Moderne Cloud-Infrastrukturen müssen Flexibilität, Kontrolle und Betriebsaufwand in Einklang bringen. Mit Kubernetes wünschen sich viele Unternehmen feingranulare Kontrolle über Nodes, Networking, Storage und mehr – die Verwaltung und Pflege dieser Infrastruktur wird jedoch schnell zur Belastung.
Google Kubernetes Engine (GKE) adressiert das mit zwei Modi:
- Standard-Modus: Sie verwalten Node-Pools, Upgrade-Zeitpläne, OS-Images usw. selbst.
- Autopilot-Modus: Google übernimmt einen Großteil der Infrastruktur, einschließlich Autoscaling, Upgrades und Sicherheitskonfigurationen.
Doch was, wenn Sie für einige Workloads die granulare Kontrolle des Standard-Modus brauchen und für andere den wartungsarmen, vollständig verwalteten Komfort des Autopilot-Modus – und das alles im selben Cluster?
GKE unterstützt dieses hybride Modell jetzt über Autopilot-ComputeClasses in Standard-Clustern. So lassen sich Autopilot-verwaltete Workloads innerhalb eines Standard-Clusters betreiben.
Herausforderungen mit Standard- und Autopilot-Clustern
Im Folgenden einige typische Probleme, mit denen Unternehmen bei rein Standard- oder rein Autopilot-Clustern zu kämpfen haben – und warum keiner der beiden Modi für sich allein immer ausreicht.
- Betriebsaufwand in Standard-Clustern: Sie haben die volle Kontrolle, tragen aber auch die Verantwortung für Skalierung, Wartung und Sicherheit. Für kleinere Teams kann das schnell zur Belastung werden.
- Eingeschränkte Flexibilität in Autopilot-Clustern: Autopilot nimmt Ihnen viel Betrieb ab, bringt aber auch Einschränkungen mit sich: Mindest-Resource-Requests, vorgegebene OS-Images, weniger Kontrolle über die Node-Konfiguration und so weiter.
- Kosten und Abrechnung: In einem Standard-Cluster zahlen Sie für die virtuellen Maschinen (VMs), aus denen Ihre Node-Pools bestehen – unabhängig davon, ob Ihre Workloads die verfügbaren Ressourcen tatsächlich nutzen. Ohne sorgfältiges Management führt das schnell zu Overprovisioning und unnötigen Kosten.
Aus diesen Gründen mussten viele Unternehmen sich bislang zwischen reinem Standard-Modus (flexibel, aber wartungsintensiv) und reinem Autopilot-Modus (wartungsarm, aber weniger Kontrolle und mehr Einschränkungen) entscheiden. In Szenarien mit gemischten Workloads ist keine der beiden Optionen wirklich ideal.
Die Lösung: Autopilot-ComputeClasses in Standard-Clustern
Der Mechanismus "Autopilot ComputeClasses in Standard Clusters" von GKE setzt auf ComputeClasses – eine Kubernetes Custom Resource, die eine Liste von Node-Konfigurationen wie Maschinentypen oder Feature-Einstellungen definiert. Damit wird das hybride Modell möglich, das eine neue Flexibilitätsstufe und mehrere zentrale Vorteile bietet.
Der Autopilot-Modus in Standard basiert auf einer neuen, container-optimierten Compute-Plattform, die auf minimale Latenz und maximale Performance ausgelegt ist. Sie ermöglicht bis zu 7-mal schnelleres Pod-Scheduling und verkürzt damit die Antwortzeiten von Anwendungen, deren Workloads für die Autopilot-ComputeClasses konfiguriert sind, deutlich.
Weitere zentrale Vorteile:
- Bestimmte Workloads im Autopilot-Modus betreiben – vollständig verwaltet von Google.
- Die manuelle Kontrolle über Workloads und Infrastruktur behalten, die nicht im Autopilot-Modus laufen, etwa manuell erstellte Node-Pools.
- Eine Autopilot-ComputeClass als Standard für Cluster oder Namespace festlegen, sodass Workloads automatisch von den Autopilot-Vorteilen profitieren – sofern nichts anderes angegeben ist.
Voraussetzungen und Einschränkungen
Klingt spannend? Dann werfen Sie zuerst einen Blick auf die Voraussetzungen und Einschränkungen, bevor Sie Autopilot-Workloads in einem Standard-Cluster aktivieren.
- Autopilot-Nodes unterliegen strengen Feature- und Sicherheitsregeln. Standard-Workloads können abgelehnt werden, wenn sie diese Anforderungen nicht erfüllen. Prüfen Sie daher die Node-Einstellungen auf Kompatibilität.
- Der Cluster muss im Rapid Release Channel registriert sein und Version 1.33.1-gke.1107000 oder höher ausführen.
- Rapid Release liefert neue Features und Kubernetes-Versionen schneller, kann aber auch Breaking Changes enthalten. Prüfen und beheben Sie API- oder andere Änderungen, bevor Sie den Cluster aktualisieren.
- Mindestens ein Node-Pool im Cluster darf keine Node Taints haben, damit die Standard-System-Pods ausgeführt werden können.
- Der Cluster muss VPC-nativ sein, mit standardmäßig aktivierten Shielded GKE Nodes.
Integrierte Autopilot-ComputeClasses
GKE konfiguriert die Custom Resources autopilot und autopilot-spot automatisch, sobald der Cluster auf eine unterstützte Version aktualisiert wurde.
