Auf der AWS re:Invent 2024 wurde kürzlich die Einführung von Amazon S3 Tables angekündigt: vollständig verwaltete Apache-Iceberg-Tabellen, optimiert für Analytics-workloads. Diese Tabellen nutzen verwalteten Speicher im Iceberg-Format und lassen sich über die s3tables-API verwalten. Für Datenoperationen ist eine Integration mit Apache Spark oder AWS-Analytics-Services möglich – Amazon EMR, Amazon Athena, Amazon Redshift, Amazon EMR, Amazon QuickSight und Amazon Data Firehose.

Erstellt mit Amazon Bedrock
Erste Schritte
Zunächst legen Sie einen Table Bucket an – entweder über die Konsole oder die AWS CLI. Dabei können Sie die Integration des Table Buckets mit den oben genannten AWS-Analytics-Services aktivieren.
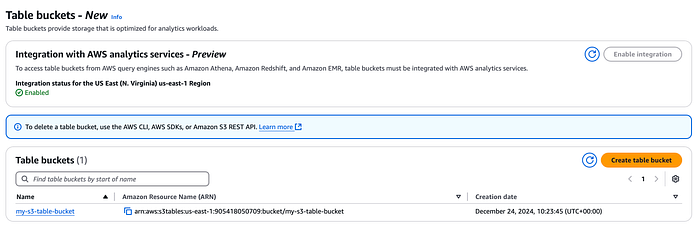
S3-Table-Bucket-Konsole
Sobald der Table Bucket erstellt ist, legen Sie darin einen Namespace an (vergleichbar mit einer logischen Datenbank, die mehrere Tabellen enthält), in dem dann Ihre Tabellen abgelegt werden.
aws s3tables create-namespace \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace
aws s3tables create-table \
--table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--namespace my_first_namespace \
--name my_first_table --format ICEBERG
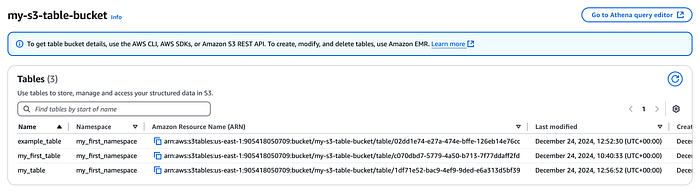
Im Table Bucket erstellte Tabellen in der Konsole
Das Tabellenformat basiert auf dem Apache-Iceberg-Framework; der zugrunde liegende Speicher enthält sowohl die Tabellendaten als auch die zugehörigen Metadaten. Mit S3 Tables müssen Sie sich nicht um die Tabellenpflege kümmern: Amazon S3 übernimmt die Wartung und sorgt damit für eine bessere Performance Ihrer S3 Tables und Table Buckets. Dazu zählen File Compaction, Snapshot-Management und das Entfernen nicht referenzierter Dateien. Diese Optionen sind standardmäßig aktiv. Über Wartungskonfigurationsdateien können Sie sie anpassen oder deaktivieren. Zusätzlich lassen sich die Parameter der Wartungs-Jobs auf für Sie passende Werte einstellen. Den Job-Status fragen Sie über die s3tables-API ab:
aws s3tables get-table-maintenance-job-status \
--table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \
--namespace="mynamespace" \
--name="testtable"
Bevor wir S3 Tables an die Analytics-Services anbinden, sind die Voraussetzungen zu erfüllen.
Legen Sie einen neuen Katalog für S3 Tables an:
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'
Dieser Katalog wird unter AWS Lake Formation registriert. In der Lake-Formation-Konsole sehen Sie anschließend auch den zuvor erstellten Namespace samt Tabelle (wählen Sie dazu im Dropdown den oben angelegten S3-Tabellenkatalog aus).
