
Dieser Beitrag knüpft an Teil 1 an, in dem wir gezeigt haben, wie Sie eine produktionsreife Flotte von IoT-Geräten sicher anbinden und Telemetriedaten über IoT Core und Pub/Sub in Ihre Google-Cloud-Umgebung streamen.
Glückwunsch! Sie haben mehrere IoT-Geräte erfolgreich registriert – und nun?
Im nächsten Schritt geht es darum, ein System zu entwerfen, das Speicherung, Analyse und Visualisierung Ihrer Daten in großem Maßstab ermöglicht.
Dafür braucht es frühzeitig eine durchdachte Datenflussarchitektur, die solchen datenintensiven Operationen gewachsen ist. Dieser Artikel zeigt Schritt für Schritt, wie das gelingt.
Überblick
Der Artikel ist in folgende Abschnitte gegliedert:
- Batch-Loading in Data Sinks
- Speicherung und Analyse der Daten
- Visualisierung der Daten im Warehouse
Anders als in Teil 1 lässt sich alles, was hier beschrieben wird, vollständig über die GCP-Webkonsole erledigen. SQL-Grundkenntnisse genügen.
Folgende vollständig verwalteten und automatisch skalierenden Google-Cloud-Dienste kommen zum Einsatz:
- Pub/Sub – eine serverlose Message Queue
- Dataflow – eine Engine für Stream- und Batch-Verarbeitung
- BigQuery – ein serverloses Data Warehouse
- Data Studio – ein Dienst zur Datenvisualisierung und Dashboard-Erstellung
Batch-Loading in Data Sinks
Prüfen, ob Nachrichten ankommen
Wenn Sie Geräte erfolgreich in der IoT-Registry angemeldet haben und bereits Daten an den IoT Core streamen, sollten Sie im GCP-IoT-Hauptdashboard einen kontinuierlichen Strom an Nachrichten sehen:
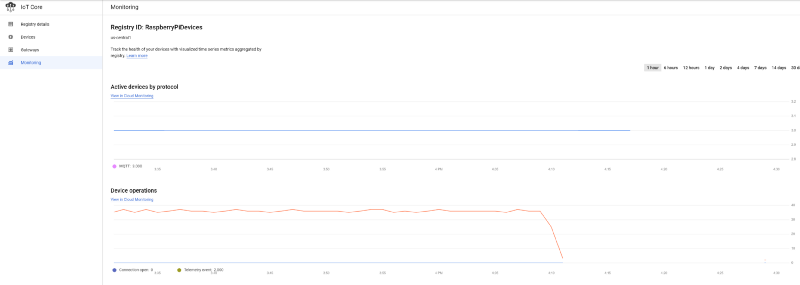 Drei erfolgreich verbundene Geräte, die alle fünf Sekunden Temperaturdaten senden
Drei erfolgreich verbundene Geräte, die alle fünf Sekunden Temperaturdaten senden
Wie in Teil 1 gezeigt, treffen diese Nachrichten auch in Ihrem Pub/Sub-Topic "temperature" ein:
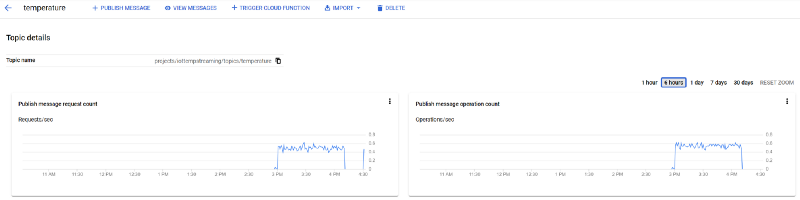 Pub/Sub-Nachrichten treffen im Topic "temperature" ein
Pub/Sub-Nachrichten treffen im Topic "temperature" ein
Streaming nach BigQuery
Sehr gut – die Nachrichten kommen in Google Cloud an. Als Nächstes wandern die Pub/Sub-Nachrichten in ein Data Warehouse, das die Daten kosteneffizient langfristig speichert und gut skalierbare Auswertungen erlaubt. Auftritt: BigQuery.
BigQuery, das vollständig verwaltete, serverlose und automatisch skalierende Data Warehouse von Google Cloud, rechnet Compute und Storage nutzungsbasiert ab – und ist damit ein idealer Data Sink, um unsere IoT-Daten zu speichern und auszuwerten.
Aber wie streamen wir die Pub/Sub-Nachrichten nach BigQuery? Mit Dataflow.
Dataflow, die vollständig verwaltete und automatisch skalierende Variante von Apache Beam, ist darauf ausgelegt, Daten von einem Dienst zum nächsten zu transportieren. Optional können Sie Daten filtern und transformieren und das Batch-Loading in Dienste mit begrenzter Ladekapazität – etwa Datenbanken oder Data Warehouses – optimieren.
Dataflow bringt mehrere von Google Cloud bereitgestellte Standard-Templates mit, darunter eines für Pub/Sub-zu-BigQuery. Es ist also keine Zeile Code nötig, um Datenaufnahme und Speicher-/Analysedienste miteinander zu verbinden.
Da Pub/Sub, Dataflow und BigQuery vollständig verwaltet und automatisch skalierbar sind und – mit Ausnahme von Dataflow – auch serverlos arbeiten, lässt sich ein durchgängiges IoT-Datenmanagementsystem aufbauen, das mühelos vom Entwicklungstest bis hin zu Petabyte-Workloads skaliert – praktisch ohne Infrastrukturaufwand beim Skalieren.
