
Nel mondo del cloud engineering la velocità è tutto. I team sono sotto costante pressione: rilasciare funzionalità più rapidamente, scalare i sistemi in modo più efficiente e generare valore di business senza ritardi.
Alla luce di queste priorità, non stupisce che le attività di manutenzione ordinaria del cloud finiscano spesso in fondo alla lista. Per quanto l'ottimizzazione dei costi possa generare risparmi, il ROI è difficile da quantificare a priori e di conseguenza diventa complicato darle precedenza rispetto ad altre attività di engineering critiche.
Eppure, sul lungo periodo, trascurare queste piccole attività può tradursi silenziosamente in inefficienze di costo significative e in un aumento del rischio operativo.
Il costo delle ottimizzazioni cloud mancate
In ogni organizzazione si annidano inefficienze cloud sotto gli occhi di tutti. Alcune sono evidenti, come istanze sovradimensionate o workloads zombie. Altre sono più sottili, come bucket pieni di multipart upload incompleti su S3 che accumulano lentamente costi di storage.
La maggior parte dei team cloud sa che questi problemi esistono. Il punto non è la consapevolezza, ma la priorità. Quando gli engineer vengono valutati sulla velocità di rilascio del prodotto, è difficile giustificare il tempo dedicato a passare al setaccio i bucket S3 o a controllare l'assenza di regole di pulizia.
Eppure queste ottimizzazioni mancate hanno spesso un impatto economico misurabile. Sono attività abbastanza fastidiose da essere ignorate, ma abbastanza onerose da pesare nel tempo.
Perché le attività di manutenzione vengono trascurate
Chieda a un qualsiasi cloud engineer come impiega il proprio tempo: sentirà variazioni sullo stesso tema. Sviluppare nuove funzionalità, gestire incidenti, supportare la produttività degli sviluppatori, stare al passo con nuovi servizi e API: le attività sembrano non finire mai.
Nel frattempo, la cloud hygiene — l'audit delle policy IAM, la configurazione dell'auto-delete sui volumi non collegati o l'impostazione di regole di lifecycle per gli upload S3 incompleti — finisce in una categoria che si potrebbe riassumere così: "Ce ne occuperemo più avanti".
Il problema è che "più avanti" raramente arriva.
Un caso emblematico: la pulizia dei multipart upload S3
Prendiamo il caso specifico dei multipart upload di Amazon S3. Quando un upload viene avviato ma non viene mai completato (cosa che accade più spesso di quanto si pensi), AWS continua a conservare le parti già caricate, addebitando lo storage anche se l'oggetto non è mai stato finalizzato.
La soluzione è semplice: configurare una regola di lifecycle per interrompere i multipart upload incompleti dopo un determinato numero di giorni (in genere 7). Nella pratica, però, molti bucket S3 ne sono sprovvisti.
Perché? Perché farlo dalla console AWS comporta i seguenti passaggi:
Procedura manuale per gestire la pulizia dei multipart upload S3 dalla console AWS
1. Accedere alla console AWS
- Aprire la AWS Management Console
- Andare al dashboard del servizio S3
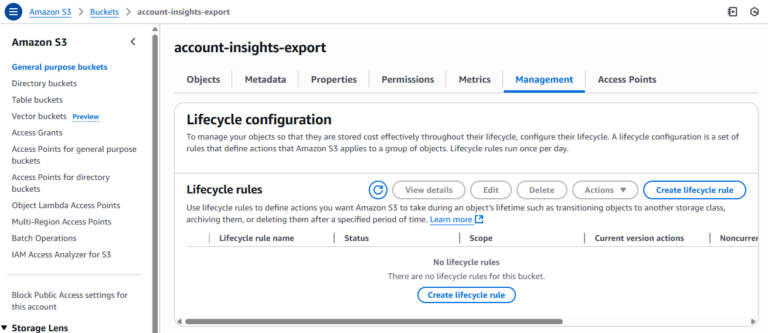
2. Verificare le regole di lifecycle per ciascun bucket
Ed è qui che il processo diventa inefficiente: nella console AWS non esiste un modo nativo per filtrare o cercare le configurazioni di lifecycle o le regole mancanti tra i bucket. L'utente è quindi costretto a:
- Aprire manualmente ogni singolo bucket
- Andare su Management → Lifecycle rules.
- Se sono presenti regole, esaminarle per verificare se ne esiste una che gestisca gli "Incomplete multipart uploads"
- Se la regola esiste (di solito denominata "Abort incomplete multipart uploads after X days"), non occorre fare altro
- Se la regola non esiste, procedere ad aggiungerla
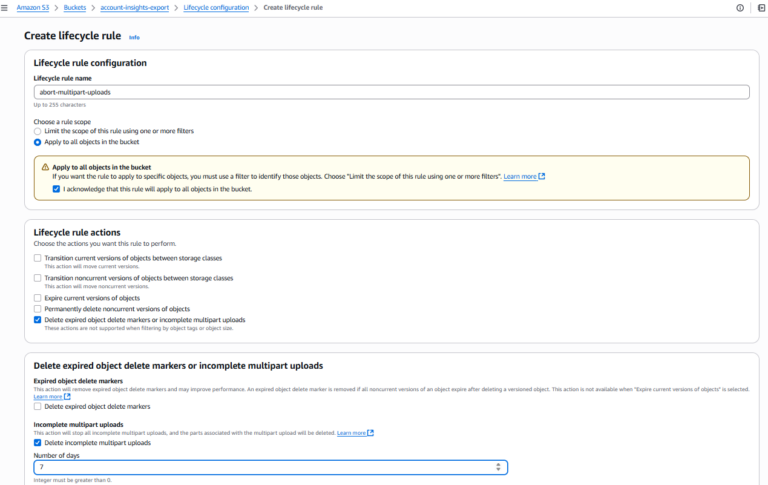
3. Aggiungere la regola di pulizia dei multipart upload
Per ciascun bucket privo della regola:
- Cliccare su "Create lifecycle rule"
- Inserire un nome per la regola (ad esempio, abort-multipart-uploads)
- Definire l'ambito della regola (ad esempio, applicarla a tutti gli oggetti del bucket)
- In Lifecycle rule actions, selezionare "Delete expired object delete markers or incomplete multipart upload"
- In Incomplete multipart uploads, selezionare " Delete incomplete multipart uploads"
- Impostare il numero di giorni dall'avvio (AWS consiglia 7 o meno)
- Rivedere e salvare la regola
- Ripetere l'operazione per ogni bucket che necessita della regola
Come può ben immaginare, individuare e risolvere il problema su decine, centinaia o persino migliaia di bucket significa che l'intero processo — ripetitivo, lento e soggetto a errori — semplicemente non viene mai portato a termine.
