
Con Google BigQuery ML può prevedere la spesa su Google Cloud in pochi minuti, senza mai uscire dalla console di BigQuery.
Introduzione
La regressione lineare, pur nella sua semplicità, consente di generare previsioni accurate ed efficienti per molti problemi del mondo reale. Proprio grazie a questa semplicità, l'addestramento è facile da configurare e raggiunge rapidamente la convergenza.
In questo articolo spiegherò come analizzare i dati di fatturazione di Google Cloud e costruire un semplice modello predittivo per stimare la spesa mensile complessiva attesa. Per rendere l'esercizio più stimolante, userò solo Google BigQuery, mantenendo così tutti i dati di fatturazione all'interno dell'ecosistema del data warehouse.
Per questo esercizio mi affiderò a Google Billing Exports. L'export della fatturazione su BigQuery permette di esportare automaticamente nel corso della giornata i dati di utilizzo e di costo in un dataset BigQuery a scelta. Per approfondire Google Billing Exports può consultare questa pagina.
I dati e gli esempi di codice sono disponibili qui: https://github.com/doitintl/BigQueryML-Examples
Dati grezzi
La tabella che segue riporta gli addebiti per i diversi servizi consumati su due account di fatturazione Google Cloud di nostra proprietà.
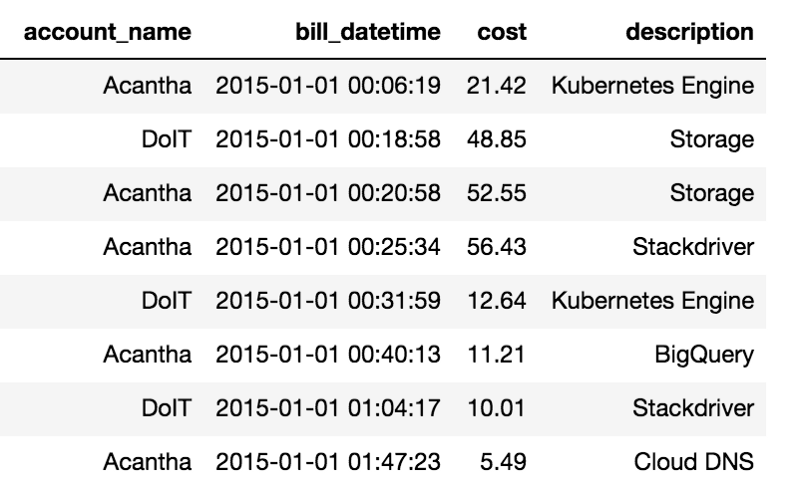 Esempio di dati in Google Billing Exports verso BigQuery
Esempio di dati in Google Billing Exports verso BigQuery
Il modello desiderato
L'obiettivo è stimare il totale della bolletta del mese in corso a partire da tutti gli addebiti registrati fino a un dato giorno.
Il modello permetterà al cliente non solo di stimare la spesa complessiva, ma anche di rilevare anomalie e generare avvisi in caso di addebiti eccessivi.
Ipotesi
Il modello presuppone che la bolletta mensile dipenda linearmente da 3 variabili:
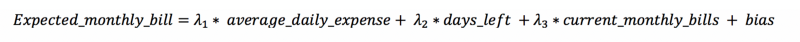
La prima variabile rappresenta l'andamento attuale dei consumi giornalieri. Le altre due sono il numero di giorni che mancano alla fine del mese e il saldo corrente. Insieme, queste tre variabili permettono al modello di stimare la spesa residua del mese.
Aggregare i dati su base giornaliera
Poiché il modello richiede dati su base giornaliera, useremo BigQuery per aggregarli per giorno.
https://gist.github.com/gidutz/2ce58c9391c979b63ac1bbe3bfece7c5
Lo schema risultante è il seguente:
account_name — l'id dell'account
day — giorni che mancano alla fine del mese
month — mese di fatturazione
year — anno di fatturazione
daily_cost — il costo totale di tutti i servizi nel giorno di fatturazione
monthly_cost — l'etichetta, ovvero la somma di tutti gli addebiti del mese corrente, compresi quelli futuri
Ora che i dati sono aggregati su base giornaliera, li salvo in una nuova tabella e li uso per generare un dataset di ML.
