



KubeMQ is a container-first solution for a Kubernetes world
We cannot simply sign off on a battle-tested, proven messaging system like Kafka, but the evolution towards a more scalable, reliable, functional and easier-to-maintain messaging system must begin, as many organizations are adopting the microservice-based, containerized architecture model.
Gartner predicts that, by the end of 2022, 75% of global organizations will be utilizing Kubernetes and its containerized approach to managing and scaling production applications, a huge jump from a mere 30% in 2019. As we will demonstrate, Kafka is not optimally designed for containerization, so a container-first solution has emerged to replace it in a Kubernetes-run world.
Kafka Innovation:
Kafka was invented to solve LinkedIn’s need for a low latency data collection system for the real-time data generated by 675 million-plus customers daily. When Kafka was under development in 2010, LinkedIn’s data infrastructure was monolithic, on-prem and Java-based. Kafka retained those characteristics, so no matter what platform your application is built on, you will need Java Virtual Machine (JVM) running in your Infrastructure if you plan to use Kafka.
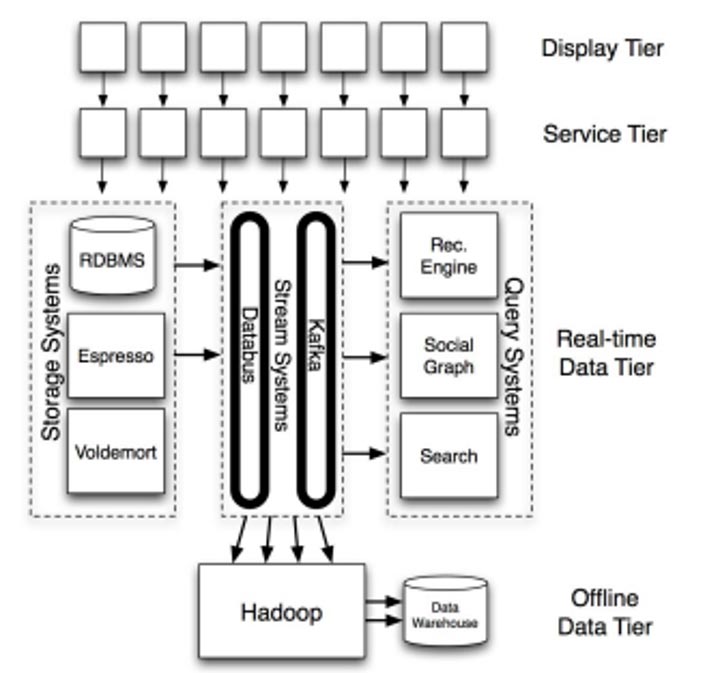
A very high-level overview of LinkedIn’s architecture, focusing on the core data systems.
Kafka and Kubernetes Deployment:
If you decide to migrate to Kubernetes and choose Kafka as your messaging system, here are the requirements:
- Zookeeper orchestrator for managing Kafka brokers and topic is a must when creating a K8 cluster using Kafka, so a single container weighs 600 MB for Kafka and 100 MB for Zookeeper.
- Kafka performance depends upon a low latency network and high bandwidth. As with Kafka brokers, don’t attempt to put all brokers on a single node, as this will reduce availability. Different availability zones are an acceptable trade-off.
- If storage in the container is not persistent, data will be lost after restart. EmptyDir is used for Kafka data and will persist if the container restarts. So, if the container starts, the failing broker first must replicate all the data, which is a time-consuming process. That's why you should use a persistence volume, and storage must be nonlocal so that Kubernetes will be more flexible in choosing another node after restart or relocation.
- Kafka was created using Java and Scala, so your team should have a resource with significant experience in both Java and Scala for proper tuning and debugging..
- Finally, you will need a third-party monitoring tool to track and monitor Kafka performance.
KubeMQ Innovation:
KubeMQ was built with Kubernetes in mind. It is delivered by default in a preconfigured cluster. Its greatest strengths are statelessness and ease of deployment and configuration by any DevOps team member with experience in Kubernetes.
There is no need for a Java or Scala specialty skill set. KubeMQ supports all messaging patterns – synchronous as well as asynchronous – whereas Kafka only supports asynchronous messaging patterns.
KubeMQ container is super lightweight at only 30 MB, making it a very good candidate to integrate in microservices. Built with Kubernetes in mind, KubeMQ is very flexible when it comes to all types of environments: multi-cloud, hybrid or single cloud. A few of its key advantages are listed below.
- Deployed with Operator for full life cycle operation
- Blazing fast (written in Go), small and lightweight Docker container
- Asynchronous and synchronous messaging with support for At Most Once Delivery and At Least Once Delivery models
- Supports durable FIFO based Queue, Publish-Subscribe Events, Publish-Subscribe with Persistence (Events Store), RPC Command and Query messaging patterns
- Supports gRPC, Rest and WebSocket Transport protocols with TLS support (both RPC and Stream modes)
- Supports Access control Authorization and Authentication
- Supports message masticating and smart routing
- No message broker configuration needed (i.e., queues, exchanges)
- SDK support for .Net, Java, Python, Go and NodeJS
KubeMQ and Kubernetes Deployment:
These are the steps to deploy KubeMQ in a Kubernetes cluster:
kubectl apply -f https://deploy.kubemq.io/community
That’s it, you’re done. For extensive documentation on KubeMQ you can refer to the docs page. The KubeMQ git repo can be found here. There are no special networking requirements, no memory overhead due to large containers running JVM, and anyone with a basic Devops background can deploy it. Usage of small, lightweight docker containers with software written in Go together make it blazing fast.