Sehen wir uns das Zusammenspiel dieser Dienste in der Praxis an!
Pub/Sub-Subscription einrichten
Bevor wir Daten von Pub/Sub nach Dataflow bewegen, legen wir eine Pub/Sub-Subscription an, die das Topic abonniert.
Warum? Nachrichten, die ein Pub/Sub-Topic erreichen, gehen sofort an die Topic-Subscriber (Push-Strategie) und werden anschließend aus dem Topic gelöscht. Subscriber dagegen können Nachrichten vorhalten, bis ein Prozess sie abruft (Pull-Strategie). Sie könnten Dataflow zwar direkt mit einem Topic verbinden – fällt der Dataflow-Job dann jedoch aus, gehen alle Nachrichten verloren, die in dieser Zeit am Topic eintreffen.
Verbinden Sie Dataflow stattdessen mit einer Subscription, die das Topic abonniert hat, gehen auch bei Ausfällen keine Nachrichten verloren. Wird ein Dataflow-Job vorübergehend unterbrochen, bleiben alle noch nicht verarbeiteten IoT-Nachrichten in der Pub/Sub-Subscription liegen, bis Dataflow den Pull wieder aufnimmt.
Eine Pub/Sub-Subscription auf ein Topic schafft also eine Datenarchitektur, die robust gegenüber Ausfällen nachgelagerter Dienste ist.
So legen Sie eine Subscription in Pub/Sub an:
- Wechseln Sie zu Subscriptions.
- Klicken Sie auf "Create Subscription" und benennen Sie die Subscription mit "temperature_sub".
- Abonnieren Sie damit das Pub/Sub-Topic "temperature".
- Belassen Sie alle weiteren Optionen auf den Standardwerten.
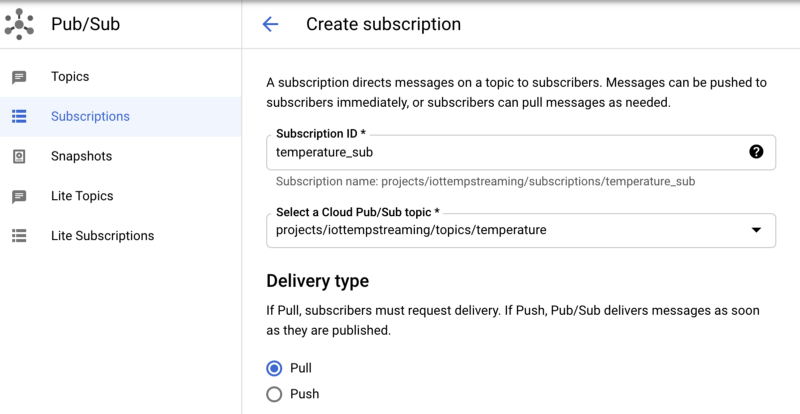 Anlegen der Pub/Sub-Subscription "temperature_sub" auf das Topic "temperature"
Anlegen der Pub/Sub-Subscription "temperature_sub" auf das Topic "temperature"
Sobald die Subscription erstellt ist, klicken Sie darauf und anschließend auf " Pull". Die ersten Nachrichten sollten nun eintreffen:
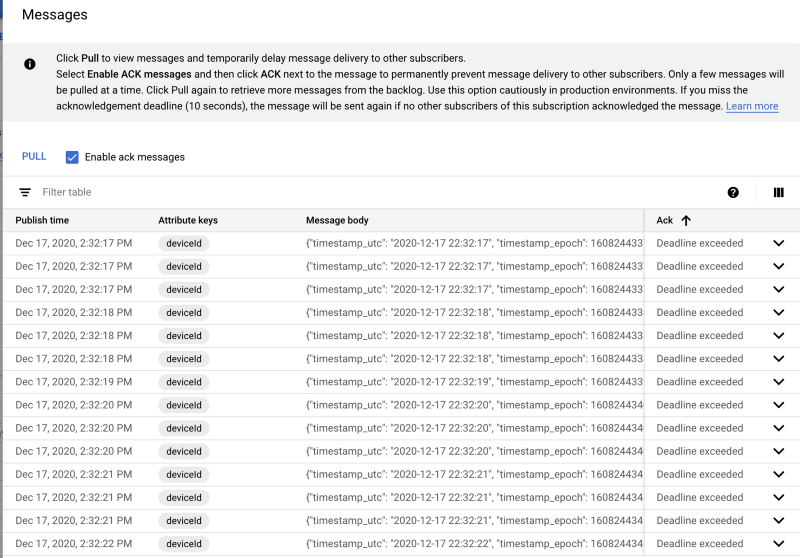 Beispielnachrichten, die in der Pub/Sub-Subscription eintreffen
Beispielnachrichten, die in der Pub/Sub-Subscription eintreffen
Speicherung und Analyse der Daten
Da nun eine Pub/Sub-Subscription Nachrichten empfängt, können wir gleich einen Dataflow-Job einrichten, der die Pub/Sub-Nachrichten nach BigQuery überträgt. Vorher legen wir in BigQuery aber eine Tabelle an, in der die Daten von Dataflow landen sollen.
