Ad AWS re:invent 2024 è stato pubblicato un annuncio dedicato ad Amazon S3 Tables: tabelle Apache Iceberg completamente gestite e ottimizzate per workloads di analytics. Queste tabelle si appoggiano su uno storage gestito in formato Iceberg, governabile tramite la s3tables API; per le operazioni sui dati è possibile integrarle con Apache Spark o con i servizi di analytics AWS — Amazon EMR, Amazon Athena, Amazon Redshift, Amazon EMR, Amazon QuickSight, Amazon Data Firehose.

Per prima cosa, occorre creare un table bucket dalla console o tramite AWS CLI; in questa fase è possibile abilitare l'integrazione del table bucket con i servizi di analytics AWS sopra elencati.
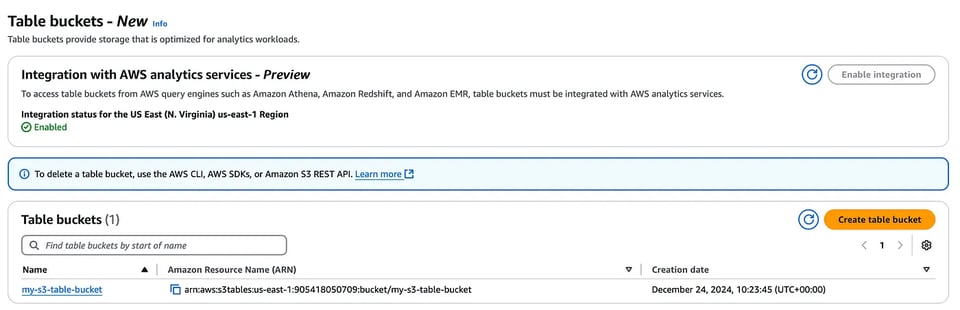
Console del table bucket S3
Una volta creato il table bucket, è il momento di creare un namespace (lo si può pensare come un database logico che ospita più tabelle) all'interno del quale risiederanno le nostre tabelle.
aws s3tables create-namespace \ --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace
aws s3tables create-table \ --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace \ --name my_first_table --format ICEBERG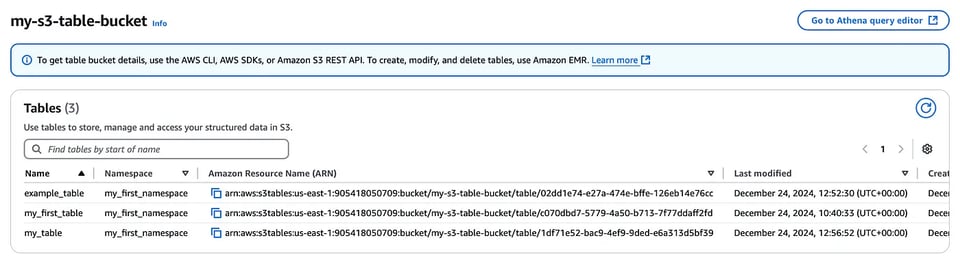 Tabelle create nella console del table bucket
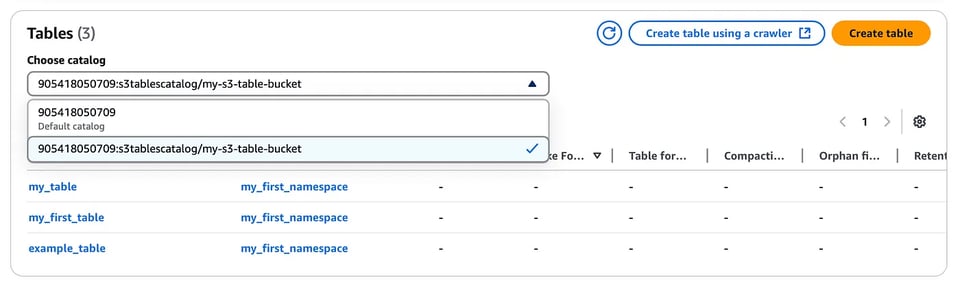
Tabelle create nella console del table bucket
Il formato delle tabelle si basa sul framework Apache Iceberg: lo storage sottostante contiene sia i dati sia i relativi metadati. Con S3 tables non occorre preoccuparsi della manutenzione: Amazon S3 mette a disposizione operazioni di manutenzione per migliorare le prestazioni delle S3 tables e dei table buckets, ovvero compaction dei file, gestione degli snapshot e rimozione dei file non referenziati. Tali opzioni sono attive di default. È possibile modificarle o disattivarle tramite i file di configurazione della manutenzione, oppure configurare i parametri del job di manutenzione con i valori più adatti alle proprie esigenze. Lo stato del job può essere consultato tramite la s3tables API.
aws s3tables get-table-maintenance-job-status \ --table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \ --namespace="mynamespace" \ --name="testtable"Prima di integrare le S3 tables con i servizi di analytics, è necessario completare i passaggi preliminari.
