
本記事は Part One の続編です。Part Oneでは、本番規模のIoTデバイス群が送信するテレメトリデータを、IoT CoreとPub/Sub経由でGoogle Cloud環境に安全に取り込む方法を解説しました。
お疲れさまでした。複数のIoTデバイスの登録に成功したところで、次は何をすべきでしょうか。
次のゴールは、収集したデータの大規模ストレージ、分析、可視化/ダッシュボード化を実現するシステムを設計することです。
そのためには、大規模なデータ運用を支えるデータフローアーキテクチャをあらかじめ設計しておく必要があります。本記事では、その具体的な手順をハンズオン形式で解説します。
概要
本記事は以下の構成でお送りします。
- データシンクへのバッチロード
- データの保存と分析
- 蓄積データの可視化
Part Oneとは異なり、本記事の内容はGCPのWebコンソール上だけで完結します。基本的なSQLの知識さえあれば実践可能です。
取り上げるGoogle Cloudサービスは、いずれもフルマネージドかつ自動スケーリング対応の以下4つです。
- Pub/Sub — サーバーレスのメッセージキュー
- Dataflow — ストリーム/バッチデータ処理エンジン
- BigQuery — サーバーレスのデータウェアハウス
- Data Studio — データ可視化/ダッシュボード作成サービス
データシンクへのバッチロード
メッセージの到着を確認する
IoTレジストリへのデバイス登録とIoT Coreへのデータストリーミングが正常に始まっていれば、GCPのIoTメインダッシュボード上でメッセージが安定して届いている様子が確認できるはずです。
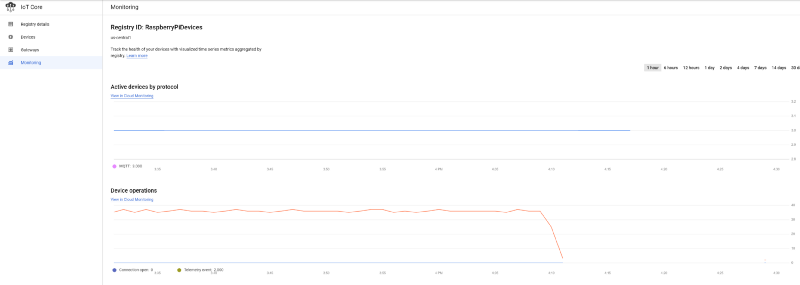 5秒間隔で温度データを送信する、正常に接続された3台のデバイス
5秒間隔で温度データを送信する、正常に接続された3台のデバイス
Part Oneで解説したとおり、これらのメッセージは「temperature」Pub/Subトピックにも届いています。
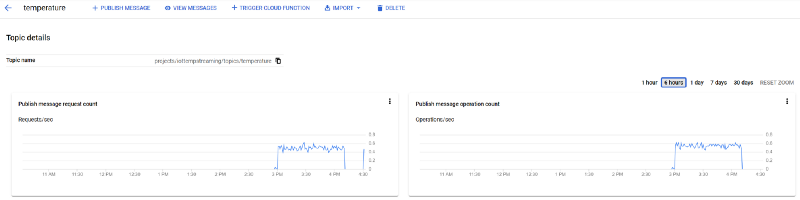 「temperature」トピックに届くPub/Subメッセージ