Risolvere il problema con l'automazione dei workflow
Attività di questo tipo sono candidate ideali all'automazione: non perché siano tecnicamente complesse, ma perché sono operativamente noiose. E le attività noiose sono proprio quelle che, svolte manualmente, prosciugano la produttività e, se ignorate, erodono silenziosamente l'efficienza.
Con CloudFlow, la soluzione no-code di automazione dei workflow integrata in DoiT Cloud Intelligence™, un cloud engineer può semplicemente configurare il workflow desiderato e lasciare che il sistema esegua il lavoro in pochi secondi.
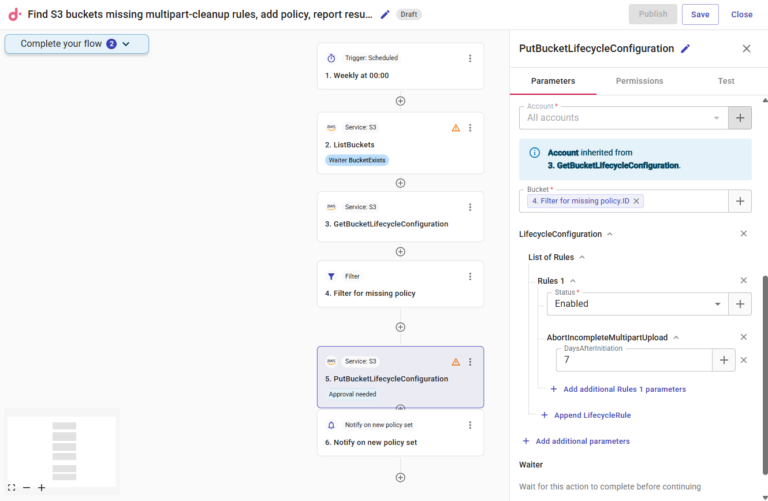
In questo caso specifico, un CloudFlow potrebbe strutturarsi così, con ogni passaggio del flusso che sostituisce uno o più step manuali altrimenti da eseguire nella console AWS:
- Impostare un trigger pianificato definendo orario e cadenza di esecuzione del CloudFlow
- Sfruttando le API di CloudFlow, ottenere innanzitutto l'elenco completo dei bucket S3 presenti negli account AWS ("ListBuckets")
- Dai bucket elencati, recuperare le rispettive regole di configurazione del lifecycle ("GetBucketLifecycleConfiguration")
- Creare un nodo di filtro per individuare tutti i bucket privi della regola richiesta ("Filter for missing policy")
- Utilizzare un'altra API AWS per applicare la nuova regola a tutti i bucket filtrati ("PutBucketLifecycleCongifuration")
- Creare uno step di notifica per documentare la modifica e tenere informati tutti gli stakeholder
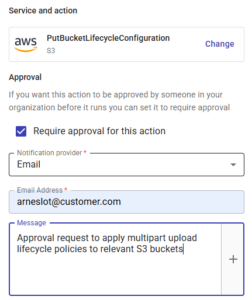
Per mantenere la compliance, può inoltre applicare un'approvazione a qualunque step del processo, in modo da assicurarsi che nessun bucket venga modificato senza il via libera dell'admin dell'account:
Questo CloudFlow non solo sostituisce il processo tedioso e dispendioso di pulizia di TUTTI i bucket S3 negli account specificati, ma può essere eseguito anche con cadenza settimanale per intercettare eventuali nuovi bucket creati senza la regola di lifecycle e applicarla automaticamente.
Un cambiamento di questa portata non si limita a far risparmiare tempo: trasforma il modo di lavorare dei team. Invece di dedicare ore alla pulizia iniziale e poi ripetere periodicamente le stesse operazioni, CloudFlow mette il processo in pilota automatico e permette ai cloud engineer di concentrarsi su attività a maggior impatto sugli obiettivi di lungo periodo dell'azienda, liberandoli al tempo stesso da compiti di noia mortale.
E la gestione del lifecycle di S3 è solo uno dei possibili casi d'uso di CloudFlow: può essere impiegato anche per applicare in autonomia tag o label alle risorse, avviare e spegnere istanze, fare right-sizing dei workloads o, in generale, per qualsiasi operazione realizzabile tramite le API di AWS o Google Cloud.
Per scoprire come CloudFlow può cambiare il modo di lavorare del Suo team, provi il tour guidato oppure contatti un esperto DoiT.