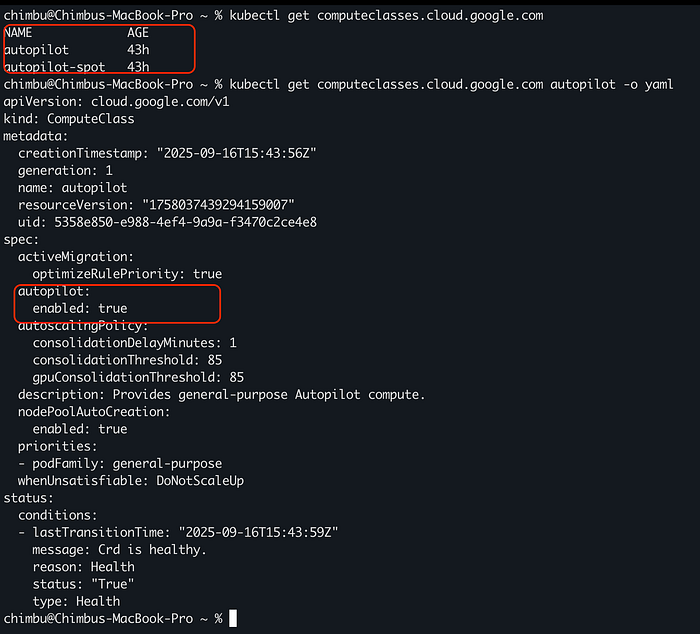
Beispiel für Autopilot-ComputeClasses
Um eine Autopilot-ComputeClass in einem Workload auszuwählen, verwenden Sie einen Node Selector für das Label cloud.google.com/compute-class.
#Beispiel-Workload, der die integrierte autopilot ComputeClass nutzt
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloweb
labels:
app: hello
spec:
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
nodeSelector:
# Ersetzen Sie COMPUTE_CLASS durch den Namen der zu verwendenden Compute Class.
cloud.google.com/compute-class: COMPUTE_CLASS
containers:
- name: hello-app
image: us-docker.pkg.dev/google-samples/containers/gke/hello-app:1.0
ports:
- containerPort: 8080
resources:
requests:
cpu: "250m"
memory: "4Gi"

Die Container-Ressourcen werden automatisch an die Autopilot-Anforderungen angepasst und auf Nodes der container-optimierten Compute-Plattform eingeplant.
Eigene ComputeClasses
Wenn die integrierten ComputeClasses Ihre Anforderungen nicht abdecken, können Sie eigene Autopilot-ComputeClasses erstellen, die auf bestimmte Workloads zugeschnitten sind. Besonders sinnvoll ist das für Workloads, die GPUs oder bestimmte Maschinenfamilien voraussetzen.
Wenn Sie bereits Custom ComputeClasses einsetzen und vorhandene ComputeClass-Ressourcen im Cluster auf den Autopilot-Modus umstellen möchten, müssen Sie die jeweilige ComputeClass mit einer aktualisierten Spezifikation neu anlegen. Weitere Informationen finden Sie unter Autopilot für eine vorhandene Custom ComputeClass aktivieren.
#sample custom ComputeClass with autopilot mode enabled
---
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: autopilot-n2-class
spec:
autopilot:
enabled: true
priorities:
- machineFamily: n2
spot: true
minCores: 64
- machineFamily: n2
spot: true
- machineFamily: n2
spot: false
activeMigration:
optimizeRulePriority: true
whenUnsatisfiable: DoNotScaleUp
Die Prioritätsregel
podFamilylässt sich in eigenen ComputeClasses nicht verwenden. Sie steht ausschließlich in den integrierten Autopilot-ComputeClasses zur Verfügung.
Mit eigenen ComputeClasses im Autopilot-Modus können Sie eine Standard-Compute-Class auf Cluster- oder Namespace-Ebene festlegen. Die konfigurierte Standardklasse gilt für jeden Pod im jeweiligen Cluster oder Namespace, der keine andere Compute Class angibt. Wird ein Pod ohne Compute-Class-Angabe deployt, wendet GKE die Standard-Compute-Classes in folgender Reihenfolge an:
- Hat der Namespace eine Standard-Compute-Class, passt GKE die Pod-Spezifikation entsprechend an und wählt diese Compute Class aus.
- Andernfalls greift die Standardeinstellung des Clusters, sofern konfiguriert – GKE verändert den Pod dann nicht.
Weitere Details finden Sie unter diesem Link.
Autopilot-Workloads innerhalb von Standard-Clustern auszuführen, bringt Unternehmen das Beste aus beiden Welten: weniger Verwaltungsaufwand für ausgewählte Workloads – und gleichzeitig die nötige Flexibilität und Kontrolle dort, wo sie gebraucht wird.
Wenn Sie diesen Ansatz in einem Proof of Concept evaluieren oder konkrete Deployments planen, unterstützt Sie DoiT. Unser Team aus über 100 Expertinnen und Experten ist auf maßgeschneiderte Cloud-Lösungen spezialisiert, begleitet Sie durch den gesamten Prozess und sorgt dafür, dass Ihre Infrastruktur Compliance-Anforderungen erfüllt und für künftige Anforderungen gerüstet ist.
Lassen Sie uns gemeinsam klären, was in dieser Phase der Richtlinien-Durchsetzung für Ihr Unternehmen am sinnvollsten ist – damit Ihre Cloud-Infrastruktur robust, konform und auf Erfolg ausgerichtet bleibt. Sprechen Sie uns an.