No AWS re:Invent 2024, foi feito o anúncio do Amazon S3 Tables, que entrega tabelas Apache Iceberg totalmente gerenciadas e otimizadas para workloads de analytics. Essas tabelas contam com armazenamento gerenciado no formato Iceberg e são administradas pela API s3tables. Para as operações de dados, dá para integrá-las ao Apache Spark ou aos serviços de análise da AWS — Amazon EMR, Amazon Athena, Amazon Redshift, Amazon EMR, Amazon QuickSight e Amazon Data Firehose.

O primeiro passo é criar um table bucket, seja pelo console ou pela AWS CLI. Aí você já pode habilitar a integração desse table bucket com os serviços de analytics da AWS citados acima.
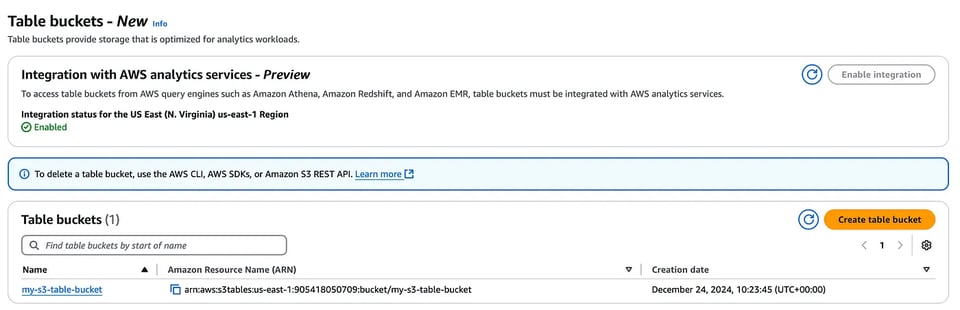
Console do S3 Table bucket
Com o table bucket criado, é hora de criar um namespace (pense nele como um banco de dados lógico que vai abrigar várias tabelas), onde ficarão as nossas tabelas.
aws s3tables create-namespace \ --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace
aws s3tables create-table \ --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace \ --name my_first_table --format ICEBERG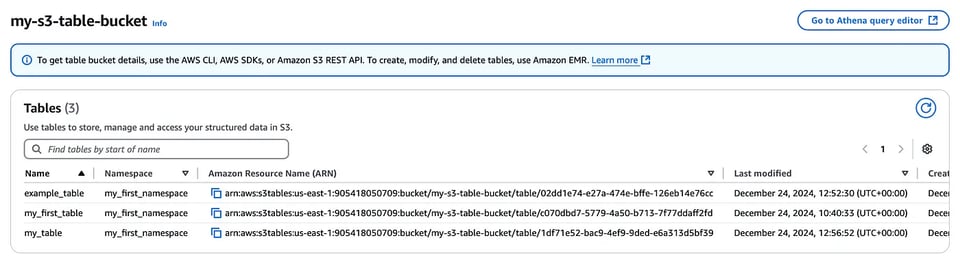 Tabelas criadas no console do table bucket
Tabelas criadas no console do table bucket
O formato das tabelas é baseado no framework Apache Iceberg, e o armazenamento subjacente guarda tanto os dados das tabelas quanto seus metadados. Com o S3 Tables, você não precisa se preocupar com a manutenção: o Amazon S3 cuida disso para melhorar o desempenho das suas S3 tables ou table buckets. As opções de manutenção incluem compactação de arquivos, gerenciamento de snapshots e remoção de arquivos não referenciados — tudo já vem ativado por padrão. Você pode editar ou desativar essas operações pelos arquivos de configuração de manutenção. E, se quiser, dá para configurar os parâmetros do job de manutenção com os valores que fazem mais sentido para o seu caso. O status do job pode ser consultado pela API s3tables.
aws s3tables get-table-maintenance-job-status \ --table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \ --namespace="mynamespace" \ --name="testtable"Antes de integrar as S3 tables aos serviços analíticos, é preciso concluir os pré-requisitos.