「temperature」トピックに届くPub/Subメッセージ
BigQueryへのストリーミング
Google Cloudへメッセージが届いていることを確認できました。次は、Pub/Subメッセージをデータウェアハウスへ送り、コスト効率のよい長期保存とスケーラブルな分析の基盤を整える必要があります。ここで活躍するのがBigQueryです。
BigQueryはGoogle Cloudのフルマネージド・サーバーレス・自動スケーリング対応のデータウェアハウスで、コンピュートとストレージのいずれもオンデマンド料金で利用できます。IoTデータの保存と分析にうってつけのデータシンクです。
では、Pub/SubメッセージはどうやってBigQueryへ流し込めばよいのでしょうか。答えはDataflowです。
DataflowはApache BeamのGoogle Cloudによるフルマネージド・自動スケーリング版で、サービス間のデータ受け渡しを担うために設計されています。必要に応じてデータのフィルタリングや変換を行えるほか、データベースやデータウェアハウスのようにロード操作に制約のあるサービスへ最適化されたバッチロードも実行できます。
DataflowにはGoogle Cloudが提供する各種デフォルトテンプレートが用意されており、その中にはPub/Sub-to-BigQueryテンプレートも含まれています。そのため、データ取り込みとデータ保存/分析サービスを連携させるのにコーディングは一切不要です。
Pub/Sub、Dataflow、BigQueryはいずれもフルマネージド・自動スケーリング対応で、(Dataflowを除き)サーバーレスでもあります。そのおかげで、開発時のテストからペタバイト規模の運用までシームレスに拡張できるエンドツーエンドのIoTデータ管理基盤を、スケール時のインフラ管理をほぼ気にすることなく構築できます。
それでは、これらのサービスを連携させて実際に動かしてみましょう。
Pub/Subサブスクリプションのセットアップ
Pub/SubからDataflowへデータを流す前に、Pub/Subトピックを購読するサブスクリプションを作成しておきます。