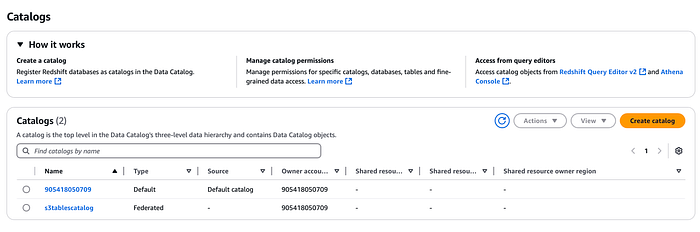
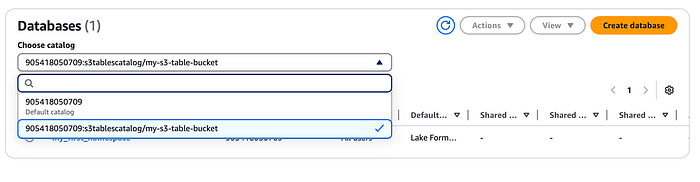
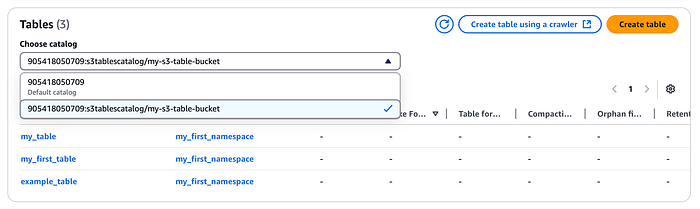
Integration mit Amazon EMR
Jetzt wird's spannend: Wir binden die S3 Tables an AWS-Services an. Den Anfang macht Amazon EMR – wir stellen einen Iceberg-fähigen EMR-Cluster mit Apache Spark bereit und melden uns anschließend per SSH am Primary Node des Clusters an.
Starten Sie die spark-shell:
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
Spark-shell auf dem EMR Primary Node
Stellen Sie sicher, dass Sie die genannten Voraussetzungen für die Integration korrekt umgesetzt haben. Für Amazon EMR weisen Sie der Rolle EMR_EC2_DefaultRole die Policy AmazonS3TablesFullAccess zu und vergeben zusätzlich passende Lake-Formation-Berechtigungen auf Katalog-, Namespace- und Tabellenebene.
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg """
)
spark.sql(
"""
INSERT INTO s3tablesbucket.my_first_namespace.example_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show()

Neuen Namespace für den Table Bucket anlegen
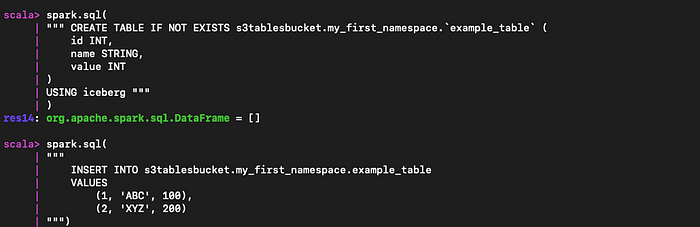
Neue Tabelle im Table Bucket innerhalb des Namespace anlegen

Tabelle abfragen
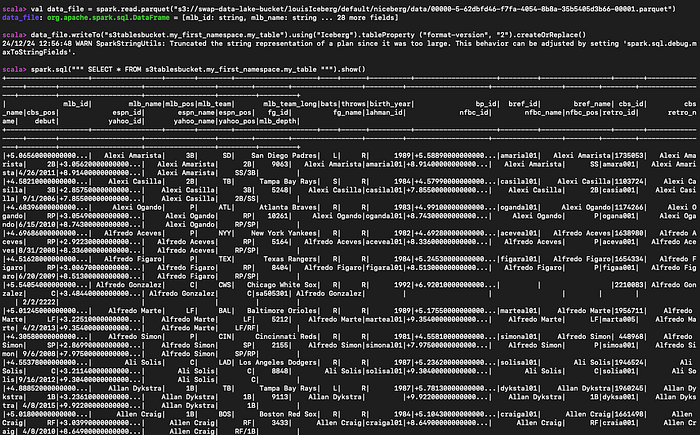
Wenn Sie Beispiel-Parquet-Daten in S3 vorliegen haben, können Sie diese einlesen, daraus eine S3-Tabelle erzeugen und sie abfragen:
#Parquet-Datei einlesen
val data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Neue Tabelle erstellen
data_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Erstellte Tabelle abfragen
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()
Integration mit Amazon Athena
Binden wir die Tabelle nun an Amazon Athena an. Da wir bereits einen Katalog für S3 Tables angelegt haben, taucht dieser in der Athena-Konsole unter "Data sources and catalogs" auf. Über das Dropdown im Editor lassen sich die S3 Tables auswählen.