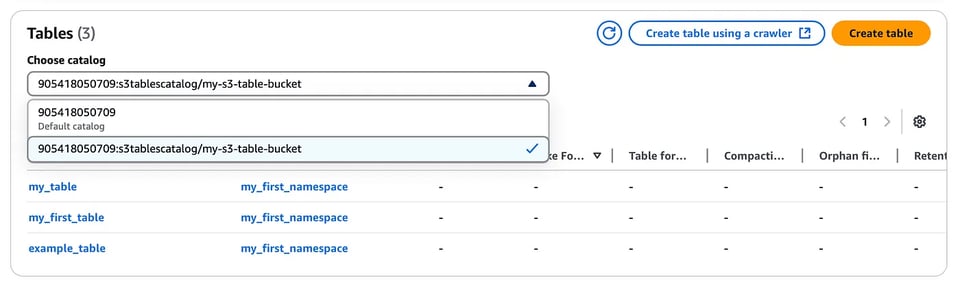
Crie um novo catálogo para as S3 tables
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog":{ "Identifier":"arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName":"aws:s3tables"} }'Esse catálogo é registrado no AWS LakeFormation e, da mesma forma, você consegue ver no console do LakeFormation o namespace e a tabela que criamos antes (basta usar o menu suspenso para selecionar o catálogo de S3 tables que criamos acima).
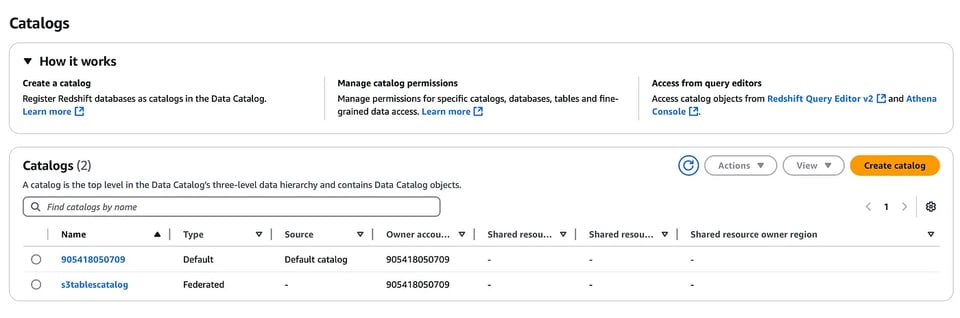
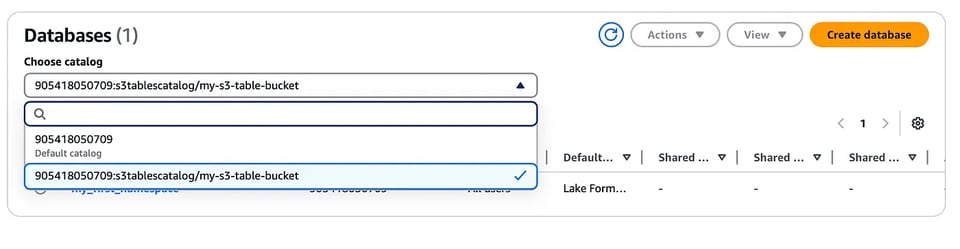
Agora vem a parte divertida! É aqui que integramos essas S3 tables aos serviços da AWS. Vou começar pelo Amazon EMR e provisionar um cluster EMR habilitado para Iceberg com Apache Spark. Depois, faça login no nó primário do cluster via SSH.
Inicie o spark-shell
spark-shell \--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions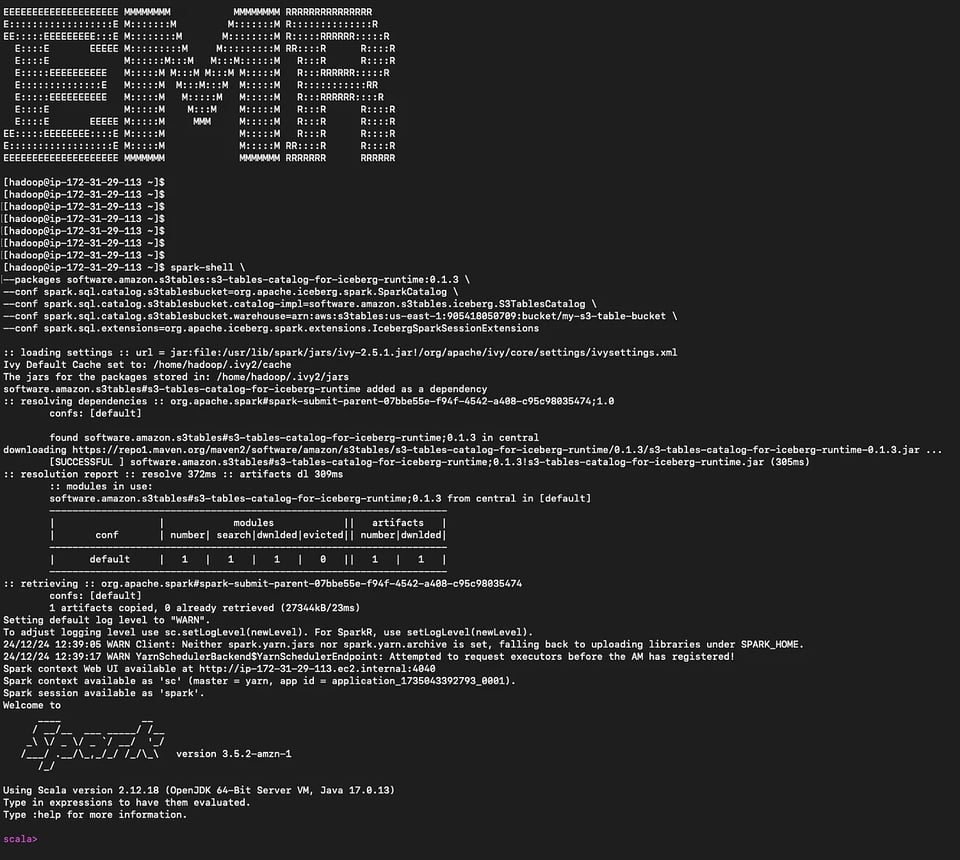 Spark-shell no nó primário do EMR
Spark-shell no nó primário do EMR
Confira se você seguiu direitinho os pré-requisitos da integração. No caso do Amazon EMR, é preciso anexar a política ``AmazonS3TablesFullAccess à EMR_EC2_DefaultRole e também conceder a essa role as permissões adequadas no LakeFormation, em nível de catálogo, namespace e tabela.