なぜでしょうか。Pub/Subトピックに届いたメッセージは、(Push方式により)即座に購読者へ送信されたあと、トピックから削除されます。一方サブスクリプションを介する場合は、(Pull方式により)プロセスがメッセージを要求するまで購読側で保持しておけます。Dataflowをサブスクリプションではなくトピックに直接接続することも可能ですが、その方式ではDataflowジョブがダウンしている間にトピックへ届いたメッセージは失われてしまいます。
これに対し、トピックを購読するPub/SubサブスクリプションにDataflowを接続しておけば、ダウンタイム中もメッセージが失われません。Dataflowジョブが一時的に停止しても、未処理のIoTメッセージはサブスクリプションに保持され、Dataflowジョブの再開とプル処理を待つ状態となります。
Pub/Subトピックに対してサブスクリプションを設けることで、下流のデータ取り込みサービスの障害にも耐性のあるデータアーキテクチャを実現できるのです。
Pub/Subでサブスクリプションを作成する手順:
- Subscriptionsへ移動
- 「Create Subscription」をクリックし、サブスクリプション名を「temperature_sub」とする
- Pub/Subトピック「temperature」を購読対象に指定
- その他のオプションはデフォルトのまま
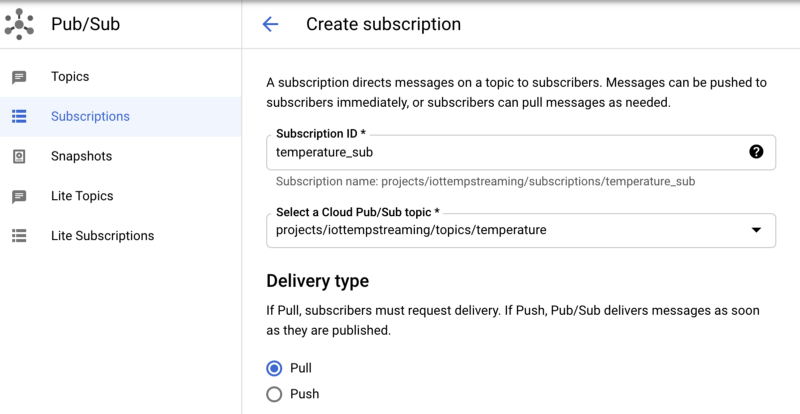 Pub/Subトピック「temperature」に対するサブスクリプション「temperature_sub」の作成
Pub/Subトピック「temperature」に対するサブスクリプション「temperature_sub」の作成
作成が完了したら、サブスクリプションを開いて「 Pull」をクリックしてみましょう。メッセージが流れ込んでくる様子を確認できます。
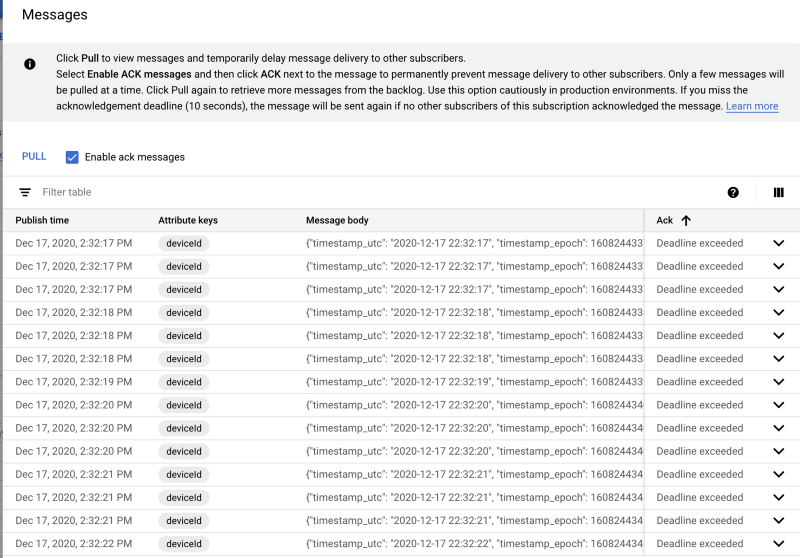 Pub/Subサブスクリプションに流れ込むメッセージの例
Pub/Subサブスクリプションに流れ込むメッセージの例
