En AWS re:invent 2024 se hizo el anuncio de Amazon S3 Tables: tablas Apache Iceberg totalmente administradas y optimizadas para workloads analíticos. Estas tablas tienen almacenamiento administrado en formato Iceberg, que se gestiona mediante la API s3tables. Para las operaciones de datos, se integran con Apache Spark o con los servicios analíticos de AWS: Amazon EMR, Amazon Athena, Amazon Redshift, Amazon EMR, Amazon QuickSight y Amazon Data Firehose.

Generado con Amazon Bedrock
Primeros pasos
Lo primero es crear un table bucket, ya sea desde la consola o con la AWS CLI. Aquí también puedes habilitar la integración del table bucket con los servicios analíticos de AWS mencionados arriba.
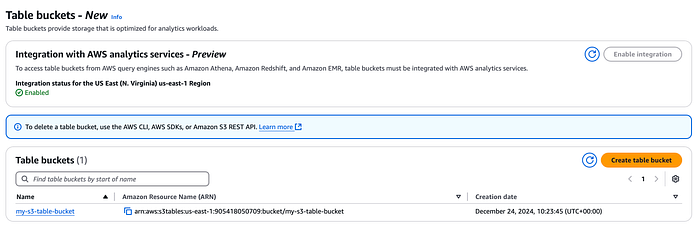
Consola del S3 Table bucket
Una vez creado el table bucket, toca crear un namespace (piénsalo como una base de datos lógica que va a contener varias tablas) dentro del cual estarán nuestras tablas.
aws s3tables create-namespace \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace
aws s3tables create-table \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace \
--name my_first_table --format ICEBERG
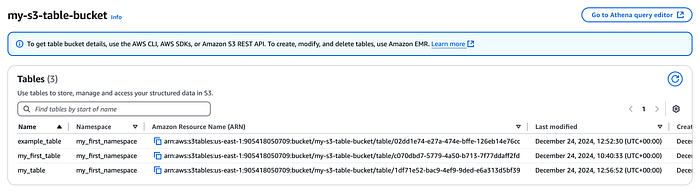
Tablas creadas en la consola del table bucket
El formato de la tabla se basa en el framework Apache Iceberg; el almacenamiento subyacente contiene tanto los datos de la tabla como sus metadatos. Con S3 Tables te olvidas del mantenimiento: Amazon S3 se encarga del mantenimiento para mejorar el rendimiento de tus S3 tables o table buckets. Las opciones de mantenimiento incluyen compactación de archivos, gestión de snapshots y eliminación de archivos sin referencia. Vienen activadas por defecto. Puedes editarlas o desactivarlas desde los archivos de configuración de mantenimiento. Si lo prefieres, también puedes configurar los parámetros del job de mantenimiento con los valores que mejor te funcionen. El estado del job se consulta mediante la API s3tables.
aws s3tables get-table-maintenance-job-status \
--table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \
--namespace="mynamespace" \
--name="testtable"
Antes de integrar S3 Tables con los servicios analíticos, hay que completar los pasos previos.
Crea un nuevo catálogo para S3 Tables.
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'
El catálogo se registrará en AWS LakeFormation y, del mismo modo, podrás ver el namespace y la tabla que creamos antes desde la consola de LakeFormation (tendrás que usar el menú desplegable para seleccionar el catálogo de S3 Tables que creamos arriba).