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
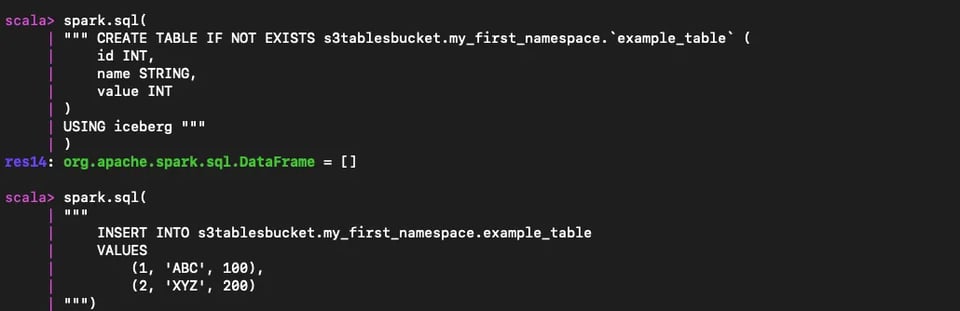
spark.sql(""" CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` ( id INT, name STRING, value INT)USING iceberg """)
spark.sql(""" INSERT INTO s3tablesbucket.my_first_namespace.example_table VALUES (1, 'ABC', 100), (2, 'XYZ', 200)""")
spark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show() Crie um novo namespace para o table bucket
Crie um novo namespace para o table bucket
 Crie uma nova tabela baseada em table bucket dentro do namespace
Crie uma nova tabela baseada em table bucket dentro do namespace
 Consulte a tabela
Consulte a tabela
Se você tiver dados de exemplo em parquet no S3, dá para lê-los, criar uma S3 table com base neles e consultá-la
#Read the parequet fileval data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#Create a new tabledata_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#Query the table we createdspark.sql(""" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()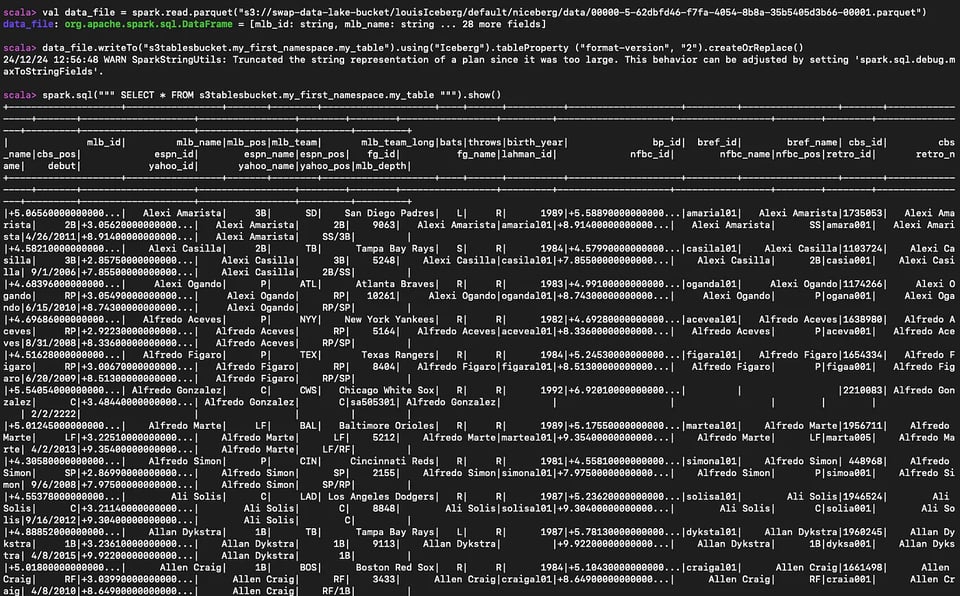
Agora vamos integrar essa tabela ao Amazon Athena! Como já criamos um catálogo para as S3 tables, ele aparece em "Data sources and catalogs" no console do Athena, e você pode usar o menu suspenso no editor para visualizar as s3 tables.
