




En el mundo de la ingeniería en la nube, la velocidad lo es todo. Los equipos están sometidos a una presión constante para enviar funciones más rápidamente, escalar sistemas de forma más eficiente y ofrecer valor empresarial sin demora.
Teniendo en cuenta estos objetivos generales, probablemente no debería sorprender demasiado que las tareas rutinarias de mantenimiento de la nube se queden a menudo en el camino. Incluso con los ahorros que puede proporcionar el mantenimiento de optimización de costes, el ROI final es difícil de calcular por adelantado, y por tanto difícil de priorizar frente a otras tareas críticas de ingeniería.
Sin embargo, a largo plazo, descuidar estas pequeñas tareas puede acumularse silenciosamente en importantes ineficiencias de costes, junto con el riesgo operativo.
El coste de las optimizaciones en la nube no realizadas
Toda organización tiene ineficiencias en la nube ocultas a plena vista. Algunas son obvias, como las instancias sobreaprovisionadas o las cargas de trabajo zombis. Otras son más sutiles, como cubos de cargas incompletas y multiparte en S3 que acumulan lentamente cargos de almacenamiento.
La mayoría de los equipos de la nube saben que estos problemas existen. El problema no es la conciencia, sino la prioridad. Cuando los ingenieros se miden por la velocidad del producto, es difícil justificar el gasto de ciclos peinando cubos de S3 o comprobando si faltan reglas de limpieza.
Y, sin embargo, estas optimizaciones no realizadas suelen tener un impacto financiero mensurable. Son el tipo de tareas lo suficientemente molestas como para ignorarlas, pero lo suficientemente costosas como para que importen con el tiempo.
Por qué se pasan por alto las tareas de mantenimiento
Pregunta a cualquier ingeniero de la nube en qué invierte su tiempo, y oirás variaciones sobre el mismo tema: crear nuevas funciones, responder a incidencias, apoyar la productividad de los desarrolladores, mantenerse al día con los nuevos servicios y API: las tareas parecen no tener fin.
Mientras tanto, la higiene en la nube, como auditar las políticas de IAM, configurar el borrado automático en volúmenes no conectados o establecer reglas de ciclo de vida para cargas incompletas en S3, se agrupa en una categoría que se describe mejor como: "Nos ocuparemos de ello más tarde".
El problema es que "más tarde" rara vez llega.
Un ejemplo: Limpieza de cargas multiparte en S3
Tomemos el caso concreto de las cargas multiparte de Amazon S3. Cuando se inicia una subida pero nunca se completa (lo que ocurre más de lo que crees), AWS sigue almacenando las partes subidas, cobrándote por el almacenamiento, aunque el objeto en sí nunca se haya finalizado.
La solución es sencilla: configura una regla de ciclo de vida para aborte las subidas multiparte incompletas tras un número determinado de días (normalmente 7). Pero en la práctica, muchos cubos de S3 no cumplen esta regla.
¿Por qué? Porque para hacerlo en la consola de AWS, esto es lo que hay que hacer:
Proceso manual para administrar la limpieza de cargas multiparte de S3 mediante la consola de AWS
1. Accede a la consola de AWS
- Navega a la Consola de administración de AWS
- Ve al Panel de control del servicio S3
2. Revisa las reglas del ciclo de vida de cada cubo
Aquí es donde las cosas se vuelven ineficaces, porque no hay ninguna forma nativa en la consola de AWS de filtrar o buscar en los buckets las configuraciones del ciclo de vida o las reglas que faltan. En su lugar, el usuario debe
- Abre manualmente cada cubo
- Ir a Gestión → Reglas del ciclo de vida.
- Si existen reglas, inspecciónalas para confirmar si alguna gestiona "Subidas multiparte incompletas"
- Si existe una regla de este tipo (normalmente denominada "Abortar subidas multiparte incompletas después de X días"), no es necesario realizar ninguna otra acción
- Si no existe ninguna regla, procede a añadir una
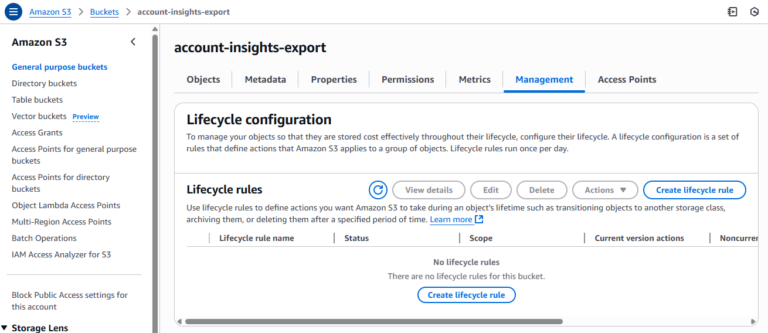
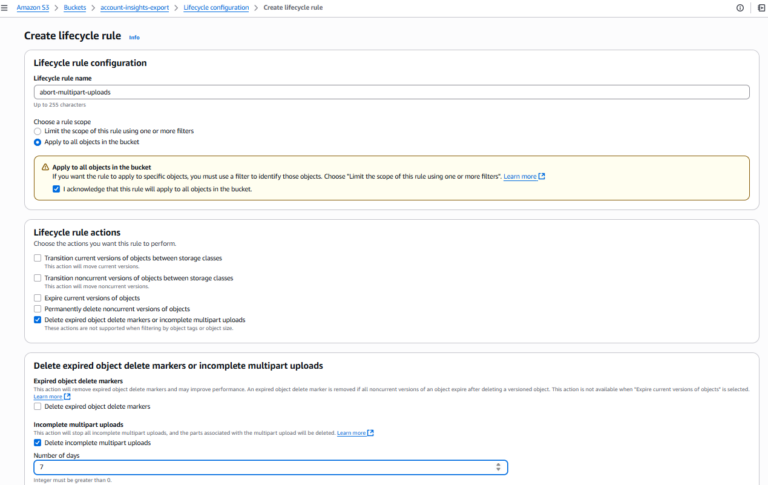
3. Añadir regla de limpieza multiparte
Para cada cubo que carezca de la regla:
- Haz clic en "Crear regla de ciclo de vida"
- Introduce un nombre de regla (por ejemplo abortar-cargas-multiparte)
- Elige el ámbito de la regla (por ejemplo aplicar a todos los objetos del cubo)
- En Acciones de las reglas del ciclo de vidamarca "Borrar marcadores de borrado de objetos caducados o carga multiparte incompleta"
- En Cargas multiparte incompletasmarca "Eliminar subidas multiparte incompletas"
- Establece el número de días tras el inicio (AWS recomienda 7 o menos)
- Revisa y guarda la regla
- Repite esto para cada cubo que necesite la regla
Como puedes ver, encontrar y solucionar el problema en decenas, cientos o incluso miles de cubos significa que todo este proceso repetitivo, lento y propenso a errores simplemente no se lleva a cabo.
