
Cet article fait suite à la première partie, dans laquelle nous avons vu comment intégrer en toute sécurité une flotte d'appareils IoT à grande échelle qui transmettent leurs données de télémétrie vers Google Cloud via IoT Core et Pub/Sub.
Bravo ! Vous avez enregistré plusieurs appareils IoT — et maintenant ?
L'étape suivante consiste à concevoir un système capable d'assurer le stockage à grande échelle, l'analyse et la visualisation de vos données via des dashboards.
Cela suppose d'anticiper la conception d'une architecture de flux de données capable de supporter de telles opérations. Cet article vous propose une démarche concrète, étape par étape.
Vue d'ensemble
Cet article s'articule autour des sections suivantes :
- Chargement par lots vers les data sinks
- Stockage et analyse des données
- Visualisation des données entreposées
Contrairement à la première partie, tout ce qui suit peut être réalisé entièrement depuis la console web GCP. Seules des notions de base en SQL sont requises.
Nous aborderons les services Google Cloud entièrement managés et auto-scalables suivants :
- Pub/Sub — une file de messages serverless
- Dataflow — un moteur de traitement de données en flux et par lots
- BigQuery — un entrepôt de données serverless
- Data Studio — un service de visualisation de données et de création de dashboards
Chargement par lots vers les data sinks
Vérifier que les messages arrivent bien
Si vos appareils ont été correctement intégrés au registre IoT et que le streaming des données vers IoT Core est lancé, un flux régulier de messages devrait apparaître dans le dashboard principal GCP IoT :
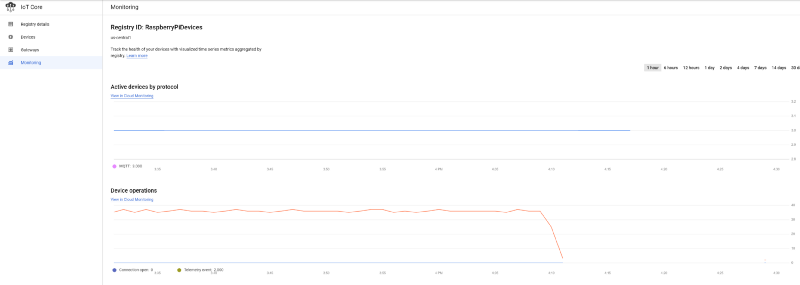 Trois appareils connectés diffusant des données de température toutes les cinq secondes
Trois appareils connectés diffusant des données de température toutes les cinq secondes
Comme indiqué dans la première partie, ces messages arrivent également dans votre topic Pub/Sub temperature :
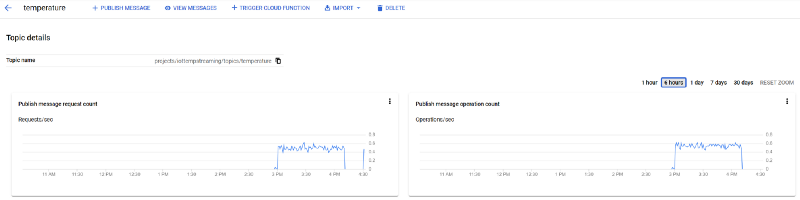 Messages Pub/Sub arrivant dans le topic temperature
Messages Pub/Sub arrivant dans le topic temperature
Streaming vers BigQuery
Parfait — les messages arrivent bien dans Google Cloud. Reste à les acheminer vers un entrepôt de données où ils pourront être conservés à long terme à moindre coût et analysés à grande échelle. C'est là qu'intervient BigQuery.
BigQuery, l'entrepôt de données entièrement managé, serverless et auto-scalable de Google Cloud, facture le compute et le stockage à la demande, ce qui en fait un excellent data sink pour stocker et analyser nos données IoT.
Mais comment streamer les messages Pub/Sub vers BigQuery ? Avec Dataflow.
Dataflow, la version entièrement managée et auto-scalable d'Apache Beam proposée par Google Cloud, est conçu pour acheminer les données d'un service à un autre. Vous pouvez au passage filtrer et transformer ces données, et optimiser le chargement par lots vers des services dont les opérations de chargement sont contraintes, comme les bases de données ou les solutions d'entreposage.
Dataflow propose plusieurs templates par défaut créés par Google Cloud, dont un template Pub/Sub vers BigQuery — aucune ligne de code n'est donc nécessaire pour relier l'ingestion aux services de stockage et d'analyse.
Pub/Sub, Dataflow et BigQuery étant tous entièrement managés et auto-scalables, et serverless (à l'exception de Dataflow), il devient possible de bâtir un système de gestion de données IoT de bout en bout qui passe sans heurt du test en développement aux opérations à l'échelle du pétaoctet — sans pratiquement aucune gestion d'infrastructure à mesure que la charge croît.
Voyons maintenant tous ces services à l'œuvre !
