




Both XGBoost and TensorFlow are very capable machine learning frameworks but how do you know which one you need? Or perhaps you need both?
In machine learning there are “no free lunches”. Matching specific algorithms to specific problems often outperforms the “one-fits-all” approach. However, over the years the data science community has gained enough experience to generate thumb rules for matching between certain algorithms and typical tasks.
In this short post I will try to cover some of these rules to help you decide between Gradient Boosting Machines using XGBoost and Neural Networks using TensorFlow.
In 2012 Alex Krizhevsky and his colleagues astonished the world with a computational model that could not only learn to tell which object is present in a given image based on features, but also perform the feature extraction itself — a task that was thought to be complex even for experienced “human” engineers.
Since then, deep neural networks have dominated the research landscape with more articles suggesting revolutionary concepts for image recognition, translation, playing computer games and even self driving cars. Nevertheless, in the very popular data-science hub Kaggle, the benchmarks for many competitions are based on some implementation of Gradient Boosting Machines.
While Cloud Machine Learning Engine offers both frameworks now, it’s not always clear which algorithm should be explored first. After solving many machine learning problems which use both methods, I put together some of my thoughts on how to choose between the different approaches
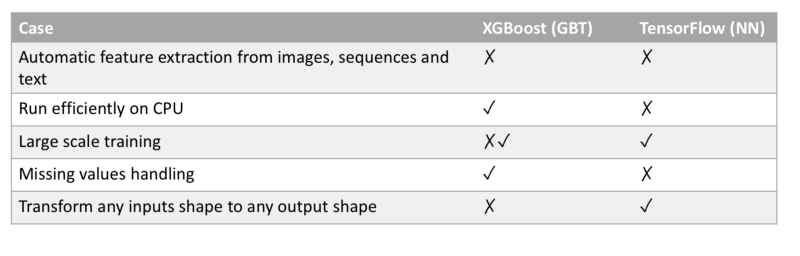
Case 1: Difficult to Breakdown to Features?
If we have learned anything from 2012 is that neural networks are very efficient for dealing with high dimensional raw data. Image, video, text and audio are all examples of high dimensional raw data that is very hard to preprocess and represent as features. In these cases, using NN’s built-in feature extraction units (CNNs, LSTMs, Embedding layers) can obtain phenomenal results in a fraction of the development time of the classic engineering approaches.

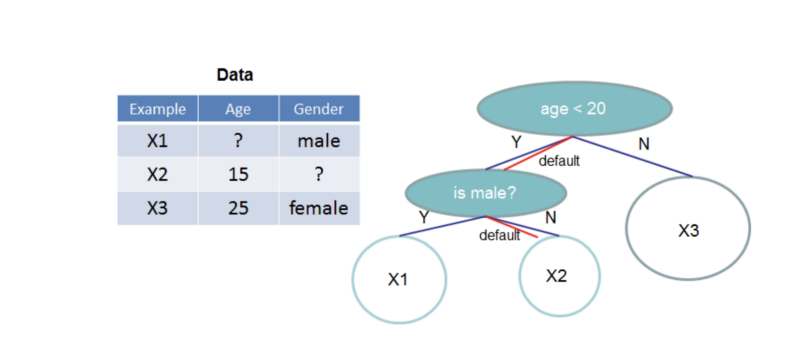
Case 2: Handling Missing Values?
If you ever tried to feed a neural network with a missing data you probably ended with errors. This is because the equations which are being solved during NN training assume a valid value for each input variable.
XGBoost on the other hand, has its own way of dealing with missing data. During training XGBoost performs a sub-task of learning to impute data for each feature. Many real world problems have missing data that for itself contains valuable information about the target. So for “free” missing values handling — XGBoost wins.
Case 3: How Deep Are Your Pockets?
Neural networks training is “embarrassingly parallel”, making them great for parallel and distributed training. That is, if your budget can cover running hours of training on expensive machines with TPUs or GPUs.
On the other hand, if you only use up to several million of records XGBoost can be trained on a less expensive multi-core CPU and converge in less time. So if you have a limited amount of data and want to train a model — XGBoost may be more affordable and achieve similar results.
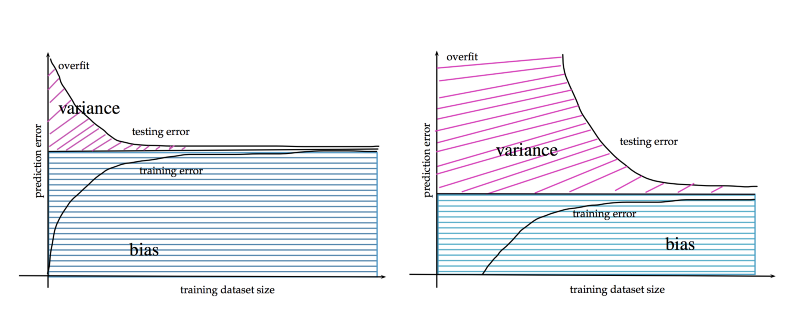
Case 4: How Much Data Do You Have?
The previous case brings us to the question of how much data do you have. Due to its underlying data structure, XGBoost is limited in the ways it can be parallelized making it short in the amount of data it can process. One way of handling massive datasets is splitting the data to shards and stacking models — thus effectively multiplying the number of parameters used to fit the data.
However with neural networks it is usually “the more the merrier”. When dealing with massive datasets neural networks can converge with the same number of parameters to lower generalization error. But for smaller datasets XBGoost typically converges faster and with smaller error.
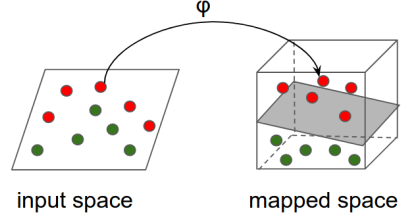
Case 5: How Complex are the Input/Output shapes?
XGBoost has more limitations than NNs regarding the shape of the data it can work with. It usually take 1-d arrays as record inputs and outputs a single number (regression) or a vector of probabilities (classification). For this reason, it is easier to configure an XGBoost pipeline. In XGBoost there is no need to worry about shapes of data — just provide a pandas datafame that looks like a table, set the label column and you are good to go.
Neural networks on the other hand, are designed to work on tensors — a high dimensional matrix. NN’s output and input shape can vary between numbers, sequences (vectors), images and even videos. So for classic problems like click-though prediction based on structured data —both can work well. in terms of data shape. But when it comes building more complex data transformations — the NN’s may be your only valid choise!
Case 6: Can I Have Both Please?
What if you don’t want to choose? In many cases, a combination of both models may achieve better results than each individual model. I already mentioned model-stacking in this post. The mathematical difference between models results in a different error distribution over the same data. When stacking the models — a lower error rate can be achieved while using the same amount of data — but with the cost of complicating the engineering of the system.
I’d like to thank Philip Tannor for his insightful remarks
Want more stories? Check our blog, or follow Gad on Twitter.