データの保存と分析
メッセージを受信するPub/Subサブスクリプションが整いました。あとはDataflowジョブを作成してPub/SubメッセージをBigQueryへ送るだけですが、その前に、Dataflowからのデータを受け取るためのテーブルをBigQuery側に用意しておく必要があります。
BigQueryテーブルのセットアップ
BigQueryへ移動して「Create Dataset」をクリックし、データセット名を「sensordata」に設定します。その他のオプションはデフォルトのままで構いません。
 BigQueryデータセットの作成画面
BigQueryデータセットの作成画面
データセットが作成できたら、それを選択して「 Create table」をクリックし、新しいテーブル名を「temperature」とします。一般的なクエリパターンに対応できるよう、以下のスクリーンショットに示すスキーマ、パーティショニング、クラスタリングのオプションを必ず指定してください。
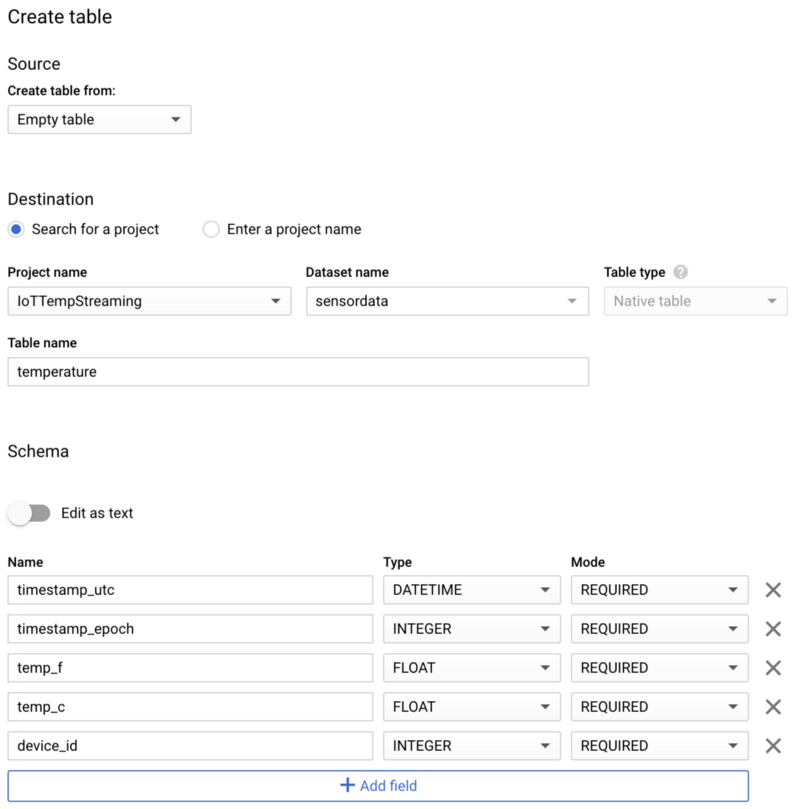 新しい「temperature」BigQueryテーブルのスキーマ
新しい「temperature」BigQueryテーブルのスキーマ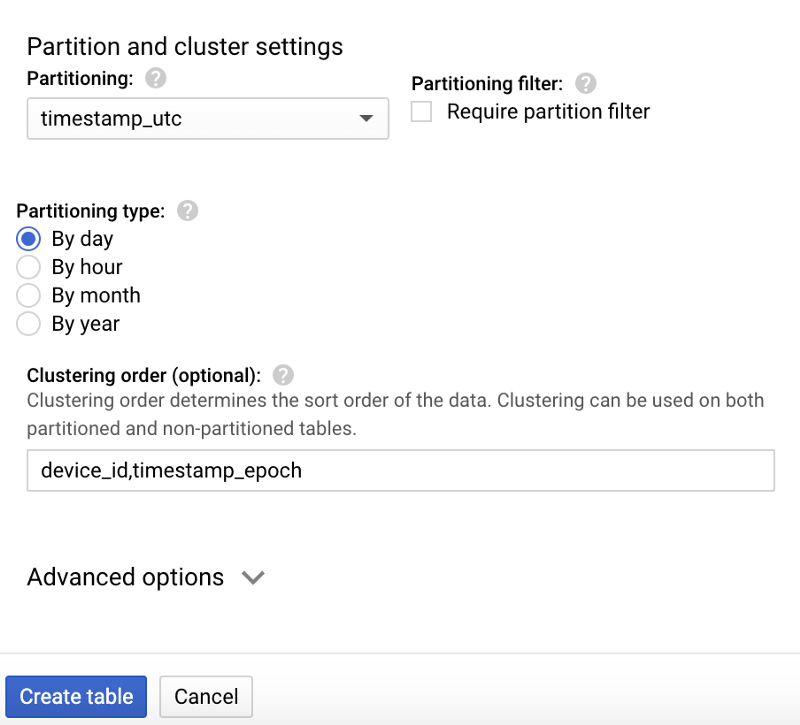 「temperature」テーブルのパーティショニングとクラスタリング設定
「temperature」テーブルのパーティショニングとクラスタリング設定
正しく作成できれば、新しい空のテーブルは次のような状態になります。
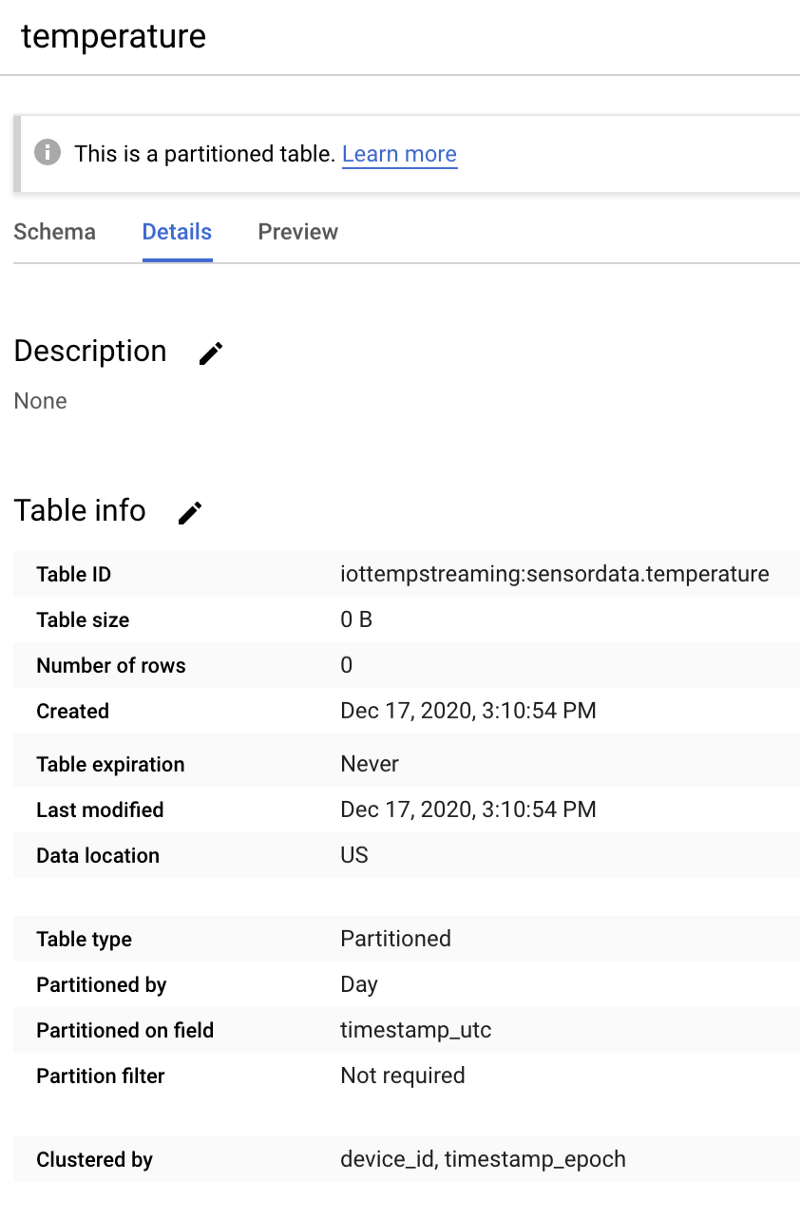 「sensordata」データセット内の空の「temperature」BigQueryテーブル
「sensordata」データセット内の空の「temperature」BigQueryテーブル
テーブルにデータを投入したあとは、IoTでよくあるクエリパターン——特定の時間範囲(例:当日の1時間ウィンドウ)かつ特定のデバイスに対する分析——を取り上げます。