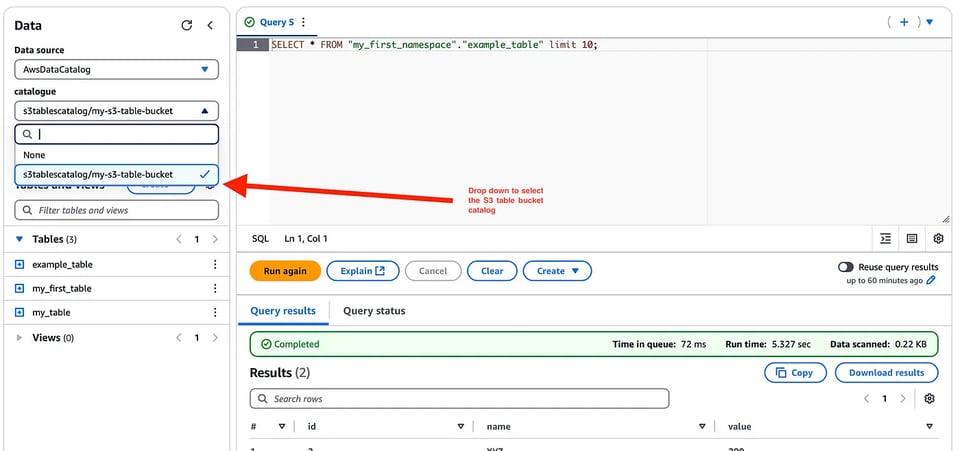
Pronto: agora dá para consultar essas tabelas no Athena exatamente como você faria com as tabelas nativas do catálogo Glue.
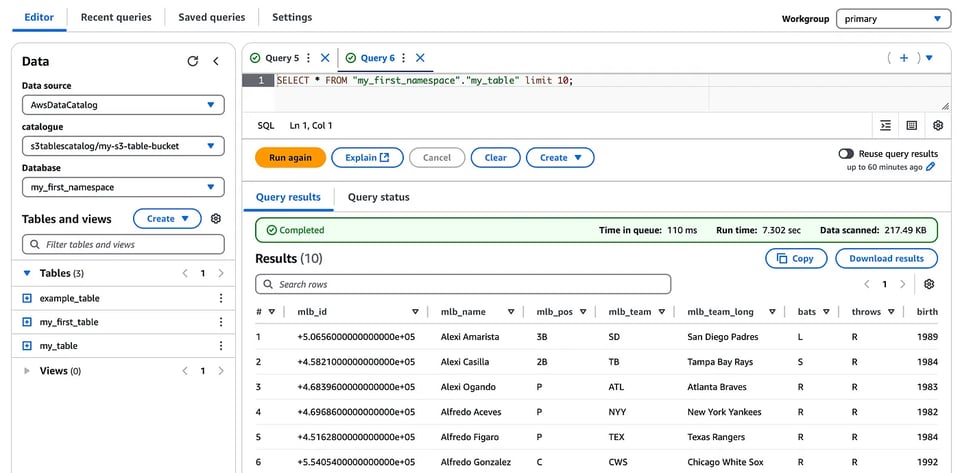
Vale lembrar que, como as s3 tables são gerenciadas pelo S3, você não tem acesso ao local físico dos dados no S3 e não consegue consultar os arquivos de manifesto, diferente do que acontece ao consultar metadados de tabelas Iceberg em tabelas baseadas no Amazon Athena.
O Amazon S3 Tables permite criar tabelas lógicas em cima dos seus dados no S3, armazenados em formato parquet para um desempenho de leitura otimizado. Como essas tabelas usam o formato Iceberg, elas não só suportam transações ACID como também permitem updates, deletes, inserts e consultas time-travel sobre os seus dados. E tudo isso é gerenciado pelo Amazon S3, com os benefícios extras de durabilidade, escalabilidade e desempenho do S3.
Se você quiser saber mais ou tiver interesse nos nossos serviços, fale com a gente sem hesitar. Entre em contato aqui.