AWS re:Invent 2024で、分析workloads向けに最適化されたフルマネージドのApache Icebergテーブルを提供するAmazon S3 Tablesが発表されました。Iceberg形式のマネージドストレージをs3tables APIで管理でき、データ操作はApache SparkやAWSの分析サービス(Amazon EMR、Amazon Athena、Amazon Redshift、Amazon EMR、Amazon QuickSight、Amazon Data Firehose)と連携できます。

はじめに、コンソールまたはAWS CLIでテーブルバケットを作成します。作成時に、上記のAWS分析サービスとの統合を有効化するオプションを選べます。
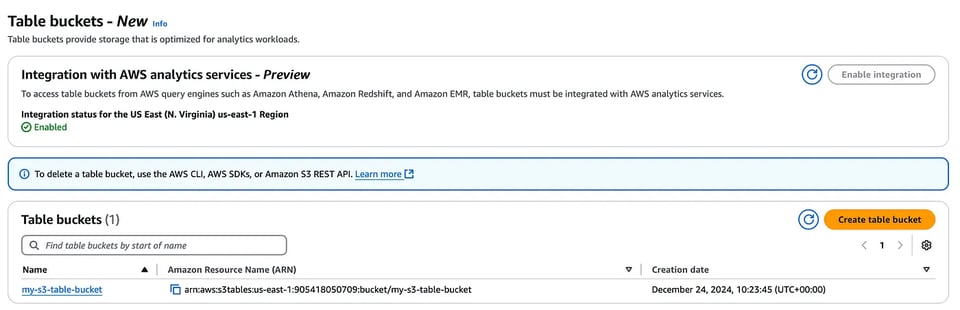
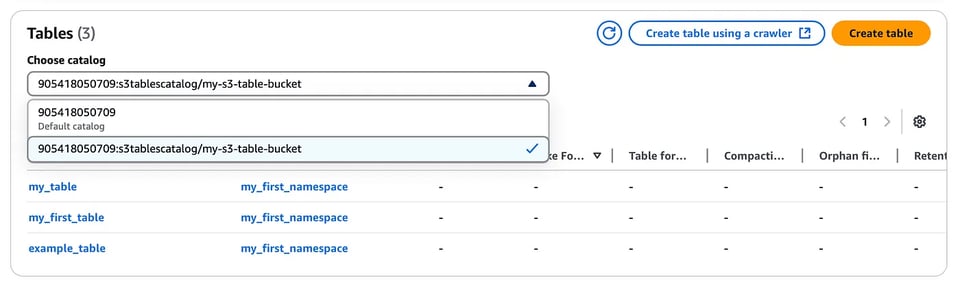
S3 Table bucketコンソール
テーブルバケットを作成したら、続いてネームスペース(複数のテーブルをまとめる論理的なデータベースのようなもの)を作成し、その中にテーブルを配置します。
aws s3tables create-namespace \ --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace
aws s3tables create-table \ --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace \ --name my_first_table --format ICEBERG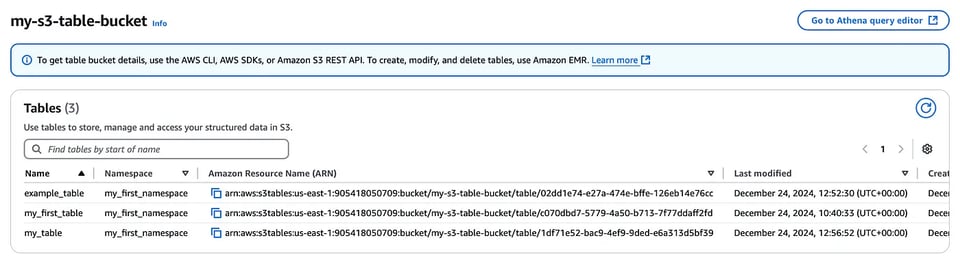 テーブルバケットコンソールで作成されたテーブル
テーブルバケットコンソールで作成されたテーブル