Configuration de la souscription Pub/Sub
Avant de transférer les données de Pub/Sub vers Dataflow, créons une souscription Pub/Sub abonnée au topic Pub/Sub.
Pourquoi ? Les messages qui arrivent dans un topic Pub/Sub sont envoyés immédiatement aux abonnés (via une stratégie Push), puis supprimés du topic. À l'inverse, les souscriptions peuvent conserver les messages jusqu'à ce qu'un processus les demande (via une stratégie Pull). On peut connecter Dataflow directement à un topic plutôt qu'à une souscription, mais si le job Dataflow venait à subir une indisponibilité, les messages arrivés dans le topic pendant ce laps de temps seraient perdus.
En reliant plutôt Dataflow à une souscription Pub/Sub abonnée au topic, vous évitez toute perte de messages en cas d'indisponibilité. Si un job Dataflow était temporairement interrompu, les messages IoT non encore traités resteraient dans la souscription Pub/Sub, en attente de la reprise du pull par Dataflow.
Une souscription Pub/Sub à un topic Pub/Sub permet ainsi de bâtir une architecture de données résiliente face aux interruptions des services d'ingestion en aval.
Pour créer une souscription dans Pub/Sub :
- Accédez à Subscriptions
- Cliquez sur Create Subscription et nommez votre souscription temperature_sub
- Abonnez-la au topic Pub/Sub temperature
- Laissez les autres options à leurs valeurs par défaut
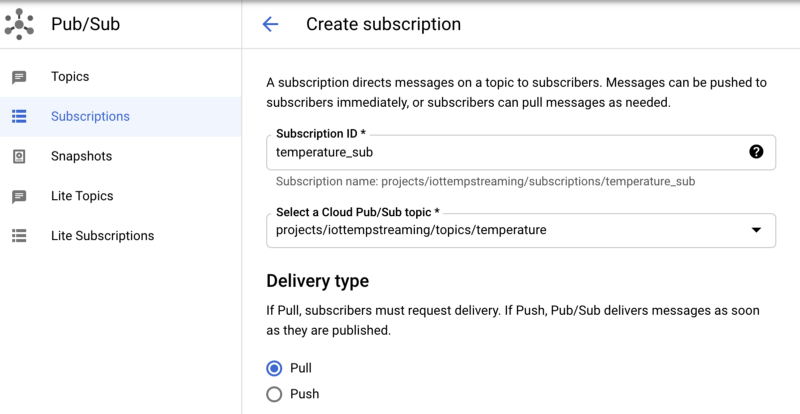 Création de la souscription Pub/Sub temperature_sub au topic Pub/Sub temperature
Création de la souscription Pub/Sub temperature_sub au topic Pub/Sub temperature
Une fois créée, cliquez sur la souscription puis sur Pull : les messages devraient commencer à apparaître :
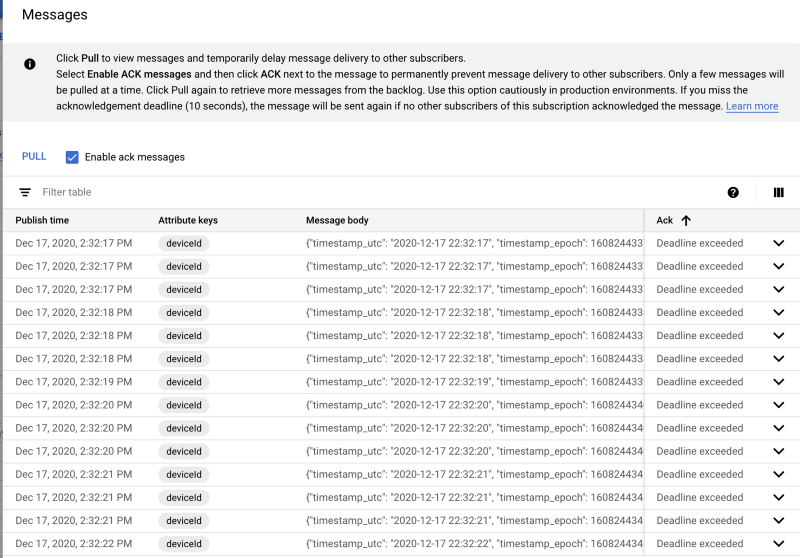 Exemples de messages arrivant dans la souscription Pub/Sub
Exemples de messages arrivant dans la souscription Pub/Sub
Stockage et analyse des données
Maintenant qu'une souscription Pub/Sub reçoit les messages, nous sommes presque prêts à créer un job Dataflow pour les transférer vers BigQuery. Avant cela, il faut créer dans BigQuery la table qui recevra les données envoyées par Dataflow.