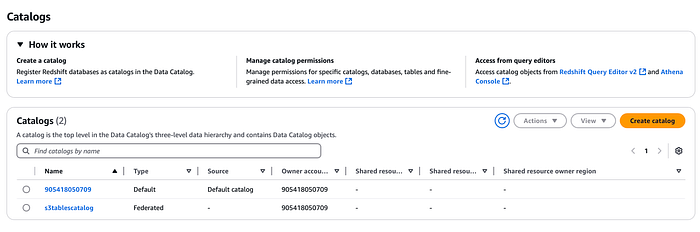
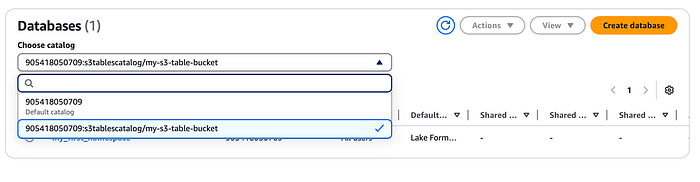
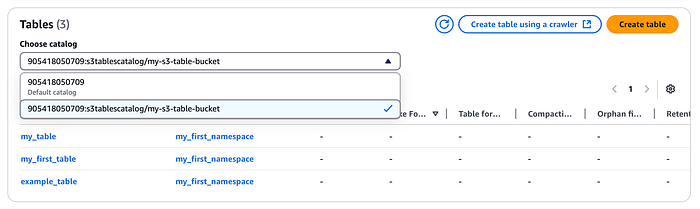
Integración con Amazon EMR
¡Ahora viene lo bueno! Vamos a integrar las S3 tables con los servicios de AWS. Voy a empezar con Amazon EMR y aprovisionaré un clúster EMR habilitado para Iceberg con Apache Spark. Después me conectaré al nodo principal del clúster por SSH.
Inicia el spark-shell.
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
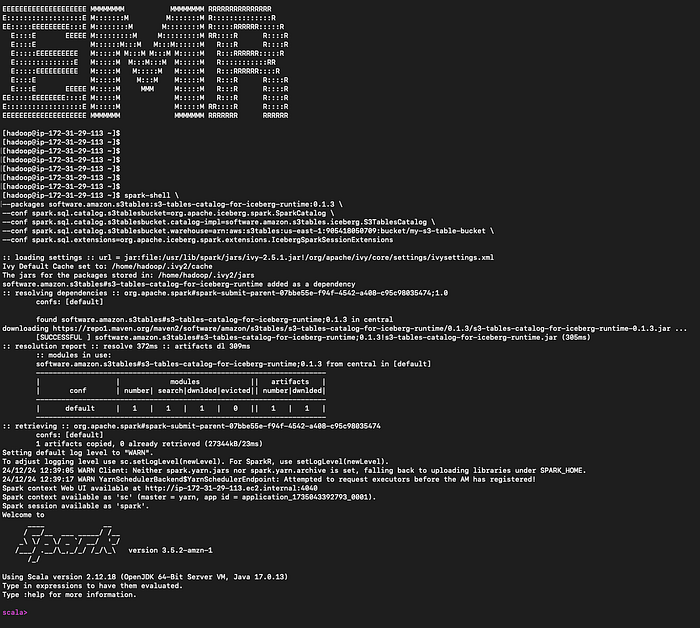
Spark-shell en el nodo principal de EMR
Verifica que hayas seguido correctamente los prerrequisitos de la integración. Para Amazon EMR debes adjuntar la política AmazonS3TablesFullAccess al rol EMR_EC2_DefaultRole y, además, otorgarle a ese mismo rol los permisos correspondientes en LakeFormation a nivel de catálogo, namespace y tabla.
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg """
)
spark.sql(
"""
INSERT INTO s3tablesbucket.my_first_namespace.example_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show()

Crear un nuevo namespace para el table bucket
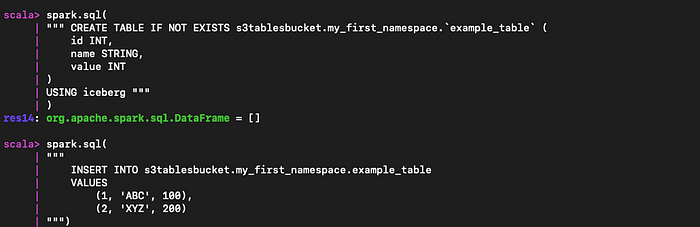
Crear una nueva tabla basada en el table bucket dentro del namespace

Consultar la tabla
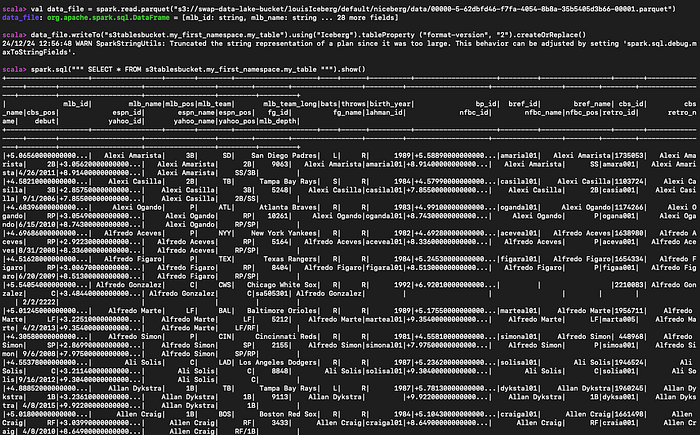
Si tienes datos parquet de ejemplo en S3, puedes leerlos, crear una S3 table a partir de ellos y consultarla.
