Les infrastructures cloud modernes cherchent à concilier flexibilité, contrôle et charge opérationnelle. Avec Kubernetes, de nombreuses organisations veulent un contrôle fin sur les nœuds, le réseau, le stockage, etc., mais gérer et maintenir cette infrastructure peut vite devenir lourd.
Google Kubernetes Engine (GKE) répond à ce besoin via deux modes :
- Mode Standard : vous gérez les node pools, les calendriers de mise à niveau, les images d'OS, etc.
- Mode Autopilot : Google prend en charge l'essentiel de l'infrastructure, y compris l'autoscaling, les mises à niveau et les configurations de sécurité.
Mais que faire si vous avez besoin du contrôle granulaire du mode Standard pour certains workloads et de l'expérience managée et sans intervention du mode Autopilot pour d'autres, le tout au sein d'un même cluster ?
GKE prend désormais en charge ce modèle hybride grâce aux Autopilot ComputeClasses dans les clusters Standard, qui permettent d'exécuter des workloads gérés par Autopilot au sein d'un cluster Standard.
Les défis des clusters Standard et Autopilot
Voici quelques-unes des difficultés rencontrées par les organisations avec des clusters purement Standard ou purement Autopilot, et pourquoi aucun de ces modes ne suffit toujours à lui seul.
- Charge opérationnelle des clusters Standard : vous gardez un contrôle total, mais vous assumez aussi la responsabilité du scaling, de la maintenance et de la sécurité, ce qui peut représenter un effort considérable pour les petites équipes.
- Perte de flexibilité dans les clusters Autopilot : Autopilot offre davantage d'opérations managées, mais impose aussi des contraintes : requêtes de ressources minimales, images d'OS imposées, contrôle limité sur la configuration des nœuds, etc.
- Coûts et facturation : dans un cluster Standard, vous payez pour les machines virtuelles (VM) qui composent vos node pools, que vos workloads exploitent ou non l'ensemble des ressources disponibles. Sans une gestion rigoureuse, cela mène vite au surprovisionnement et à des dépenses inutiles.
Beaucoup d'organisations se sont donc retrouvées contraintes de choisir entre le mode Standard intégral (flexible, mais plus de maintenance) ou le mode Autopilot intégral (moins de maintenance, mais moins de contrôle et plus de contraintes). Aucune de ces options n'est idéale dès lors que les workloads sont mixtes.
La solution : les Autopilot ComputeClasses dans les clusters Standard
Le mécanisme Autopilot ComputeClasses in Standard Clusters de GKE s'appuie sur les ComputeClasses (une ressource personnalisée Kubernetes qui définit une liste de configurations de nœuds, comme les types de machines ou les paramètres de fonctionnalités) pour activer ce modèle hybride. Celui-ci ouvre un nouveau niveau de flexibilité et offre plusieurs avantages clés.
Le mode Autopilot dans Standard repose sur une nouvelle plateforme de calcul optimisée pour les conteneurs, conçue pour offrir une latence minimale et des performances maximales. Ce nouveau socle permet une planification des pods jusqu'à 7 fois plus rapide, améliorant nettement les temps de réponse des applications pour les workloads configurés pour utiliser les Autopilot ComputeClasses.
Parmi les principaux avantages :
- Exécuter des workloads spécifiques en mode Autopilot, entièrement gérés par Google.
- Conserver le contrôle manuel sur les workloads et l'infrastructure qui n'utilisent pas le mode Autopilot, comme les node pools créés manuellement.
- Définir une Autopilot ComputeClass comme classe par défaut pour votre cluster ou votre namespace, afin que les workloads bénéficient automatiquement des avantages d'Autopilot, sauf indication contraire.
Prérequis et limites
Cela vous semble intéressant ? Consultez les prérequis et limites avant d'activer les workloads Autopilot dans un cluster Standard.
- Les nœuds Autopilot appliquent des règles de fonctionnalités et de sécurité strictes. Les workloads standards peuvent être rejetés s'ils ne respectent pas ces exigences. Vérifiez donc les paramètres des nœuds pour vous assurer de la compatibilité.
- Le cluster doit être enregistré sur le canal Rapid release et exécuter la version 1.33.1-gke.1107000 ou ultérieure.
- Le canal Rapid déploie plus rapidement les nouvelles fonctionnalités et les nouvelles versions de Kubernetes, mais peut aussi inclure des breaking changes. Examinez et corrigez toute modification d'API ou autre avant de mettre à niveau le cluster.
- Au moins un node pool du cluster ne doit comporter aucun node taint, afin de pouvoir exécuter les pods système standards.
- Le cluster doit être VPC-native, avec les Shielded GKE Nodes activés par défaut.
Autopilot ComputeClasses intégrées
GKE configure automatiquement les ressources personnalisées ComputeClasses autopilot et autopilot-spot dès que le cluster est mis à niveau vers une version compatible.
