Lors de l'AWS re:Invent 2024, Amazon a annoncé les Amazon S3 Tables, des tables Apache Iceberg entièrement managées et optimisées pour les workloads analytiques. Elles s'appuient sur un stockage managé au format Iceberg, pilotable via l'API s3tables. Côté traitement des données, l'intégration se fait avec Apache Spark ou les services analytiques AWS — Amazon EMR, Amazon Athena, Amazon Redshift, Amazon QuickSight et Amazon Data Firehose.

Image générée avec Amazon Bedrock
Pour commencer
Première étape : créer un table bucket, soit depuis la console, soit via l'AWS CLI. À cette occasion, vous pouvez activer son intégration avec les services analytiques AWS cités plus haut.
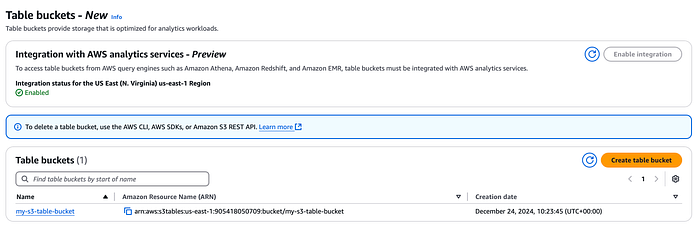
Console S3 Table bucket
Une fois le table bucket créé, créez un namespace (à voir comme une base de données logique regroupant plusieurs tables), qui hébergera vos tables.
aws s3tables create-namespace \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace
aws s3tables create-table \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace \
--name my_first_table --format ICEBERG
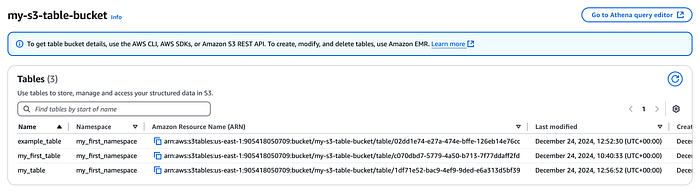
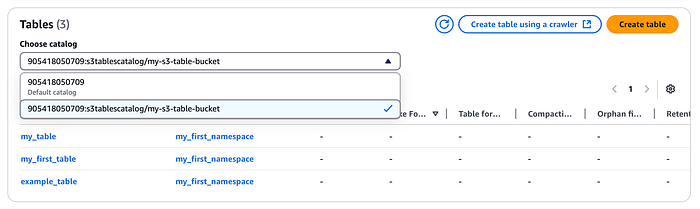
Tables créées dans la console table bucket
Le format de table repose sur le framework Apache Iceberg ; le stockage sous-jacent regroupe à la fois les données de la table et ses métadonnées. Avec les S3 Tables, plus besoin de gérer la maintenance vous-même : Amazon S3 s'en charge pour optimiser les performances de vos S3 Tables et table buckets. Au programme : compaction des fichiers, gestion des snapshots et suppression des fichiers non référencés. Ces opérations sont activées par défaut. Vous pouvez les modifier ou les désactiver via les fichiers de configuration de maintenance, ou encore ajuster les paramètres des jobs de maintenance selon vos besoins. Le statut des jobs se consulte via l'API s3tables.
aws s3tables get-table-maintenance-job-status \
--table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \
--namespace="mynamespace" \
--name="testtable"
Avant de connecter les S3 Tables aux services analytiques, complétez les étapes préalables.
Créez ensuite un nouveau catalogue dédié aux S3 Tables :
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'
Ce catalogue sera enregistré dans AWS Lake Formation. Vous y retrouverez aussi le namespace et la table créés précédemment depuis la console Lake Formation (utilisez le menu déroulant pour sélectionner le catalogue S3 Table créé ci-dessus).
