



AWS released an awesome tool to teach Reinforcement Learning to beginners, but only exposed a limited interface for controlling it. We’ve hacked it and turned it into a Deep Q-Learning Raging Bull, compatible with OpenAI Gym and powered by TensorFlow.
Together with: Nir Malbin and Aviv Laufer

When AWS released its AWS DeepRacer, it was intended to teach the basics of reinforcement learning through an interactive and physical autonomous car. The car could only be controlled by specific types of models, trained using the AWS console and uploaded through the car’s interface. Little did they know that we were about to turn it into a raging bull that will learn to stampede towards objects!
The transformation required three steps: First, we had to discover the API running the car. Second, we had to develop a deep reinforcement learning environment and agent to integrate it with the controls of the car. Finally, we had to let the car learn how to steer and drive into objects.
Discovering the Car’s API
We wanted to discover the API used by the car. By logging the HTTP requests from the browser to the car, we found out that the API calls are in car_ip/api/. Having that knowledge, we connected to the car via SSH and by using the ‘ps’ command, we found that there is a Python web server up and running. We CD’d into the directory and grep the string “/API/” in all the PY files. Now we have the list of the APIs that the car supports.
Deep Object Detection
Object detection is a task in which we let a machine identify objects within an image. We used a TensorFlow/Keras implementation of the YOLOv3 model that can detect objects to extract the center and proportions of bottles with respect to the overall frame. The goal of the Deep-Q-Agent is to perform actions so that the center of the detected object would move towards the center of the frame.

The Deep-Q-Agent
Knowing where the bottle is with respect to the car is one thing, but how will the car know how to move towards it? If you are unfamiliar with the concept of Deep Reinforcement Learning, you would probably try to write a piece of code that does some sort of geometric calculations in order to find the estimated angle in which the car needs to move in order to bring itself closer, and in front of the bottle. Be that as it may, reinforcement learning enables you to let the machine learn how to control itself in order to accomplish this goal, through a process of trial and error. In this implementation, we used a method called Deep Q-Learning that helped Google’s DeepMind teach computers to win at games, as tested on the classic Atari 2600.
Deep Q-Learning
Deep Q-Learning is an approach to solve reinforcement learning without modeling the environment; e.g., not trying to model the physics of moving the car nor the interaction between the car and the bottle. Instead, letting the machine experiment and learn which actions will earn the best reward for a given state.
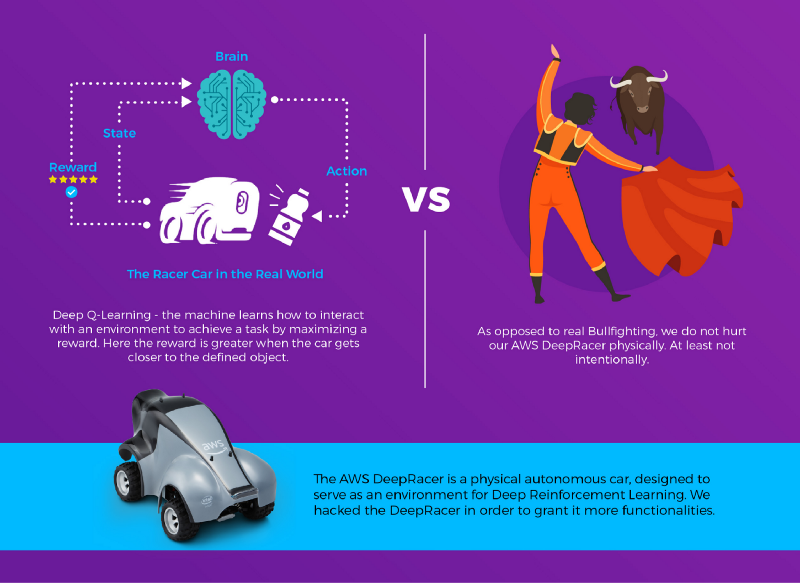
Reward?
In Reinforcement Learning, the reward is a score given as a consequence of the actor performing an action, assuming that it’s possible to evaluate how “good” an action was. The actor will try to optimize it’s actions so that the rewards it receives will be maximized. In our case, we thought that bringing the center of the detected object to the center of the frame would mean that the car would be standing in front of the object while enlarging the coverage of the detected object, meaning that the car is closer to the object. Hence we combined the two-to-one formula that outputs 1 when the car is in front of the object and it covers the entire screen, and less when it gets further:
# sizes are scaled so that the frame side = 1 step_reward = (1-distance_to_center)*(object_coverage)
Applying Deep-Q-Learning to DeepRacer
The DeepRacer movement is controlled by two parameters; angle and throttle. Both are floating-point numbers in the range of -1.0 and +1.0. An “action” would be to set angle and throttle values and let the car run for 0.3 seconds. In order to simplify the task, we discretized the continuous action space to 12 different tuples (angle, throttle), so that the task of the agent would be reduced to selecting one of 12 possible combinations given the observation.
https://www.youtube.com/watch?v=L2MsII6-kd8
https://gist.github.com/gidutz/d4e0d8aa90293bf5e90b428878f5da35
_____________________________________________________________
Liked the story? Follow Gad on Twitter to get the latest updates and content.


