
Avec Google BigQuery ML, vous pouvez désormais anticiper vos dépenses Google Cloud en quelques minutes, sans quitter l'interface BigQuery Console.
Introduction
Aussi simple soit-elle, la régression linéaire permet de générer efficacement des prédictions précises pour de nombreux cas d'usage concrets. Sa simplicité rend l'entraînement facile à configurer et garantit une convergence rapide.
Dans cet article, je vais expliquer comment analyser les données de facturation Google Cloud et construire un modèle de prédiction simple pour estimer la dépense mensuelle globale attendue. Pour corser un peu l'exercice, je n'utiliserai que Google BigQuery, ce qui permet de conserver toutes les données de facturation au sein de l'écosystème data warehouse.
Pour cet exercice, je vais m'appuyer sur Google Billing Exports. L'export de facturation vers BigQuery permet aux clients d'exporter automatiquement, tout au long de la journée, leur consommation et leurs frais quotidiens vers un dataset BigQuery de leur choix. Pour en savoir plus sur Google Billing Exports, c'est par ici.
Les données et les exemples de code sont disponibles ici : https://github.com/doitintl/BigQueryML-Examples
Données brutes
Le tableau ci-dessous recense les facturations des différents services consommés par deux comptes de facturation Google Cloud que nous possédons.
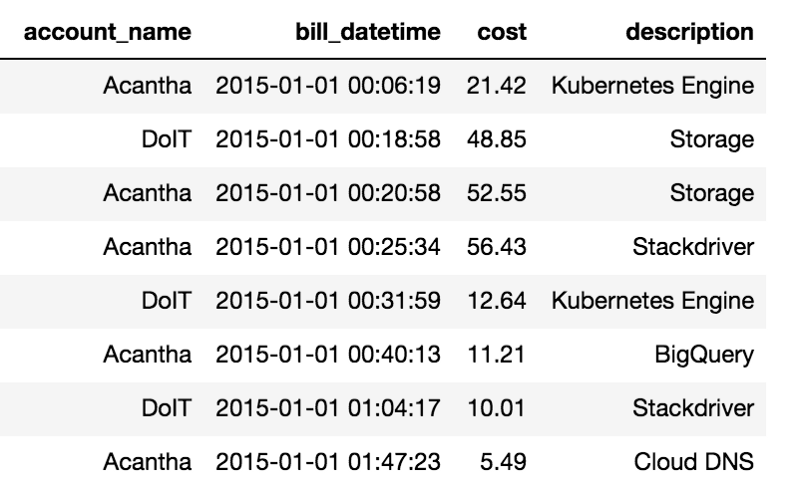 Échantillon de données issues de Google Billing Exports vers BigQuery
Échantillon de données issues de Google Billing Exports vers BigQuery
Le modèle visé
L'objectif est d'estimer la facture totale du mois en cours à partir de l'ensemble des facturations reçues jusqu'à un jour donné.
Le modèle permettra non seulement au client d'estimer sa dépense globale, mais aussi de détecter des anomalies et de déclencher des alertes en cas de surfacturation.
Hypothèses
Le modèle part du principe que la facture mensuelle dépend linéairement de 3 variables :
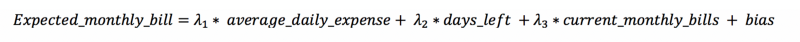
La première variable représente la tendance de consommation quotidienne actuelle. Les deux autres correspondent au nombre de jours restants avant la fin du mois et au solde courant. Combinées, elles permettent au modèle d'estimer la dépense restante du mois.
Agrégation des données à la journée
Le modèle ayant besoin de données quotidiennes, nous nous servons de BigQuery pour agréger les données par jour.
https://gist.github.com/gidutz/2ce58c9391c979b63ac1bbe3bfece7c5
Le schéma obtenu est le suivant :
account_name — l'identifiant du compte
day — le nombre de jours restants avant la fin du mois
month — le mois de facturation
year — l'année de facturation
daily_cost — le coût total payé pour l'ensemble des services durant la journée de facturation
monthly_cost — le label, c'est-à-dire la somme de toutes les facturations effectuées sur le mois en cours, facturations à venir incluses
Maintenant que les données sont agrégées à la journée, je les enregistre dans une nouvelle table et je m'en sers pour générer un dataset ML.