BigQuery-Tabelle einrichten
Wechseln Sie zu BigQuery, klicken Sie auf "Create Dataset" und benennen Sie das Dataset "sensordata". Belassen Sie die übrigen Optionen auf den Standardwerten:
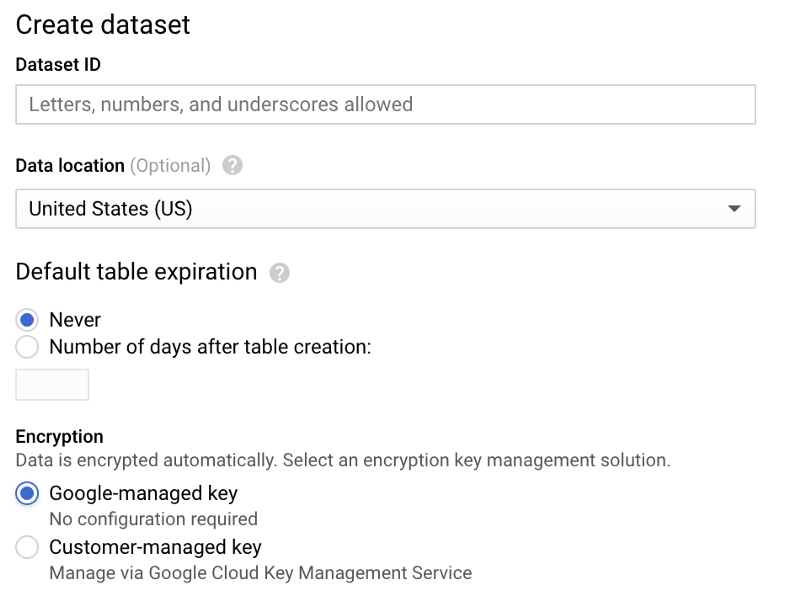 Dialog zum Anlegen eines BigQuery-Datasets
Dialog zum Anlegen eines BigQuery-Datasets
Wählen Sie das angelegte Dataset aus, klicken Sie auf " Create table" und nennen Sie die neue Tabelle "temperature". Übernehmen Sie unbedingt das Schema sowie die Partitionierungs- und Clustering-Optionen aus den folgenden Screenshots, da sie typische Abfragemuster optimal unterstützen:
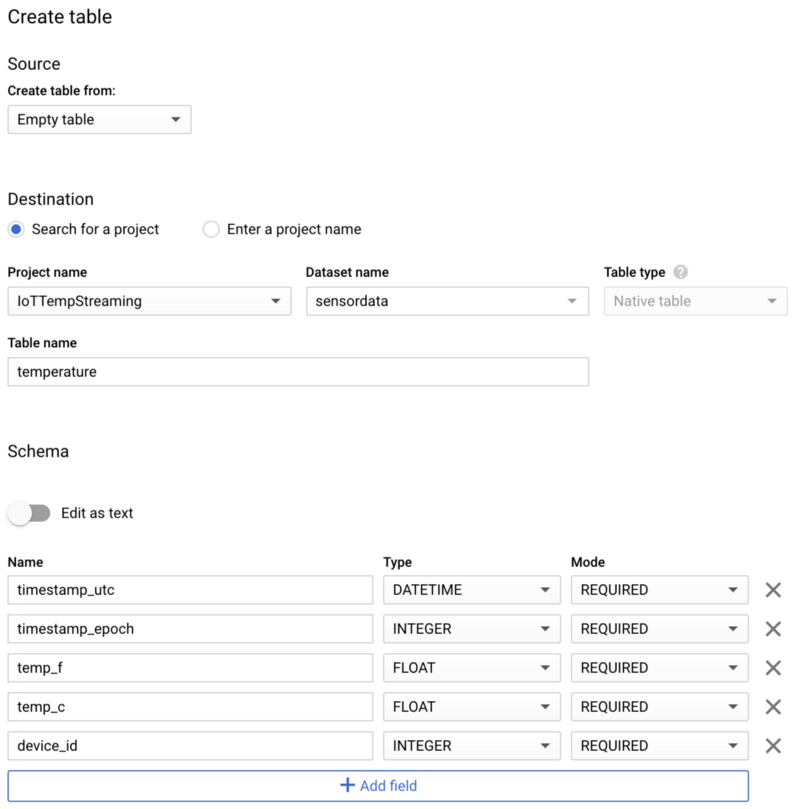 Schema der neuen BigQuery-Tabelle "temperature"
Schema der neuen BigQuery-Tabelle "temperature"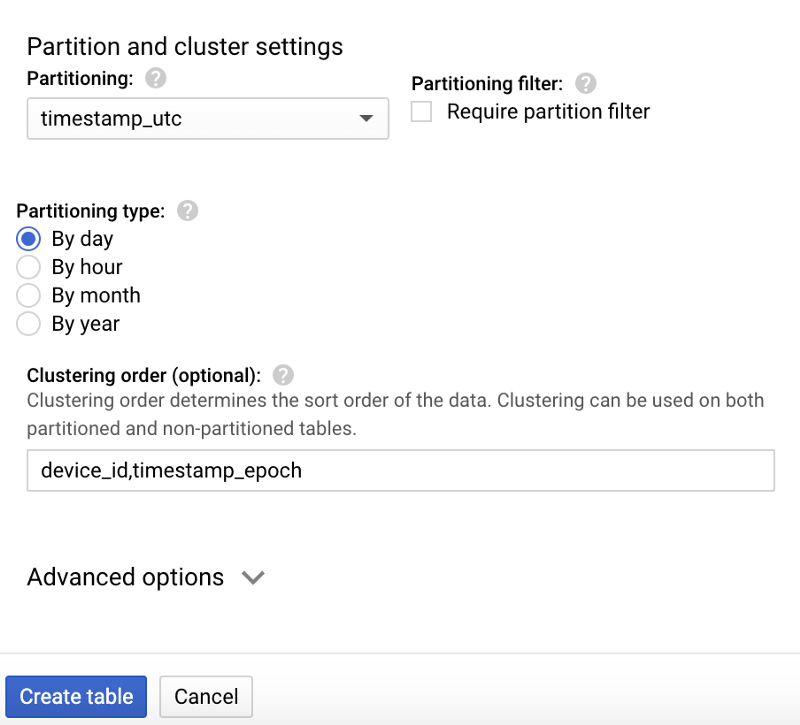 Partitionierungs- und Clustering-Optionen für die Tabelle "temperature"
Partitionierungs- und Clustering-Optionen für die Tabelle "temperature"
Bei korrekter Einrichtung sieht Ihre neue, leere Tabelle so aus:
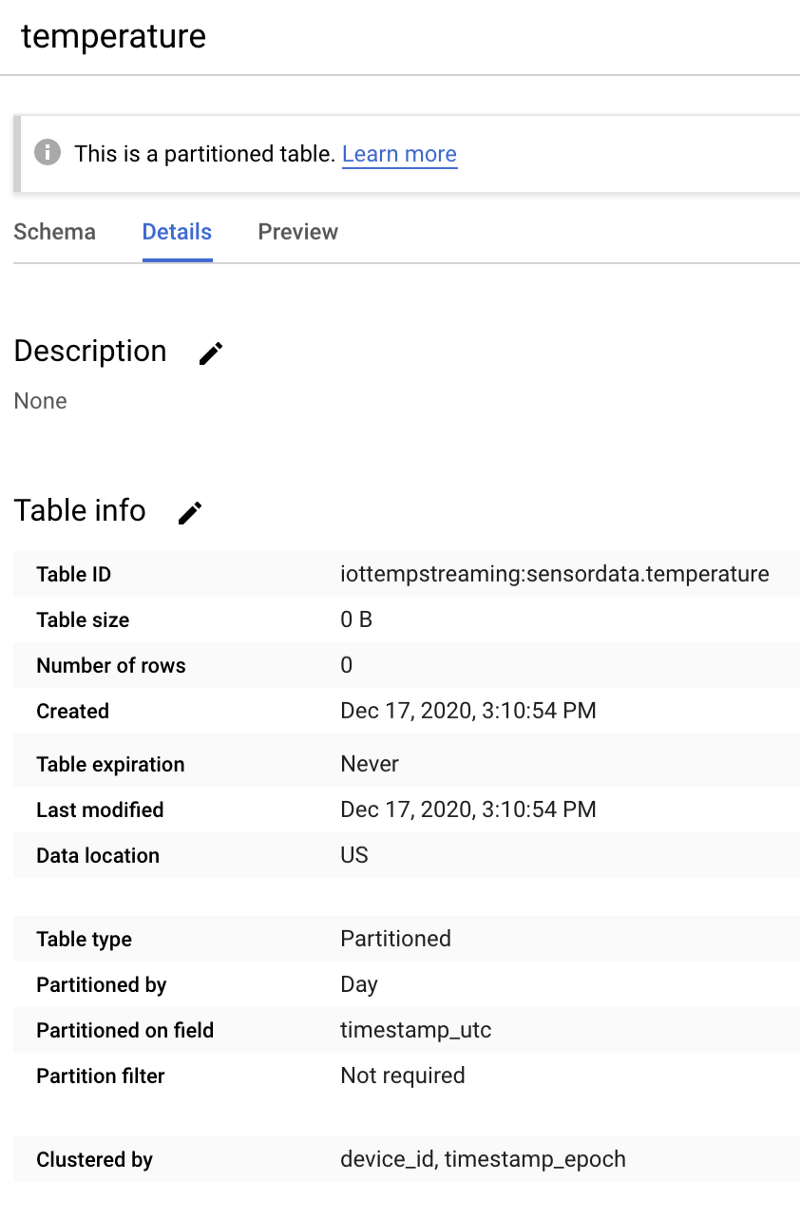 Eine leere BigQuery-Tabelle "temperature" im Dataset "sensordata"
Eine leere BigQuery-Tabelle "temperature" im Dataset "sensordata"
Sobald Daten in die Tabelle fließen, demonstrieren wir ein typisches IoT-Abfragemuster: Analysen für ein bestimmtes Zeitfenster (z. B. eine Stunde am aktuellen Tag) und ein bestimmtes Gerät.
Das oben gezeigte Tabellendesign ist für solche Abfragen aus zwei Gründen ideal:
- Die Partitionierung auf das UTC-Zeitstempelfeld sorgt dafür, dass datumsspezifische Abfragen DateTime-Partitionen anderer Tage gar nicht erst scannen.
- Innerhalb einer Partition ermöglicht das Clustering (Sortierung) nach deviceId und Epoch-Zeitstempel ein deutlich effizienteres Abrufen der Daten für ein bestimmtes Gerät und Zeitfenster innerhalb dieser Tagespartition.
Um solche Abfragen schreiben zu können, brauchen wir Daten in der Tabelle. Bringen wir also den Dataflow-Job in Gang!