上記のテーブル設計が、こうしたクエリに最適である理由:
- UTCタイムスタンプフィールドでパーティショニングしているため、日付指定クエリでは対象外日のDateTimeパーティションをスキャンせずに済む
- パーティション内では、deviceIdとエポックタイムスタンプによるクラスタリング(ソート)により、その日付パーティション内の特定デバイス・特定時間帯のデータを効率よく取得できる
これらのクエリを書くには、テーブルに実データが入っている必要があります。さっそくDataflowジョブを動かしましょう。
Dataflowのセットアップ
現状、メッセージはPub/Subサブスクリプションに溜まっており、移し先となるBigQueryテーブルも準備済みです。あとは両者をつなぐETLの「のり」が要るだけです。Pub/SubもBigQueryもフルマネージド・自動スケーリング・サーバーレスのサービスなので、ETLツールにも同じ特性が望まれます。
Dataflowは(おおむね)その要件を満たしています。マーケティング上は3拍子そろっているとうたわれていますが、実際には完全なサーバーレスではありません。利用するインスタンスのタイプとサイズ、自動スケーリングが行き来するインスタンス数の最小値・最大値、各インスタンスに必要な一時ディスク容量を指定する必要があるためです。インスタンス自体やスケール判断の管理は不要ですが、こうしたスペックの指定は欠かせません。インフラ設定なしで自動スケールするPub/SubやBigQueryとは対照的な点です。
完全なサーバーレスではないとはいえ、Pub/Sub-to-BigQueryのETL要件にはDataflowが最適です。GCPには多数のデフォルトDataflowジョブテンプレートが用意されており、その中にはPub/Sub-to-BigQueryワークフロー対応のものも含まれているため、使い勝手も良好です。IoTデータのスループット増加に応じて自動スケーリングの最大インスタンス数を引き上げる程度で、Dataflowを支えるインフラの管理に頭を悩ませることは理論上ほぼありません。
