先日のAWS re:Invent 2024で、分析workloads向けに最適化されたフルマネージドのApache Icebergテーブルを提供するAmazon S3 Tablesが発表されました。これらのテーブルはマネージドストレージ上のIceberg形式テーブルで、s3tables APIを通じて管理できます。データ操作の面では、Apache SparkやAWSの分析サービス(Amazon EMR、Amazon Athena、Amazon Redshift、Amazon EMR、Amazon QuickSight、Amazon Data Firehose)と連携可能です。

Amazon Bedrockで生成
はじめに
まずは、コンソールまたはAWS CLIからテーブルバケットを作成します。作成時には、上述のAWS分析サービスとの連携を有効化するオプションも選択できます。
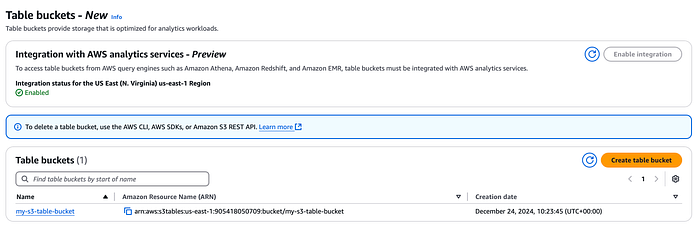
S3テーブルバケットのコンソール画面
テーブルバケットを作成したら、続いてネームスペース(複数のテーブルを格納する論理データベースのようなもの)を作成し、その中にテーブルを配置していきます。
aws s3tables create-namespace \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace
aws s3tables create-table \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace \
--name my_first_table --format ICEBERG
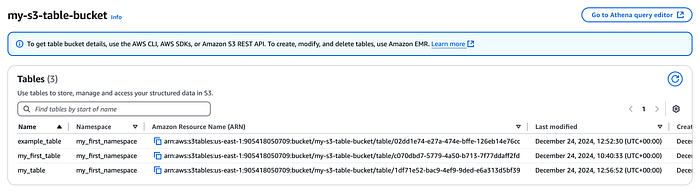
テーブルバケットコンソールに作成されたテーブル
テーブル形式はApache Icebergフレームワークに基づき、ストレージにはテーブルデータとそのメタデータの両方が保持されます。S3 Tablesではテーブルメンテナンスを自前で行う必要はなく、Amazon S3側がメンテナンスを実施し、S3テーブルやテーブルバケットのパフォーマンスを最適化してくれます。メンテナンスの内容はファイルコンパクション、スナップショット管理、未参照ファイルの削除で、いずれもデフォルトで有効化されています。これらの動作はメンテナンス設定ファイルから編集・無効化が可能で、必要に応じてメンテナンスジョブのパラメータを環境に合わせて調整することもできます。ジョブの実行状況はs3tables APIで確認できます。
aws s3tables get-table-maintenance-job-status \