Dataflow einrichten
Aktuell liegen Nachrichten in einer Pub/Sub-Subscription, die abgeholt werden wollen, und eine BigQuery-Tabelle ist bereit, sie aufzunehmen. Was noch fehlt, ist der ETL-Klebstoff, der beides verbindet. Da Pub/Sub und BigQuery vollständig verwaltet, automatisch skalierend und serverlos sind, suchen wir idealerweise ein ETL-Werkzeug mit denselben Eigenschaften.
Dataflow erfüllt diese Anforderungen weitgehend. Das Marketing rund um Dataflow verspricht alle drei Eigenschaften – tatsächlich ist Dataflow aber nicht vollständig serverlos. Sie müssen Instanztypen und -größen festlegen, die Mindest- und Höchstanzahl an Instanzen für das Auto-Scaling angeben sowie den temporären Speicherplatz pro Instanz definieren. Sie verwalten diese Instanzen und ihre Skalierungsentscheidungen zwar nicht selbst, müssen die Spezifikationen aber vorgeben. Bei Pub/Sub und BigQuery hingegen erfolgt das Skalieren ganz ohne Infrastrukturkonfiguration.
Auch wenn Dataflow nicht völlig serverlos ist, eignet es sich perfekt für unsere Pub/Sub-zu-BigQuery-ETL-Anforderung. Es ist zudem einfach zu nutzen, vor allem weil GCP zahlreiche Standard-Job-Templates mitbringt – darunter eines für den Pub/Sub-zu-BigQuery-Workflow. Abgesehen davon, dass Sie das Auto-Scaling-Limit erhöhen müssen, sobald Ihr IoT-Datenvolumen mit der Zeit wächst, brauchen Sie sich theoretisch nie um die Infrastruktur hinter Dataflow zu kümmern.
Mit den Grundlagen im Gepäck richten wir nun einen Dataflow-Job ein. Wechseln Sie zu Dataflow, klicken Sie auf " Create Job from Template" und folgen Sie diesen Schritten:
- Benennen Sie den Job mit "pubsub-temp-to-bq".
- Verwenden Sie das Standard-Streaming-Template "Pub/Sub Subscription to BigQuery".
- Geben Sie den vollständigen Namen der Pub/Sub-Subscription an.
- Geben Sie die vollständige BigQuery-Tabellen-ID an.
- Geben Sie einen Cloud-Storage-Bucket-Pfad an, in dem temporäre Daten als Teil des Batch-Loading-Prozesses von Dataflow nach BigQuery abgelegt werden.
- Belassen Sie alle weiteren Optionen auf ihren Standardwerten. Üblicherweise würde man die Advanced Options aufklappen und Parameter wie Maschinentyp und -größe, die Min-/Max-Maschinenzahl für das Auto-Scaling sowie die Festplattengröße pro Maschine festlegen. Für Testzwecke reichen die Standardwerte.
Ihr Dataflow-Job-Erstellungsfenster sollte etwa so aussehen:
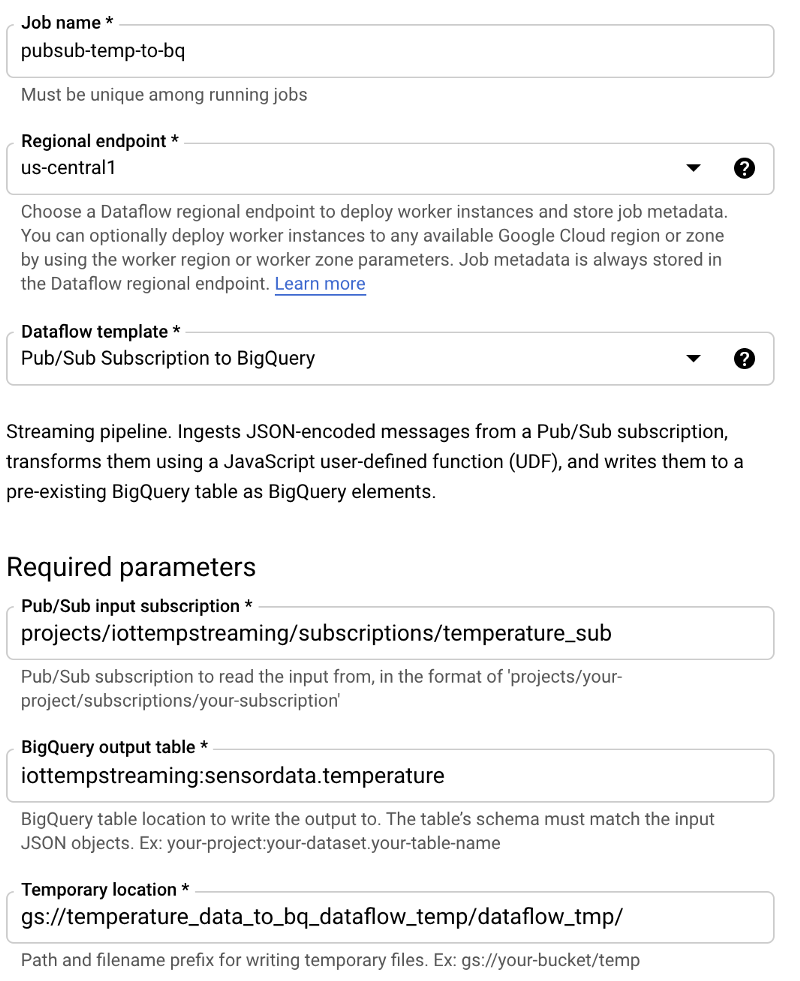
Nach einem Klick auf " Create" und ein paar Minuten Wartezeit, bis die Infrastruktur hochgefahren ist, sehen Sie, wie Daten von der Pub/Sub-Subscription in die Ziel-Tabelle in BigQuery fließen.
