



Training GANs using mixed precision VS single precision
In the previous post, we described how to change Tensorflow code to perform mixed precision training on Tensor Cores. In order to examine the benefits of using this method, we trained a Generative Adversarial Network (GAN) on Google Cloud’s Deep Learning VMs running on different hardware. We discovered that using mixed precision one can save up to 25% of the training cost on the cloud.

A little bit about GANs
GANs are complex networks composed of two sub-networks: a generator that receives as an input a noise and outputs a data (like images) and a discriminator that receives data as input and the output is a probability for the data to be generated or sampled from the dataset. In this example, we used an extension of the classic GAN model called AC-GAN that perform additional task of classifying the generated output
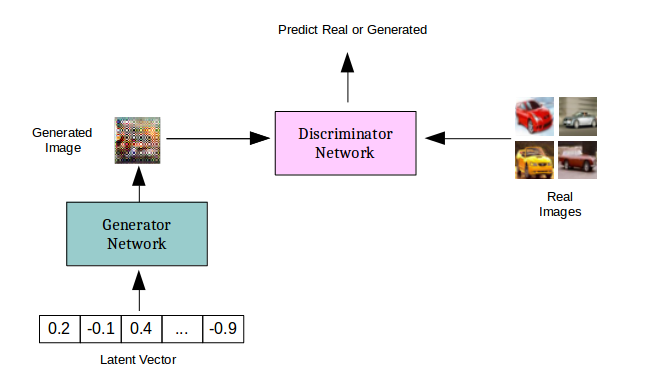
We extended Nvidia’s code relying on principles from Mixed precision training.
Part 1 — using mixed precision in code
Step 1- convert the model the use the float16 data type.
In order to utilize tensor-cores during mixed precision training, the code must use FP16 for heavy calculations. For example, we show the code changes made to the generator network to use FP16. The discriminator’s and the classifier’s code changes are similar to the generator.
We start with a generator using single precision:
https://gist.github.com/eladshabi/f5abe93ef7dd2e13b3cb2144bb8274a4
We create a custom conv2D layer used in the generator model:
https://gist.github.com/eladshabi/b9957db1b5d4feff8d6de824af4f7bad
To train using mixed precision we need to ensure the following:
- Enable Tensor Core path in the framework - choose FP16 format for tensors and/or convolution/fully-connected layers. This data type automatically takes advantage of the Tensor Core hardware whenever possible, in other words, to increase your chances for Tensor Core acceleration, choose where possible multiple of eight linear layer matrix dimensions and convolution channel counts
- Save the trainable parameters in FP32, and use a custom getter function to convert then to FP16 for the training.
- For specific parts like softmax and batch normalization layers, we use float32 to feed the layers in order to preserve the statistics.
After applying these principles the generator code would look like this:
https://gist.github.com/eladshabi/325aa0a4007343776221bb070b4d962f
Step 2 - Loss scaling.
Gradient calculation in mixed precision can result in vanishing gradients, in order to prevent that issue we'll do :
- Multiplying the loss by a scale factor.
- Calculate the gradient using the scaled loss.
- Dividing the gradients by the scale factor.
- Continue the optimization stage as usual.
Now we can run the mixed precision training with :
training_step_op_D/G/Q.
Part 2 — analyzing the results
GAN results
To examine the GAN results, I trained the GAN on the Quick-draw dataset for 7 minutes using V100 GPU and batch size of 1024. The results were very clear, while the single precision was able to generate only noise, the mixed precision mode generates clear and well results.=


Training Speed and cost analysis
The following results are related were achieved using V100, T4 and P100 GPUs, to generate images from the CIFAR-10 dataset.
- Using mixed precision with small batch size - The difference between training with mixed precision and single precision was insignificant. moreover, the overhead from casting the variables even slowed the training by little.
- Using mixed precision with larger batch size- For GPUs with tensor cores increasing the batch size reduce the average time to complete the batch by 15%-40%. The largest gain was achieved on T4, while single precision took around 700 ms per batch of 2048 samples using mixed precision reduced the time to approximately 410 ms.
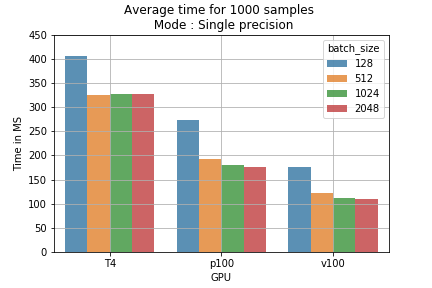
The advantage of the tensor cores comes from the ability to do massive calculation sequentially (loading and processing). When using a small batch size the loading part is more often, and the processing time is shorter and vice versa on larger batch size. On fig 1 we can see the difference. When training on the P100, that doesn’t have any tensor cores, no decrease was observed in the training time (ensuring that we are using the Tensor Cores).
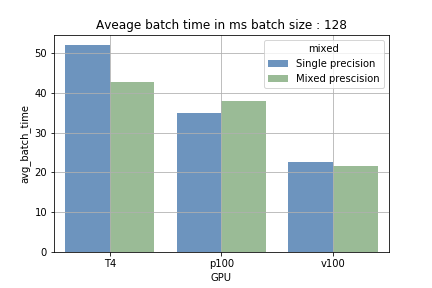
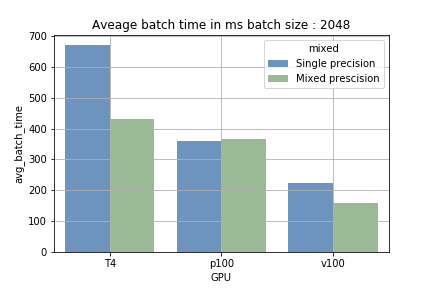
Tensor cores can save money
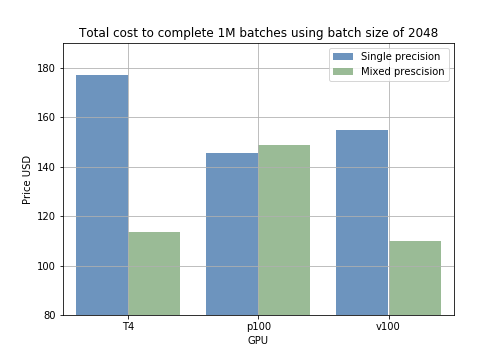
The results can be converted to training cost. for example running 1000 samples with different batch size using mixed precision model takes less time compare to single precision (fig 2). By calculating the price of training for 1 million batches we can see for example, that using mixed precision with a batch size of 2048 on T4 GPU will reduce the cost from 178$ to 118$ (save 60$ per 1M samples) (fig 3).
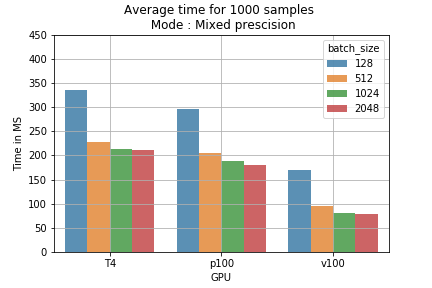
Conclusions
As AI models become more complicated and smarter applications are applied the human brain will have to work hard on how to make training feasible. Tensor Cores’ technology is definitely a game changer in AI training. However, Tensor Cores mostly benefit when using mixed precision on large networks with large batch size.