Création de la table BigQuery
Accédez à BigQuery, cliquez sur Create Dataset et nommez votre dataset sensordata, en laissant les autres options à leurs valeurs par défaut :
 Fenêtre de création d'un dataset BigQuery
Fenêtre de création d'un dataset BigQuery
Une fois le dataset créé, sélectionnez-le, cliquez sur Create table et nommez votre nouvelle table temperature. Veillez à reprendre le schéma, le partitionnement et les options de clustering présentés dans les captures d'écran ci-dessous : ces choix sont adaptés aux patterns de requêtes courants.
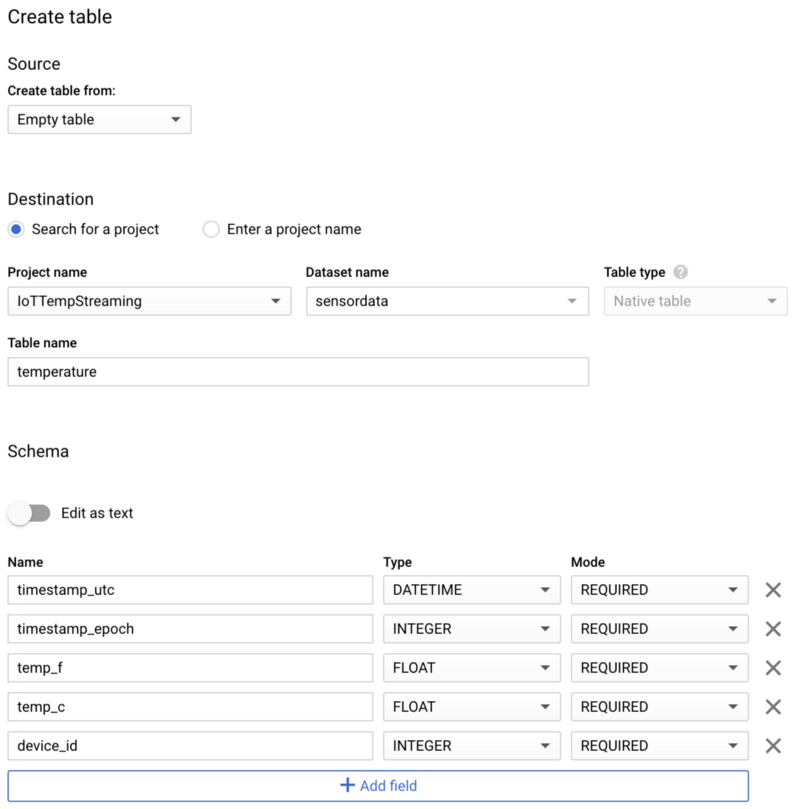 Schéma de la nouvelle table BigQuery temperature
Schéma de la nouvelle table BigQuery temperature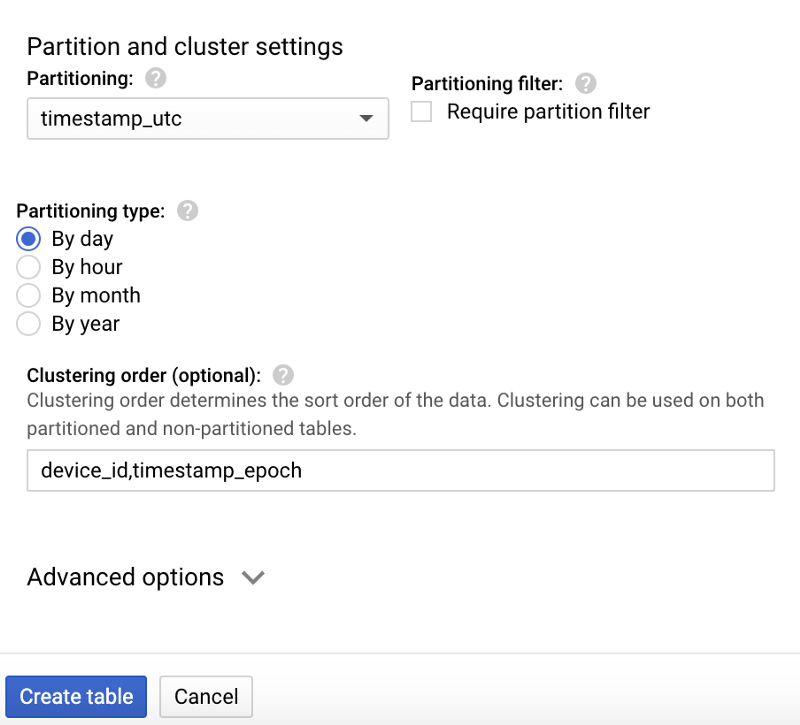 Options de partitionnement et de clustering pour la table temperature
Options de partitionnement et de clustering pour la table temperature
Si tout est correct, votre nouvelle table vide ressemblera à ceci :
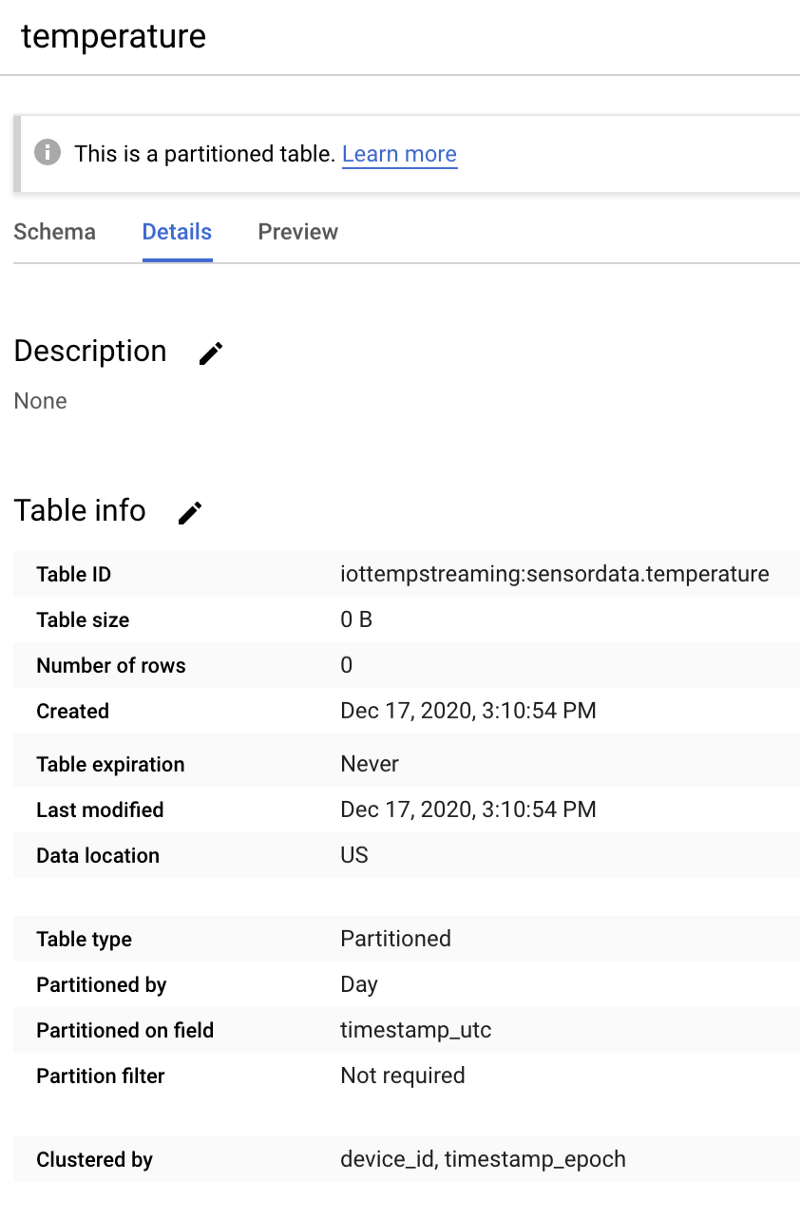 Une table BigQuery temperature vide dans le dataset sensordata
Une table BigQuery temperature vide dans le dataset sensordata
Une fois les données chargées, nous illustrerons un pattern de requête IoT classique : analyser des données sur une fenêtre temporelle précise (par exemple une plage d'une heure pour la journée en cours) et pour un appareil donné.
Le design de table ci-dessus est idéal pour ce type de requêtes, et ce pour deux raisons :