テーブル形式はApache Icebergフレームワークに準拠し、基盤となるストレージにはテーブルデータとメタデータの両方が格納されます。S3 Tablesではテーブルメンテナンスを意識する必要はなく、Amazon S3がメンテナンス機能を提供し、S3 Tablesやテーブルバケットのパフォーマンスを最適化します。メンテナンス項目はファイルコンパクション、スナップショット管理、未参照ファイルの削除の3種類で、いずれもデフォルトで有効です。メンテナンス設定ファイルから編集や無効化が可能なほか、メンテナンスジョブのパラメータを設定して運用に合わせて調整することもできます。ジョブのステータスはs3tables APIで確認可能です。
aws s3tables get-table-maintenance-job-status \ --table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \ --namespace="mynamespace" \ --name="testtable"S3 Tablesを分析サービスと統合する前に、前提条件のステップを完了させておきましょう。
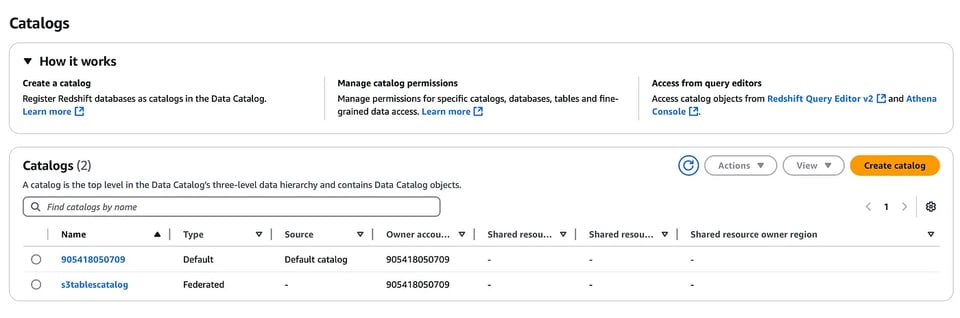
S3 Tables用の新しいカタログを作成します。
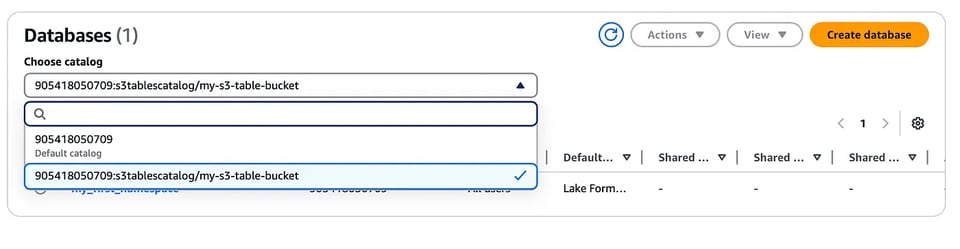
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'このカタログはAWS LakeFormationに登録されます。先ほど作成したネームスペースとテーブルもLakeFormationコンソールから確認できます(ドロップダウンで作成済みのS3テーブルカタログを選択してください)。
ここからが本題です。S3 TablesをAWSサービスと連携していきましょう。まずはAmazon EMRで、Apache Sparkを有効にしたIceberg対応のEMRクラスターをプロビジョニングします。続いてSSHでクラスターのプライマリノードにログインします。
spark-shellを起動します。