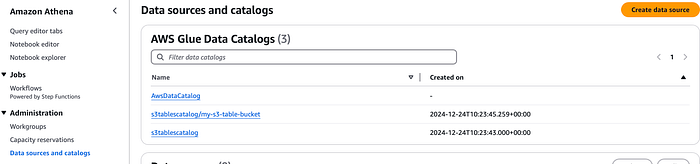
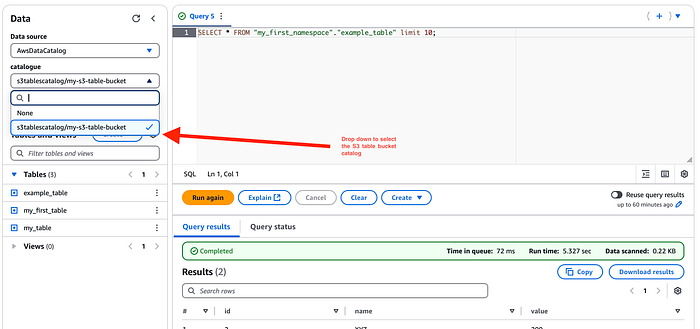
Anschließend lassen sich diese Tabellen in Athena genauso einfach abfragen wie native Glue-Katalogtabellen.
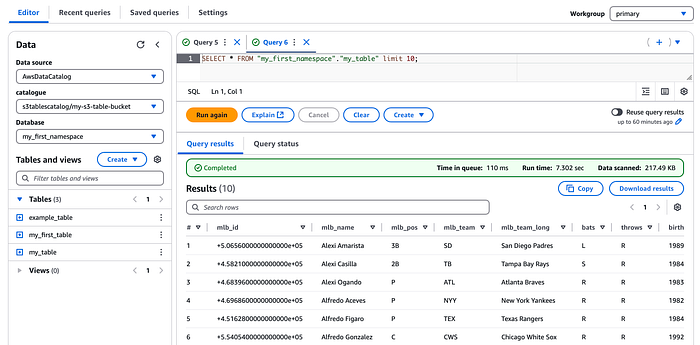
Wichtig: Da S3 Tables von S3 selbst verwaltet werden, haben Sie keinen Zugriff auf den darunterliegenden S3-Speicherort und können auch die Manifest-Dateien nicht abfragen – anders als beim Abfragen der Iceberg-Tabellenmetadaten bei Amazon-Athena-basierten Tabellen.
Mit Amazon S3 Tables legen Sie logische Tabellen über Ihren in S3 gespeicherten Daten an, die im Parquet-Format für eine optimierte Lese-Performance abgelegt sind. Die Tabellen basieren auf dem Iceberg-Format und unterstützen nicht nur ACID-Transaktionen, sondern auch Updates, Deletes, Inserts sowie Time-Travel-Abfragen Ihrer Daten. All das übernimmt Amazon S3 für Sie – mit den zusätzlichen Vorteilen von S3 in Sachen Beständigkeit, Skalierbarkeit und Performance.
Wenn Sie mehr erfahren möchten oder sich für unsere Services interessieren, sprechen Sie uns gerne an. Sie erreichen uns hier.