基本を押さえたところで、実際にDataflowジョブを実装してみましょう。Dataflowへ移動し「 Create Job from Template」をクリックして、以下の手順を進めます。
- ジョブ名を「pubsub-temp-to-bq」とする
- デフォルトのストリーミングテンプレート「Pub/Sub Subscription to BigQuery」を選択
- Pub/Subサブスクリプションのフルネームを入力
- BigQueryテーブルIDのフルネームを入力
- DataflowがBigQueryへバッチロードする過程で一時データを保存するCloud Storageバケットの場所を入力
- その他のオプションはデフォルトのまま。通常は「Advanced Options」を展開し、利用するマシンタイプやサイズ、自動スケーリングの最小/最大マシン数、マシンごとのディスクサイズを指定しますが、テスト目的であればデフォルトのままで問題ありません。
Dataflowジョブの作成画面は次のような状態になっているはずです。
「 Create」をクリックし、基盤インフラが立ち上がって稼働し始めるまで数分待つと、Pub/Subサブスクリプションから宛先のBigQueryテーブルへとデータが流れ始めます。
Part Oneで紹介したPython製の温度ストリーミングスクリプトは、毎秒1レコードを送信します。したがって、以下のDataflowの有向非巡回グラフ(DAG)では、テストに使うデバイス数を_x_とすると、毎秒_x_件の要素が流れているのが見えるはずです。今回は3台のデバイスから送信しています。
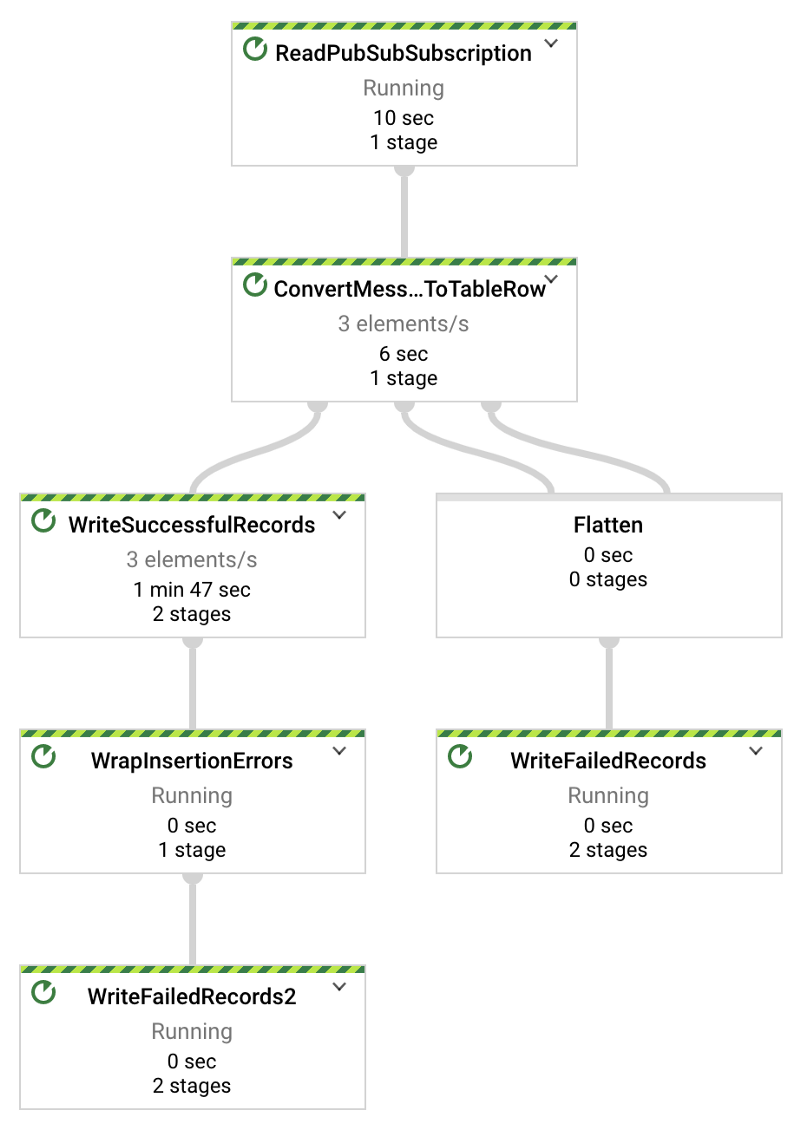 DataflowジョブによってPub/SubからBigQueryへ正常にメッセージが流れている様子
DataflowジョブによってPub/SubからBigQueryへ正常にメッセージが流れている様子
Dataflowジョブが稼働し、Pub/SubサブスクリプションのデータがBigQueryへ正常にストリーミングされていることを確認できたら、次のような形のクエリをBigQueryで実行することで、リアルタイムデータがテーブルに到着している様子を確認できます。