Crei un nuovo catalogo per le S3 tables.
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'Il catalogo verrà registrato in AWS LakeFormation; allo stesso modo, dalla console di LakeFormation potrà visualizzare il namespace e la tabella creati in precedenza (dovrà selezionare dal menu a discesa il catalogo S3 table appena creato).
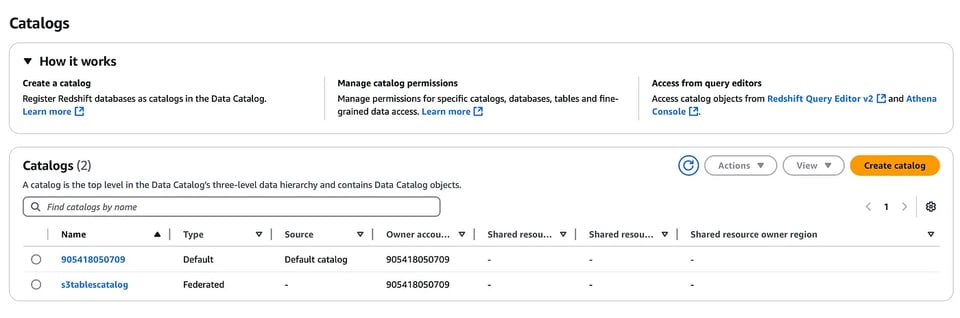
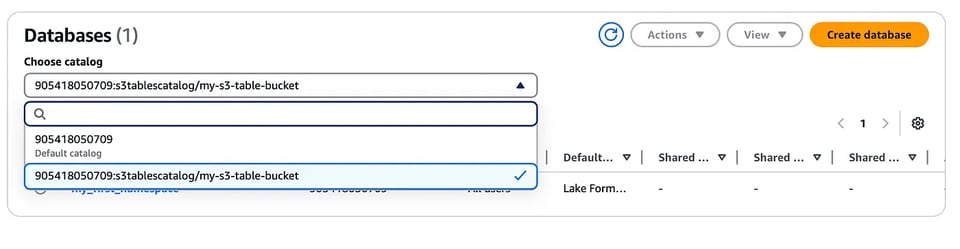
Ed eccoci alla parte più interessante: integrare queste S3 tables con i servizi AWS. Si parte da Amazon EMR e dal provisioning di un cluster EMR abilitato a Iceberg con Apache Spark. Acceda quindi al nodo primario del cluster tramite SSH.
Avvii la spark-shell.
spark-shell \--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions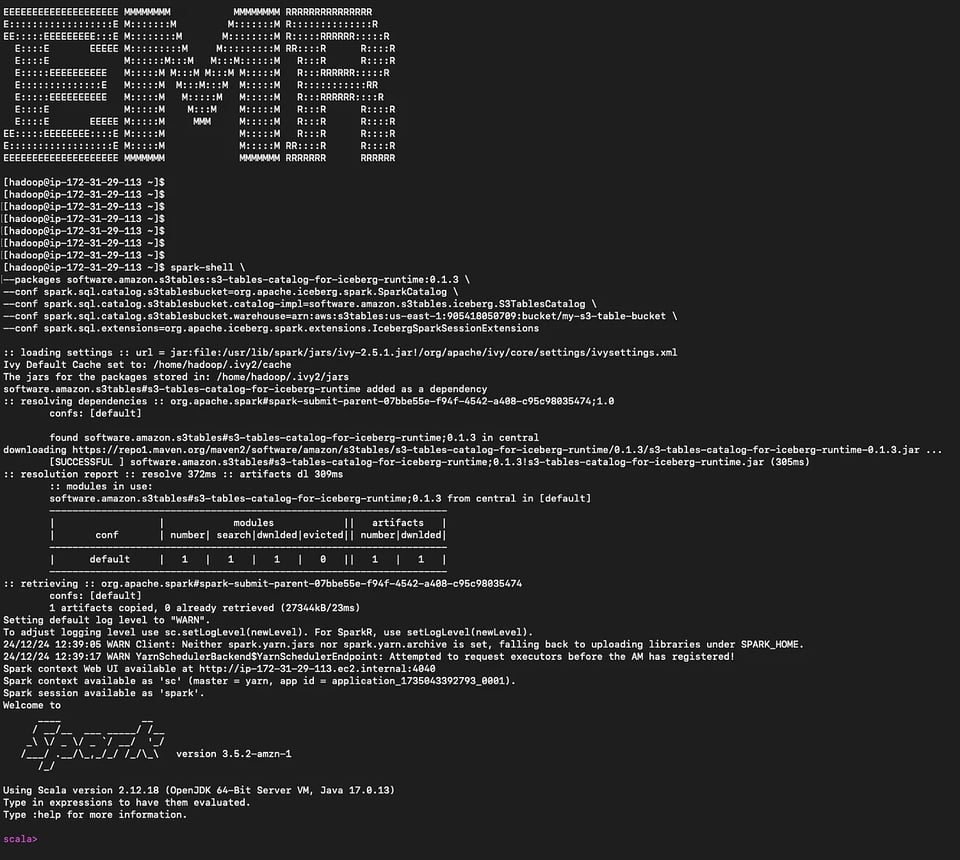 Spark-shell sul nodo primario EMR
Spark-shell sul nodo primario EMR
Verifichi di aver seguito correttamente i prerequisiti previsti per l'integrazione. Per Amazon EMR è necessario collegare la policy AmazonS3TablesFullAccess al ruolo EMR_EC2_DefaultRole e assegnare allo stesso EMR_EC2_DefaultRole i permessi LakeFormation adeguati a livello di catalogo, namespace e tabella.
