
No mundo da engenharia em nuvem, velocidade é tudo. Os times vivem sob pressão constante para entregar funcionalidades mais rápido, escalar sistemas com mais eficiência e gerar valor para o negócio sem atrasos.
Diante desses objetivos, talvez não seja surpresa que tarefas rotineiras de manutenção da nuvem acabem ficando em segundo plano. Mesmo com a economia que a manutenção voltada à otimização de custos pode trazer, o ROI final é difícil de calcular de antemão e, por isso, difícil de priorizar diante de outras tarefas críticas de engenharia.
Só que, no longo prazo, deixar essas pequenas tarefas de lado pode se transformar silenciosamente em ineficiências de custo relevantes — e em risco operacional.
O custo das otimizações de nuvem que ficam pelo caminho
Toda organização tem ineficiências de nuvem escondidas à vista de todos. Algumas são óbvias, como instâncias superdimensionadas ou workloads zumbis. Outras são mais sutis, como buckets com uploads multipart incompletos no S3 acumulando lentamente cobranças de armazenamento.
A maioria dos times de nuvem sabe que esses problemas existem. A questão não é falta de consciência — é prioridade. Quando os Engineers são avaliados pela velocidade de entrega de produto, fica difícil justificar gastar tempo vasculhando buckets do S3 ou checando se faltam regras de limpeza.
Ainda assim, essas otimizações que ficam pelo caminho costumam ter um impacto financeiro mensurável. São aquele tipo de tarefa chata o suficiente para ser ignorada, mas cara o bastante para fazer diferença com o tempo.
Por que tarefas de manutenção ficam para trás
Pergunte a qualquer engenheiro de nuvem para onde vai o tempo dele e você vai ouvir variações do mesmo tema: criar novas funcionalidades, responder a incidentes, dar suporte à produtividade dos desenvolvedores, acompanhar novos serviços e APIs — a lista parece não ter fim.
Enquanto isso, a higiene da nuvem — auditar políticas de IAM, configurar exclusão automática em volumes não anexados ou definir regras de ciclo de vida para uploads incompletos no S3 — vai parar numa categoria que dá pra resumir assim: "a gente vê isso depois".
O problema é que esse "depois" quase nunca chega.
Um exemplo prático: limpeza de uploads multipart no S3
Pegue o caso específico dos uploads multipart no Amazon S3. Quando um upload é iniciado, mas nunca concluído (e isso acontece mais do que você imagina), a AWS continua armazenando as partes enviadas — e cobrando você pelo armazenamento, mesmo que o objeto em si nunca tenha sido finalizado.
A solução é simples: configurar uma regra de ciclo de vida para abortar uploads multipart incompletos após um número definido de dias (normalmente 7). Mas, na prática, muitos buckets do S3 não têm essa regra.
Por quê? Porque, para fazer isso pelo console da AWS, o caminho é o seguinte:
Processo manual para gerenciar a limpeza de uploads multipart no S3 pelo console da AWS
1. Acesse o console da AWS
- Vá até o AWS Management Console
- Acesse o dashboard do serviço S3
2. Revise as regras de ciclo de vida de cada bucket
É aqui que tudo fica ineficiente: não existe uma forma nativa no console da AWS de filtrar ou pesquisar entre buckets por configurações de ciclo de vida ou por regras ausentes. Em vez disso, o usuário precisa:
- Abrir manualmente cada bucket
- Ir em Management → Lifecycle rules.
- Se houver regras, conferi-las para confirmar se alguma trata de "Incomplete multipart uploads"
- Se essa regra existir (normalmente nomeada como "Abort incomplete multipart uploads after X days"), nenhuma ação adicional é necessária
- Se não existir, é preciso adicioná-la
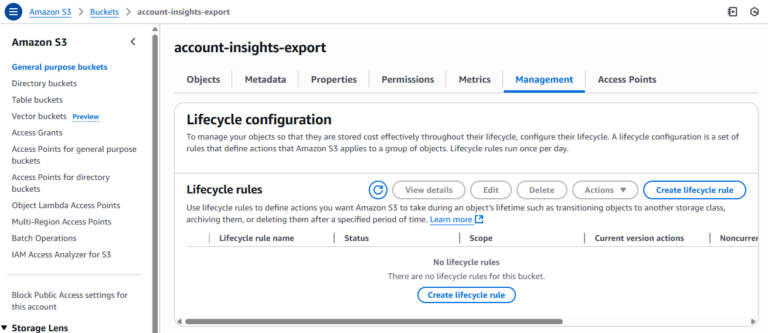
3. Adicione a regra de limpeza de multipart
Para cada bucket que não tem a regra:
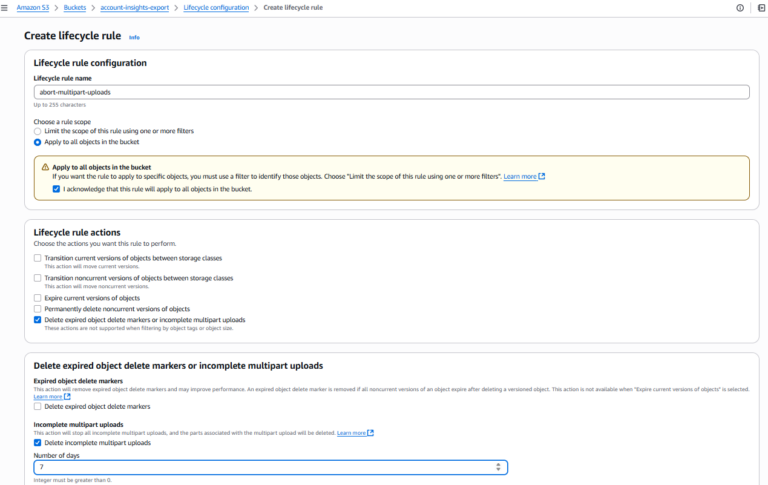
- Clique em "Create lifecycle rule"
- Informe um nome para a regra (ex.: abort-multipart-uploads)
- Defina o escopo da regra (ex.: aplicar a todos os objetos do bucket)
- Em Lifecycle rule actions, marque "Delete expired object delete markers or incomplete multipart upload"
- Em Incomplete multipart uploads, marque " Delete incomplete multipart uploads"
- Defina o número de dias após o início (a AWS recomenda 7 ou menos)
- Revise e salve a regra
- Repita o processo em cada bucket que precisar da regra
Como dá para perceber, encontrar e corrigir o problema em dezenas, centenas ou até milhares de buckets significa que todo esse processo repetitivo, lento e sujeito a erros simplesmente não é feito.