- Le partitionnement sur le champ de timestamp UTC permet aux requêtes ciblant une date précise d'éviter le scan des partitions DateTime non concernées.
- Au sein d'une partition, le clustering (tri) sur deviceId et le timestamp epoch permet une récupération plus efficace des données pour un appareil et une plage horaire donnés.
Pour écrire ces requêtes, il nous faut des données dans la table. Lançons le job Dataflow !
Configuration de Dataflow
À ce stade, nous avons des messages dans une souscription Pub/Sub en attente d'être déplacés, et une table BigQuery prête à les recevoir. Il nous manque la " colle " ETL qui relie les deux. Pub/Sub et BigQuery étant tous deux entièrement managés, auto-scalables et serverless, l'idéal est de choisir un outil ETL qui partage ces qualités.
Dataflow correspond (en grande partie) à ces exigences. Le marketing autour de Dataflow le présente comme cumulant les trois caractéristiques, mais en pratique, il n'est pas totalement serverless. Vous devez préciser les types et tailles d'instances utilisés, le nombre minimum et maximum d'instances entre lesquelles l'auto-scaling peut osciller, ainsi que l'espace disque temporaire dont chaque instance aura besoin. Vous ne gérez jamais ces instances ni leur logique de montée en charge, mais vous devez fournir ces spécifications. À la différence de Pub/Sub et de BigQuery, qui s'auto-scalent sans aucune configuration d'infrastructure.