--table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \
--namespace="mynamespace" \
--name="testtable"
S3 Tablesを分析サービスと連携させる前に、前提条件のステップを完了させておく必要があります。
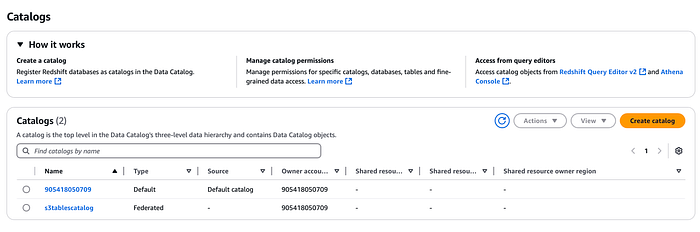
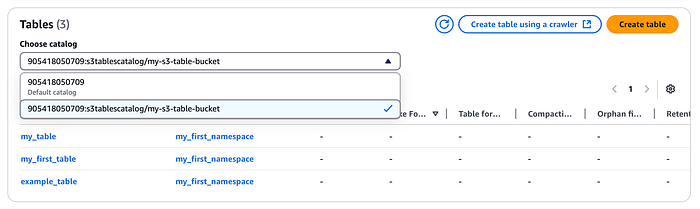
S3 Tables用の新しいカタログを作成します。
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'
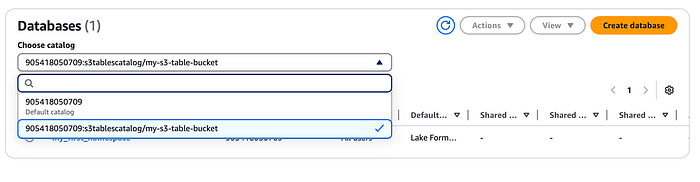
このカタログはAWS LakeFormationに登録されます。LakeFormationコンソールでも、先ほど作成したネームスペースとテーブルを確認できます(ドロップダウンから上で作成したS3テーブルカタログを選択してください)。
Amazon EMRとの連携
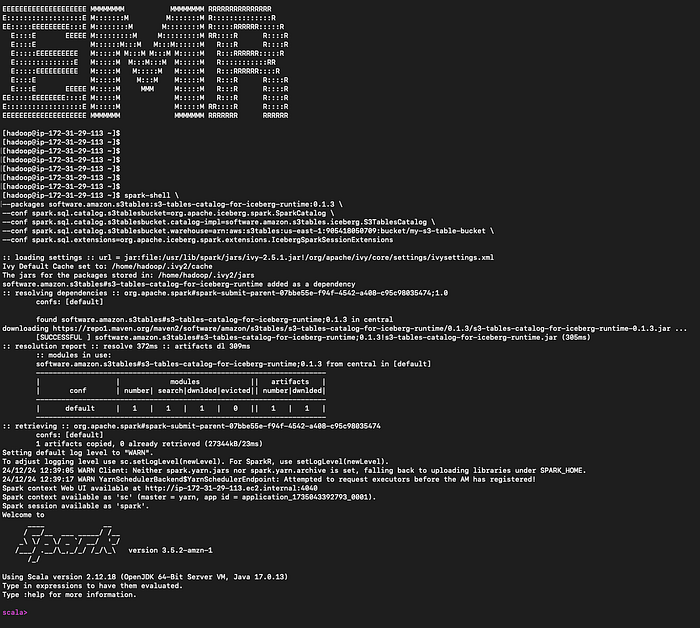
ここからが本題です。S3 TablesをAWSサービスと連携させていきましょう。まずはAmazon EMRから。Apache Sparkを搭載したIceberg対応のEMRクラスタをプロビジョニングし、SSHでクラスタのプライマリノードにログインします。
spark-shellを起動します。
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
EMRプライマリノード上のspark-shell
連携を行う前に、前提条件を満たしているか必ず確認してください。Amazon EMRでは、EMR_EC2_DefaultRoleにAmazonS3TablesFullAccessポリシーをアタッチし、さらにEMR_EC2_DefaultRoleに対してカタログ・ネームスペース・テーブルの各レベルで適切なLakeFormation権限を付与する必要があります。
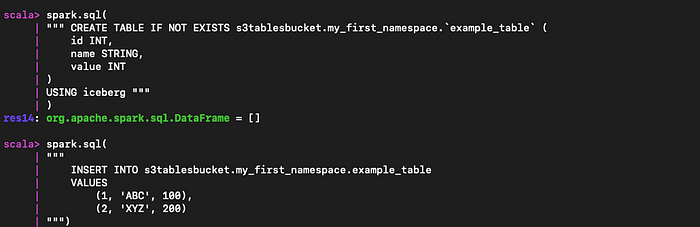
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg """
)
spark.sql(
"""
INSERT INTO s3tablesbucket.my_first_namespace.example_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show()