#Read the parequet file
val data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Create a new table
data_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Query the table we created
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()
Integración con Amazon Athena
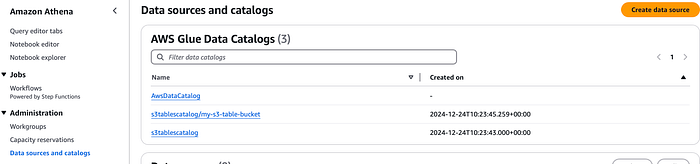
¡Ahora vamos a integrar la tabla con Amazon Athena! Como ya creamos un catálogo para S3 Tables, lo encontrarás en la sección Data sources and catalogs de la consola de Athena. Desde el menú desplegable del editor podrás visualizar las S3 tables.
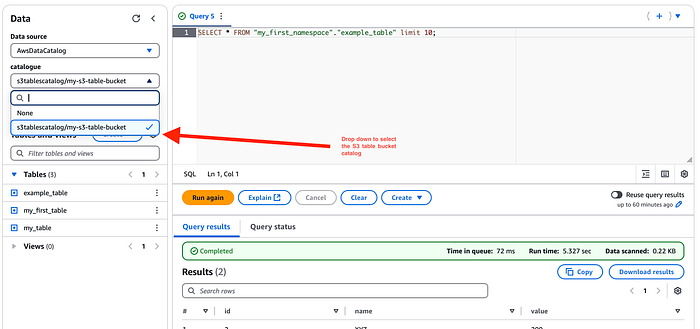
Ya puedes consultar estas tablas igual que las tablas nativas del catálogo Glue en Athena.
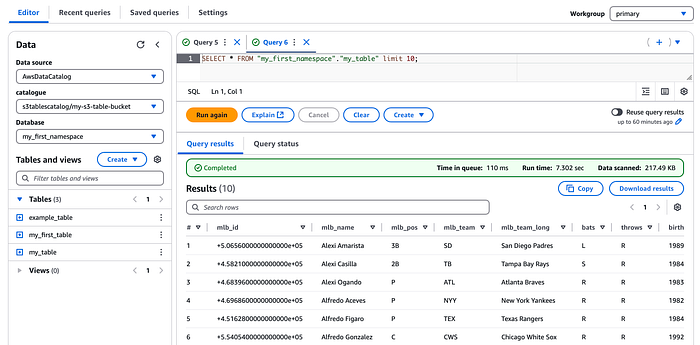
Ten en cuenta que, como las S3 tables las administra S3, no tienes acceso a la ubicación de los datos subyacentes en S3 ni puedes consultar los archivos manifest, a diferencia de lo que ocurre al consultar los metadatos de tablas Iceberg en tablas basadas en Amazon Athena.
Referencias:
Amazon S3 Tables te permite crear tablas lógicas sobre tus datos en S3 almacenados en formato parquet, con un rendimiento de lectura optimizado. Estas tablas se basan en el formato Iceberg, que no solo admite transacciones ACID, sino que también te permite hacer updates, deletes e inserts, además de consultas time-travel sobre tus datos. De todo esto se encarga Amazon S3 por ti, con el plus de la durabilidad, la escalabilidad y el rendimiento de S3.
Si quieres saber más o te interesan nuestros servicios, escríbenos sin dudarlo. Puedes contactarnos aquí.