SELECT *FROM `iottempstreaming.sensordata.temperature`WHERE DATE(timestamp_utc) = "2020-12-18"ORDER BY timestamp_epoch DESCLIMIT 10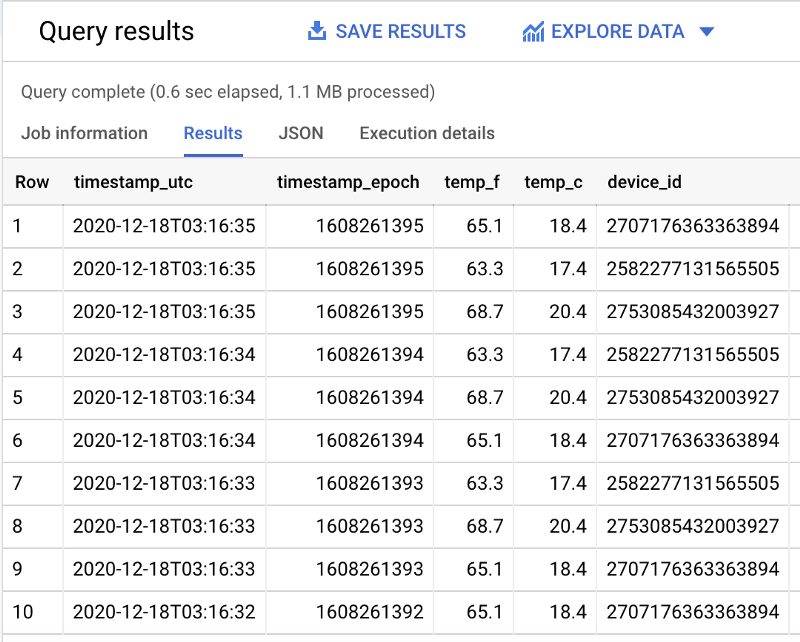
日付フィルタのWHERE句を外すとスキャン対象のデータ量が増えることから、パーティションフィルタリングが効いていることが確認できます。
今回のサンプルデータセットでは、フィルタありで1.1MB(上図)、フィルタなしで1.7MB(下図)がスキャンされました。
SELECT *FROM `iottempstreaming.sensordata.temperature`ORDER BY timestamp_epoch DESCLIMIT 10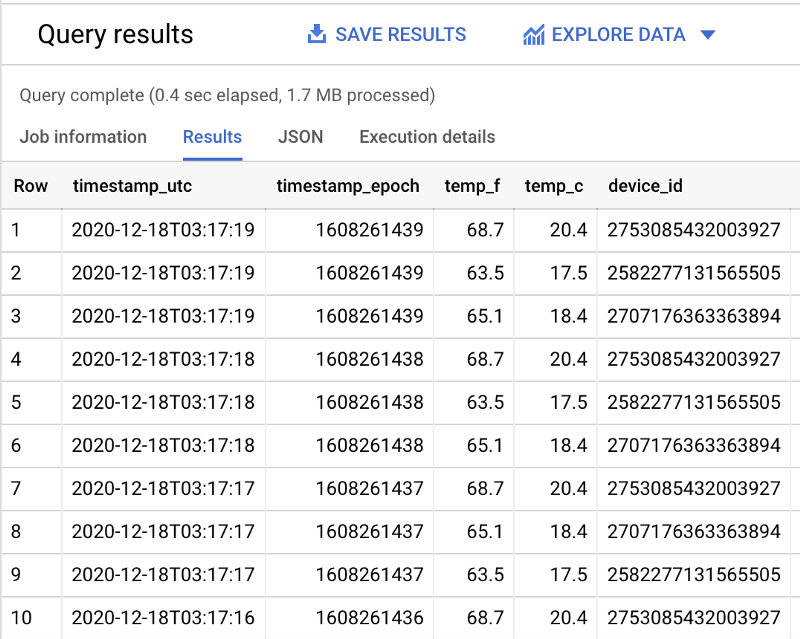
続いて、過去1時間における各センサーの温度の平均値・最小値・最大値を確認してみましょう。
SELECT device_id, ROUND(AVG(temp_f), 1) AS temp_f_avg, MIN(temp_f) AS temp_f_min, MAX(temp_f) AS temp_f_maxFROM `iottempstreaming.sensordata.temperature`WHERE timestamp_utc > DATETIME_ADD(CURRENT_DATETIME(), INTERVAL -60 MINUTE)GROUP BY device_id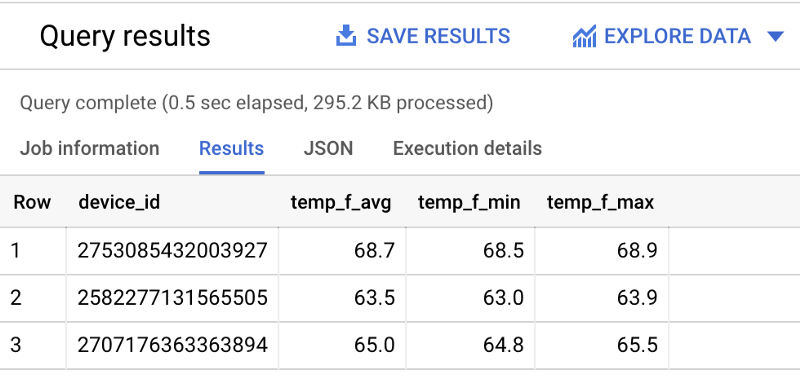 温度を送信中の各デバイスの統計値
温度を送信中の各デバイスの統計値
お疲れさまでした。データ取り込みから分析バックエンドまで、エンドツーエンドでフルマネージドなデータワークフローを構築できました。本ウォークスルーを締めくくる前に、このデータがData Studioでどれほど手軽に可視化できるかを見ておきましょう。
蓄積データの可視化
まずは、特定の日付の全データ行を取得する以下のようなクエリをBigQueryで実行します。
