
En el mundo del cloud engineering, la velocidad lo es todo. Los equipos viven bajo una presión constante para lanzar funcionalidades más rápido, escalar sistemas con mayor eficiencia y entregar valor al negocio sin demoras.
Con esos objetivos de fondo, no debería sorprender que las tareas rutinarias de mantenimiento en la nube terminen quedando relegadas. Aun considerando los ahorros que aporta la optimización de costos, el ROI final es difícil de calcular de antemano y, por lo mismo, complicado de priorizar frente a otras tareas críticas de Engineering.
Sin embargo, a la larga, descuidar estas pequeñas tareas se traduce, sin que lo notes, en ineficiencias de costo importantes y en riesgo operativo.
El costo de las optimizaciones de nube que se quedan en el tintero
Toda organización tiene ineficiencias en la nube a la vista de todos. Algunas son evidentes, como instancias sobreaprovisionadas o workloads zombis. Otras son más sutiles, como buckets con cargas multipart incompletas en S3 que van acumulando cargos de almacenamiento poco a poco.
La mayoría de los equipos cloud sabe que estos problemas existen. La cuestión no es la conciencia, sino la prioridad. Cuando a los Engineers se les mide por la velocidad de producto, cuesta justificar dedicar tiempo a revisar buckets de S3 o a verificar reglas de limpieza faltantes.
Y aun así, estas optimizaciones desaprovechadas suelen tener un impacto financiero medible. Son el tipo de tareas lo bastante molestas como para ignorarlas, pero lo bastante costosas como para que importen con el tiempo.
Por qué las tareas de mantenimiento se pasan por alto
Pregúntale a cualquier cloud engineer en qué se le va el tiempo y vas a escuchar variaciones del mismo tema: desarrollar nuevas funcionalidades, responder a incidentes, dar soporte a la productividad de los desarrolladores, mantenerse al día con nuevos servicios y APIs… las tareas parecen no tener fin.
Mientras tanto, la higiene de la nube —auditar políticas de IAM, configurar el borrado automático de volúmenes desconectados o establecer reglas de ciclo de vida para cargas incompletas en S3— termina cayendo en una categoría que se describe mejor así: "Lo vemos después".
El problema es que ese "después" rara vez llega.
Un caso concreto: limpieza de cargas multipart en S3
Tomemos el caso específico de las cargas multipart en Amazon S3. Cuando se inicia una carga pero nunca se completa (algo que ocurre más de lo que imaginas), AWS sigue almacenando las partes ya subidas y te cobra ese almacenamiento, aunque el objeto en sí nunca se haya finalizado.
La solución es simple: configurar una regla de ciclo de vida para abortar las cargas multipart incompletas tras cierto número de días (normalmente 7). Pero, en la práctica, a muchos buckets de S3 les falta esta regla.
¿Por qué? Porque hacerlo desde la consola de AWS implica lo siguiente:
Proceso manual para gestionar la limpieza de cargas multipart en S3 desde la consola de AWS
1. Inicia sesión en la consola de AWS
- Ve a la consola de administración de AWS
- Entra al dashboard del servicio S3
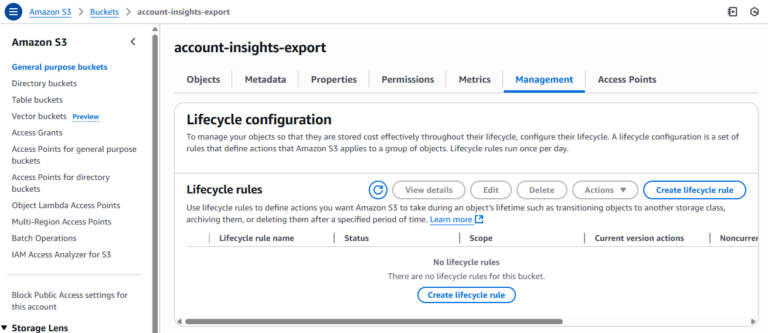
2. Revisa las reglas de ciclo de vida de cada bucket
Acá es donde la cosa se complica, porque la consola de AWS no ofrece ninguna forma nativa de filtrar o buscar entre buckets las configuraciones de ciclo de vida ni las reglas faltantes. En su lugar, el usuario debe:
- Abrir manualmente cada bucket
- Ir a Management → Lifecycle rules.
- Si hay reglas, revisarlas para confirmar si alguna gestiona "Incomplete multipart uploads"
- Si esa regla existe (normalmente llamada "Abort incomplete multipart uploads after X days"), no hace falta hacer nada más
- Si no existe, hay que agregarla
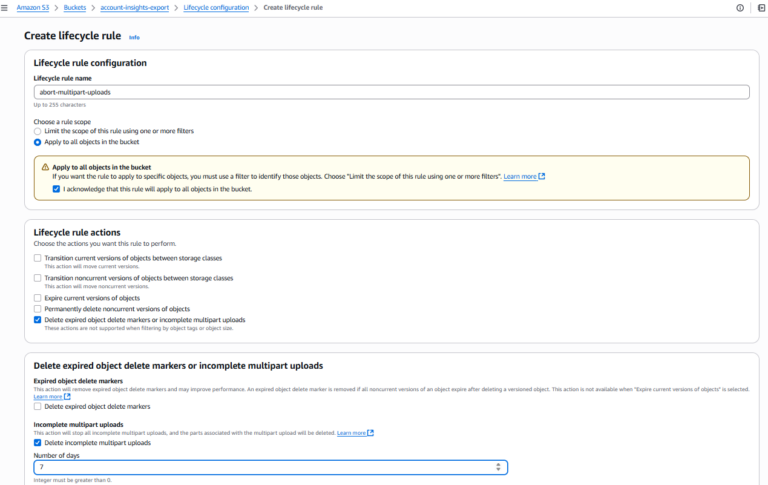
3. Agregar la regla de limpieza multipart
Para cada bucket al que le falte la regla:
- Haz clic en "Create lifecycle rule"
- Ingresa un nombre para la regla (por ejemplo, abort-multipart-uploads)
- Define el alcance de la regla (por ejemplo, aplicar a todos los objetos del bucket)
- En Lifecycle rule actions, marca "Delete expired object delete markers or incomplete multipart upload"
- En Incomplete multipart uploads, marca "Delete incomplete multipart uploads"
- Indica el número de días tras el inicio de la carga (AWS recomienda 7 o menos)
- Revisa y guarda la regla
- Repite el proceso en cada bucket que la necesite
Como ves, detectar y corregir el problema en decenas, cientos o incluso miles de buckets implica que todo este proceso repetitivo, lento y propenso a errores simplemente nunca se hace.