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` ( id INT, name STRING, value INT)USING iceberg """)
spark.sql(""" INSERT INTO s3tablesbucket.my_first_namespace.example_table VALUES (1, 'ABC', 100), (2, 'XYZ', 200)""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show() Creazione di un nuovo namespace per il table bucket
Creazione di un nuovo namespace per il table bucket
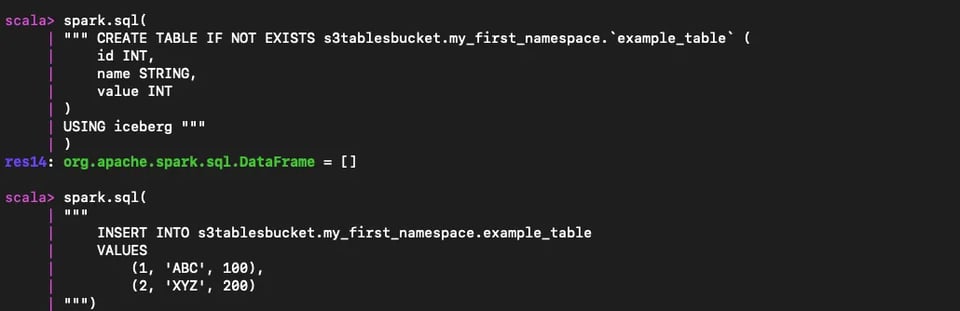 Creazione di una nuova tabella basata sul table bucket all'interno del namespace
Creazione di una nuova tabella basata sul table bucket all'interno del namespace
 Query sulla tabella
Query sulla tabella
Se dispone di dati di esempio in formato parquet su S3, può leggerli, creare una S3 table corrispondente ed eseguirvi query.
#Read the parequet fileval data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Create a new tabledata_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Query the table we createdspark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()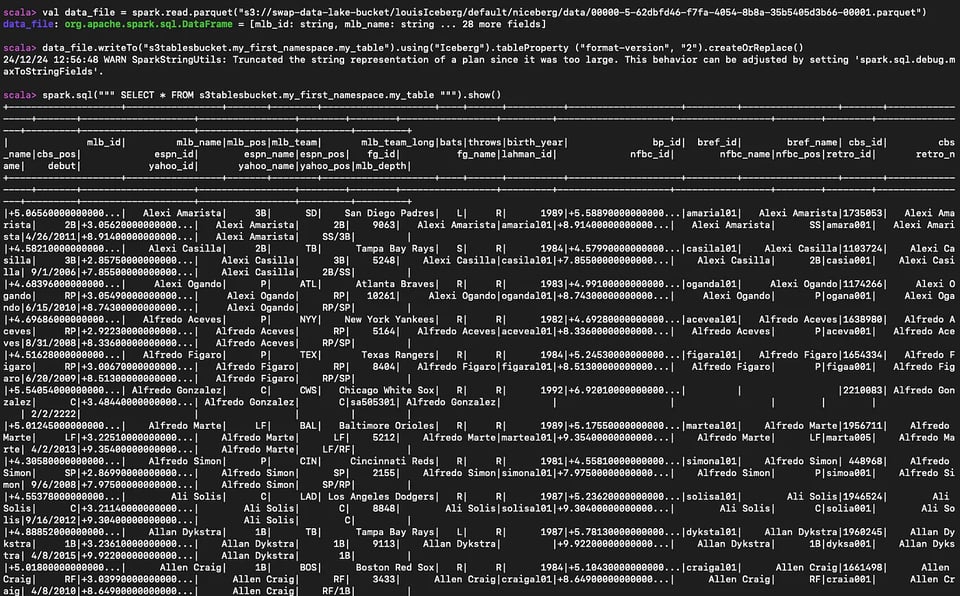
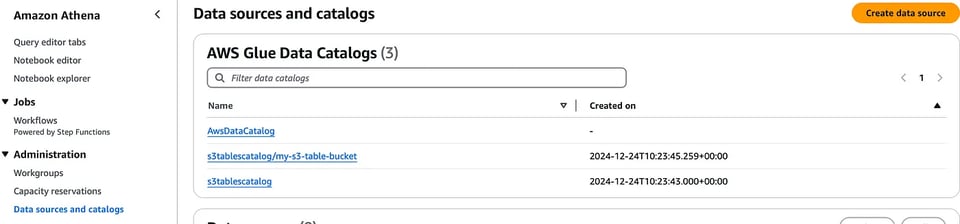
Passiamo ora all'integrazione con Amazon Athena. Avendo creato un catalogo per le S3 tables, lo troverà nella sezione Data sources and catalogs della console Athena; dal menu a discesa nell'editor potrà visualizzare le s3 tables.