spark-shell \--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions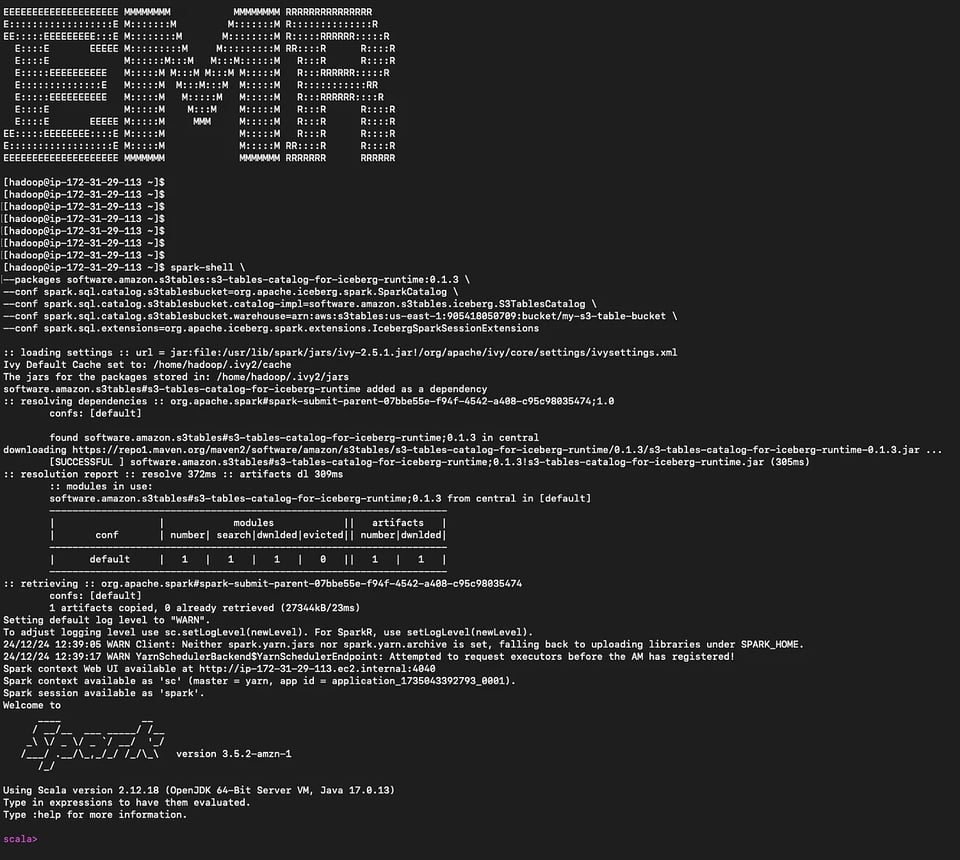 EMRプライマリノードでのSpark-shell
EMRプライマリノードでのSpark-shell
統合の前提条件を満たしているかを必ず確認してください。Amazon EMRの場合、``AmazonS3TablesFullAccessポリシーをEMR_EC2_DefaultRoleにアタッチし、さらにEMR_EC2_DefaultRoleへカタログ・ネームスペース・テーブルレベルのLakeFormation権限を適切に付与する必要があります。
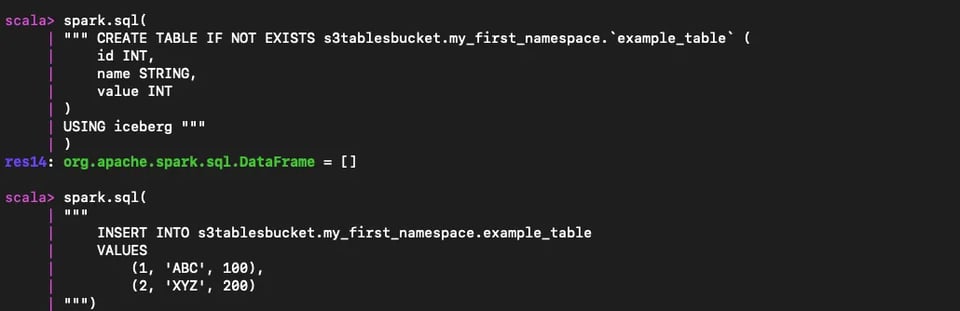
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` ( id INT, name STRING, value INT)USING iceberg """)
spark.sql(""" INSERT INTO s3tablesbucket.my_first_namespace.example_table VALUES (1, 'ABC', 100), (2, 'XYZ', 200)""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show() テーブルバケット用に新しいネームスペースを作成
テーブルバケット用に新しいネームスペースを作成
 ネームスペース内にテーブルバケットベースのテーブルを作成
ネームスペース内にテーブルバケットベースのテーブルを作成
 テーブルへのクエリ
テーブルへのクエリ
S3にサンプルのparquetデータがあれば、それを読み込んでS3テーブルを作成し、クエリを実行することもできます。
