
Mit Google BigQuery ML prognostizieren Sie Ihre Google Cloud-Kosten in wenigen Minuten – ohne die BigQuery-Konsole zu verlassen.
Einleitung
Lineare Regression ist zwar denkbar einfach, eignet sich aber hervorragend, um für ganz unterschiedliche Praxisprobleme präzise Vorhersagen zu liefern. Dank ihrer schlanken Struktur lässt sich das Training problemlos konfigurieren und konvergiert schnell.
In diesem Beitrag zeige ich, wie Sie Google Cloud-Abrechnungsdaten analysieren und ein einfaches Vorhersagemodell aufbauen, mit dem sich die voraussichtlichen Monatsausgaben abschätzen lassen. Um die Sache spannender zu machen, setze ich ausschließlich auf Google BigQuery – so bleiben sämtliche Abrechnungsdaten im Data-Warehouse-Ökosystem.
Für diese Übung greife ich auf Google Billing Exports zurück. Über den Billing Export nach BigQuery lassen sich tägliche Nutzungs- und Kostendaten automatisch und fortlaufend in ein BigQuery-Dataset Ihrer Wahl exportieren. Mehr zu Google Billing Exports lesen Sie hier.
Die Daten und Code-Beispiele finden Sie hier: https://github.com/doitintl/BigQueryML-Examples
Rohdaten
Die folgende Tabelle zeigt die Abrechnungen verschiedener Services aus zwei unserer Google Cloud-Abrechnungskonten.
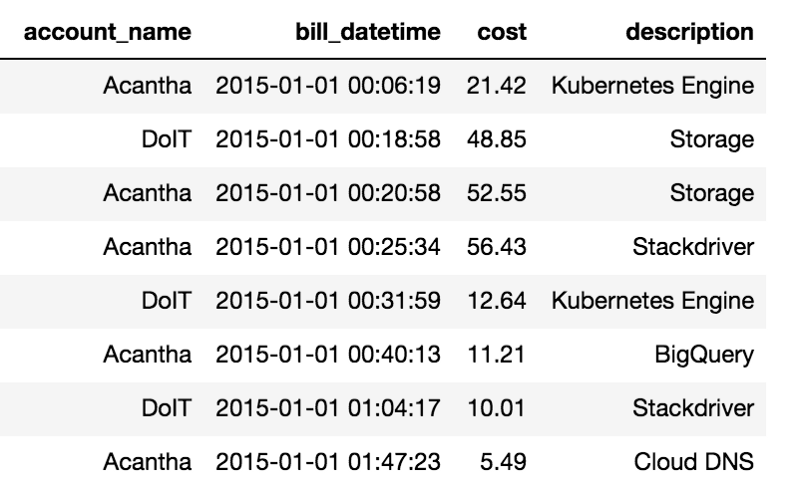 Beispieldaten aus Google Billing Exports nach BigQuery
Beispieldaten aus Google Billing Exports nach BigQuery
Das angestrebte Modell
Ziel ist es, die Gesamtrechnung des laufenden Monats auf Basis aller bis zu einem bestimmten Tag eingegangenen Abrechnungen zu schätzen.
Damit kann der Kunde nicht nur seine Gesamtausgaben einschätzen, sondern auch Anomalien erkennen und Alerts bei Überschreitungen auslösen.
Annahmen
Das Modell geht davon aus, dass die Monatsrechnung linear von 3 Variablen abhängt:
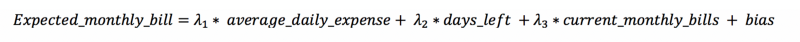
Die erste Variable bildet den aktuellen Trend des täglichen Verbrauchs ab. Die beiden anderen sind die verbleibenden Tage bis zum Monatsende und der aktuelle Saldo. Auf dieser Basis schätzt das Modell die noch ausstehenden Monatsausgaben.
Daten auf Tagesebene aggregieren
Da das Modell Daten auf Tagesebene benötigt, aggregieren wir sie mit BigQuery pro Tag.
https://gist.github.com/gidutz/2ce58c9391c979b63ac1bbe3bfece7c5
Das resultierende Schema sieht so aus:
account_name — die Konto-ID
day — verbleibende Tage bis zum Monatsende
month — Abrechnungsmonat
year — Abrechnungsjahr
daily_cost — die Gesamtkosten aller Services für den jeweiligen Abrechnungstag
monthly_cost — das Label, also die Summe aller Abrechnungen des laufenden Monats inklusive zukünftiger Buchungen
Sobald die Daten auf Tagesebene aggregiert sind, speichere ich sie als neue Tabelle und nutze sie zum Erstellen eines ML-Datasets.