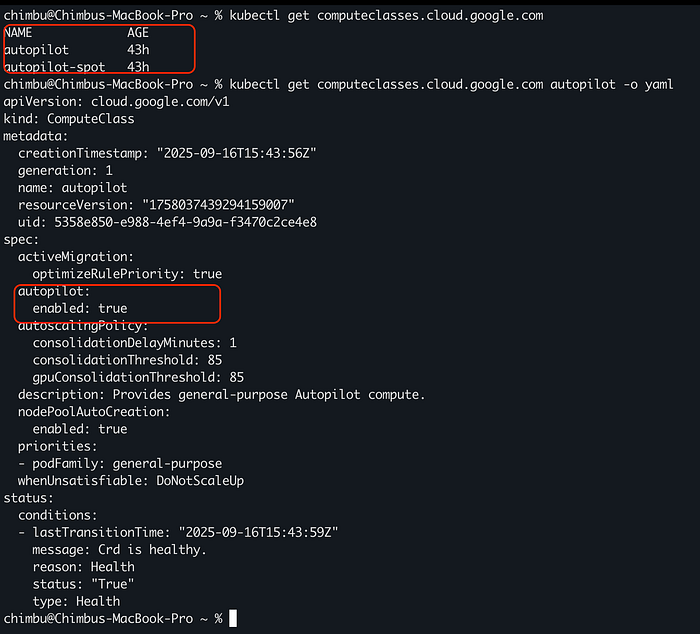
Exemples de ComputeClasses autopilot
Pour sélectionner une Autopilot ComputeClass dans un workload, utilisez un node selector sur le label cloud.google.com/compute-class.
#Sample workload that uses built-in autopilot ComputeClass
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloweb
labels:
app: hello
spec:
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
nodeSelector:
# Replace COMPUTE_CLASS with the name of the compute class to use.
cloud.google.com/compute-class: COMPUTE_CLASS
containers:
- name: hello-app
image: us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0
ports:
- containerPort: 8080
resources:
requests:
cpu: "250m"
memory: "4Gi"

Les ressources des conteneurs sont automatiquement ajustées pour répondre aux exigences d'Autopilot, puis planifiées sur des nœuds de la plateforme de calcul optimisée pour les conteneurs.
ComputeClasses personnalisées
Si les ComputeClasses intégrées ne répondent pas à vos besoins, vous pouvez créer des Autopilot ComputeClasses personnalisées, adaptées à des workloads spécifiques. C'est particulièrement utile pour les workloads nécessitant des GPU ou certaines familles de machines.
Si vous utilisez déjà une ComputeClass personnalisée, pour faire passer les ressources ComputeClass existantes du cluster en mode Autopilot, vous devez recréer la ComputeClass avec une spécification mise à jour. Pour en savoir plus, consultez Activer Autopilot pour une ComputeClass personnalisée existante.
#sample custom ComputeClass with autopilot mode enabled
---
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: autopilot-n2-class
spec:
autopilot:
enabled: true
priorities:
- machineFamily: n2
spot: true
minCores: 64
- machineFamily: n2
spot: true
- machineFamily: n2
spot: false
activeMigration:
optimizeRulePriority: true
whenUnsatisfiable: DoNotScaleUp
La règle de priorité
podFamilyn'est pas utilisable dans vos propres ComputeClasses. Elle est disponible uniquement dans les Autopilot ComputeClasses intégrées.
Les ComputeClasses personnalisées avec le mode Autopilot activé permettent de définir une compute class par défaut au niveau du cluster GKE ou du namespace. La classe par défaut ainsi configurée s'applique à tout pod de ce cluster ou de ce namespace qui ne spécifie pas d'autre compute class. Lorsque vous déployez un pod qui n'en précise aucune, GKE applique les compute classes par défaut dans l'ordre suivant :
- Si le namespace dispose d'une compute class par défaut, GKE modifie la spécification du pod pour sélectionner cette compute class.
- Sinon, le paramètre par défaut du cluster s'applique s'il est configuré, et GKE ne modifie pas le pod.
Pour plus de détails, consultez ce lien.
Pouvoir exécuter des workloads en mode Autopilot au sein de clusters Standard offre aux organisations le meilleur des deux mondes : une charge de gestion allégée pour certains workloads, tout en préservant la flexibilité et le contrôle là où c'est nécessaire.
Si vous évaluez cette approche pour un proof of concept ou que vous planifiez des déploiements, DoiT peut vous accompagner. Notre équipe de plus de 100 experts est spécialisée dans les solutions cloud sur mesure, prête à vous guider tout au long du processus et à optimiser votre infrastructure pour répondre aux exigences de conformité et aux besoins futurs.
Échangeons sur l'approche la plus pertinente pour votre entreprise durant cette phase d'application des règles, afin de garantir une infrastructure cloud robuste, conforme et taillée pour la réussite. Contactez-nous dès aujourd'hui.