




In the world of parsers, the state-of-the-art in text analysis power and functionality lies in a parser that can build an abstract syntax tree (AST) of your text. The main benefit of an AST is that you use a JSON string that contains classifications of the information that you parsed. It is extremely useful and easy for building services on top of. If the input text is a SQL statement, even more so.
Any SQL editor worth its weight in gold uses a parser. superQuery uses a parser called pegJs, a javascript-based system that has been enhanced by the team now acquired by DoiT International to also handle most of Google BigQuery’s syntax efficiently.
About zetaSQL
Early in 2019, Google open-sourced the AST-based parser called zetaSQL that is used in production for parsing and formatting queries in Google BigQuery and Cloud Spanner. The repository is here. zetaSQL can be compiled using bazel and consists mainly of C++ code, although a java implementation is also available.
Diving into the code, the parser has quite a few functionalities, some of which are:
- Formatting a SQL statement (sql_formatter.h)
- Analyzing a SQL statement (analyzer.h)
- Finding syntax errors and returning the error, line, and column to you (parse_helpers.h)
After looking into the repository, we quickly see that it seems easy to build. To save you time, I should point out that the file called .bazelrc is very important, as it sets the C++ compiler version to the correct level, as supported by the other software by Google. So it is of critical importance to have this file during a build.
Also, the base zetaSQL repository doesn’t offer a Dockerfile (yet) which allows you to build and compile the latest version of zetaSQL. I offer it here, based on Ubuntu 18.04 and the latest version of bazel.
My implementation (zetasql-analyzer-server) solves point 3 above, which is the syntax error finder. It is based on a Docker implementation made by apstndb called the zetasql-format-server (that solves point 2 above). Under the hood it is a golang server that wraps the formatter (or analyzer) api of zetaSQL and serves an endpoint in Google Cloud Run.
Examples
Simple one
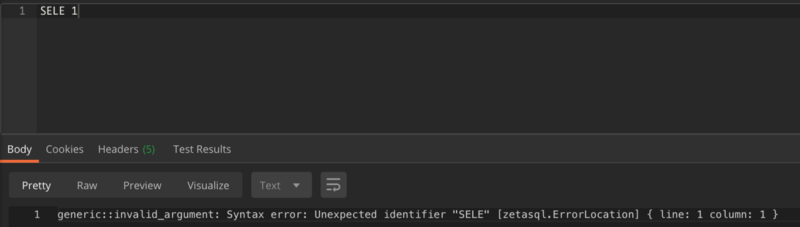
Here is an example output from the analyzer endpoint for an erroneous query SELEC 1 (the T is missing):
Complicated one
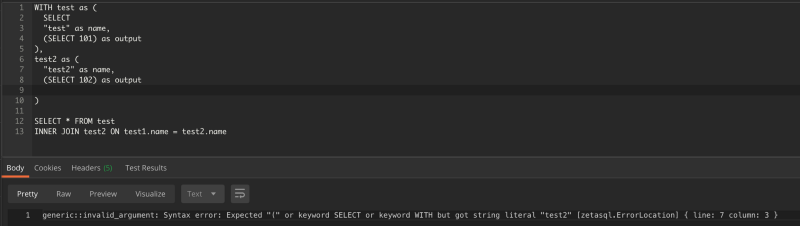
In the example below, the second nest of the query is missing the word SELECT . You can see that the parser indicates this information.
What about speed and performance?
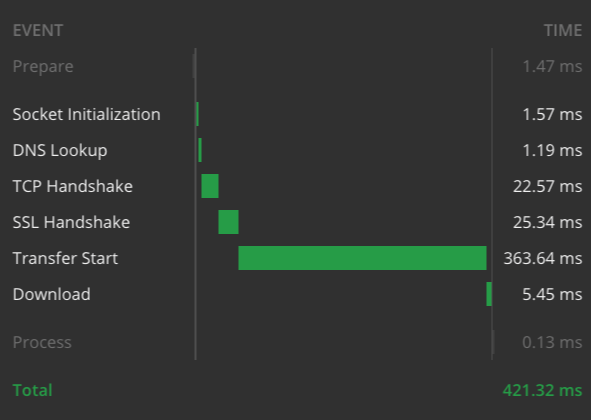
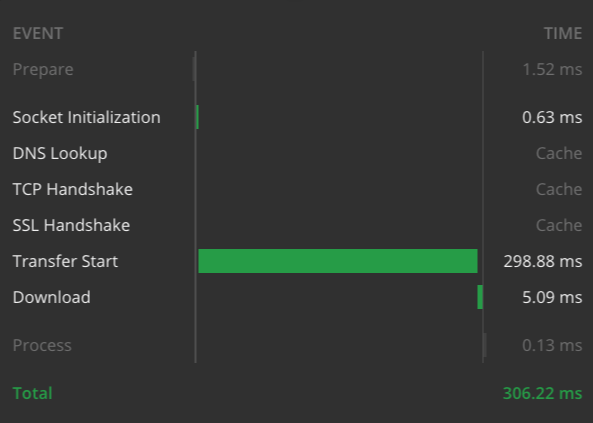
From the limited number of tests I’ve performed, it seems most responses (even for queries over 600 rows) stays within 1 second, with the mean of 300ms.
Here are timing graphs for the 2 examples from my laptop, with a high-speed internet connection:
The stack that allows this high speed parsing is using adistroless container image (https://github.com/GoogleContainerTools/distroless) and aserverless hardware implementation (Cloud Run) using C++ as input language.
Installation and Usage
To install this you are welcome to read the README file here. Let me know where I can help to get it going.
After creating an endpoint in Cloud Run, you can get information from it by issuing a curl command:
curl -X POST -H 'Content-type: application/text' --data 'SLECT 1, ' https://<your endpoint goes here>Lastly
Happy parsing!
References
- zetasql-analyzer-server: https://github.com/ebendutoit/zetasql-analyzer-server
- zetaSQL: https://github.com/google/zetasql
- zetasql-format-server: https://github.com/apstndb/zetasql-format-server

