No AWS re:invent 2024, a AWS anunciou o Amazon S3 Tables, que oferece tabelas Apache Iceberg totalmente gerenciadas e otimizadas para workloads analíticos. Essas tabelas têm armazenamento gerenciado em formato Iceberg e podem ser administradas pela API s3tables. Já as operações de dados podem ser feitas via Apache Spark ou pelos serviços analíticos da AWS — Amazon EMR, Amazon Athena, Amazon Redshift, Amazon EMR, Amazon QuickSight e Amazon Data Firehose.

Gerado com o Amazon Bedrock
Primeiros passos
Para começar, você precisa criar um table bucket, seja pelo console ou pela AWS CLI. Nesse momento, você tem a opção de habilitar a integração desse table bucket com os serviços analíticos da AWS citados acima.
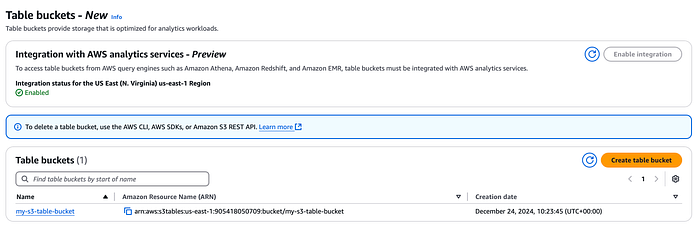
Console do S3 Table bucket
Depois de criar o table bucket, é hora de criar um namespace (pense nele como um banco de dados lógico que vai abrigar várias tabelas), onde ficarão as nossas tabelas.
aws s3tables create-namespace \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace
aws s3tables create-table \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace \
--name my_first_table --format ICEBERG
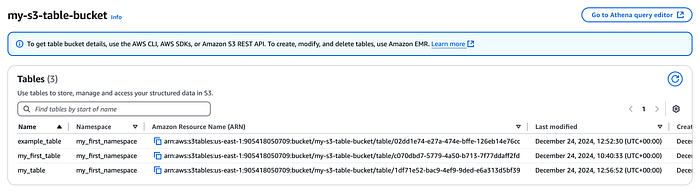
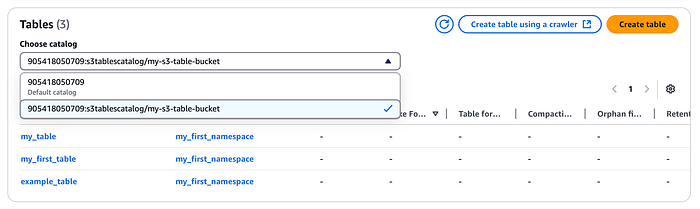
Tabelas criadas no console do table bucket
O formato da tabela é baseado no framework Apache Iceberg, e o armazenamento subjacente guarda tanto os dados quanto os metadados da tabela. Com o S3 tables, você não precisa se preocupar com a manutenção: o Amazon S3 cuida disso para melhorar o desempenho dos seus S3 tables e table buckets. As opções de manutenção incluem compactação de arquivos, gerenciamento de snapshots e remoção de arquivos não referenciados — todas habilitadas por padrão. Você pode editá-las ou desativá-las pelos arquivos de configuração de manutenção. Também é possível configurar os parâmetros do job de manutenção com os valores que fizerem mais sentido para o seu caso. O status do job pode ser consultado pela API s3tables.
aws s3tables get-table-maintenance-job-status \
--table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \
--namespace="mynamespace" \
--name="testtable"
Antes de integrar o S3 tables aos serviços analíticos, conclua as etapas de pré-requisitos.
Crie um novo catálogo para o S3 tables
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'
Esse catálogo será registrado no AWS LakeFormation e, da mesma forma, você verá o namespace e a tabela que criamos antes no console do LakeFormation (use o menu suspenso para selecionar o catálogo do S3 table que criamos acima).