Das Python-Skript zum Streaming der Temperaturdaten aus Teil 1 sendet einen Datensatz pro Sekunde. Im unten gezeigten Directed Acyclic Graph (DAG) von Dataflow sollten Sie also x Elemente pro Sekunde sehen, wobei x der Anzahl der getesteten Geräte entspricht. In meinem Fall streamen drei Geräte:
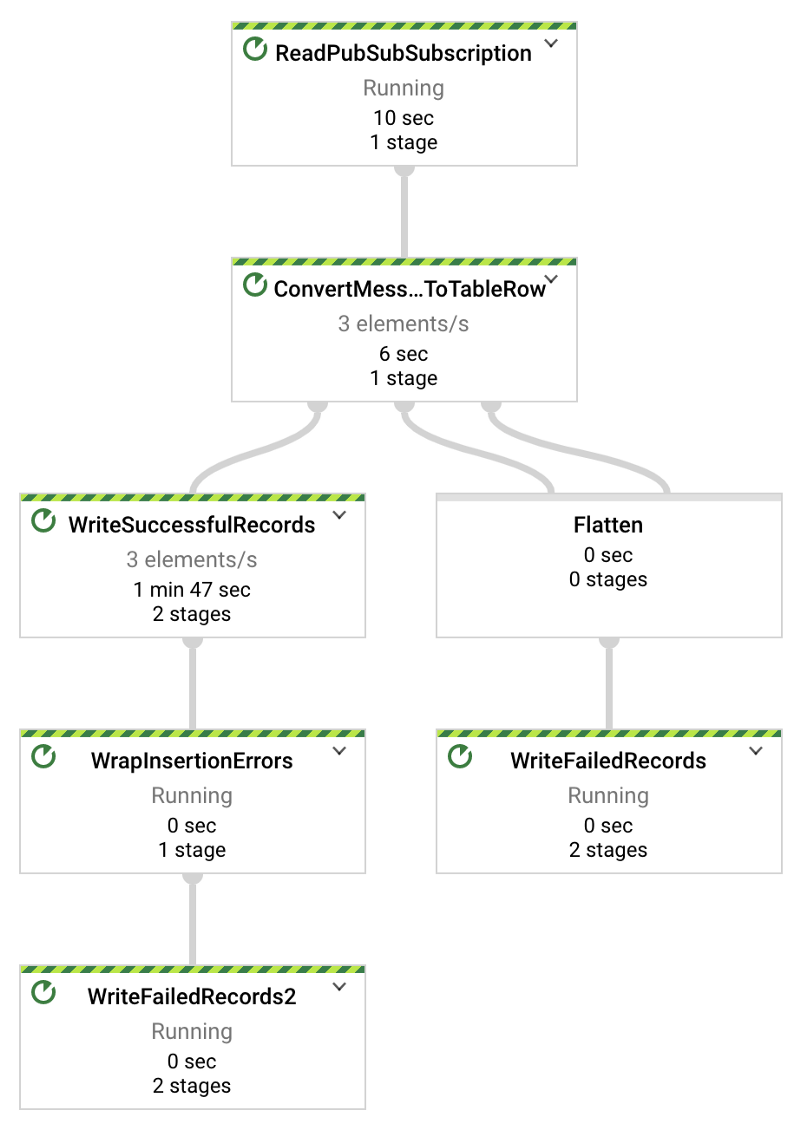 Nachrichten, die per Dataflow-Job erfolgreich von Pub/Sub nach BigQuery gestreamt werden
Nachrichten, die per Dataflow-Job erfolgreich von Pub/Sub nach BigQuery gestreamt werden
Sobald der Dataflow-Job aktiv ist und Daten erfolgreich von der Pub/Sub-Subscription nach BigQuery überträgt, können Sie in BigQuery eine Abfrage in folgendem Format ausführen und Echtzeitdaten in der Tabelle beobachten:
SELECT *FROM `iottempstreaming.sensordata.temperature`WHERE DATE(timestamp_utc) = "2020-12-18"ORDER BY timestamp_epoch DESCLIMIT 10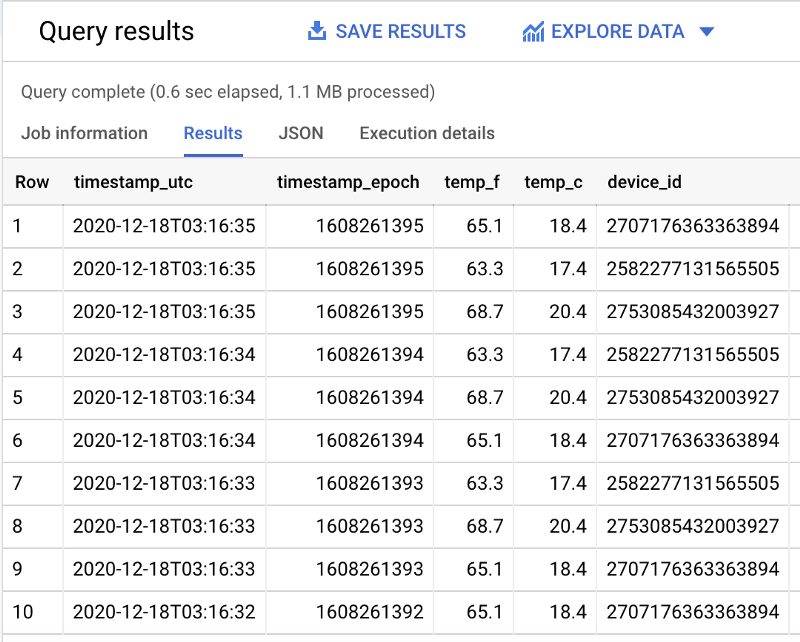
Dass die Partitionsfilterung greift, erkennt man daran, dass ohne den datumsbezogenen WHERE-Filter mehr Daten gescannt werden.