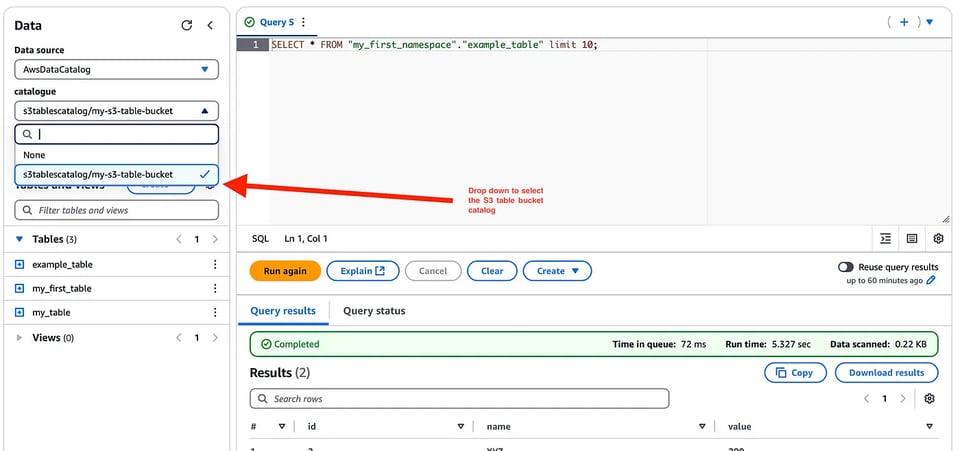
A questo punto può eseguire query su queste tabelle proprio come avviene con le tabelle native del catalogo Glue in Athena.
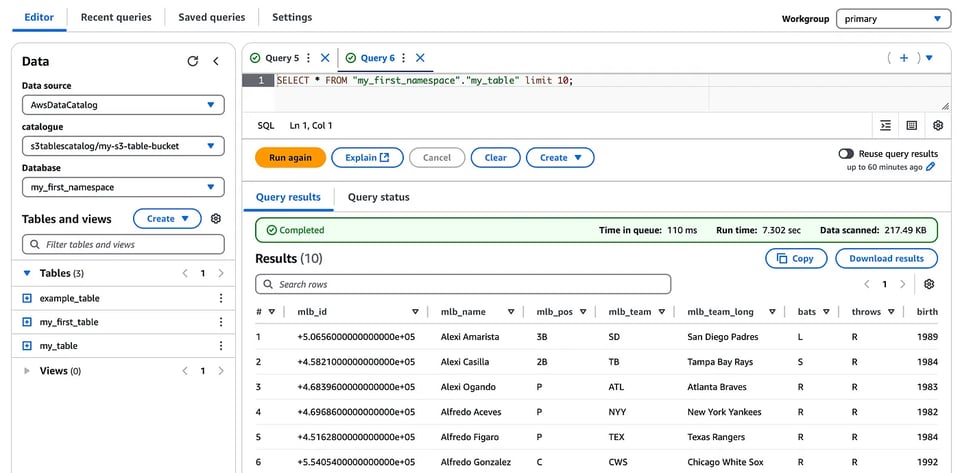
Tenga presente che, essendo le s3 tables gestite direttamente da S3, non si ha accesso alla location S3 sottostante né è possibile interrogare i manifest file, a differenza di quanto accade quando si interrogano i metadati delle tabelle Iceberg per le tabelle basate su Amazon Athena.
Amazon S3 tables permette di creare tabelle logiche sopra i dati presenti su S3 — archiviati in formato parquet per ottimizzare le prestazioni in lettura — basate sul formato Iceberg, che oltre a supportare le transazioni ACID consente di eseguire update, delete e insert, nonché query di tipo time-travel sui dati. Il tutto è gestito da Amazon S3, con in più i vantaggi di durabilità, scalabilità e prestazioni tipici di S3.
Se desidera saperne di più o è interessato ai nostri servizi, non esiti a contattarci. Ci scriva qui.