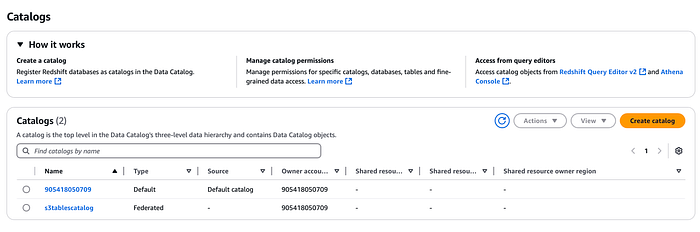
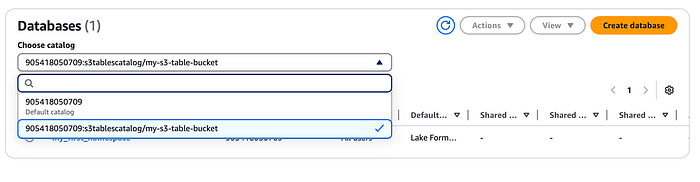
Integração com o Amazon EMR
Agora vem a parte legal! É hora de integrar esses S3 tables aos serviços da AWS. Vou começar pelo Amazon EMR e provisionar um cluster EMR habilitado para Iceberg com Apache Spark. Depois, faça login no nó primário do cluster via SSH.
Inicie o spark-shell
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
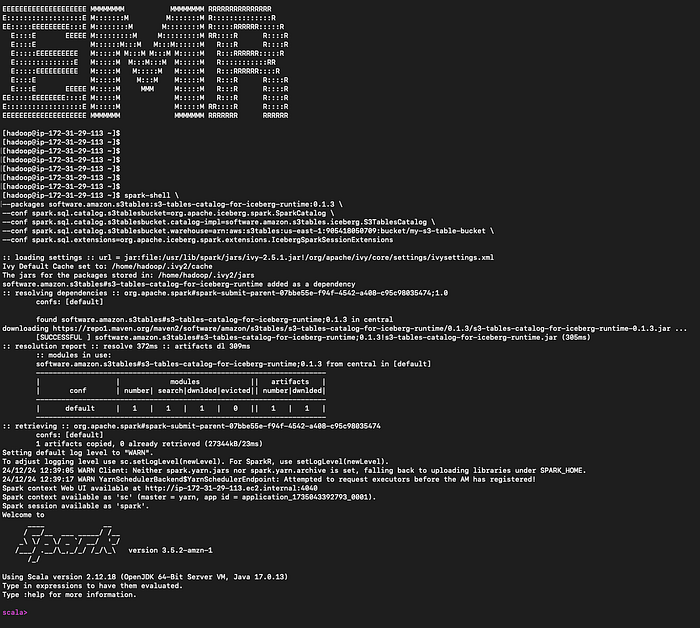
Spark-shell no nó primário do EMR
Confira se você seguiu corretamente os pré-requisitos para a integração. No Amazon EMR, é preciso anexar a política AmazonS3TablesFullAccess à EMR_EC2_DefaultRole e também conceder à EMR_EC2_DefaultRole as permissões adequadas no LakeFormation, em nível de catálogo, namespace e tabela.
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg """
)
spark.sql(
"""
INSERT INTO s3tablesbucket.my_first_namespace.example_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show()

Crie um novo namespace para o table bucket
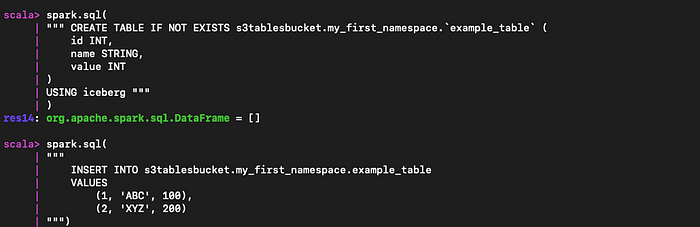
Crie uma nova tabela baseada em table bucket dentro do namespace

Consulte a tabela
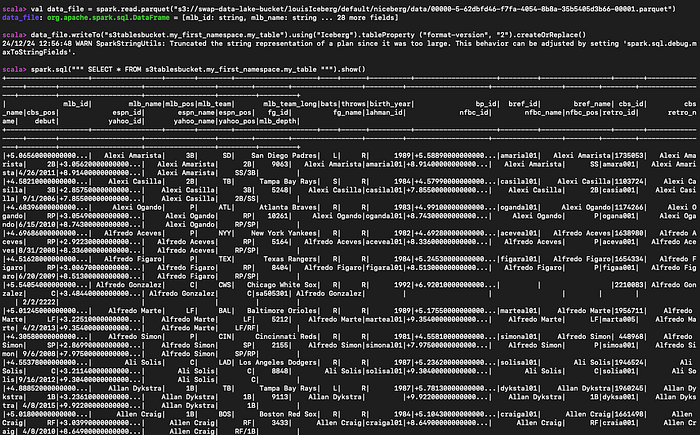
Se você tiver dados de exemplo em parquet no S3, dá para lê-los, criar um S3 table com base neles e consultá-los.