Calcolare le aggregazioni con window function
Il passaggio successivo è calcolare quanto è stato fatturato a ciascun account dall'inizio del mese fino al giorno corrente. Lo faremo con una window function di aggregazione, che ci permetterà anche di calcolare la spesa giornaliera media del mese fino al giorno corrente.
La sintassi della window function di aggregazione è disponibile qui: [1]
analytic_function_name ( [ argument_list ] ) OVER ( [ PARTITION BY partition_expression_list ] [ ORDER BY expression [{ ASC | DESC }] [, ...] ] [ window_frame_clause ] )Applico la funzione alla nostra tabella billing_daily_monthly come segue:
https://gist.github.com/gidutz/da662ead3e013c45436b10b574585c06
Mettendo i dati su grafico si vede che la bolletta mensile cresce in modo pressoché lineare:
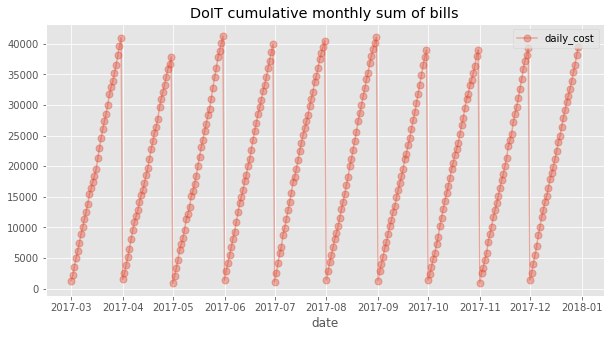
I risultati ci confermano che un modello lineare è la scelta giusta per il problema della stima di spesa. Inoltre, il gradiente varia poco da un mese all'altro, segno che le feature selezionate sono statistiche sufficienti rispetto alla variabile indipendente.
Naturalmente, con più feature e modelli più sofisticati si potranno ottenere previsioni ancora più accurate — strade percorribili con altri strumenti come Google Cloud ML. Per ora però la fase di preparazione dei dati sembra conclusa.
(WOO HOO!)
Addestrare un modello di regressione lineare con BigQuery ML
Una volta pronti i dati, posso sfruttare il nuovo strumento BigQuery ML (disponibile da agosto 2018) per addestrare un modello di regressione lineare.
Addestrare il modello sul nostro dataset è di una semplicità disarmante!
https://gist.github.com/gidutz/7a0bd510494285fd679cde71944e9d77
Generare previsioni e valutare il modello
Una volta salvato, il modello può essere usato per generare previsioni. Per farlo ricorro alla query seguente, che stima la spesa mensile finale e calcola il Relative Absolute Error delle previsioni per ogni giorno:
https://gist.github.com/gidutz/f7de19eee11478d75757e4bdc3b25001
I risultati riportati nella tabella seguente possono essere salvati e messi a disposizione di altri componenti del sistema, comprese le applicazioni di monitoraggio e alerting. Il Mean Relative Absolute Error del modello si attesta intorno al 3,0%: un risultato tutt'altro che male. (Nota: i dati sono stati generati appositamente per questa demo. Con dati reali ho ottenuto un errore di circa il 2,0%.)
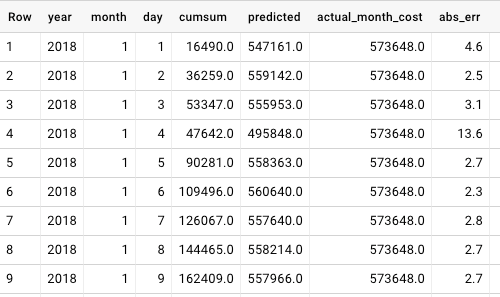 esempio di previsione
esempio di previsione
Vuole leggere altri articoli? Visiti il nostro blog, oppure segua Gad su Twitter.
Ringraziamenti: Vadim Solovey — Editing
amiel m — Revisione tecnica
Keywords: BigQueryML, BigQuery ML tutorial, BigQuery ML example