Wow, KubeMQ is awesome. But I am already running Kafka Cluster. What do I do?
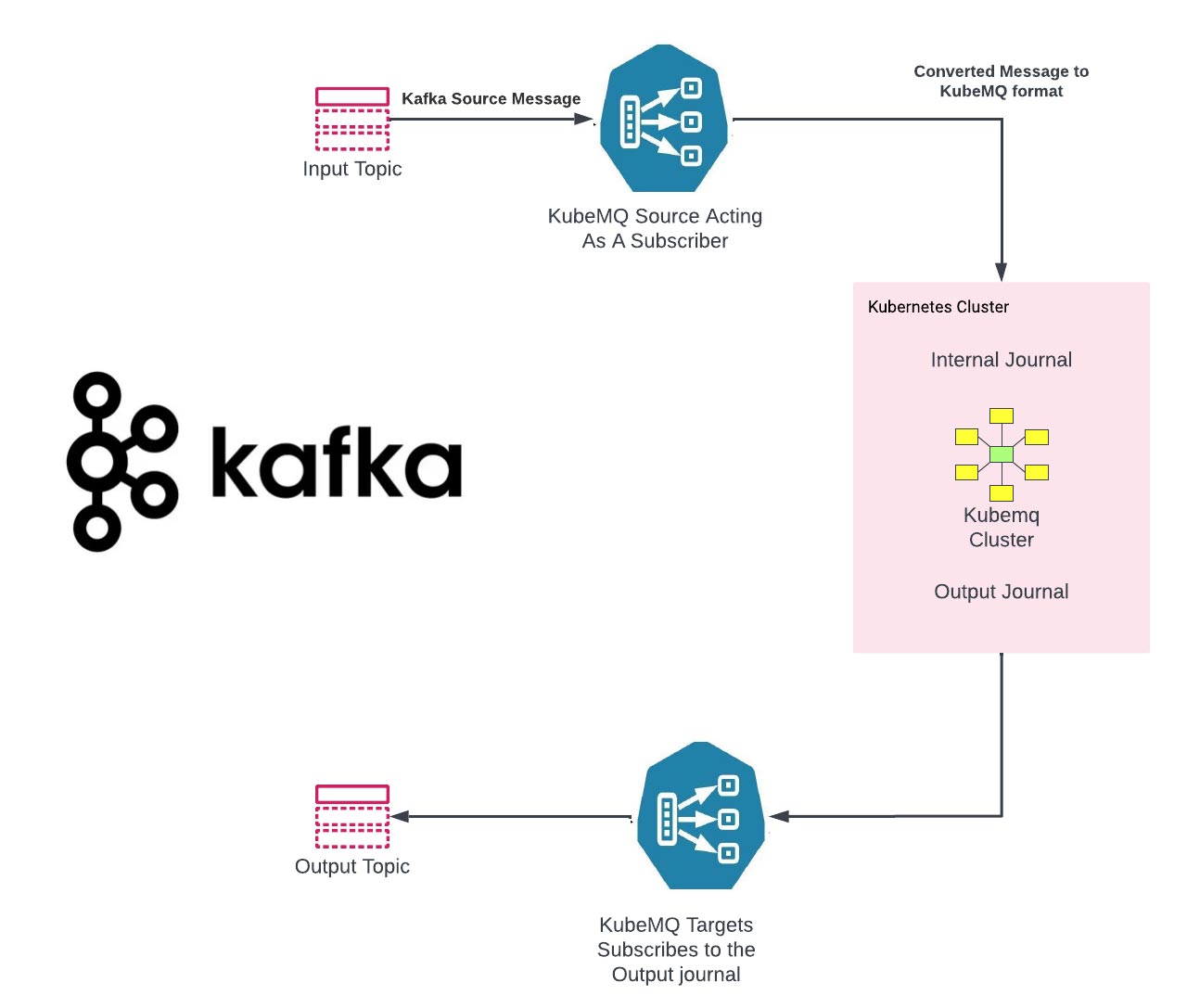
KubeMQ has developed universal connectors that make it easy to migrate the legacy systems to KubeMQ:
KubeMQ Source - https://github.com/kubemq-io/kubemq-sources
KubeMQ Targets - https://github.com/kubemq-io/kubemq-targets
Example Of KubeMQ Source for Kafka - https://github.com/kubemq-io/kubemq-sources/blob/master/examples/messaging/kafka/main.go
Example of KubeMQ Target For Kafka - https://github.com/kubemq-io/kubemq-targets/blob/master/examples/messaging/kafka/main.go
Wrapping up
When you are choosing between stateless vs stateful messaging systems to integrate into your stack, it is always best to opt for stateless systems that offer fewer dependencies, faster processing times and less complex recovery from messaging system crashes. When tested for performance against Kafka, KubeMQ has returned 20% faster message processing speed. The greatest advantage of KubeMQ is that it supports Pub/Sub with or without persistence, Request/Reply (sync, async), at least once delivery, streaming patterns and RPC. You are not tied to only async Patterns as you are with Kafka.
If you need assistance with this or any aspect of your cloud infrastructure, talk to DoiT International. Recently named 2021 Google Cloud Sales Partner of the Year, we offer expert consultancy paired with unlimited, world-class support to customers of all sizes across Google Workspace and Google Cloud Platform.


