son ruidosos. En internet pública, la congestión y el rebalanceo de BGP pueden afectar mucho tanto la latencia como el throughput. Aun así, los resultados arrojan conclusiones claras. La latencia y el throughput sí son mejores dentro de una nube que entre nubes, aunque quizá no tan distintos como uno pensaría.
En lo que aquí nos interesa principalmente, los efectos de la distancia, vemos que la latencia es lineal respecto a la distancia (correlación r=0,92). Así que la velocidad de la luz y un mínimo procesamiento de los routers se traducen en tiempo de manera bastante directa. El throughput es mucho más irregular, ya que los buffers TCP y otros cuellos de botella ralentizan la transmisión de forma menos lineal, pero el throughput es claramente log-proporcional a la distancia (r=-0,7).
Mira las gráficas a continuación. La conclusión principal es esta: aunque en teoría un río masivo de datos puede fluir lentamente a gran distancia, en la práctica los buffers TCP hacen que la latencia, y por ende la distancia, frenen el throughput. Si quieres descargar grandes volúmenes de datos entre nubes, consulta las ubicaciones físicas y elige la región más cercana.