Resolver el problema con la automatización del flujo de trabajo
Este tipo de tareas son candidatas ideales para la automatización, no porque sean técnicamente complejas, sino porque son aburridas desde el punto de vista operativo. Y las tareas aburridas son las que merman la productividad si se hacen manualmente, y dañan silenciosamente la eficiencia si se ignoran.
Pero con CloudFlowla solución de automatización del flujo de trabajo sin código de DoiT Inteligencia en la Nube™un ingeniero de la nube podría simplemente configurar el flujo de trabajo que desea realizar y hacer que el sistema haga el trabajo en segundos.
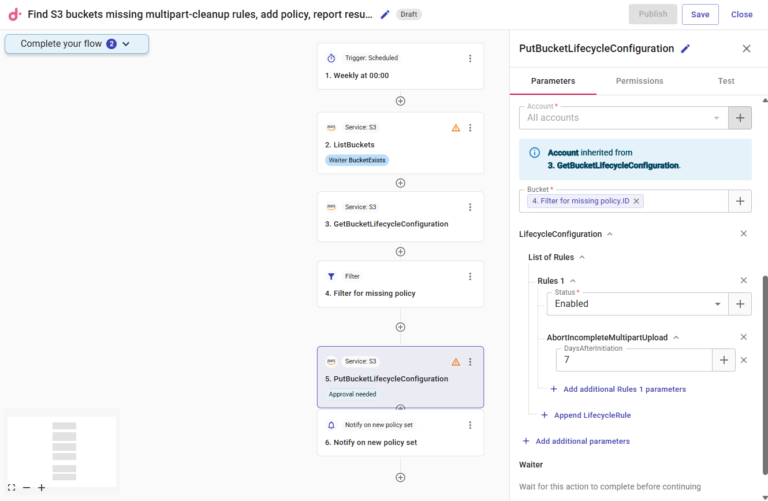
En este caso, un CloudFlow correspondiente podría tener este aspecto, en el que cada paso del flujo sustituiría a uno o más pasos manuales que de otro modo tendrías que hacer en la consola de AWS:
- Establece un activador programado para la hora y cadencia en que quieres que se ejecute el CloudFlow
- Utilizando la funcionalidad de la API de CloudFlow, primero obtén la lista completa de buckets S3 en tu(s) cuenta(s) de AWS ("ListBuckets")
- De los cubos de la lista, obtén su configuración del ciclo de vida reglas ("GetBucketLifecycleConfiguration")
- Crea un nodo filtro para encontrar todos los cubos a los que les falta la regla requerida ("Filtro para la política que falta")
- Utiliza otra API de AWS para aplicar la nueva regla a todos los cubos filtrados ("PutBucketLifecycleCongifuration")
- Crea un paso de notificación para documentar el cambio y mantener informadas a todas las partes interesadas
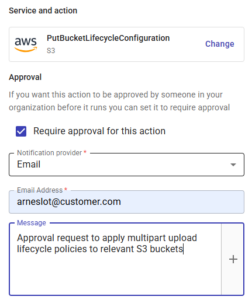
Para mantener el cumplimiento, también puedes aplicar una aprobación a cualquier paso del proceso para asegurarte de que no se modifica ningún cubo sin el permiso del administrador de la cuenta:
Este CloudFlow no sólo sustituye el tedioso y lento proceso de limpiar TODOS los buckets de S3 dentro de las cuentas especificadas, sino que también puede ejecutarse semanalmente para garantizar que cualquier bucket nuevo que se cree sin la regla del ciclo de vida pueda detectarse y modificarse correctamente para incluir la regla.
Este tipo de cambio no sólo ahorra tiempo, sino que cambia la forma de trabajar de los equipos. En lugar de dedicar horas a la limpieza inicial y luego realizar regularmente el mismo mantenimiento una y otra vez, CloudFlow pone el proceso en piloto automático y permite a los ingenieros de la nube centrarse en un trabajo que no sólo tiene un mayor impacto en los objetivos a largo plazo de la empresa, sino que también les libra de tareas aburridas que entumecen la mente.
Y la gestión del ciclo de vida de S3 es sólo un caso de uso potencial de CloudFlow; también puede utilizarse para aplicar de forma autónoma etiquetas a los recursos, activar y desactivar instancias, redimensionar cargas de trabajo o hacer cualquier otra cosa que pueda conseguirse con las API de AWS o Google Cloud.
Para saber más sobre cómo CloudFlow puede influir en la forma de trabajar de tu equipo, consulta esta visita guiadao ponte en contacto con un experto de DoiT.