#Read the parequet file
val data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Create a new table
data_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Query the table we created
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()
Integração com o Amazon Athena
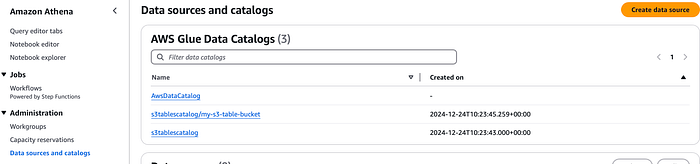
Agora vamos integrar essa tabela ao Amazon Athena! Como já criamos um catálogo para o S3 tables, ele aparece em Data sources and catalogs no console do Athena. Basta selecionar a opção no menu suspenso do editor para visualizar os s3 tables.
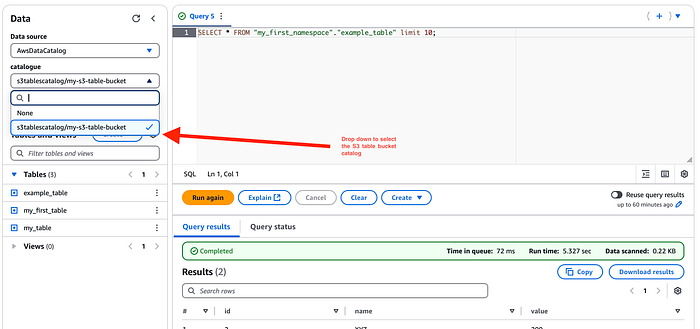
Pronto, agora você consulta essas tabelas como se fossem tabelas nativas do catálogo Glue no Athena.
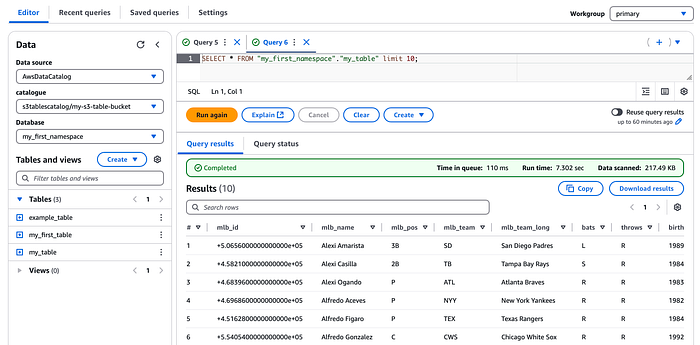
Vale lembrar: como os s3 tables são gerenciados pelo S3, você não tem acesso ao local de armazenamento subjacente no S3 e não consegue consultar os arquivos manifest, diferentemente do que ocorre ao consultar metadados de tabelas Iceberg em tabelas baseadas no Amazon Athena.
Referências:
O Amazon S3 tables permite criar tabelas lógicas sobre os seus dados no S3, armazenados em formato parquet para um desempenho de leitura otimizado. Essas tabelas usam o formato Iceberg, que não só dá suporte a transações ACID, como também permite executar updates, deletes e inserts, além de consultas com time-travel nos seus dados. Tudo isso é gerenciado pelo Amazon S3, com os benefícios de durabilidade, escalabilidade e desempenho do S3.
Quer saber mais ou tem interesse nos nossos serviços? Não hesite em entrar em contato. Fale com a gente aqui.