Bien qu'il ne soit pas totalement serverless, Dataflow convient parfaitement à notre besoin ETL Pub/Sub vers BigQuery. Il est aussi simple à utiliser, d'autant que GCP propose de nombreux templates de jobs Dataflow par défaut, dont un dédié au workflow Pub/Sub vers BigQuery. Hormis l'augmentation du nombre maximum d'instances en auto-scaling à mesure que votre débit IoT croît, vous n'aurez en théorie jamais à vous soucier de l'infrastructure qui fait tourner Dataflow.
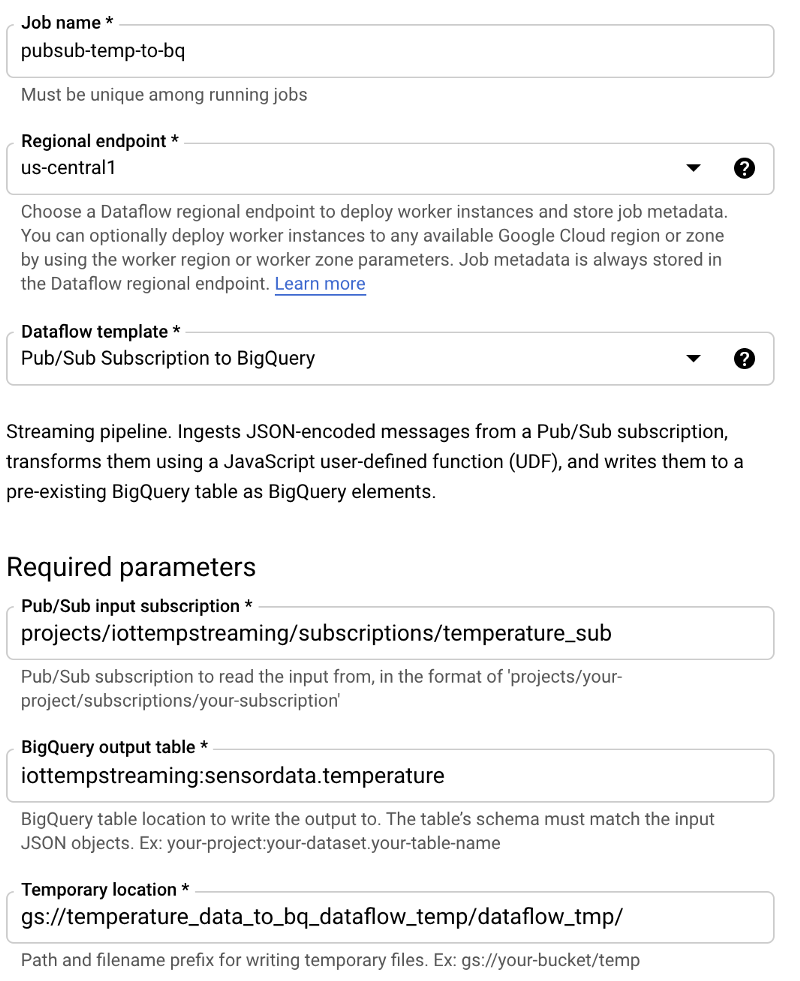
Maintenant que les bases sont posées, mettons en place un job Dataflow. Accédez à Dataflow, cliquez sur Create Job from Template et suivez ces étapes :
- Nommez le job pubsub-temp-to-bq
- Utilisez le template streaming par défaut Pub/Sub Subscription to BigQuery
- Saisissez le nom complet de la souscription Pub/Sub
- Saisissez l'ID complet de la table BigQuery
- Indiquez l'emplacement d'un bucket Cloud Storage où les données temporaires pourront être stockées dans le cadre du chargement par lots de Dataflow vers BigQuery
- Laissez les autres options à leurs valeurs par défaut. En production, vous déploieriez les Advanced Options pour préciser des paramètres tels que le type et la taille de machine, les valeurs min/max de l'auto-scaling ou la taille de disque par machine. Pour des tests, les valeurs par défaut suffisent.
Votre écran de création de job Dataflow devrait ressembler à ceci :
Après avoir cliqué sur Create et patienté quelques minutes, le temps que l'infrastructure sous-jacente démarre, vous verrez les données circuler de la souscription Pub/Sub vers la table BigQuery cible.