Calcul des agrégations par fenêtre
L'étape suivante consiste à calculer le montant facturé à chaque compte depuis le début du mois jusqu'au jour en cours. Pour cela, nous allons utiliser une fonction d'agrégation par fenêtre. Cette fonction permettra aussi de calculer la dépense quotidienne moyenne du mois, jusqu'au jour en cours.
La syntaxe de la fonction d'agrégation par fenêtre est documentée ici : [1]
analytic_function_name ( [ argument_list ] ) OVER ( [ PARTITION BY partition_expression_list ] [ ORDER BY expression [{ ASC | DESC }] [, ...] ] [ window_frame_clause ] )J'applique cette fonction à notre table billing_daily_monthly de la manière suivante :
https://gist.github.com/gidutz/da662ead3e013c45436b10b574585c06
La visualisation des données montre que la facture mensuelle progresse de manière relativement linéaire :
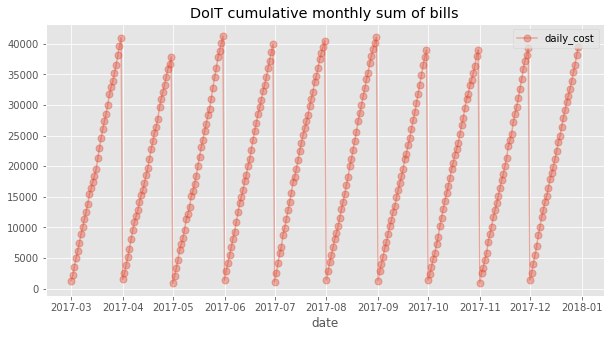
Ces résultats confortent l'idée qu'un modèle linéaire est un choix pertinent pour ce problème de prévision des dépenses. Le gradient varie par ailleurs peu d'un mois à l'autre, ce qui suggère que les variables retenues constituent des statistiques suffisantes au regard de la variable indépendante.
Bien sûr, davantage de variables et des modèles plus complexes produiraient probablement des prédictions plus précises — c'est tout à fait possible avec d'autres outils comme Google Cloud ML. Mais pour l'instant, la préparation des données peut être considérée comme terminée.
(YOUPI !)
Entraînement d'un modèle de régression linéaire avec BigQuery ML
Une fois les données prêtes, je peux m'appuyer sur le tout nouvel outil BigQuery ML (disponible depuis août 2018) pour entraîner un modèle de régression linéaire sur ces données.
Entraîner le modèle sur notre dataset est d'une simplicité déconcertante !
https://gist.github.com/gidutz/7a0bd510494285fd679cde71944e9d77
Prédictions et évaluation du modèle
Une fois enregistré, le modèle peut servir à faire des prédictions. J'utilise pour cela la requête suivante, qui estime la dépense mensuelle finale et calcule l'erreur absolue relative des prédictions au jour le jour :
https://gist.github.com/gidutz/f7de19eee11478d75757e4bdc3b25001
Les résultats présentés dans le tableau ci-dessous peuvent ensuite être enregistrés et alimenter d'autres briques du système, notamment des applications de monitoring et d'alerte. L'erreur absolue relative moyenne du modèle avoisine les 3,0 %, ce qui reste honorable. (À noter : les données ont été générées spécifiquement pour cette démo. Sur des données réelles, j'ai obtenu une erreur d'environ 2,0 %.)
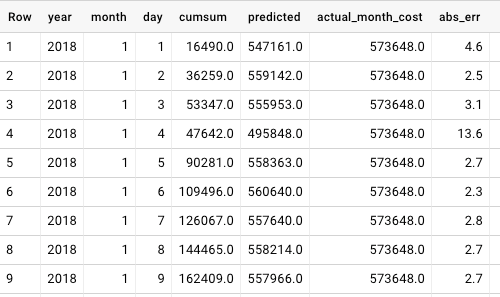 exemple de prédiction
exemple de prédiction
Envie d'aller plus loin ? Rendez-vous sur notre blog, ou suivez Gad sur Twitter.
Remerciements : Vadim Solovey — Édition
amiel m — Relecture technique
Mots-clés : BigQueryML, tutoriel BigQuery ML, exemple BigQuery ML