テーブルバケット用の新しいネームスペースを作成
ネームスペース内にテーブルバケットベースの新しいテーブルを作成

テーブルへのクエリ実行
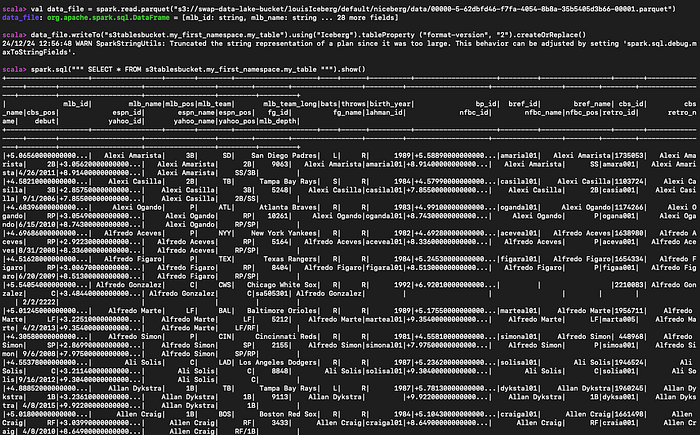
S3にサンプルのparquetデータがあれば、それを読み込んでS3テーブルとして作成し、クエリすることもできます。
#parquetファイルの読み込み
val data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#新しいテーブルを作成
data_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#作成したテーブルへのクエリ
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()
Amazon Athenaとの連携
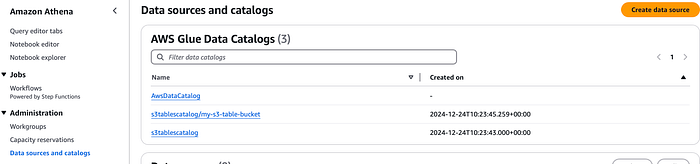
続いて、このテーブルをAmazon Athenaと連携させてみましょう。先ほどS3 Tables用のカタログを作成済みなので、Athenaコンソールの「データソースとカタログ」から確認でき、エディタのドロップダウンを切り替えればS3テーブルが表示されます。
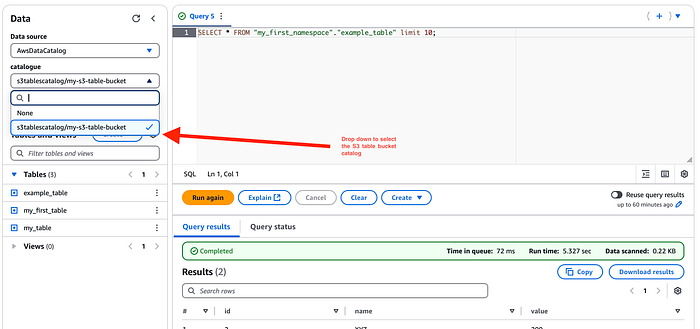
あとはAthena上で、ネイティブのGlueカタログテーブルと同じ感覚でこれらのテーブルにクエリを実行できます。
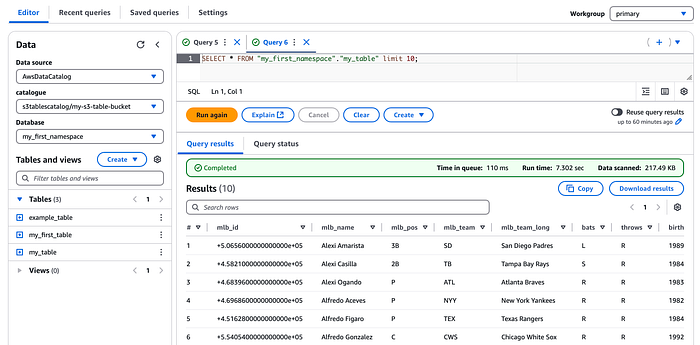
ただし、S3テーブルはS3側で管理されているため、基盤となるS3のデータ保存場所にはアクセスできず、Amazon Athenaベースのテーブルに対するIcebergテーブルメタデータのクエリのように、マニフェストファイルを直接クエリすることはできない点に注意してください。
Amazon S3 Tablesを使えば、読み取りパフォーマンスを最適化したparquet形式でS3に保存されたデータの上に、論理的なテーブルを構築できます。これらのテーブルはIceberg形式に基づいているため、ACIDトランザクションをサポートし、更新・削除・挿入はもちろん、データに対するタイムトラベルクエリまで実行できます。しかも、これらすべてをAmazon S3が管理してくれるため、S3が誇る耐久性・スケーラビリティ・パフォーマンスといったメリットもそのまま享受できます。
さらに詳しく知りたい方や、当社のサービスにご興味をお持ちの方は、お気軽にお問い合わせください。ご連絡はこちらから。