Le script Python de streaming de température fourni dans la première partie émet à raison d'un enregistrement par seconde. Dans le DAG (Directed Acyclic Graph) Dataflow ci-dessous, vous devriez donc voir x éléments diffusés par seconde, où x correspond au nombre d'appareils testés. Dans mon cas, trois appareils diffusent :
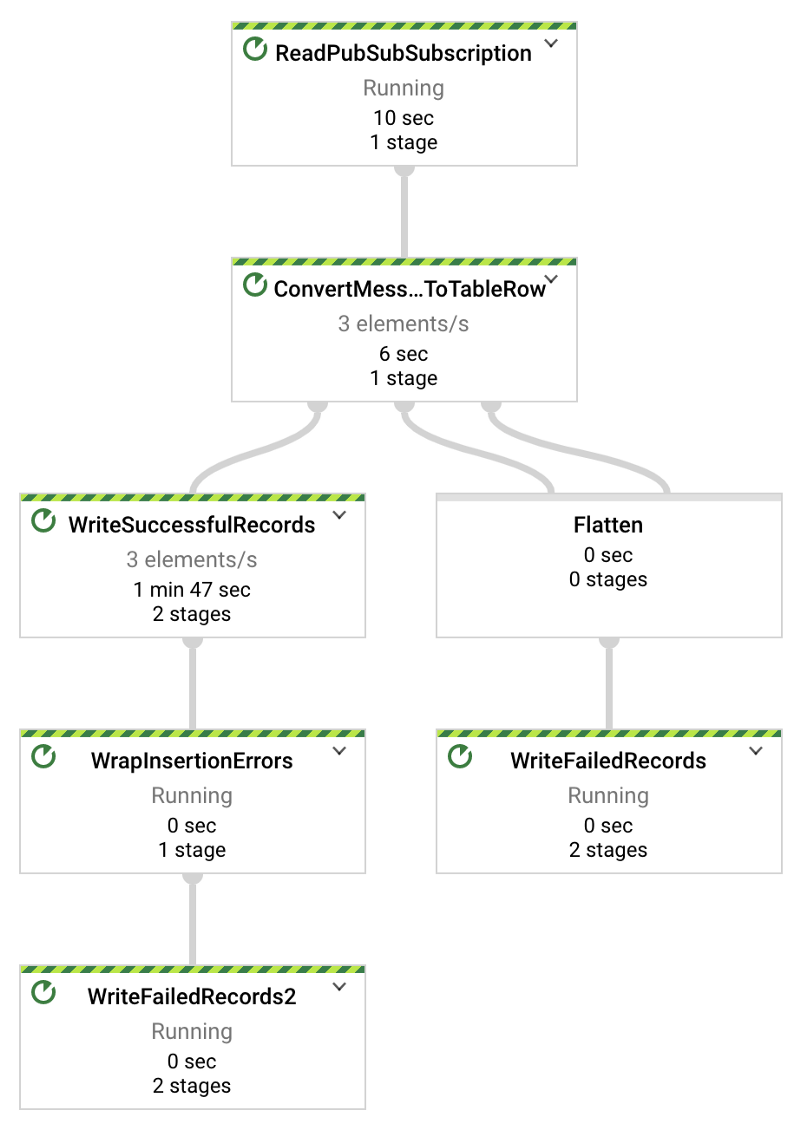 Messages diffusés avec succès de Pub/Sub vers BigQuery via un job Dataflow
Messages diffusés avec succès de Pub/Sub vers BigQuery via un job Dataflow
Dès que le job Dataflow est actif et qu'il diffuse correctement les données de la souscription Pub/Sub vers BigQuery, vous pouvez exécuter une requête au format suivant pour observer les données arriver en temps réel :
SELECT *FROM `iottempstreaming.sensordata.temperature`WHERE DATE(timestamp_utc) = "2020-12-18"ORDER BY timestamp_epoch DESCLIMIT 10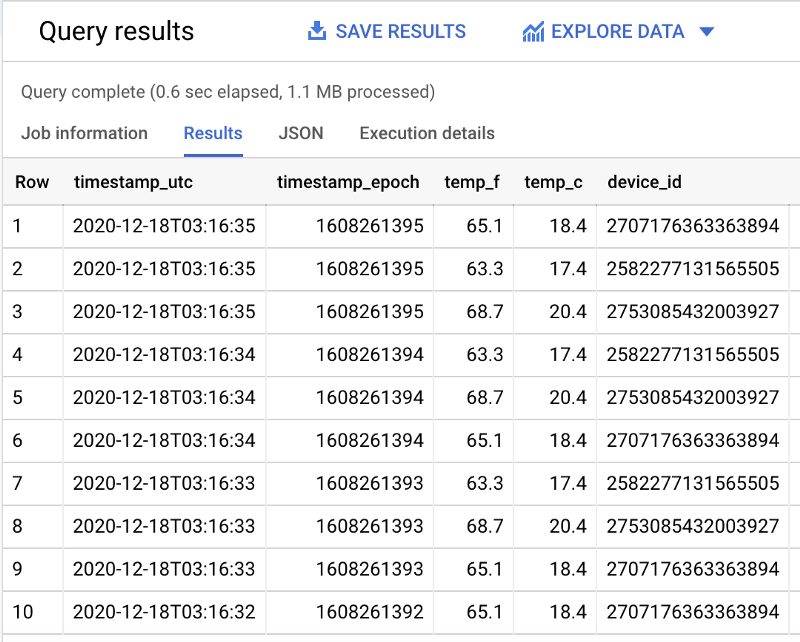
On constate que le filtrage par partition est bien actif : davantage de données sont scannées lorsque la clause WHERE de filtrage par jour est supprimée.