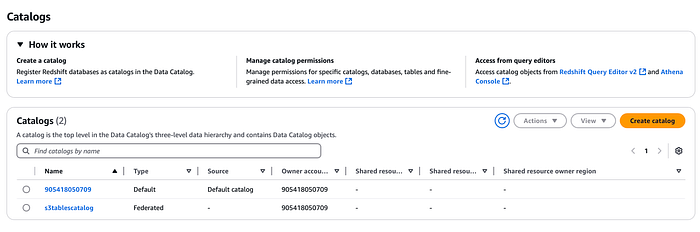
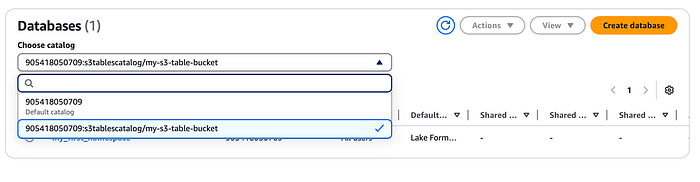
Intégration avec Amazon EMR
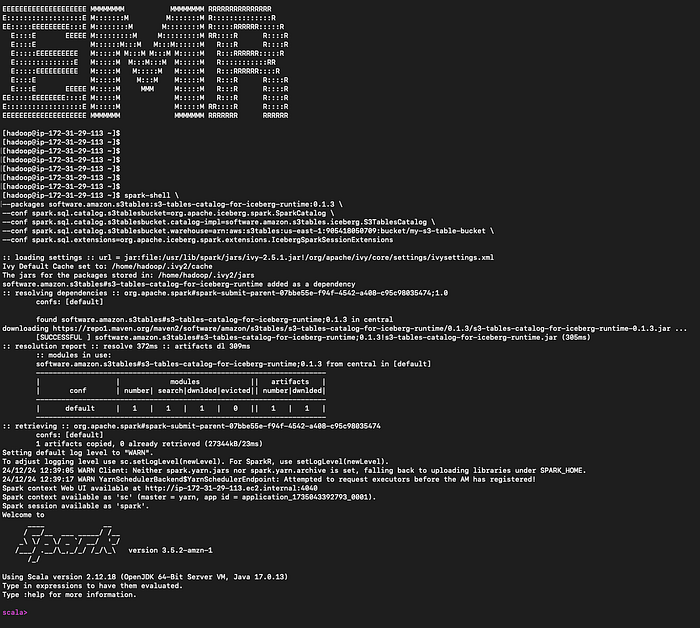
Place maintenant à la partie la plus intéressante : connecter les S3 Tables aux services AWS. Commençons par Amazon EMR en provisionnant un cluster EMR compatible Iceberg avec Apache Spark. Connectez-vous ensuite au nœud principal du cluster en SSH.
Lancez le spark-shell :
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
Spark-shell sur le nœud principal EMR
Vérifiez que vous avez bien suivi les prérequis liés à l'intégration. Pour Amazon EMR, attachez la policy AmazonS3TablesFullAccess au rôle EMR_EC2_DefaultRole et accordez à ce même rôle les permissions Lake Formation nécessaires au niveau du catalogue, du namespace et des tables.