In meinem Beispieldatensatz werden mit Filter 1,1 MB gescannt (siehe oben) und ohne Filter 1,7 MB (siehe unten):
SELECT *FROM `iottempstreaming.sensordata.temperature`ORDER BY timestamp_epoch DESCLIMIT 10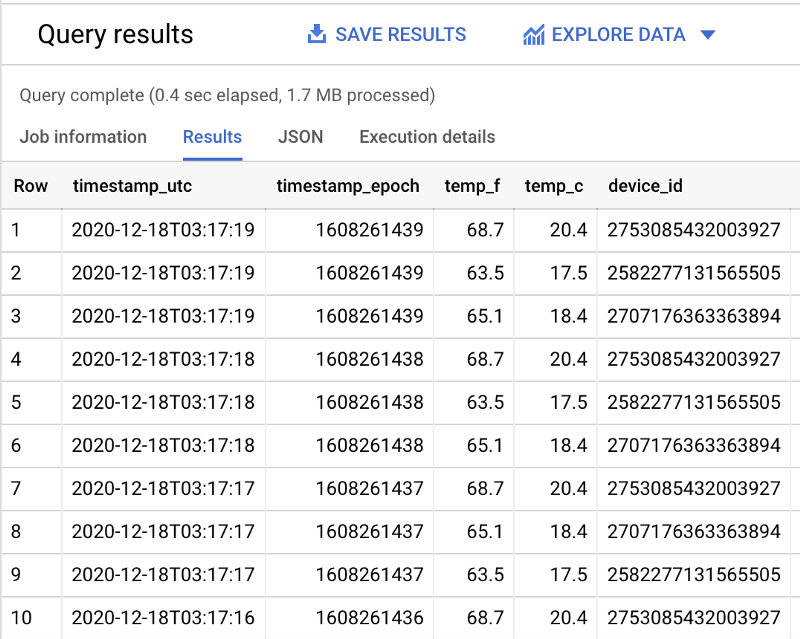
Sehen wir uns nun Durchschnitt, Minimum und Maximum der Temperaturen jedes Sensors aus der vergangenen Stunde an:
SELECT device_id, ROUND(AVG(temp_f), 1) AS temp_f_avg, MIN(temp_f) AS temp_f_min, MAX(temp_f) AS temp_f_maxFROM `iottempstreaming.sensordata.temperature`WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)GROUP BY device_id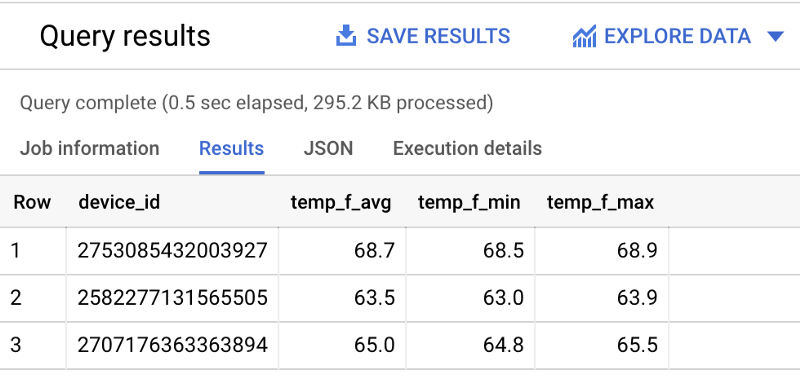 Verschiedene Kennzahlen je Temperatursensor
Verschiedene Kennzahlen je Temperatursensor
Glückwunsch! Sie haben einen durchgängig vollständig verwalteten Daten-Workflow eingerichtet – von der Datenaufnahme bis zum Analyse-Backend. Bevor wir abschließen, schauen wir uns kurz an, wie einfach sich diese Daten mit Data Studio visualisieren lassen.
Visualisierung der Daten im Warehouse
Führen Sie zunächst in BigQuery eine Abfrage aus, die alle Datensätze eines bestimmten Tages zurückgibt:
SELECT *FROM `iottempstreaming.sensordata.temperature`WHERE DATE(timestamp_utc) = "2020-12-18"ORDER BY timestamp_epoch DESCKlicken Sie rechts neben " Query Results" auf " Explore Data" und anschließend auf " Explore with Data Studio":
Daraufhin öffnet sich eine Tabelle mit den eben abgefragten Daten. Standardmäßig zeigt sie allerdings eine eher unspannende Übersicht: die Anzahl der pro Sekunde gestreamten Datensätze.