Avec mon dataset d'exemple, 1,1 Mo de données filtrées sont scannés (comme vu ci-dessus) contre 1,7 Mo sans filtre (ci-dessous) :
SELECT *FROM `iottempstreaming.sensordata.temperature`ORDER BY timestamp_epoch DESCLIMIT 10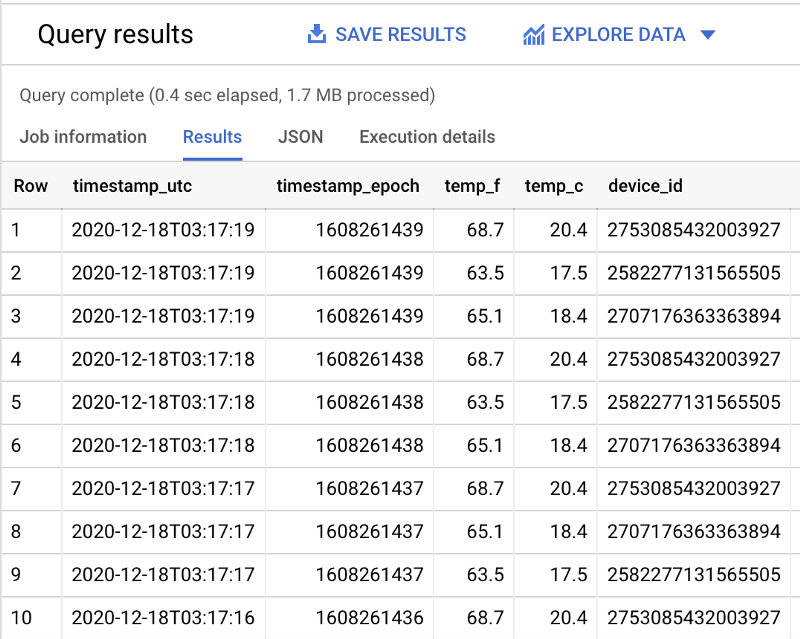
Examinons maintenant les températures moyennes, minimales et maximales relevées par chaque capteur sur la dernière heure :
SELECT device_id, ROUND(AVG(temp_f), 1) AS temp_f_avg, MIN(temp_f) AS temp_f_min, MAX(temp_f) AS temp_f_maxFROM `iottempstreaming.sensordata.temperature`WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)GROUP BY device_id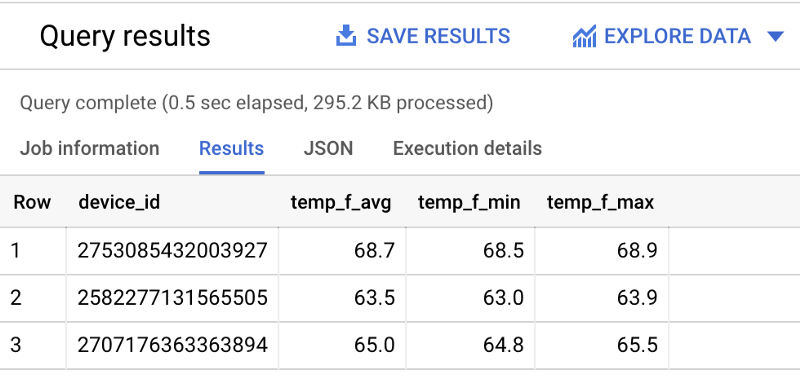 Diverses statistiques pour chaque appareil de streaming de température
Diverses statistiques pour chaque appareil de streaming de température
Bravo ! Vous venez de mettre en place un workflow de données entièrement managé de bout en bout, de l'ingestion à l'analytique. Avant de conclure, voyons rapidement avec quelle facilité ces données peuvent être visualisées dans Data Studio.
Visualisation des données entreposées
Commencez par exécuter dans BigQuery une requête semblable à celle-ci, qui récupère toutes les lignes pour une journée donnée :
SELECT *FROM `iottempstreaming.sensordata.temperature`WHERE DATE(timestamp_utc) = "2020-12-18"ORDER BY timestamp_epoch DESCÀ droite de Query Results, cliquez sur Explore Data, puis sur Explore with Data Studio :
Cela charge un tableau récapitulant les données interrogées. Par défaut, il affiche cependant un tableau peu parlant qui résume le nombre total d'enregistrements diffusés par seconde.