SELECT *FROM `iottempstreaming.sensordata.temperature`WHERE DATE(timestamp_utc) = "2020-12-18"ORDER BY timestamp_epoch DESC「 Query Results」の右側にある「 Explore Data」をクリックし、続いて「 Explore with Data Studio」を選びます。
すると、いま取得したデータをまとめたテーブルが表示されます。ただしデフォルトでは、毎秒のレコード件数を集計しただけのやや単調なテーブルが出るだけです。
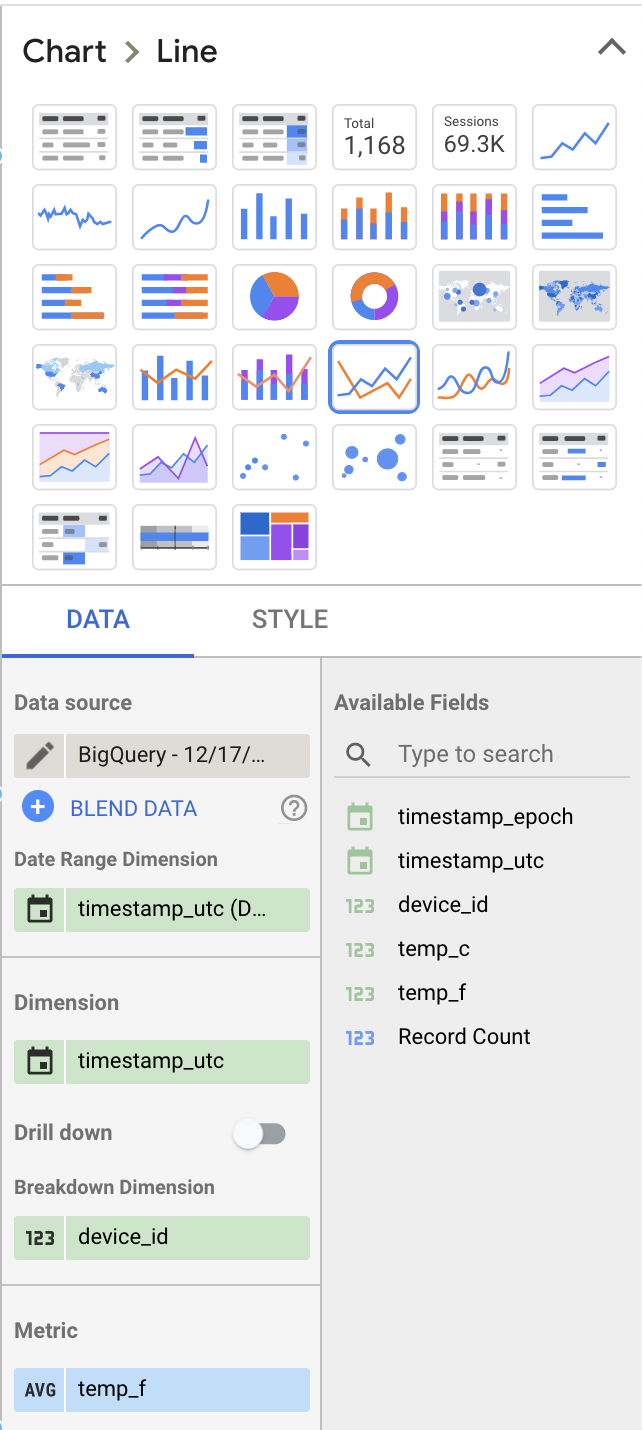
右側のデータセクションでいくつか値を変更し、もう少し見栄えのよい形にしてみましょう:
- 可視化タイプを「Table」から「Line Chart」に変更
- 表示する指標(Metric)から「Record Count」を外し、「temp_f」に置き換え。デフォルトの「SUM」は必ず「AVG」に変更
- ブレークアウトのディメンションとして「device_id」を追加
これらを設定すると、ダッシュボードのレイアウト設定は次のようになります。
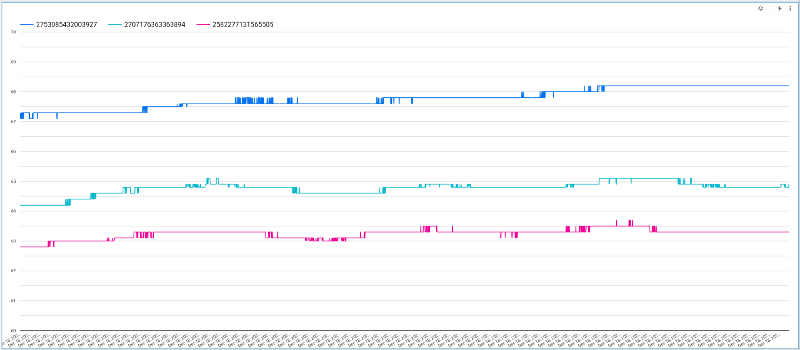
このグラフは各デバイスの温度推移を時系列で表示しますが、Y軸の最小値がデフォルトでゼロになるため、自動スケーリングがあまりきれいに効かない場合があります。これを調整するには、「Style」タブをクリックし、下にスクロールして「Left Y-Axis」のオプションを適切な値に変更してください。

あわせて、グラフ上に表示できるデータポイント数も増やしておくとよいでしょう。
これらの調整を加えると、時間とともに変動するデバイスの温度値をスクロールしながら確認できる、見やすくインタラクティブなチャートが完成します。
次回予告:機械学習
Part 3では、このBigQueryデータセットを使って実用的な機械学習モデルを構築し、リアルタイム予測を生成する方法をご紹介します。お楽しみに。