
Dans le cloud engineering, la vélocité est reine. Les équipes sont sous pression permanente pour livrer plus vite, faire évoluer les systèmes plus efficacement et délivrer de la valeur métier sans délai.
Au regard de ces priorités, il n'est guère surprenant que les tâches de maintenance cloud passent souvent au second plan. Même quand l'optimisation des coûts promet de vraies économies, le ROI final reste difficile à chiffrer en amont, et donc difficile à arbitrer face à d'autres chantiers critiques d'engineering.
Pourtant, sur la durée, négliger ces petites tâches finit par générer des inefficacités de coûts conséquentes, sans compter le risque opérationnel.
Le coût des optimisations cloud laissées de côté
Toute organisation héberge des inefficacités cloud sous ses propres yeux. Certaines sautent aux yeux : instances surprovisionnées, workloads zombies. D'autres sont plus discrètes, comme ces buckets remplis d'uploads multipart inachevés sur S3, qui font grimper la facture de stockage à petit feu.
La plupart des équipes cloud connaissent le problème. L'enjeu n'est pas la prise de conscience, mais la priorisation. Quand les Engineers sont évalués sur la vélocité produit, difficile de justifier des heures à éplucher des buckets S3 ou à traquer des règles de nettoyage manquantes.
Et pourtant, ces optimisations laissées de côté ont un impact financier mesurable. Ce sont typiquement des tâches juste assez agaçantes pour être ignorées, mais juste assez coûteuses pour finir par peser.
Pourquoi la maintenance passe à la trappe
Demandez à n'importe quel cloud engineer où passent ses journées : vous entendrez toujours le même refrain. Développer de nouvelles fonctionnalités, gérer les incidents, soutenir la productivité des développeurs, suivre les nouveaux services et les nouvelles API… la liste est sans fin.
Pendant ce temps, l'hygiène cloud — auditer les politiques IAM, activer la suppression automatique des volumes orphelins, définir des règles de cycle de vie pour les uploads S3 incomplets — atterrit dans la catégorie : " On verra plus tard ".
Le problème, c'est que " plus tard " n'arrive presque jamais.
Cas d'école : le nettoyage des uploads multipart S3
Prenons le cas précis des uploads multipart Amazon S3. Lorsqu'un upload est lancé sans jamais être finalisé (ce qui arrive plus souvent qu'on ne le croit), AWS continue de stocker les parties téléversées et vous facture ce stockage, même si l'objet n'a jamais été assemblé.
La solution est simple : configurer une règle de cycle de vie pour interrompre les uploads multipart incomplets après un nombre de jours défini (généralement 7). Mais en pratique, beaucoup de buckets S3 en sont dépourvus.
Pourquoi ? Parce que pour le faire dans la console AWS, voici ce que cela implique :
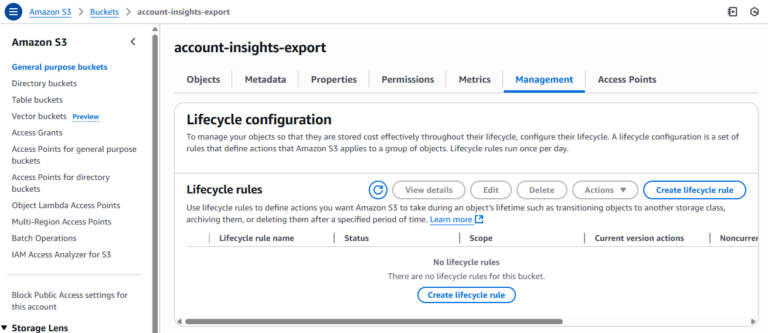
Processus manuel pour gérer le nettoyage des uploads multipart S3 via la console AWS
1. Se connecter à la console AWS
- Accéder à la console de gestion AWS
- Aller sur le dashboard du service S3
2. Examiner les règles de cycle de vie de chaque bucket
C'est là que tout se complique : la console AWS ne propose aucun moyen natif de filtrer ou de rechercher, à travers les buckets, les configurations de cycle de vie ou les règles manquantes. L'utilisateur doit donc :
- Ouvrir manuellement chaque bucket
- Aller dans Management → Lifecycle rules.
- Si des règles existent, les inspecter pour vérifier si l'une d'elles gère les " Incomplete multipart uploads "
- Si une telle règle existe (généralement nommée " Abort incomplete multipart uploads after X days "), aucune action supplémentaire n'est nécessaire
- Si aucune règle n'existe, en ajouter une
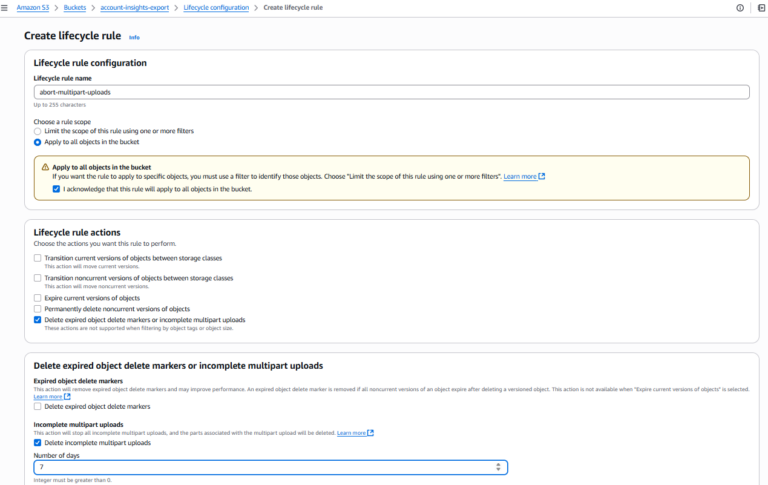
3. Ajouter une règle de nettoyage multipart
Pour chaque bucket dépourvu de la règle :
- Cliquer sur " Create lifecycle rule "
- Saisir un nom de règle (par ex. abort-multipart-uploads)
- Choisir la portée de la règle (par ex. l'appliquer à tous les objets du bucket)
- Dans Lifecycle rule actions, cocher " Delete expired object delete markers or incomplete multipart upload "
- Dans Incomplete multipart uploads, cocher " Delete incomplete multipart uploads "
- Définir le nombre de jours après l'initiation (AWS recommande 7 jours ou moins)
- Vérifier et enregistrer la règle
- Répéter l'opération pour chaque bucket concerné
Vous le voyez : sur des dizaines, des centaines, voire des milliers de buckets, ce processus répétitif, lent et propice aux erreurs ne se fait tout simplement jamais.