Resolver el problema con automatización de workflows
Este tipo de tareas son candidatas ideales para automatizar, no porque sean técnicamente complejas, sino porque resultan operativamente aburridas. Y son justamente las tareas aburridas las que drenan la productividad cuando se hacen a mano y las que erosionan la eficiencia, sin hacer ruido, cuando se ignoran.
Pero con CloudFlow, la solución no-code de automatización de workflows dentro de DoiT Cloud Intelligence™, un cloud engineer puede configurar el workflow que necesita y dejar que el sistema haga el trabajo en segundos.
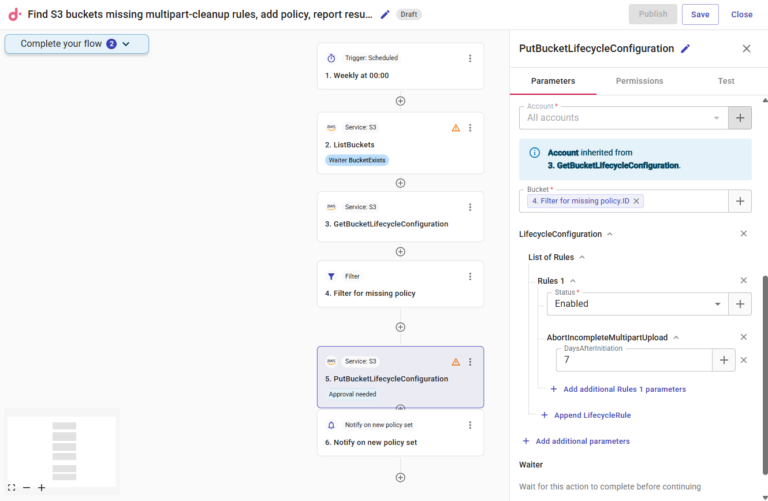
En este caso, el CloudFlow correspondiente podría verse así, donde cada paso del flujo reemplaza uno o más pasos manuales que tendrías que hacer en la consola de AWS:
- Configura un trigger programado con la hora y la frecuencia con que quieres que se ejecute el CloudFlow
- Con la funcionalidad de API de CloudFlow, primero obtén la lista completa de buckets de S3 en tu(s) cuenta(s) de AWS ("ListBuckets")
- A partir de los buckets listados, recupera sus reglas de configuración de ciclo de vida ("GetBucketLifecycleConfiguration")
- Crea un nodo de filtro para identificar todos los buckets a los que les falta la regla requerida ("Filter for missing policy")
- Usa otra API de AWS para aplicar la nueva regla a todos los buckets filtrados ("PutBucketLifecycleCongifuration")
- Crea un paso de notificación para documentar el cambio y mantener informados a todos los stakeholders
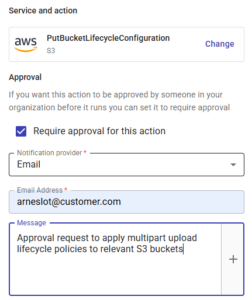
Para mantener el cumplimiento, también puedes añadir una aprobación a cualquier paso del proceso, de modo que ningún bucket se modifique sin el permiso del administrador de la cuenta:
Este CloudFlow no solo reemplaza el tedioso y largo proceso de limpiar TODOS los buckets de S3 dentro de las cuentas especificadas: además se puede ejecutar semanalmente para garantizar que cualquier bucket nuevo creado sin la regla de ciclo de vida sea detectado y modificado correctamente para incluirla.
Este tipo de cambio no solo ahorra tiempo: transforma la forma en que trabajan los equipos. En lugar de dedicar horas a la limpieza inicial y después repetir el mismo mantenimiento una y otra vez, CloudFlow pone el proceso en piloto automático y permite que los cloud engineers se enfoquen en trabajo que tiene mayor impacto en los objetivos a largo plazo de la empresa, además de liberarlos de tareas terriblemente monótonas.
Y la gestión del ciclo de vida en S3 es solo uno de los posibles casos de uso de CloudFlow; también sirve para aplicar tags o labels a los recursos de forma autónoma, encender y apagar instancias, hacer right-sizing de workloads o, en realidad, cualquier otra cosa que pueda lograrse con las APIs de AWS o Google Cloud.
Para conocer más sobre cómo CloudFlow puede transformar la forma en que trabaja tu equipo, mira este tour guiado o contacta a un experto de DoiT.