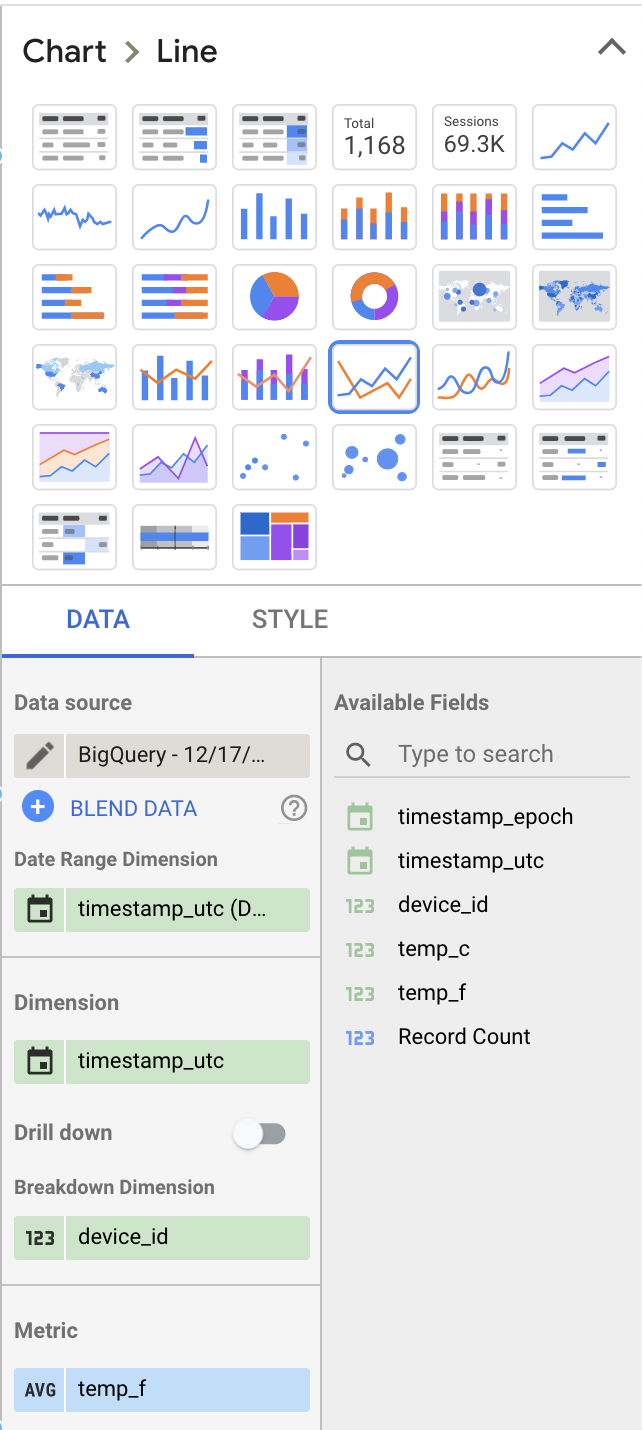
Passen wir rechts im Datenbereich ein paar Werte an, damit es interessanter wird:
- Wählen Sie statt "Table" den Visualisierungstyp "Line Chart".
- Entfernen Sie "Record Count" als angezeigte Metrik und ersetzen Sie sie durch "temp_f". Wechseln Sie dabei die Standardmetrik von "SUM" auf "AVG".
- Fügen Sie "device_id" als Breakout-Dimension hinzu.
Ihre Einstellungen für das Dashboard-Layout sollten ungefähr so aussehen:
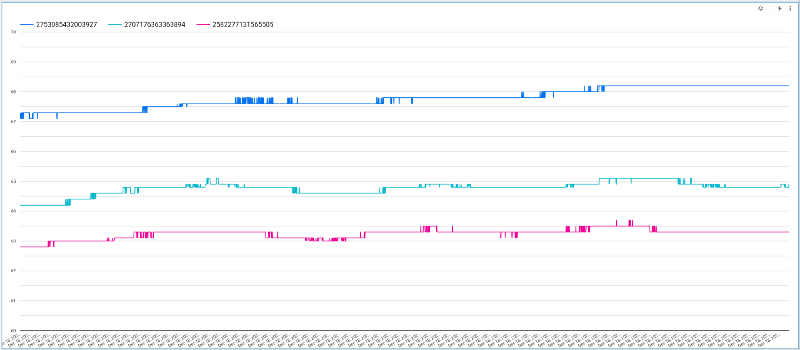
Das Diagramm zeigt nun die Temperaturwerte je Gerät über die Zeit. Allerdings ist die automatische Skalierung möglicherweise nicht ideal, da der Standardwert der Y-Achse bei null beginnt. Wechseln Sie auf den Tab "Style", scrollen Sie zur Option "Left Y-Axis" und passen Sie die Werte sinnvoll an:

Auch die Anzahl der Datenpunkte im Diagramm können Sie erhöhen:
Das Ergebnis: ein ansprechendes, interaktives Diagramm, mit dem Sie die Temperaturverläufe Ihrer Geräte über die Zeit erkunden können:
Als Nächstes: Machine Learning
Bleiben Sie dran für Teil 3: Dort bauen wir auf diesem BigQuery-Datensatz ein funktionsfähiges Machine-Learning-Modell auf und nutzen es für Echtzeitvorhersagen.