Resolvendo o problema com automação de workflow
Esse tipo de tarefa é o candidato ideal à automação — não porque seja tecnicamente complexa, mas porque é operacionalmente entediante. E tarefas entediantes são justamente as que minam a produtividade quando feitas na mão e corroem a eficiência em silêncio quando são ignoradas.
Mas, com o CloudFlow, a solução de automação de workflow no-code dentro do DoiT Cloud Intelligence™, um engenheiro de nuvem pode simplesmente configurar o workflow que precisa rodar e deixar que o sistema faça o trabalho em segundos.
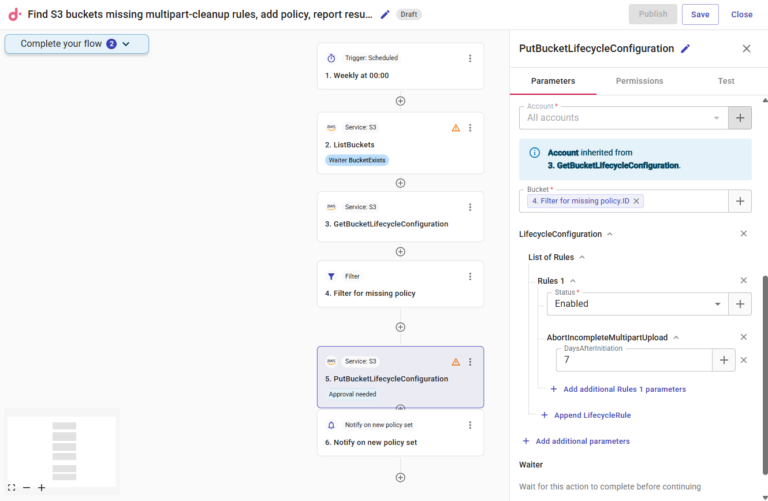
Neste caso, um CloudFlow correspondente poderia ficar assim, com cada etapa do fluxo substituindo uma ou mais ações manuais que, de outra forma, você teria que executar no console da AWS:
- Configure um gatilho agendado com o horário e a frequência em que você quer que o CloudFlow seja executado
- Usando a funcionalidade de API do CloudFlow, primeiro obtenha a lista completa de buckets do S3 nas suas contas AWS ("ListBuckets")
- A partir dos buckets listados, busque as regras de configuração de ciclo de vida ("GetBucketLifecycleConfiguration")
- Crie um nó de filtro para encontrar todos os buckets que estão sem a regra exigida ("Filter for missing policy")
- Use outra API da AWS para aplicar a nova regra a todos os buckets filtrados ("PutBucketLifecycleCongifuration")
- Crie uma etapa de notificação para registrar a alteração e manter todos os stakeholders informados
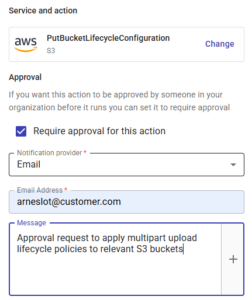
Para manter a conformidade, você também pode incluir uma aprovação em qualquer etapa do processo, garantindo que nenhum bucket seja modificado sem a permissão do administrador da conta:
Esse CloudFlow não só substitui o processo tedioso e demorado de limpar TODOS os buckets do S3 nas contas indicadas, como também pode rodar semanalmente para garantir que qualquer bucket novo, criado sem a regra de ciclo de vida, seja identificado e ajustado corretamente para incluí-la.
Esse tipo de mudança não economiza só tempo: muda a forma como os times trabalham. Em vez de dedicar horas à limpeza inicial e depois refazer a mesma manutenção repetidamente, o CloudFlow coloca o processo no piloto automático e libera os engenheiros de nuvem para focar em trabalhos com maior impacto nos objetivos de longo prazo da empresa — livrando-os, de quebra, de tarefas extremamente monótonas.
E o gerenciamento de ciclo de vida no S3 é só um dos casos de uso possíveis do CloudFlow; ele também pode ser usado para aplicar tags ou labels em recursos de forma autônoma, ligar e desligar instâncias, fazer right-sizing de workloads ou praticamente qualquer outra ação que possa ser executada via APIs da AWS ou do Google Cloud.
Para saber mais sobre como o CloudFlow pode impactar a forma como o seu time trabalha, confira este tour guiado ou fale com um especialista da DoiT.