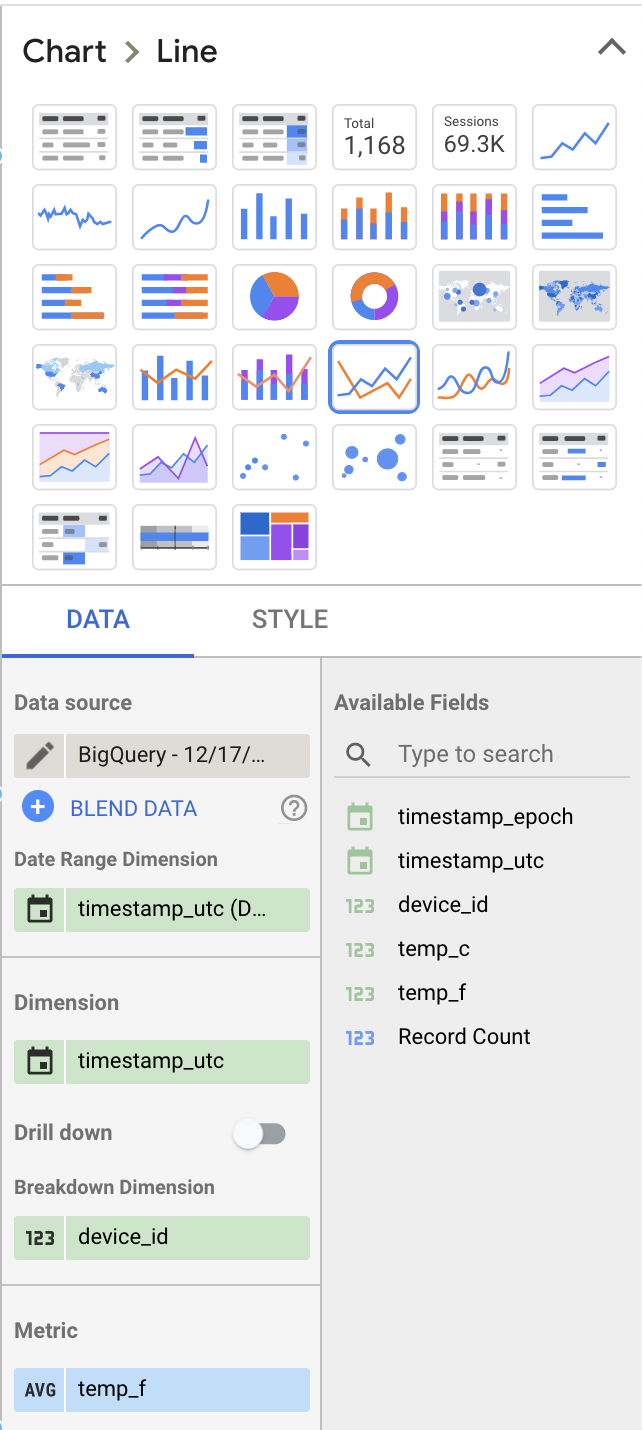
Modifions quelques valeurs dans la section Data sur la droite pour rendre l'affichage plus pertinent :
- Sélectionnez Line Chart comme type de visualisation à la place de Table
- Retirez Record Count de la métrique affichée et remplacez-la par temp_f. Veillez à passer la métrique par défaut SUM à AVG.
- Ajoutez device_id comme dimension de ventilation
Vos choix devraient produire des paramètres de mise en page de dashboard semblables à ceux-ci :
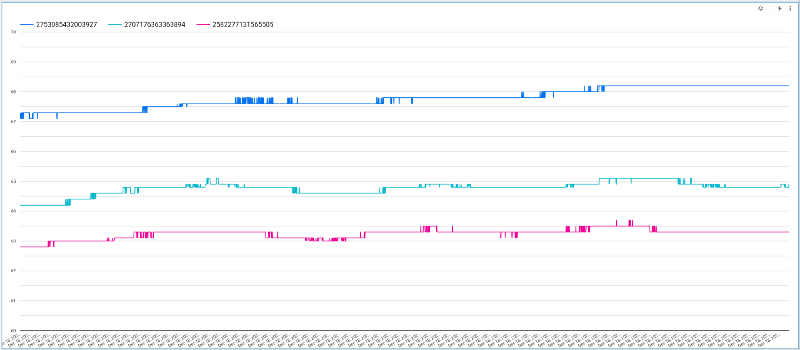
Le graphique obtenu affiche les températures de chaque appareil au fil du temps, mais l'échelle automatique n'est pas forcément optimale, la valeur minimale par défaut de l'axe Y étant zéro. Pour y remédier, cliquez sur l'onglet Style, faites défiler jusqu'à l'option Left Y-Axis et ajustez les valeurs :

Vous pouvez également augmenter le nombre de points de données affichables sur le graphique :
Avec ces réglages, vous obtenez un graphique interactif et soigné qui permet de parcourir les températures de chaque appareil au fil de leurs variations :
À suivre : Machine Learning
Rendez-vous dans la troisième partie, où nous construirons un modèle de machine learning fonctionnel sur ce dataset BigQuery et l'utiliserons pour générer des prédictions en temps réel.