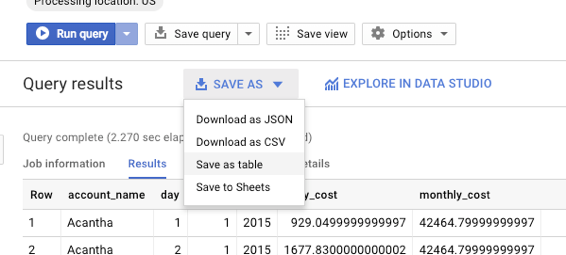
Window-Aggregationen berechnen
Im nächsten Schritt berechnen wir, wie viel jedem Konto vom Monatsanfang bis zum aktuellen Tag berechnet wurde. Dafür nutzen wir eine aggregierende Window-Funktion. Damit lassen sich auch die durchschnittlichen Tagesausgaben des Monats bis zum aktuellen Tag ermitteln.
Die Syntax der aggregierenden Window-Funktion finden Sie hier: [1]
analytic_function_name ( [ argument_list ] ) OVER ( [ PARTITION BY partition_expression_list ] [ ORDER BY expression [{ ASC | DESC }] [, ...] ] [ window_frame_clause ] )Auf unsere Tabelle billing_daily_monthly wende ich die Funktion so an:
https://gist.github.com/gidutz/da662ead3e013c45436b10b574585c06
Beim Visualisieren der Daten zeigt sich, dass die Monatsrechnung weitgehend linear anwächst:
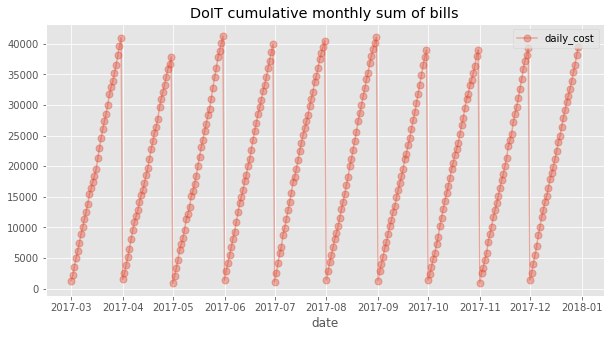
Die Ergebnisse bestätigen, dass ein lineares Modell für das Kostenproblem die richtige Wahl ist. Zudem variiert der Gradient zwischen den Monaten kaum – ein Hinweis darauf, dass die gewählten Features hinreichende Statistiken in Bezug auf die unabhängige Variable sind.
Natürlich liefern mehr Features und komplexere Modelle in der Regel genauere Vorhersagen – die lassen sich mit Tools wie Google Cloud ML umsetzen. Fürs Erste ist die Datenaufbereitung damit aber abgeschlossen.
(JUHU!)
Lineares Regressionsmodell mit BigQuery ML trainieren
Sobald die Daten bereitstehen, kann ich das neue (seit August 2018 verfügbare) BigQuery ML-Tool nutzen, um ein lineares Regressionsmodell auf die Daten zu trainieren.
Das Modell an unser Dataset anzupassen, ist wahnsinnig einfach!
https://gist.github.com/gidutz/7a0bd510494285fd679cde71944e9d77
Vorhersagen erzeugen und das Modell evaluieren
Einmal gespeichert, lässt sich das Modell für Vorhersagen nutzen. Dafür verwende ich die folgende Query – sie schätzt die finalen Monatsausgaben und berechnet zugleich den Relative Absolute Error der Vorhersagen pro Tag:
https://gist.github.com/gidutz/f7de19eee11478d75757e4bdc3b25001
Die Ergebnisse in der folgenden Tabelle lassen sich speichern und in weiteren Systemkomponenten weiterverwenden, etwa für Monitoring- und Alerting-Anwendungen. Der Mean Relative Absolute Error des Modells liegt bei rund 3,0 % – ein durchaus solider Wert. (Hinweis: Die Daten wurden eigens für diese Demo generiert. Mit echten Daten habe ich rund 2,0 % Fehler erreicht.)
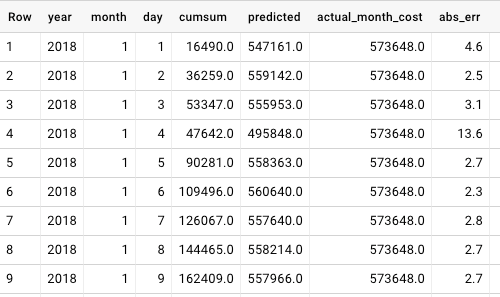 Beispielvorhersage
Beispielvorhersage
Lust auf mehr? Schauen Sie in unserem Blog vorbei oder folgen Sie Gad auf Twitter.
Danksagungen: Vadim Solovey — Lektorat
amiel m — Technisches Review
Keywords: BigQueryML, BigQuery ML Tutorial, BigQuery ML Beispiel