Résoudre le problème par l'automatisation des workflows
Ce type de tâches est un candidat idéal à l'automatisation — non pas parce qu'elles sont techniquement complexes, mais parce qu'elles sont opérationnellement rébarbatives. Or ce sont précisément ces tâches qui plombent la productivité quand on les exécute à la main, et qui rongent l'efficacité quand on les ignore.
Avec CloudFlow, la solution no-code d'automatisation de workflows intégrée à DoiT Cloud Intelligence™, un cloud engineer peut simplement configurer le workflow voulu et laisser le système faire le travail en quelques secondes.
Pour notre cas, le CloudFlow correspondant pourrait ressembler à ceci, chaque étape du flux remplaçant une ou plusieurs manipulations qu'il faudrait sinon réaliser dans la console AWS :
- Définir un déclencheur planifié selon l'horaire et la fréquence d'exécution voulus
- Via la fonctionnalité API de CloudFlow, récupérer d'abord la liste complète des buckets S3 de votre ou vos comptes AWS (" ListBuckets ")
- À partir de cette liste, récupérer les règles de configuration de cycle de vie (" GetBucketLifecycleConfiguration ")
- Créer un nœud de filtrage pour identifier tous les buckets dépourvus de la règle requise (" Filter for missing policy ")
- Utiliser une autre API AWS pour appliquer la nouvelle règle à tous les buckets filtrés (" PutBucketLifecycleCongifuration ")
- Créer une étape de notification pour documenter le changement et tenir toutes les parties prenantes informées
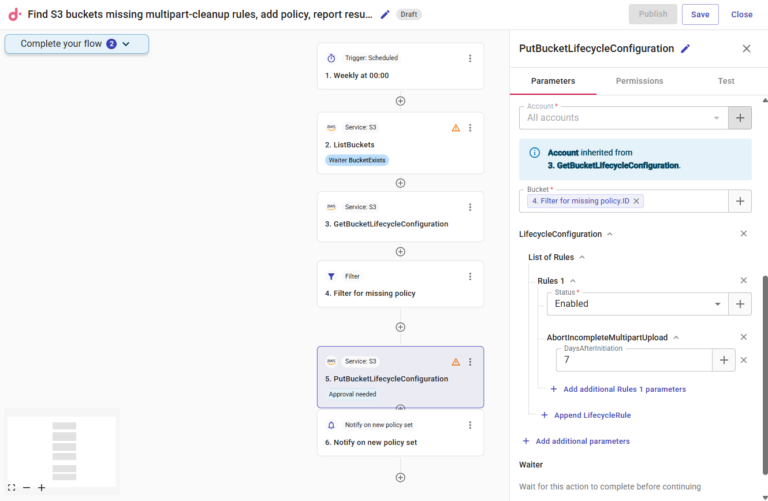
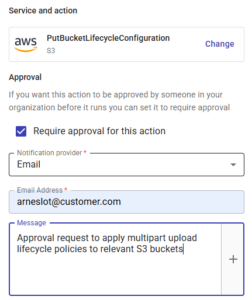
Pour rester en conformité, vous pouvez aussi ajouter une approbation à n'importe quelle étape du processus, afin qu'aucun bucket ne soit modifié sans l'aval d'un administrateur du compte :
Ce CloudFlow ne se contente pas de remplacer le travail laborieux et chronophage de nettoyage de TOUS les buckets S3 des comptes ciblés : il peut aussi tourner chaque semaine pour s'assurer que tout nouveau bucket créé sans règle de cycle de vie soit détecté et corrigé pour intégrer cette règle.
Ce changement ne fait pas que gagner du temps : il transforme la façon de travailler des équipes. Plutôt que de consacrer des heures au nettoyage initial puis de refaire indéfiniment la même maintenance, CloudFlow met le processus en pilote automatique et libère les cloud engineers pour des sujets à plus fort impact sur les objectifs à long terme de l'entreprise — tout en leur épargnant des tâches d'un ennui mortel.
Et la gestion du cycle de vie S3 n'est qu'un cas d'usage parmi d'autres pour CloudFlow : il permet également d'appliquer automatiquement des tags ou des labels aux ressources, d'allumer ou d'éteindre des instances, de right-sizer des workloads, ou de faire à peu près tout ce qui est réalisable via les API AWS ou Google Cloud.
Pour découvrir comment CloudFlow peut transformer le quotidien de votre équipe, faites cette visite guidée, ou contactez un expert DoiT.