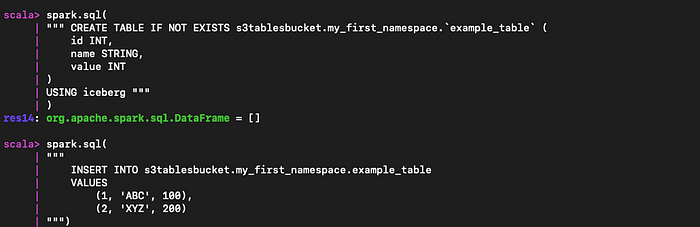
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg """
)
spark.sql(
"""
INSERT INTO s3tablesbucket.my_first_namespace.example_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show()

Création d'un nouveau namespace pour le table bucket
Création d'une nouvelle table dans le namespace

Interrogation de la table
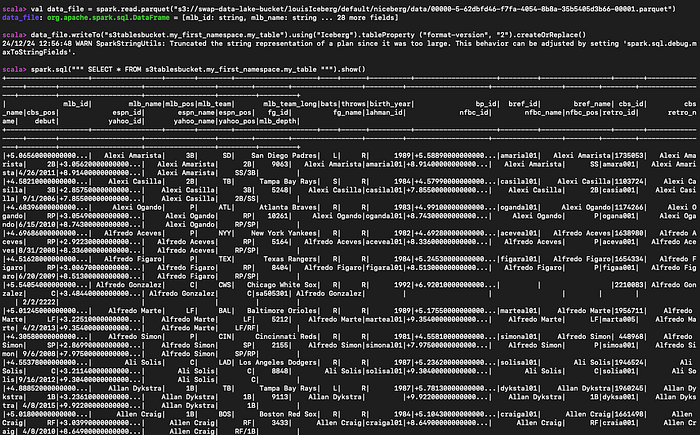
Si vous disposez d'un échantillon de données parquet sur S3, vous pouvez les lire, créer une S3 Table associée et l'interroger :
#Read the parequet file
val data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Create a new table
data_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Query the table we created
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()
Intégration avec Amazon Athena
Connectons à présent cette table à Amazon Athena. Le catalogue créé pour les S3 Tables apparaît dans la section Sources de données et catalogues de la console Athena : sélectionnez-le dans le menu déroulant de l'éditeur pour afficher les S3 Tables.
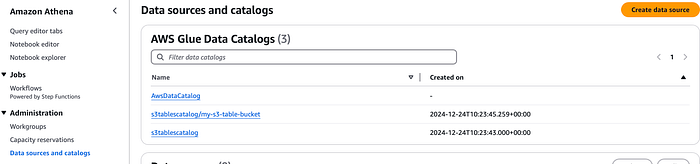
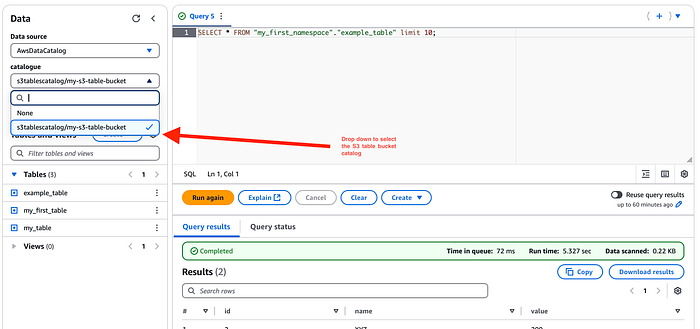
Vous pouvez désormais interroger ces tables aussi facilement que des tables natives du catalogue Glue dans Athena.
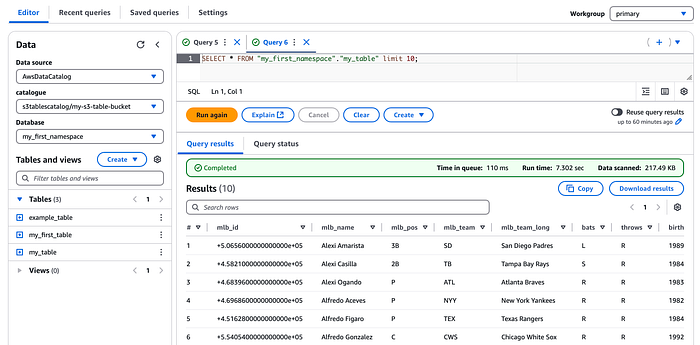
À noter : les S3 Tables étant managées par S3, vous n'avez pas accès à l'emplacement S3 sous-jacent et ne pouvez pas interroger les fichiers manifest comme lors de l'interrogation des métadonnées Iceberg pour les tables Amazon Athena.
Les Amazon S3 Tables permettent de créer des tables logiques au-dessus de vos données stockées dans S3 au format parquet, pour des performances de lecture optimisées. Reposant sur le format Iceberg, elles prennent en charge les transactions ACID et autorisent les opérations d'update, de delete et d'insert, ainsi que les requêtes time-travel sur vos données. Le tout est géré par Amazon S3, avec en prime la durabilité, la scalabilité et la performance propres à S3.
Pour en savoir plus ou découvrir nos services, n'hésitez pas à nous contacter ici.