#Read the parequet fileval data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Create a new tabledata_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Query the table we createdspark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()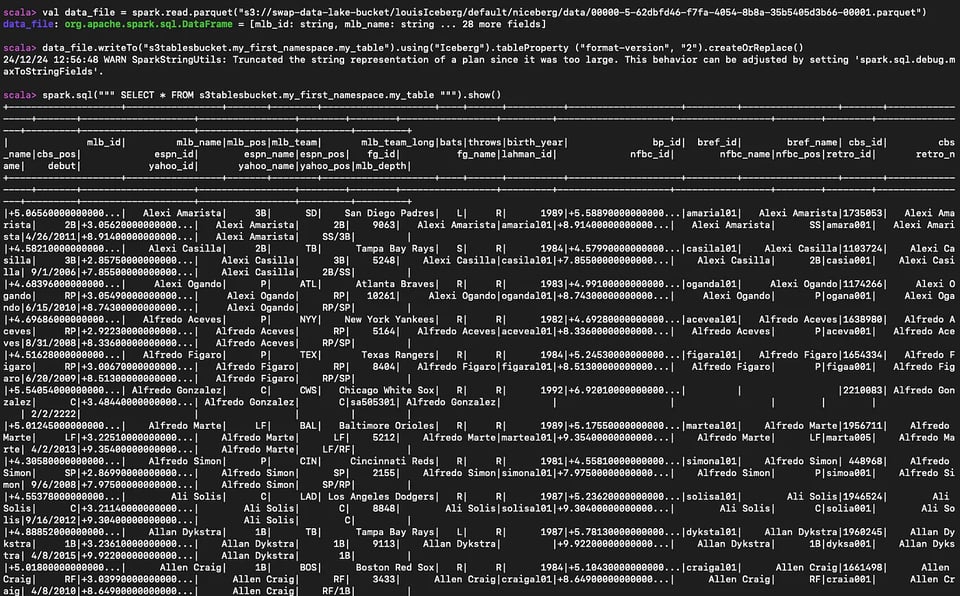
では、このテーブルをAmazon Athenaと連携してみましょう。S3 Tables用のカタログを作成済みのため、Athenaコンソールの「データソースとカタログ」に表示され、エディター内のドロップダウンからS3テーブルを選択できます。
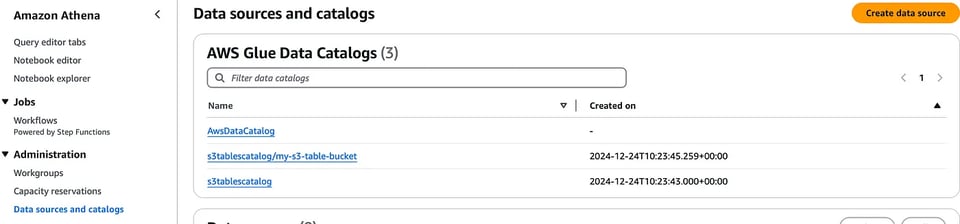
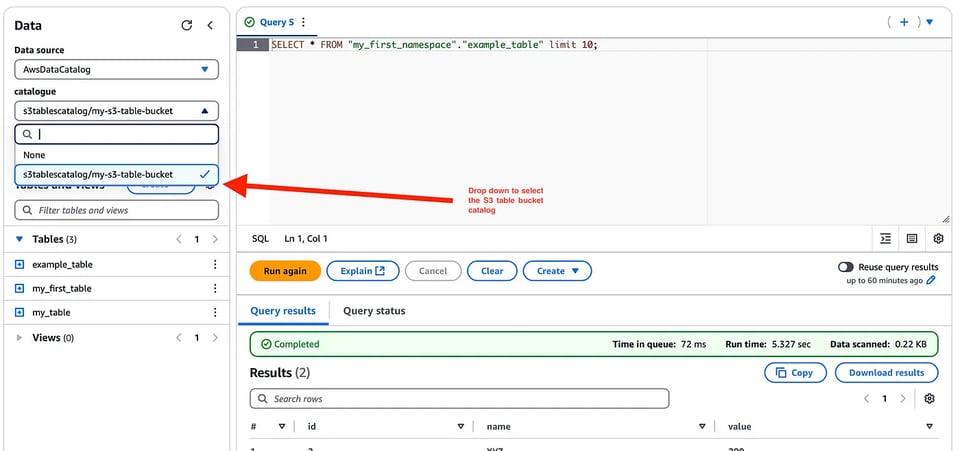
あとはAthenaのネイティブなGlueカタログテーブルと同じ感覚で、これらのテーブルにクエリを実行できます。
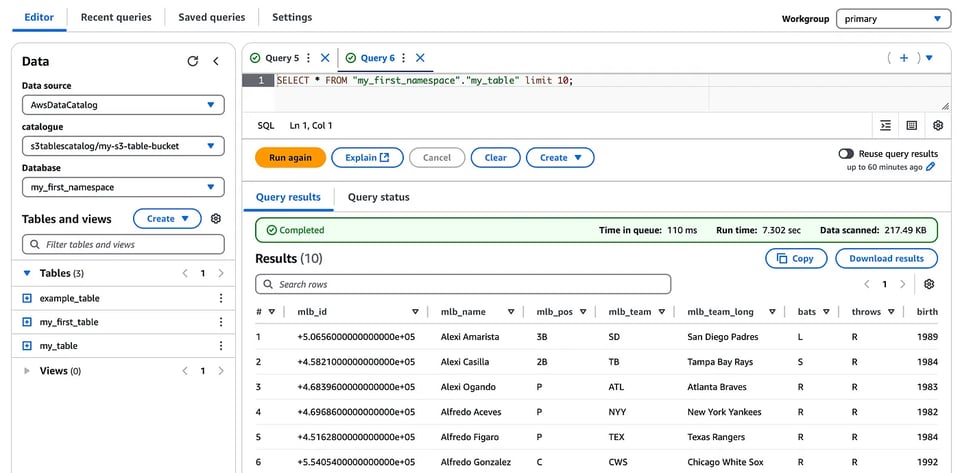
なお、S3 TablesはS3側で管理されるため、基盤となるS3データの場所には直接アクセスできず、Amazon Athenaベースのテーブルに対するIcebergテーブルメタデータのクエリのようにマニフェストファイルを照会することはできない点にご注意ください。
Amazon S3 Tablesを使うと、読み取りパフォーマンスを最適化するためにparquet形式で保存されたS3上のデータに対して、論理テーブルを作成できます。これらのテーブルはIceberg形式に基づいており、ACIDトランザクションに加えて、更新・削除・挿入や、データに対するタイムトラベルクエリにも対応します。これらをすべてAmazon S3が管理してくれるため、S3ならではの耐久性・スケーラビリティ・パフォーマンスもそのまま享受できます。
さらに詳しく知りたい方や、当社のサービスにご関心をお持ちの方は、お気軽にお問い合わせください。お問い合わせはこちらから。